 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Quantum-inspired Kolmogorov-Arnold Eigensolver
May 06, 2026High-performance computing (HPC) is increasingly important for scalable quantum chemistry workflows that couple classical generative models, quantum circuit simulation, and selected configuration interaction postprocessing. We present the generative quantum-inspired Kolmogorov-Arnold eigensolver (GQKAE), a parameter-efficient extension of the generative quantum eigensolver (GQE) for quantum chemistry. GQKAE replaces the parameter-heavy feed-forward network components in GPT-style generative eigensolvers with hybrid quantum-inspired Kolmogorov-Arnold network modules, forming a compact HQKANsformer backbone. The method preserves autoregressive operator selection and the quantum-selected configuration interaction evaluation pipeline, while using single-qubit DatA Re-Uploading ActivatioN modules to provide expressive nonlinear mappings. Numerical benchmarks on H4, N2, LiH, C2H6, H2O, and the H2O dimer show that GQKAE achieves chemical accuracy comparable to the GPT-based GQE architecture, while reducing trainable parameters and memory by approximately 66% and improving wall-time performance. For strongly correlated systems such as N2 and LiH, GQKAE also improves convergence behavior and final energy errors. These results indicate that quantum-inspired Kolmogorov-Arnold networks can reduce classical-side overhead while preserving circuit-generation quality, offering a scalable route for HPC-quantum co-design on near-term quantum platforms.
Quantum Hierarchical Reinforcement Learning via Variational Quantum Circuits
May 05, 2026Reinforcement learning is one of the most challenging learning paradigms where efficacy and efficiency gains are extremely valuable. Hierarchical reinforcement learning is a variant that leverages temporal abstraction to structure decision-making. While parametrized quantum computations have shown success in non-hierarchical reinforcement learning, whether these advantages adapt to hierarchical decision-making remains a critical open question. In this work, we develop a hybrid hierarchical agent based on the option-critic architecture. This hybrid agent substitutes classical components with variational quantum circuits for feature extractors, option-value functions, termination functions, and intra-option policies. Evaluated on standard benchmarking environments, results show that a hybrid agent utilizing a quantum feature extractor can outperform classical baselines while saving up to 66\% trainable parameters. We also identify an architectural bottleneck that quantum option-value estimation severely degrades performance. Further ablation studies reveal how architectural choices of the quantum circuits affect performance. Our work establishes design principles for parameter-efficient hybrid hierarchical agents.
MADQRL: Distributed Quantum Reinforcement Learning Framework for Multi-Agent Environments
Apr 13, 2026Reinforcement learning (RL) is one of the most practical ways to learn from real-life use-cases. Motivated from the cognitive methods used by humans makes it a widely acceptable strategy in the field of artificial intelligence. Most of the environments used for RL are often high-dimensional, and traditional RL algorithms becomes computationally expensive and challenging to effectively learn from such systems. Recent advancements in practical demonstration of quantum computing (QC) theories, such as compact encoding, enhanced representation and learning algorithms, random sampling, or the inherent stochastic nature of quantum systems, have opened up new directions to tackle these challenges. Quantum reinforcement learning (QRL) is seeking significant traction over the past few years. However, the current state of quantum hardware is not enough to cater for such high-dimensional environments with complex multi-agent setup. To tackle this issue, we propose a distributed framework for QRL where multiple agents learn independently, distributing the load of joint training from individual machines. Our method works well for environments with disjoint sets of action and observation spaces, but can also be extended to other systems with reasonable approximations. We analyze the proposed method on cooperative-pong environment and our results indicate ~10% improvement from other distribution strategies, and ~5% improvement from classical models of policy representation.
Photonic Quantum-Enhanced Knowledge Distillation
Mar 16, 2026Photonic quantum processors naturally produce intrinsically stochastic measurement outcomes, offering a hardware-native source of structured randomness that can be exploited during machine-learning training. Here we introduce Photonic Quantum-Enhanced Knowledge Distillation (PQKD), a hybrid quantum photonic--classical framework in which a programmable photonic circuit generates a compact conditioning signal that constrains and guides a parameter-efficient student network during distillation from a high-capacity teacher. PQKD replaces fully trainable convolutional kernels with dictionary convolutions: each layer learns only a small set of shared spatial basis filters, while sample-dependent channel-mixing weights are derived from shot-limited photonic features and mapped through a fixed linear transform. Training alternates between standard gradient-based optimisation of the student and sampling-robust, gradient-free updates of photonic parameters, avoiding differentiation through photonic hardware. Across MNIST, Fashion-MNIST and CIFAR-10, PQKD traces a controllable compression--accuracy frontier, remaining close to teacher performance on simpler benchmarks under aggressive convolutional compression. Performance degrades predictably with finite sampling, consistent with shot-noise scaling, and exponential moving-average feature smoothing suppresses high-frequency shot-noise fluctuations, extending the practical operating regime at moderate shot budgets.
Hybrid Quantum Temporal Convolutional Networks
Feb 27, 2026Quantum machine learning models for sequential data face scalability challenges with complex multivariate signals. We introduce the Hybrid Quantum Temporal Convolutional Network (HQTCN), which combines classical temporal windowing with a quantum convolutional neural network core. By applying a shared quantum circuit across temporal windows, HQTCN captures long-range dependencies while achieving significant parameter reduction. Evaluated on synthetic NARMA sequences and high-dimensional EEG time-series, HQTCN performs competitively with classical baselines on univariate data and outperforms all baselines on multivariate tasks. The model demonstrates particular strength under data-limited conditions, maintaining high performance with substantially fewer parameters than conventional approaches. These results establish HQTCN as a parameter-efficient approach for multivariate time-series analysis.
Quantum Super-resolution by Adaptive Non-local Observables
Jan 20, 2026Super-resolution (SR) seeks to reconstruct high-resolution (HR) data from low-resolution (LR) observations. Classical deep learning methods have advanced SR substantially, but require increasingly deeper networks, large datasets, and heavy computation to capture fine-grained correlations. In this work, we present the \emph{first study} to investigate quantum circuits for SR. We propose a framework based on Variational Quantum Circuits (VQCs) with \emph{Adaptive Non-Local Observable} (ANO) measurements. Unlike conventional VQCs with fixed Pauli readouts, ANO introduces trainable multi-qubit Hermitian observables, allowing the measurement process to adapt during training. This design leverages the high-dimensional Hilbert space of quantum systems and the representational structure provided by entanglement and superposition. Experiments demonstrate that ANO-VQCs achieve up to five-fold higher resolution with a relatively small model size, suggesting a promising new direction at the intersection of quantum machine learning and super-resolution.
TITAN: A Trajectory-Informed Technique for Adaptive Parameter Freezing in Large-Scale VQE
Sep 18, 2025



Variational quantum Eigensolver (VQE) is a leading candidate for harnessing quantum computers to advance quantum chemistry and materials simulations, yet its training efficiency deteriorates rapidly for large Hamiltonians. Two issues underlie this bottleneck: (i) the no-cloning theorem imposes a linear growth in circuit evaluations with the number of parameters per gradient step; and (ii) deeper circuits encounter barren plateaus (BPs), leading to exponentially increasing measurement overheads. To address these challenges, here we propose a deep learning framework, dubbed Titan, which identifies and freezes inactive parameters of a given ansatze at initialization for a specific class of Hamiltonians, reducing the optimization overhead without sacrificing accuracy. The motivation of Titan starts with our empirical findings that a subset of parameters consistently has a negligible influence on training dynamics. Its design combines a theoretically grounded data construction strategy, ensuring each training example is informative and BP-resilient, with an adaptive neural architecture that generalizes across ansatze of varying sizes. Across benchmark transverse-field Ising models, Heisenberg models, and multiple molecule systems up to 30 qubits, Titan achieves up to 3 times faster convergence and 40% to 60% fewer circuit evaluations than state-of-the-art baselines, while matching or surpassing their estimation accuracy. By proactively trimming parameter space, Titan lowers hardware demands and offers a scalable path toward utilizing VQE to advance practical quantum chemistry and materials science.
Quantum Machine Learning, Quantitative Trading, Reinforcement Learning, Deep Learning
Sep 11, 2025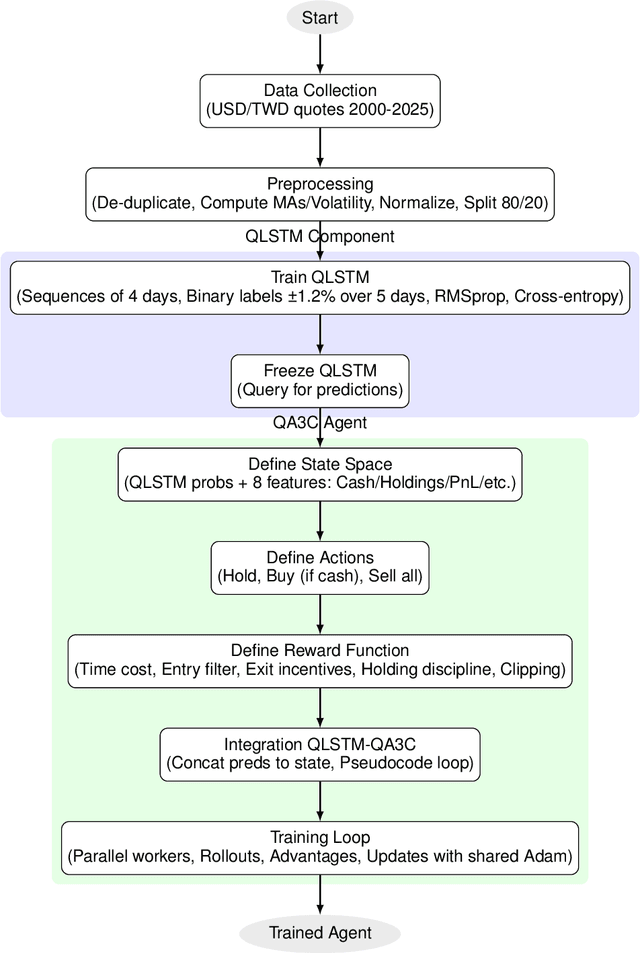
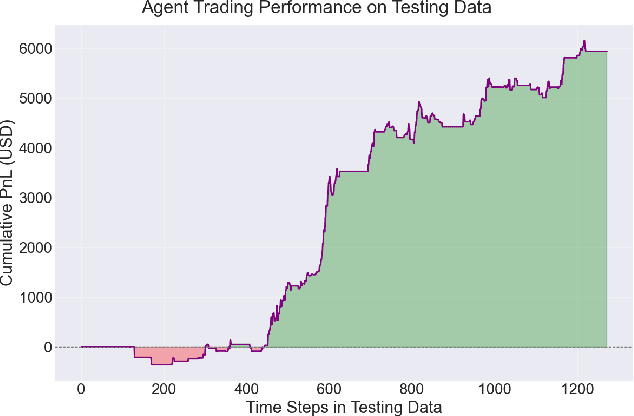
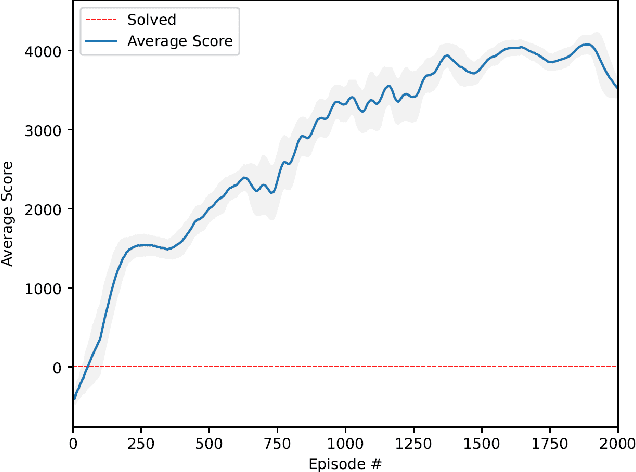

The convergence of quantum-inspired neural networks and deep reinforcement learning offers a promising avenue for financial trading. We implemented a trading agent for USD/TWD by integrating Quantum Long Short-Term Memory (QLSTM) for short-term trend prediction with Quantum Asynchronous Advantage Actor-Critic (QA3C), a quantum-enhanced variant of the classical A3C. Trained on data from 2000-01-01 to 2025-04-30 (80\% training, 20\% testing), the long-only agent achieves 11.87\% return over around 5 years with 0.92\% max drawdown, outperforming several currency ETFs. We detail state design (QLSTM features and indicators), reward function for trend-following/risk control, and multi-core training. Results show hybrid models yield competitive FX trading performance. Implications include QLSTM's effectiveness for small-profit trades with tight risk and future enhancements. Key hyperparameters: QLSTM sequence length$=$4, QA3C workers$=$8. Limitations: classical quantum simulation and simplified strategy. \footnote{The views expressed in this article are those of the authors and do not represent the views of Wells Fargo. This article is for informational purposes only. Nothing contained in this article should be construed as investment advice. Wells Fargo makes no express or implied warranties and expressly disclaims all legal, tax, and accounting implications related to this article.
Quantum Long Short-term Memory with Differentiable Architecture Search
Aug 20, 2025



Recent advances in quantum computing and machine learning have given rise to quantum machine learning (QML), with growing interest in learning from sequential data. Quantum recurrent models like QLSTM are promising for time-series prediction, NLP, and reinforcement learning. However, designing effective variational quantum circuits (VQCs) remains challenging and often task-specific. To address this, we propose DiffQAS-QLSTM, an end-to-end differentiable framework that optimizes both VQC parameters and architecture selection during training. Our results show that DiffQAS-QLSTM consistently outperforms handcrafted baselines, achieving lower loss across diverse test settings. This approach opens the door to scalable and adaptive quantum sequence learning.
Q-DPTS: Quantum Differentially Private Time Series Forecasting via Variational Quantum Circuits
Aug 07, 2025Time series forecasting is vital in domains where data sensitivity is paramount, such as finance and energy systems. While Differential Privacy (DP) provides theoretical guarantees to protect individual data contributions, its integration especially via DP-SGD often impairs model performance due to injected noise. In this paper, we propose Q-DPTS, a hybrid quantum-classical framework for Quantum Differentially Private Time Series Forecasting. Q-DPTS combines Variational Quantum Circuits (VQCs) with per-sample gradient clipping and Gaussian noise injection, ensuring rigorous $(\epsilon, \delta)$-differential privacy. The expressiveness of quantum models enables improved robustness against the utility loss induced by DP mechanisms. We evaluate Q-DPTS on the ETT (Electricity Transformer Temperature) dataset, a standard benchmark for long-term time series forecasting. Our approach is compared against both classical and quantum baselines, including LSTM, QASA, QRWKV, and QLSTM. Results demonstrate that Q-DPTS consistently achieves lower prediction error under the same privacy budget, indicating a favorable privacy-utility trade-off. This work presents one of the first explorations into quantum-enhanced differentially private forecasting, offering promising directions for secure and accurate time series modeling in privacy-critical scenarios.