 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Number Sense as an Emergent Property of the Manipulating Brain
Dec 08, 2020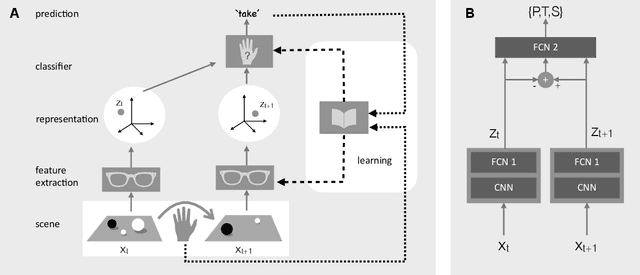
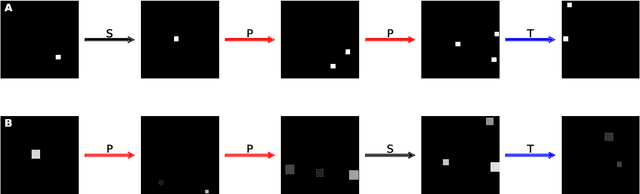
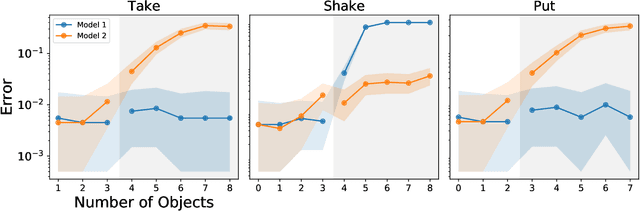
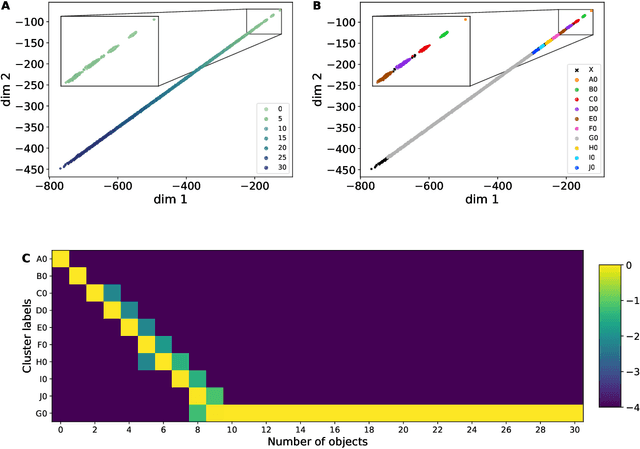
The ability to understand and manipulate numbers and quantities emerges during childhood, but the mechanism through which this ability is developed is still poorly understood. In particular, it is not known whether acquiring such a {\em number sense} is possible without supervision from a teacher. To explore this question, we propose a model in which spontaneous and undirected manipulation of small objects trains perception to predict the resulting scene changes. We find that, from this task, an image representation emerges that exhibits regularities that foreshadow numbers and quantity. These include distinct categories for zero and the first few natural numbers, a notion of order, and a signal that correlates with numerical quantity. As a result, our model acquires the ability to estimate the number of objects in the scene, as well as {\em subitization}, i.e. the ability to recognize at a glance the exact number of objects in small scenes. We conclude that important aspects of a facility with numbers and quantities may be learned without explicit teacher supervision.
Task Programming: Learning Data Efficient Behavior Representations
Nov 27, 2020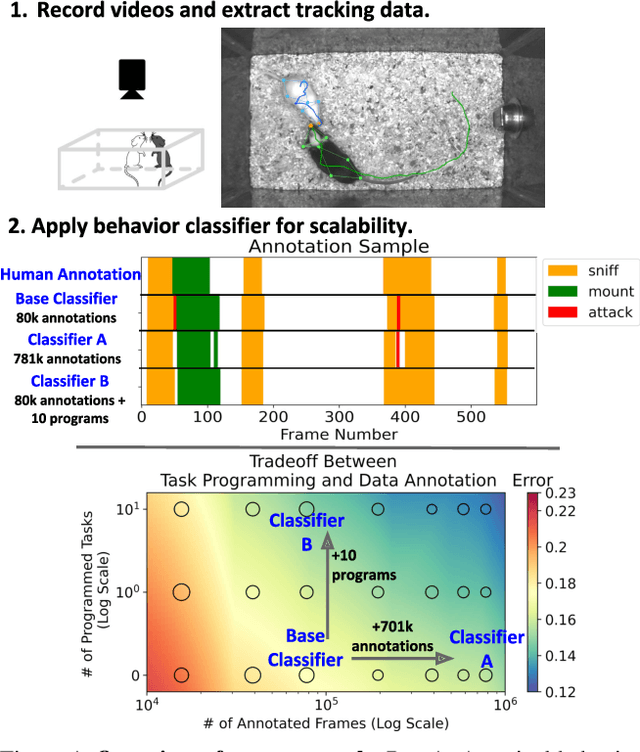
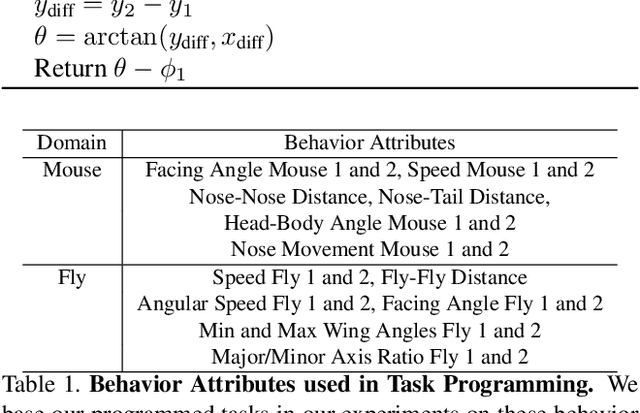
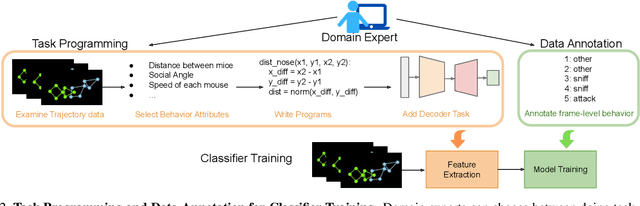
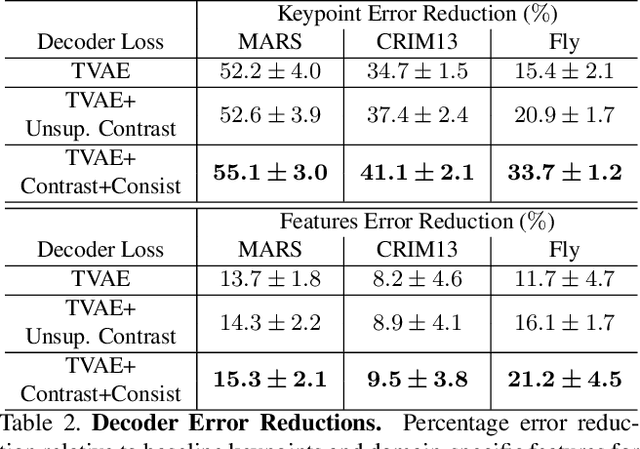
Specialized domain knowledge is often necessary to accurately annotate training sets for in-depth analysis, but can be burdensome and time-consuming to acquire from domain experts. This issue arises prominently in automated behavior analysis, in which agent movements or actions of interest are detected from video tracking data. To reduce annotation effort, we present TREBA: a method to learn annotation-sample efficient trajectory embedding for behavior analysis, based on multi-task self-supervised learning. The tasks in our method can be efficiently engineered by domain experts through a process we call "task programming", which uses programs to explicitly encode structured knowledge from domain experts. Total domain expert effort can be reduced by exchanging data annotation time for the construction of a small number of programmed tasks. We evaluate this trade-off using data from behavioral neuroscience, in which specialized domain knowledge is used to identify behaviors. We present experimental results in three datasets across two domains: mice and fruit flies. Using embeddings from TREBA, we reduce annotation burden by up to a factor of 10 without compromising accuracy compared to state-of-the-art features. Our results thus suggest that task programming can be an effective way to reduce annotation effort for domain experts.
Towards causal benchmarking of bias in face analysis algorithms
Jul 13, 2020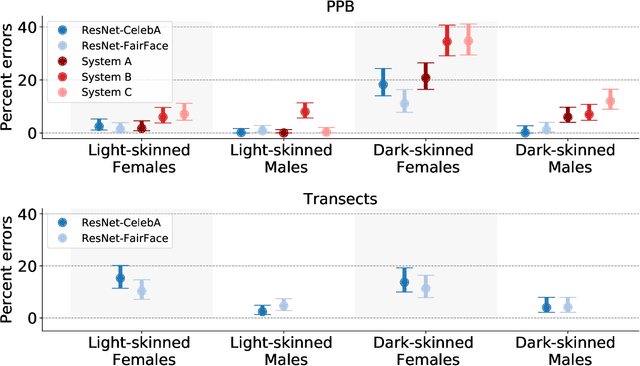
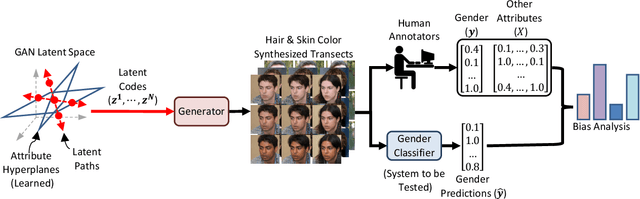


Measuring algorithmic bias is crucial both to assess algorithmic fairness, and to guide the improvement of algorithms. Current methods to measure algorithmic bias in computer vision, which are based on observational datasets, are inadequate for this task because they conflate algorithmic bias with dataset bias. To address this problem we develop an experimental method for measuring algorithmic bias of face analysis algorithms, which manipulates directly the attributes of interest, e.g., gender and skin tone, in order to reveal causal links between attribute variation and performance change. Our proposed method is based on generating synthetic ``transects'' of matched sample images that are designed to differ along specific attributes while leaving other attributes constant. A crucial aspect of our approach is relying on the perception of human observers, both to guide manipulations, and to measure algorithmic bias. Besides allowing the measurement of algorithmic bias, synthetic transects have other advantages with respect to observational datasets: they sample attributes more evenly allowing for more straightforward bias analysis on minority and intersectional groups, they enable prediction of bias in new scenarios, they greatly reduce ethical and legal challenges, and they are economical and fast to obtain, helping make bias testing affordable and widely available. We validate our method by comparing it to a study that employs the traditional observational method for analyzing bias in gender classification algorithms. The two methods reach different conclusions. While the observational method reports gender and skin color biases, the experimental method reveals biases due to gender, hair length, age, and facial hair.
Rethinking Zero-shot Video Classification: End-to-end Training for Realistic Applications
Mar 10, 2020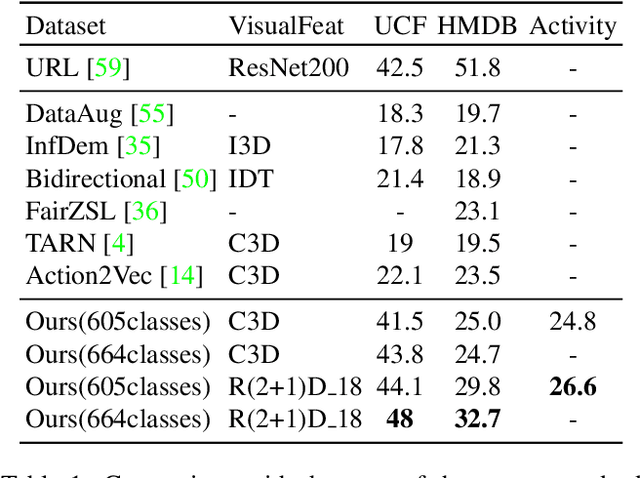
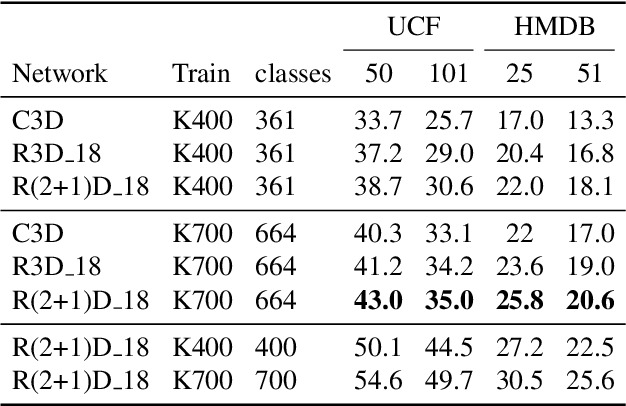
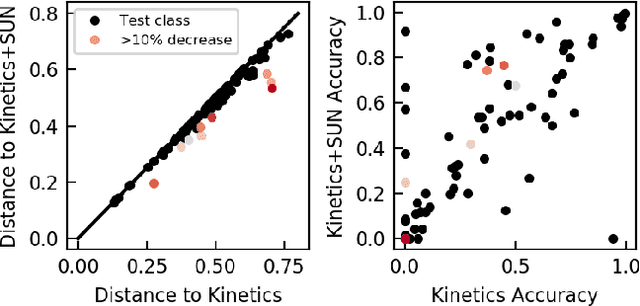
Trained on large datasets, deep learning (DL) can accurately classify videos into hundreds of diverse classes. However, video data is expensive to annotate. Zero-shot learning (ZSL) proposes one solution to this problem. ZSL trains a model once, and generalizes to new tasks whose classes are not present in the training dataset. We propose the first end-to-end algorithm for ZSL in video classification. Our training procedure builds on insights from recent video classification literature and uses a trainable 3D CNN to learn the visual features. This is in contrast to previous video ZSL methods, which use pretrained feature extractors. We also extend the current benchmarking paradigm: Previous techniques aim to make the test task unknown at training time but fall short of this goal. We encourage domain shift across training and test data and disallow tailoring a ZSL model to a specific test dataset. We outperform the state-of-the-art by a wide margin. Our code, evaluation procedure and model weights are available at github.com/bbrattoli/ZeroShotVideoClassification.
Geocoding of trees from street addresses and street-level images
Feb 05, 2020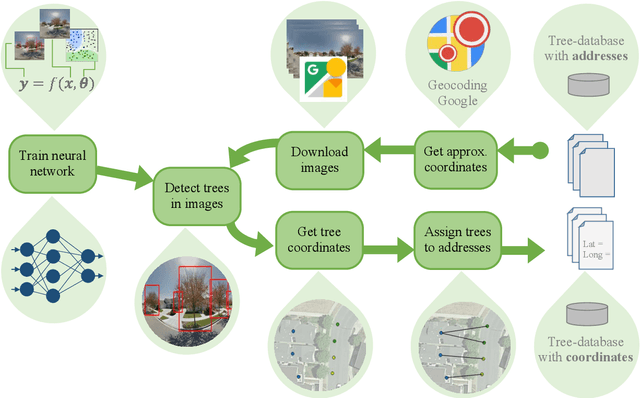

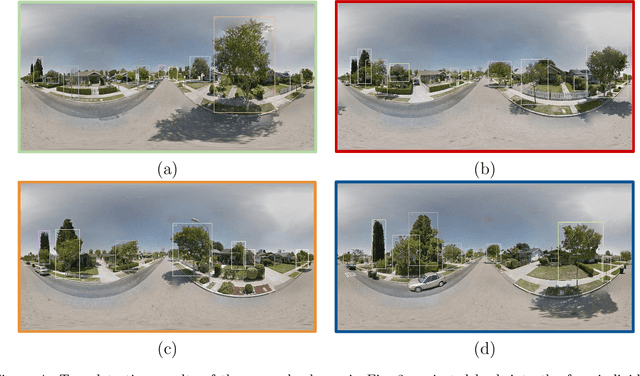
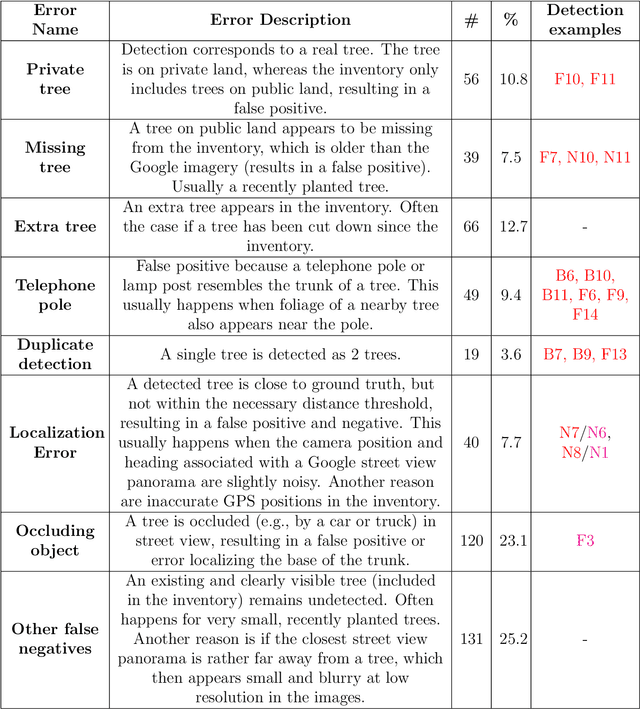
We introduce an approach for updating older tree inventories with geographic coordinates using street-level panorama images and a global optimization framework for tree instance matching. Geolocations of trees in inventories until the early 2000s where recorded using street addresses whereas newer inventories use GPS. Our method retrofits older inventories with geographic coordinates to allow connecting them with newer inventories to facilitate long-term studies on tree mortality etc. What makes this problem challenging is the different number of trees per street address, the heterogeneous appearance of different tree instances in the images, ambiguous tree positions if viewed from multiple images and occlusions. To solve this assignment problem, we (i) detect trees in Google street-view panoramas using deep learning, (ii) combine multi-view detections per tree into a single representation, (iii) and match detected trees with given trees per street address with a global optimization approach. Experiments for > 50000 trees in 5 cities in California, USA, show that we are able to assign geographic coordinates to 38 % of the street trees, which is a good starting point for long-term studies on the ecosystem services value of street trees at large scale.
HMM-guided frame querying for bandwidth-constrained video search
Dec 31, 2019

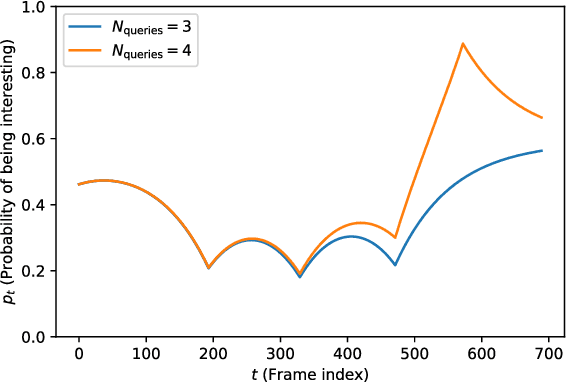

We design an agent to search for frames of interest in video stored on a remote server, under bandwidth constraints. Using a convolutional neural network to score individual frames and a hidden Markov model to propagate predictions across frames, our agent accurately identifies temporal regions of interest based on sparse, strategically sampled frames. On a subset of the ImageNet-VID dataset, we demonstrate that using a hidden Markov model to interpolate between frame scores allows requests of 98% of frames to be omitted, without compromising frame-of-interest classification accuracy.
PanDA: Panoptic Data Augmentation
Nov 27, 2019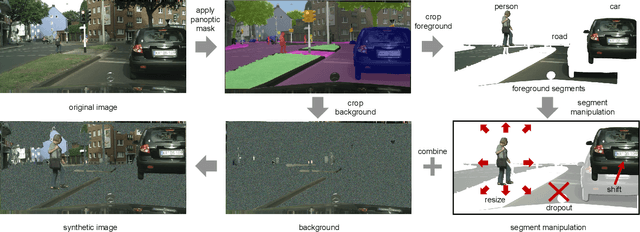



The recently proposed panoptic segmentation task presents a significant challenge of image understanding with computer vision by unifying semantic segmentation and instance segmentation tasks. In this paper we present an efficient and novel panoptic data augmentation (PanDA) method which operates exclusively in pixel space, requires no additional data or training, and is computationally cheap to implement. We retrain the original state-of-the-art UPSNet panoptic segmentation model on PanDA augmented Cityscapes dataset, and demonstrate all-round performance improvement upon the original model. We also show that PanDA is effective across scales from 10 to 30,000 images, as well as generalizable to Microsoft COCO panoptic segmentation task. Finally, the effectiveness of PanDA generated unrealistic-looking training images suggest that we should rethink about optimizing levels of image realism for efficient data augmentation.
From Google Maps to a Fine-Grained Catalog of Street trees
Oct 07, 2019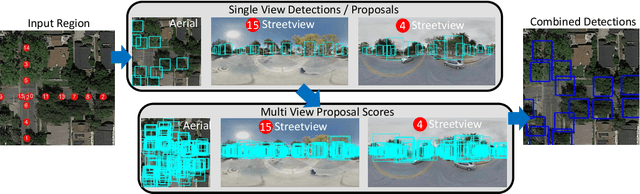

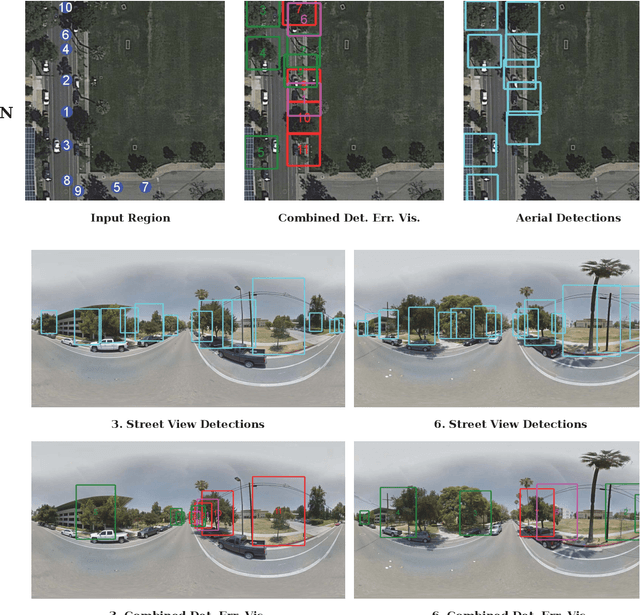
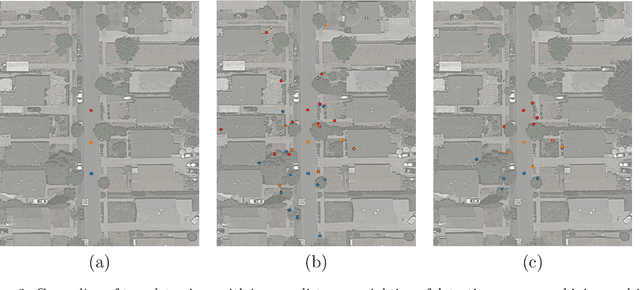
Up-to-date catalogs of the urban tree population are important for municipalities to monitor and improve quality of life in cities. Despite much research on automation of tree mapping, mainly relying on dedicated airborne LiDAR or hyperspectral campaigns, trees are still mostly mapped manually in practice. We present a fully automated tree detection and species recognition pipeline to process thousands of trees within a few hours using publicly available aerial and street view images of Google MapsTM. These data provide rich information (viewpoints, scales) from global tree shapes to bark textures. Our work-flow is built around a supervised classification that automatically learns the most discriminative features from thousands of trees and corresponding, public tree inventory data. In addition, we introduce a change tracker to keep urban tree inventories up-to-date. Changes of individual trees are recognized at city-scale by comparing street-level images of the same tree location at two different times. Drawing on recent advances in computer vision and machine learning, we apply convolutional neural networks (CNN) for all classification tasks. We propose the following pipeline: download all available panoramas and overhead images of an area of interest, detect trees per image and combine multi-view detections in a probabilistic framework, adding prior knowledge; recognize fine-grained species of detected trees. In a later, separate module, track trees over time and identify the type of change. We believe this is the first work to exploit publicly available image data for fine-grained tree mapping at city-scale, respectively over many thousands of trees. Experiments in the city of Pasadena, California, USA show that we can detect > 70% of the street trees, assign correct species to > 80% for 40 different species, and correctly detect and classify changes in > 90% of the cases.
Anchor Loss: Modulating Loss Scale based on Prediction Difficulty
Sep 24, 2019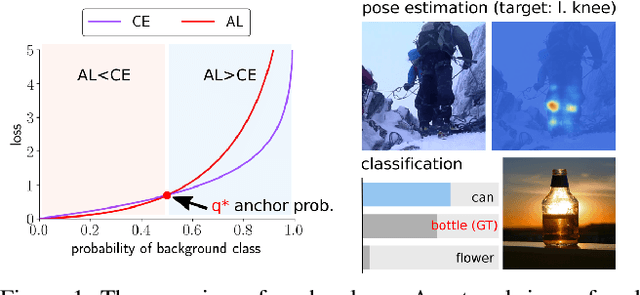
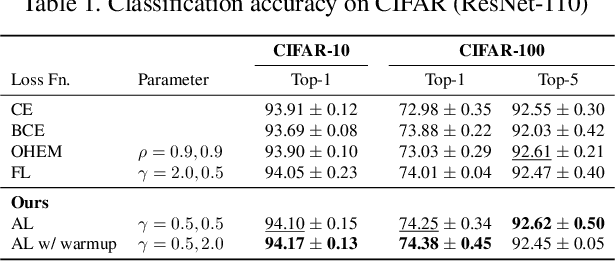
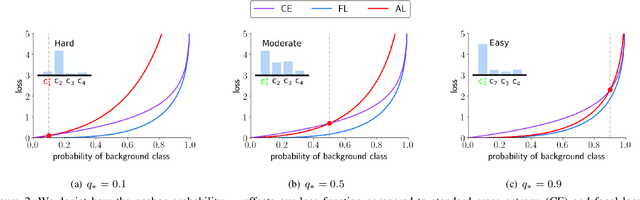

We propose a novel loss function that dynamically rescales the cross entropy based on prediction difficulty regarding a sample. Deep neural network architectures in image classification tasks struggle to disambiguate visually similar objects. Likewise, in human pose estimation symmetric body parts often confuse the network with assigning indiscriminative scores to them. This is due to the output prediction, in which only the highest confidence label is selected without taking into consideration a measure of uncertainty. In this work, we define the prediction difficulty as a relative property coming from the confidence score gap between positive and negative labels. More precisely, the proposed loss function penalizes the network to avoid the score of a false prediction being significant. To demonstrate the efficacy of our loss function, we evaluate it on two different domains: image classification and human pose estimation. We find improvements in both applications by achieving higher accuracy compared to the baseline methods.
The iWildCam 2019 Challenge Dataset
Jul 15, 2019

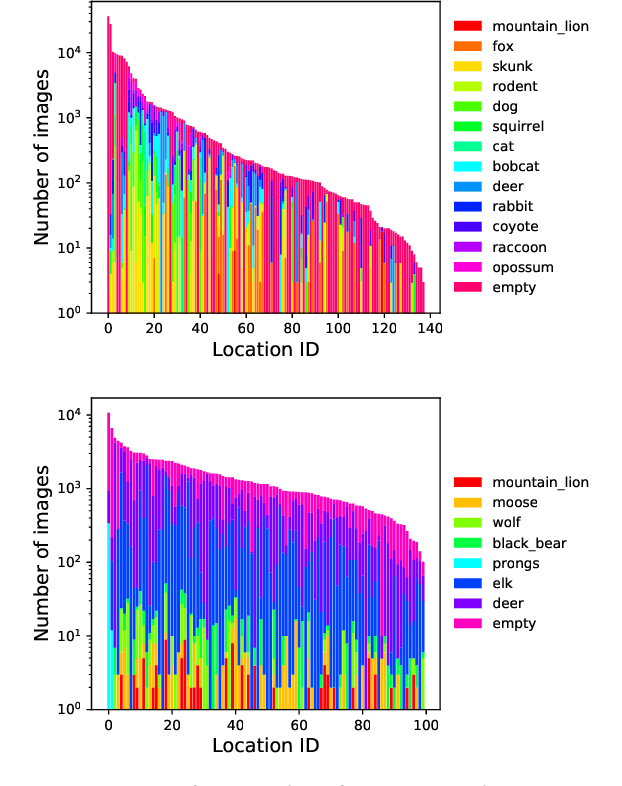
Camera Traps (or Wild Cams) enable the automatic collection of large quantities of image data. Biologists all over the world use camera traps to monitor biodiversity and population density of animal species. The computer vision community has been making strides towards automating the species classification challenge in camera traps, but as we try to expand the scope of these models from specific regions where we have collected training data to different areas we are faced with an interesting problem: how do you classify a species in a new region that you may not have seen in previous training data? In order to tackle this problem, we have prepared a dataset and challenge where the training data and test data are from different regions, namely The American Southwest and the American Northwest. We use the Caltech Camera Traps dataset, collected from the American Southwest, as training data. We add a new dataset from the American Northwest, curated from data provided by the Idaho Department of Fish and Game (IDFG), as our test dataset. The test data has some class overlap with the training data, some species are found in both datasets, but there are both species seen during training that are not seen during test and vice versa. To help fill the gaps in the training species, we allow competitors to utilize transfer learning from two alternate domains: human-curated images from iNaturalist and synthetic images from Microsoft's TrapCam-AirSim simulation environment.