 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentational Difference Explanations
May 29, 2025



We propose a method for discovering and visualizing the differences between two learned representations, enabling more direct and interpretable model comparisons. We validate our method, which we call Representational Differences Explanations (RDX), by using it to compare models with known conceptual differences and demonstrate that it recovers meaningful distinctions where existing explainable AI (XAI) techniques fail. Applied to state-of-the-art models on challenging subsets of the ImageNet and iNaturalist datasets, RDX reveals both insightful representational differences and subtle patterns in the data. Although comparison is a cornerstone of scientific analysis, current tools in machine learning, namely post hoc XAI methods, struggle to support model comparison effectively. Our work addresses this gap by introducing an effective and explainable tool for contrasting model representations.
Representational Similarity via Interpretable Visual Concepts
Mar 19, 2025How do two deep neural networks differ in how they arrive at a decision? Measuring the similarity of deep networks has been a long-standing open question. Most existing methods provide a single number to measure the similarity of two networks at a given layer, but give no insight into what makes them similar or dissimilar. We introduce an interpretable representational similarity method (RSVC) to compare two networks. We use RSVC to discover shared and unique visual concepts between two models. We show that some aspects of model differences can be attributed to unique concepts discovered by one model that are not well represented in the other. Finally, we conduct extensive evaluation across different vision model architectures and training protocols to demonstrate its effectiveness.
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Jul 18, 2024



Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Less is More: Discovering Concise Network Explanations
May 24, 2024We introduce Discovering Conceptual Network Explanations (DCNE), a new approach for generating human-comprehensible visual explanations to enhance the interpretability of deep neural image classifiers. Our method automatically finds visual explanations that are critical for discriminating between classes. This is achieved by simultaneously optimizing three criteria: the explanations should be few, diverse, and human-interpretable. Our approach builds on the recently introduced Concept Relevance Propagation (CRP) explainability method. While CRP is effective at describing individual neuronal activations, it generates too many concepts, which impacts human comprehension. Instead, DCNE selects the few most important explanations. We introduce a new evaluation dataset centered on the challenging task of classifying birds, enabling us to compare the alignment of DCNE's explanations to those of human expert-defined ones. Compared to existing eXplainable Artificial Intelligence (XAI) methods, DCNE has a desirable trade-off between conciseness and completeness when summarizing network explanations. It produces 1/30 of CRP's explanations while only resulting in a slight reduction in explanation quality. DCNE represents a step forward in making neural network decisions accessible and interpretable to humans, providing a valuable tool for both researchers and practitioners in XAI and model alignment.
Text-image Alignment for Diffusion-based Perception
Oct 04, 2023



Diffusion models are generative models with impressive text-to-image synthesis capabilities and have spurred a new wave of creative methods for classical machine learning tasks. However, the best way to harness the perceptual knowledge of these generative models for visual tasks is still an open question. Specifically, it is unclear how to use the prompting interface when applying diffusion backbones to vision tasks. We find that automatically generated captions can improve text-image alignment and significantly enhance a model's cross-attention maps, leading to better perceptual performance. Our approach improves upon the current SOTA in diffusion-based semantic segmentation on ADE20K and the current overall SOTA in depth estimation on NYUv2. Furthermore, our method generalizes to the cross-domain setting; we use model personalization and caption modifications to align our model to the target domain and find improvements over unaligned baselines. Our object detection model, trained on Pascal VOC, achieves SOTA results on Watercolor2K. Our segmentation method, trained on Cityscapes, achieves SOTA results on Dark Zurich-val and Nighttime Driving. Project page: https://www.vision.caltech.edu/tadp/
Visual Knowledge Tracing
Jul 22, 2022
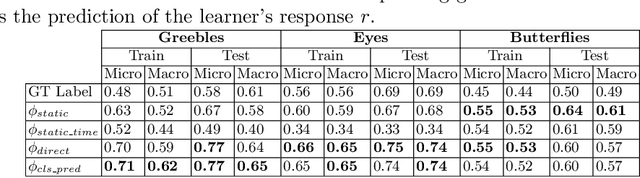
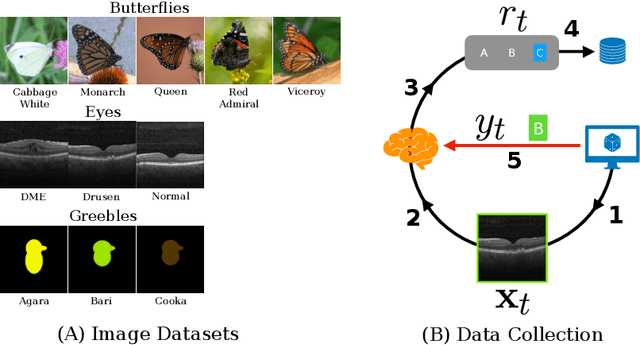
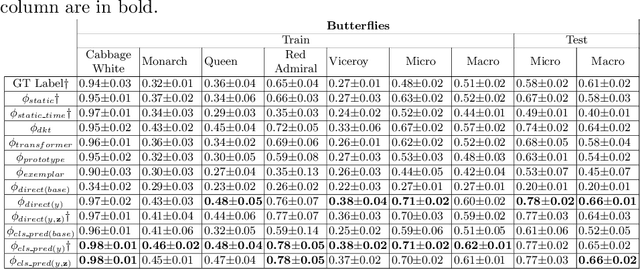
Each year, thousands of people learn new visual categorization tasks -- radiologists learn to recognize tumors, birdwatchers learn to distinguish similar species, and crowd workers learn how to annotate valuable data for applications like autonomous driving. As humans learn, their brain updates the visual features it extracts and attend to, which ultimately informs their final classification decisions. In this work, we propose a novel task of tracing the evolving classification behavior of human learners as they engage in challenging visual classification tasks. We propose models that jointly extract the visual features used by learners as well as predicting the classification functions they utilize. We collect three challenging new datasets from real human learners in order to evaluate the performance of different visual knowledge tracing methods. Our results show that our recurrent models are able to predict the classification behavior of human learners on three challenging medical image and species identification tasks.
A Number Sense as an Emergent Property of the Manipulating Brain
Dec 08, 2020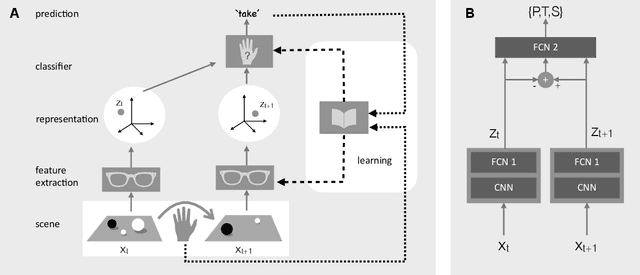
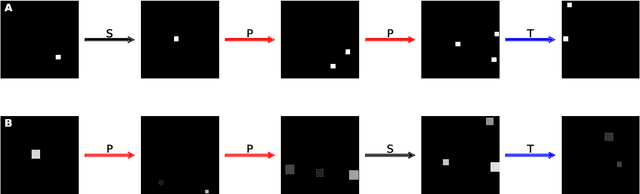
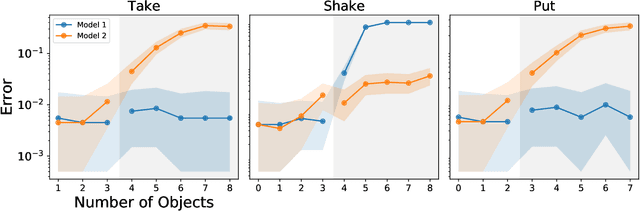
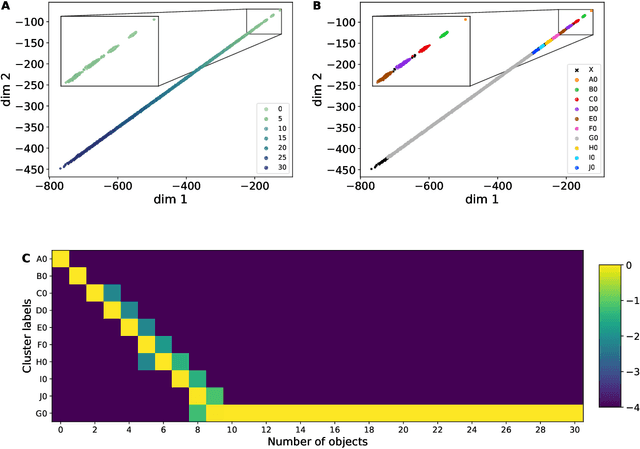
The ability to understand and manipulate numbers and quantities emerges during childhood, but the mechanism through which this ability is developed is still poorly understood. In particular, it is not known whether acquiring such a {\em number sense} is possible without supervision from a teacher. To explore this question, we propose a model in which spontaneous and undirected manipulation of small objects trains perception to predict the resulting scene changes. We find that, from this task, an image representation emerges that exhibits regularities that foreshadow numbers and quantity. These include distinct categories for zero and the first few natural numbers, a notion of order, and a signal that correlates with numerical quantity. As a result, our model acquires the ability to estimate the number of objects in the scene, as well as {\em subitization}, i.e. the ability to recognize at a glance the exact number of objects in small scenes. We conclude that important aspects of a facility with numbers and quantities may be learned without explicit teacher supervision.