 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePresence-Only Geographical Priors for Fine-Grained Image Classification
Jun 12, 2019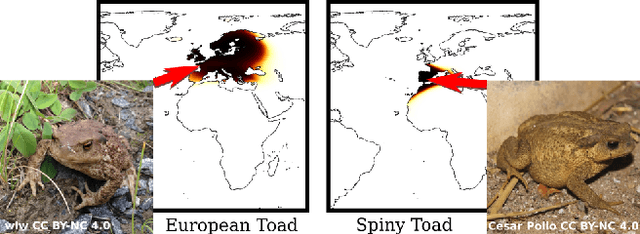
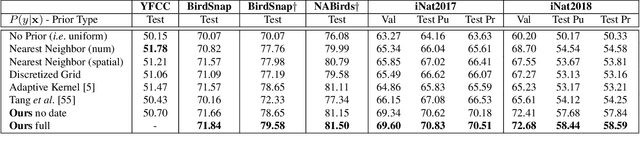
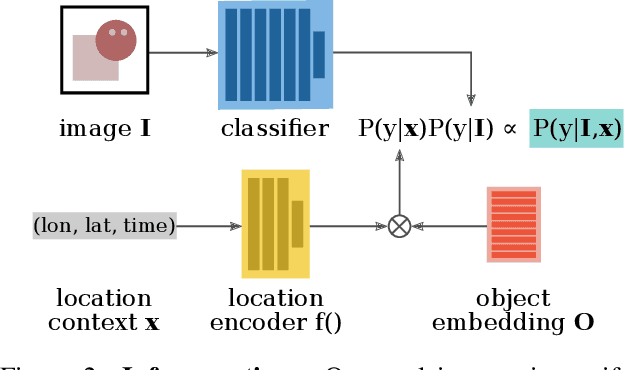
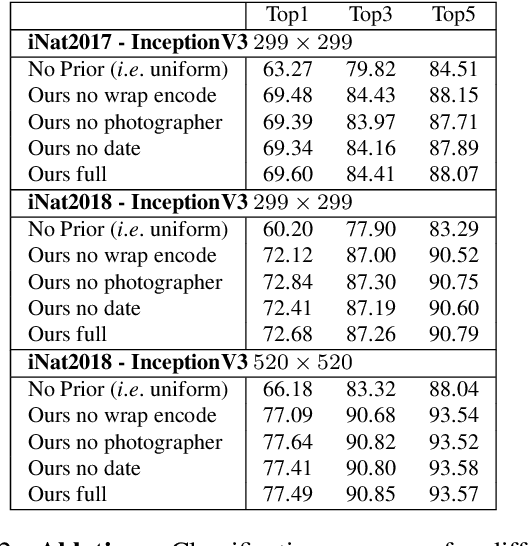
Appearance information alone is often not sufficient to accurately differentiate between fine-grained visual categories. Human experts make use of additional cues such as where, and when, a given image was taken in order to inform their final decision. This contextual information is readily available in many online image collections but has been underutilized by existing image classifiers that focus solely on making predictions based on the image contents. We propose an efficient spatio-temporal prior, that when conditioned on a geographical location and time, estimates the probability that a given object category occurs at that location. Our prior is trained from presence-only observation data and jointly models object categories, their spatio-temporal distributions, and photographer biases. Experiments performed on multiple challenging image classification datasets show that combining our prior with the predictions from image classifiers results in a large improvement in final classification performance.
Synthetic Examples Improve Generalization for Rare Classes
May 14, 2019
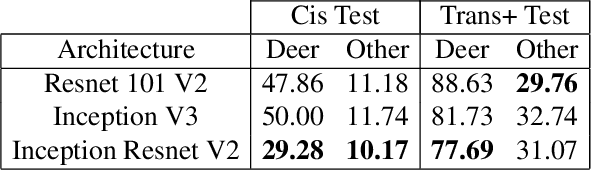

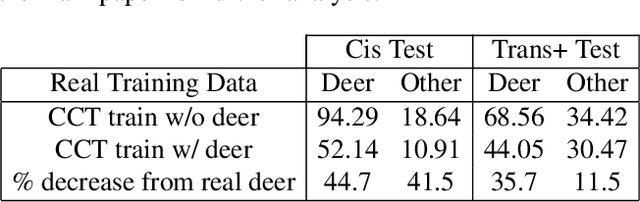
The ability to detect and classify rare occurrences in images has important applications - for example, counting rare and endangered species when studying biodiversity, or detecting infrequent traffic scenarios that pose a danger to self-driving cars. Few-shot learning is an open problem: current computer vision systems struggle to categorize objects they have seen only rarely during training, and collecting a sufficient number of training examples of rare events is often challenging and expensive, and sometimes outright impossible. We explore in depth an approach to this problem: complementing the few available training images with ad-hoc simulated data. Our testbed is animal species classification, which has a real-world long-tailed distribution. We analyze the effect of different axes of variation in simulation, such as pose, lighting, model, and simulation method, and we prescribe best practices for efficiently incorporating simulated data for real-world performance gain. Our experiments reveal that synthetic data can considerably reduce error rates for classes that are rare, that as the amount of simulated data is increased, accuracy on the target class improves, and that high variation of simulated data provides maximum performance gain.
The iWildCam 2018 Challenge Dataset
Apr 24, 2019

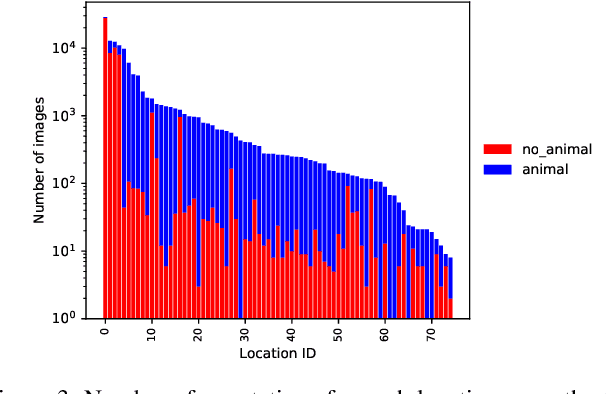
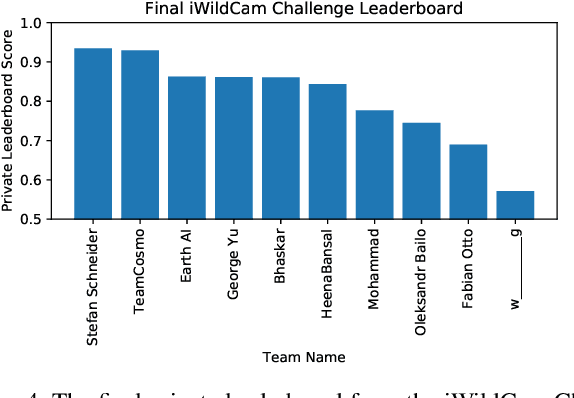
Camera traps are a valuable tool for studying biodiversity, but research using this data is limited by the speed of human annotation. With the vast amounts of data now available it is imperative that we develop automatic solutions for annotating camera trap data in order to allow this research to scale. A promising approach is based on deep networks trained on human-annotated images. We provide a challenge dataset to explore whether such solutions generalize to novel locations, since systems that are trained once and may be deployed to operate automatically in new locations would be most useful.
Task2Vec: Task Embedding for Meta-Learning
Feb 10, 2019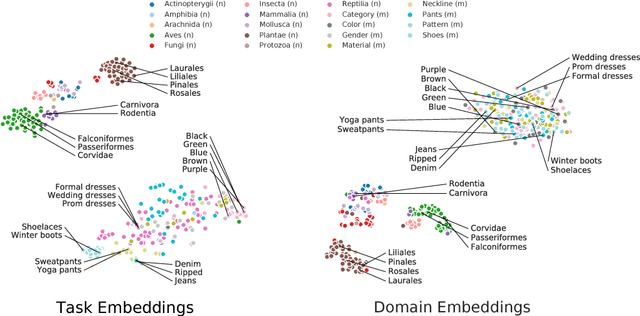
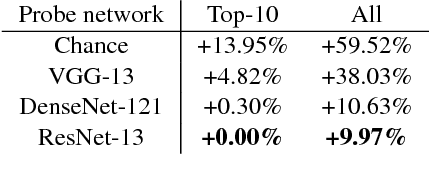
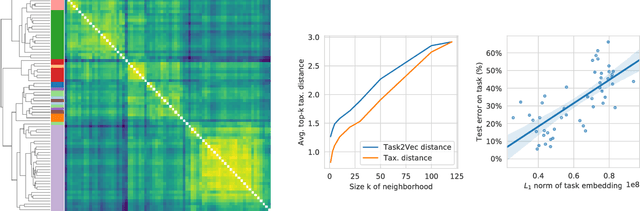

We introduce a method to provide vectorial representations of visual classification tasks which can be used to reason about the nature of those tasks and their relations. Given a dataset with ground-truth labels and a loss function defined over those labels, we process images through a "probe network" and compute an embedding based on estimates of the Fisher information matrix associated with the probe network parameters. This provides a fixed-dimensional embedding of the task that is independent of details such as the number of classes and does not require any understanding of the class label semantics. We demonstrate that this embedding is capable of predicting task similarities that match our intuition about semantic and taxonomic relations between different visual tasks (e.g., tasks based on classifying different types of plants are similar) We also demonstrate the practical value of this framework for the meta-task of selecting a pre-trained feature extractor for a new task. We present a simple meta-learning framework for learning a metric on embeddings that is capable of predicting which feature extractors will perform well. Selecting a feature extractor with task embedding obtains a performance close to the best available feature extractor, while costing substantially less than exhaustively training and evaluating on all available feature extractors.
Teaching Multiple Concepts to a Forgetful Learner
Oct 09, 2018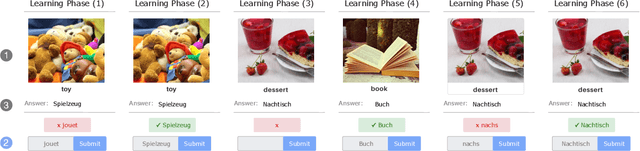
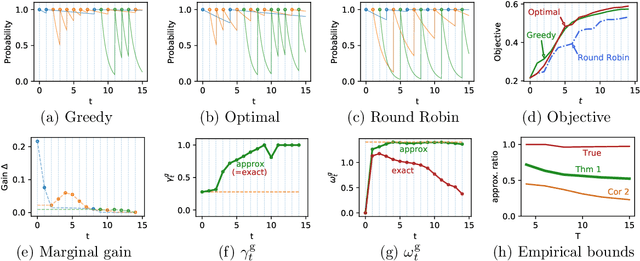
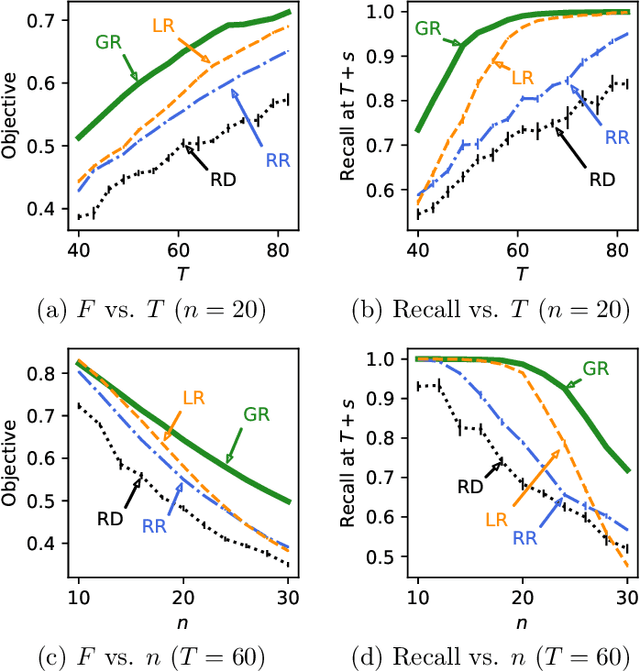

How can we help a forgetful learner learn multiple concepts within a limited time frame? For long-term learning, it is crucial to devise teaching strategies that leverage the underlying forgetting mechanisms of the learner. In this paper, we cast the problem of adaptively teaching a forgetful learner as a novel discrete optimization problem, where we seek to optimize a natural objective function that characterizes the learner's expected performance throughout the teaching session. We then propose a simple greedy teaching strategy and derive strong performance guarantees based on two intuitive data-dependent properties, which capture the degree of diminishing returns of teaching each concept. We show that, given some assumptions about the learner's memory model, one can efficiently compute the performance bounds. Furthermore, we identify parameter settings of the memory model where the greedy strategy is guaranteed to achieve high performance. We demonstrate the effectiveness of our algorithm using extensive simulations along with user studies in two concrete applications, namely (i) an educational app for online vocabulary teaching and (ii) an app for teaching novices how to recognize animal species from images.
It's all Relative: Monocular 3D Human Pose Estimation from Weakly Supervised Data
Jul 28, 2018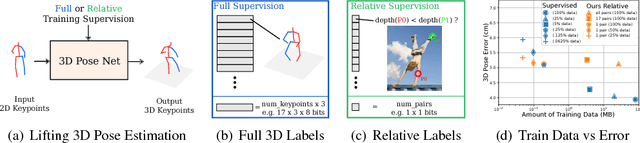
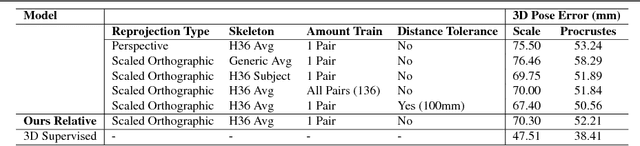
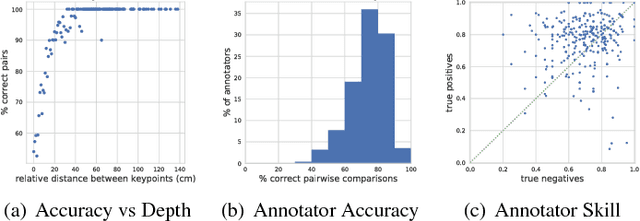
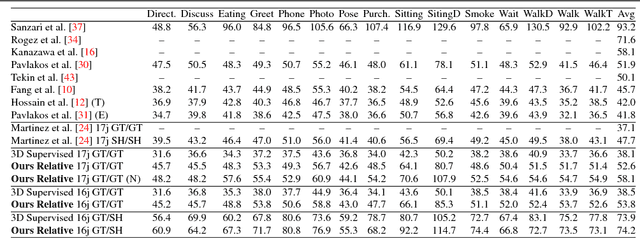
We address the problem of 3D human pose estimation from 2D input images using only weakly supervised training data. Despite showing considerable success for 2D pose estimation, the application of supervised machine learning to 3D pose estimation in real world images is currently hampered by the lack of varied training images with corresponding 3D poses. Most existing 3D pose estimation algorithms train on data that has either been collected in carefully controlled studio settings or has been generated synthetically. Instead, we take a different approach, and propose a 3D human pose estimation algorithm that only requires relative estimates of depth at training time. Such training signal, although noisy, can be easily collected from crowd annotators, and is of sufficient quality for enabling successful training and evaluation of 3D pose algorithms. Our results are competitive with fully supervised regression based approaches on the Human3.6M dataset, despite using significantly weaker training data. Our proposed algorithm opens the door to using existing widespread 2D datasets for 3D pose estimation by allowing fine-tuning with noisy relative constraints, resulting in more accurate 3D poses.
Recognition in Terra Incognita
Jul 25, 2018



It is desirable for detection and classification algorithms to generalize to unfamiliar environments, but suitable benchmarks for quantitatively studying this phenomenon are not yet available. We present a dataset designed to measure recognition generalization to novel environments. The images in our dataset are harvested from twenty camera traps deployed to monitor animal populations. Camera traps are fixed at one location, hence the background changes little across images; capture is triggered automatically, hence there is no human bias. The challenge is learning recognition in a handful of locations, and generalizing animal detection and classification to new locations where no training data is available. In our experiments state-of-the-art algorithms show excellent performance when tested at the same location where they were trained. However, we find that generalization to new locations is poor, especially for classification systems.
Understanding the Role of Adaptivity in Machine Teaching: The Case of Version Space Learners
May 21, 2018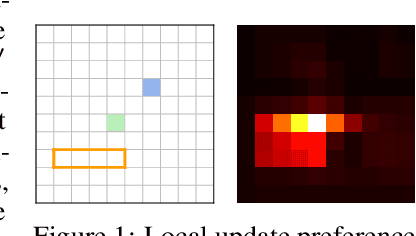
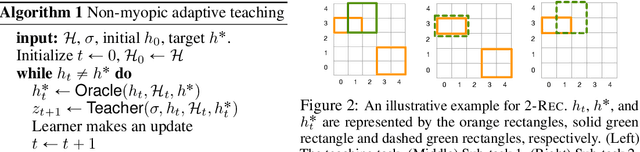
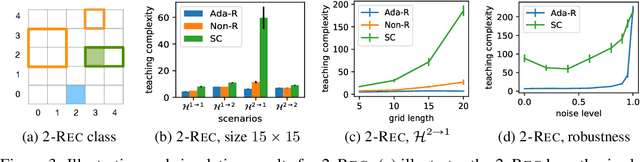
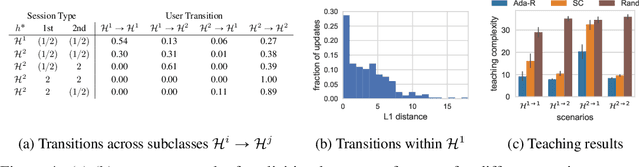
In real-world applications of education, an effective teacher adaptively chooses the next example to teach based on the learner's current state. However, most existing work in algorithmic machine teaching focuses on the batch setting, where adaptivity plays no role. In this paper, we study the case of teaching consistent, version space learners in an interactive setting. At any time step, the teacher provides an example, the learner performs an update, and the teacher observes the learner's new state. We highlight that adaptivity does not speed up the teaching process when considering existing models of version space learners, such as "worst-case" (the learner picks the next hypothesis randomly from the version space) and "preference-based" (the learner picks hypothesis according to some global preference). Inspired by human teaching, we propose a new model where the learner picks hypotheses according to some local preference defined by the current hypothesis. We show that our model exhibits several desirable properties, e.g., adaptivity plays a key role, and the learner's transitions over hypotheses are smooth/interpretable. We develop efficient teaching algorithms and demonstrate our results via simulation and user studies.
The iNaturalist Species Classification and Detection Dataset
Apr 10, 2018
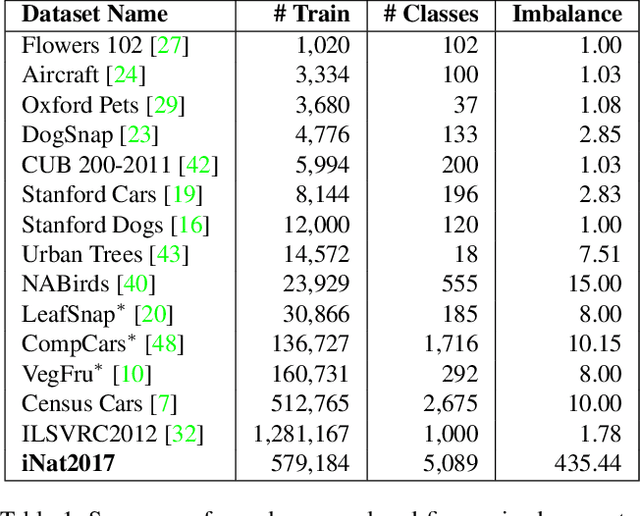
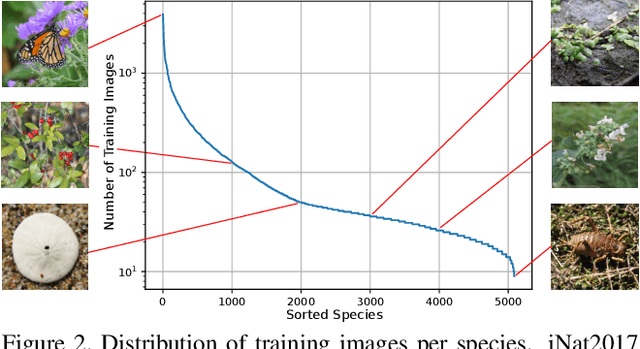
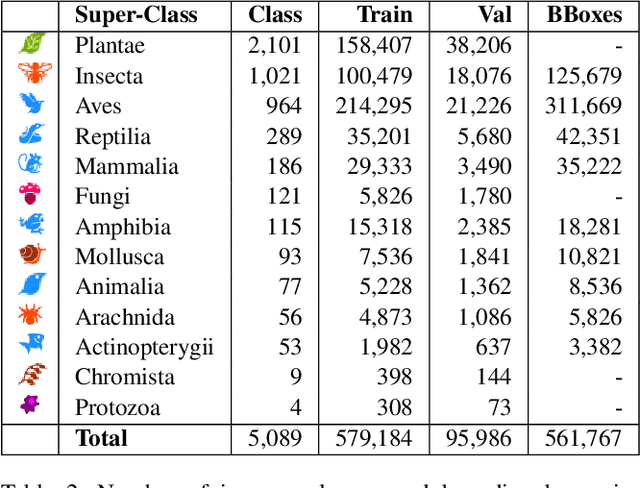
Existing image classification datasets used in computer vision tend to have a uniform distribution of images across object categories. In contrast, the natural world is heavily imbalanced, as some species are more abundant and easier to photograph than others. To encourage further progress in challenging real world conditions we present the iNaturalist species classification and detection dataset, consisting of 859,000 images from over 5,000 different species of plants and animals. It features visually similar species, captured in a wide variety of situations, from all over the world. Images were collected with different camera types, have varying image quality, feature a large class imbalance, and have been verified by multiple citizen scientists. We discuss the collection of the dataset and present extensive baseline experiments using state-of-the-art computer vision classification and detection models. Results show that current non-ensemble based methods achieve only 67% top one classification accuracy, illustrating the difficulty of the dataset. Specifically, we observe poor results for classes with small numbers of training examples suggesting more attention is needed in low-shot learning.
Fast Conditional Independence Test for Vector Variables with Large Sample Sizes
Apr 08, 2018
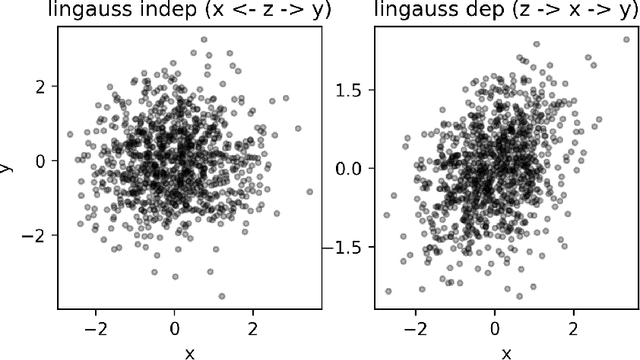
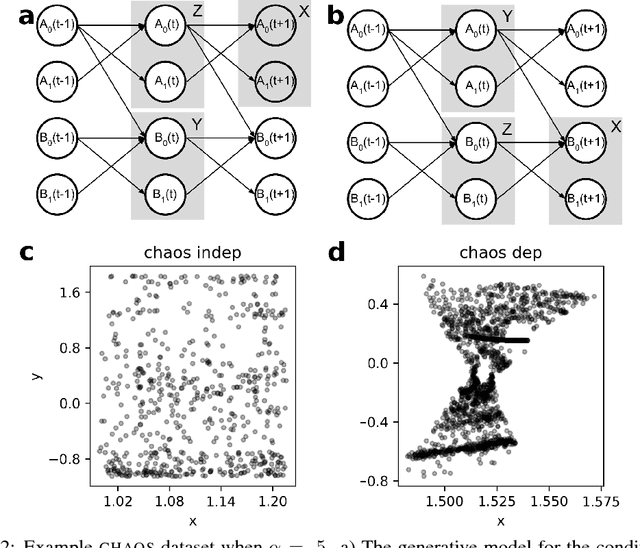
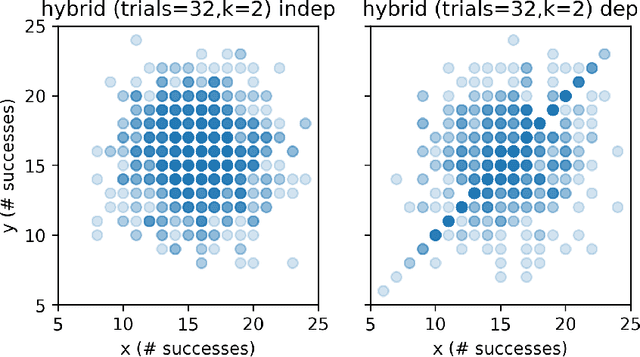
We present and evaluate the Fast (conditional) Independence Test (FIT) -- a nonparametric conditional independence test. The test is based on the idea that when $P(X \mid Y, Z) = P(X \mid Y)$, $Z$ is not useful as a feature to predict $X$, as long as $Y$ is also a regressor. On the contrary, if $P(X \mid Y, Z) \neq P(X \mid Y)$, $Z$ might improve prediction results. FIT applies to thousand-dimensional random variables with a hundred thousand samples in a fraction of the time required by alternative methods. We provide an extensive evaluation that compares FIT to six extant nonparametric independence tests. The evaluation shows that FIT has low probability of making both Type I and Type II errors compared to other tests, especially as the number of available samples grows. Our implementation of FIT is publicly available.