 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Saliency Methods for Neural Language Models
Apr 12, 2021
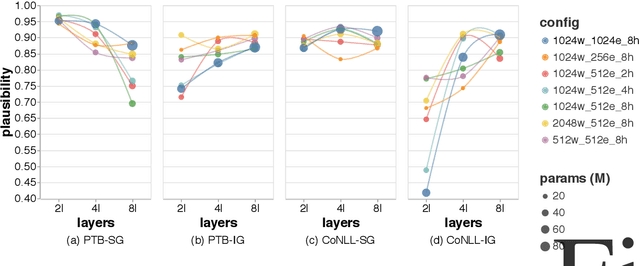

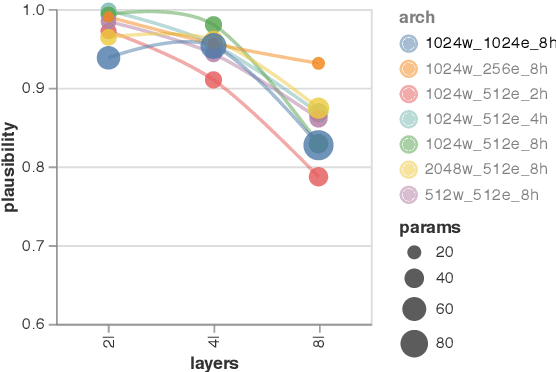
Saliency methods are widely used to interpret neural network predictions, but different variants of saliency methods often disagree even on the interpretations of the same prediction made by the same model. In these cases, how do we identify when are these interpretations trustworthy enough to be used in analyses? To address this question, we conduct a comprehensive and quantitative evaluation of saliency methods on a fundamental category of NLP models: neural language models. We evaluate the quality of prediction interpretations from two perspectives that each represents a desirable property of these interpretations: plausibility and faithfulness. Our evaluation is conducted on four different datasets constructed from the existing human annotation of syntactic and semantic agreements, on both sentence-level and document-level. Through our evaluation, we identified various ways saliency methods could yield interpretations of low quality. We recommend that future work deploying such methods to neural language models should carefully validate their interpretations before drawing insights.
Learning Feature Weights using Reward Modeling for Denoising Parallel Corpora
Mar 11, 2021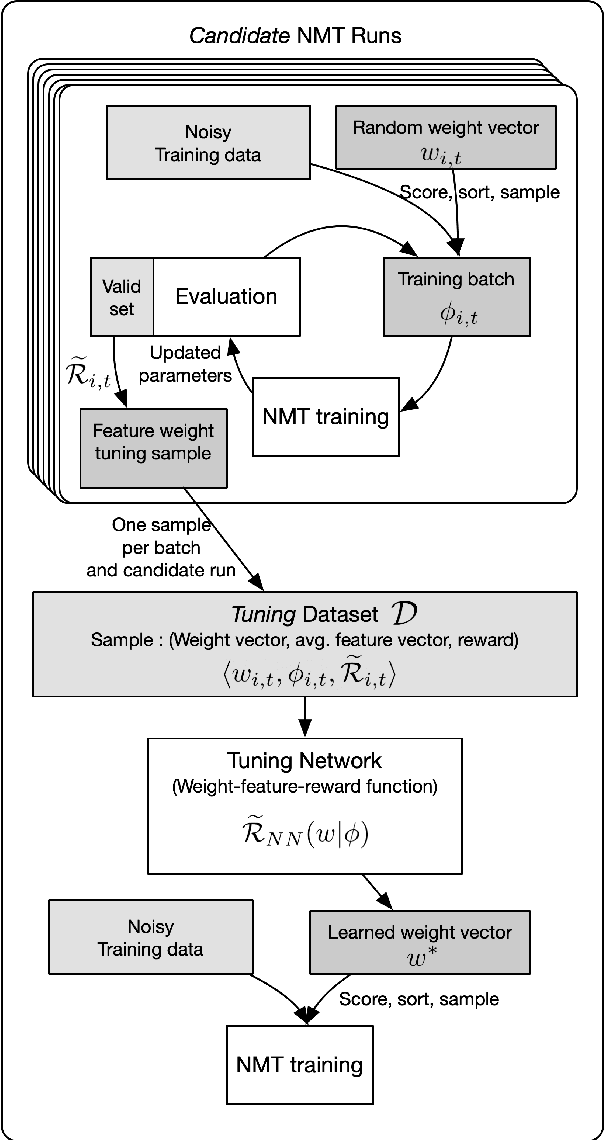
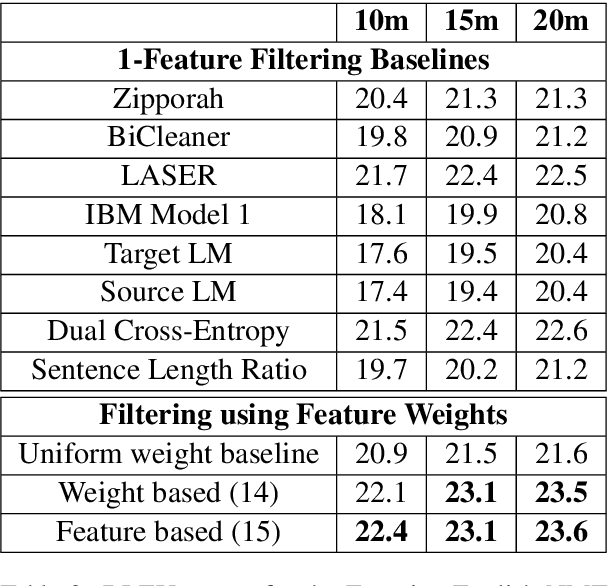
Large web-crawled corpora represent an excellent resource for improving the performance of Neural Machine Translation (NMT) systems across several language pairs. However, since these corpora are typically extremely noisy, their use is fairly limited. Current approaches to dealing with this problem mainly focus on filtering using heuristics or single features such as language model scores or bi-lingual similarity. This work presents an alternative approach which learns weights for multiple sentence-level features. These feature weights which are optimized directly for the task of improving translation performance, are used to score and filter sentences in the noisy corpora more effectively. We provide results of applying this technique to building NMT systems using the Paracrawl corpus for Estonian-English and show that it beats strong single feature baselines and hand designed combinations. Additionally, we analyze the sensitivity of this method to different types of noise and explore if the learned weights generalize to other language pairs using the Maltese-English Paracrawl corpus.
Learning Policies for Multilingual Training of Neural Machine Translation Systems
Mar 11, 2021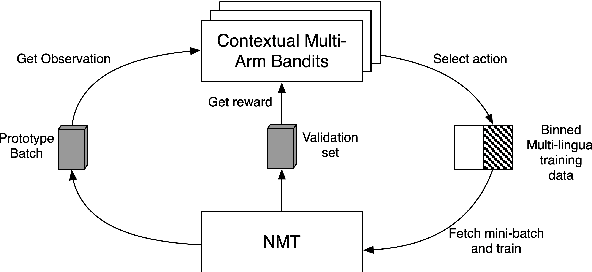
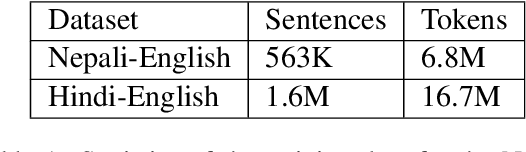
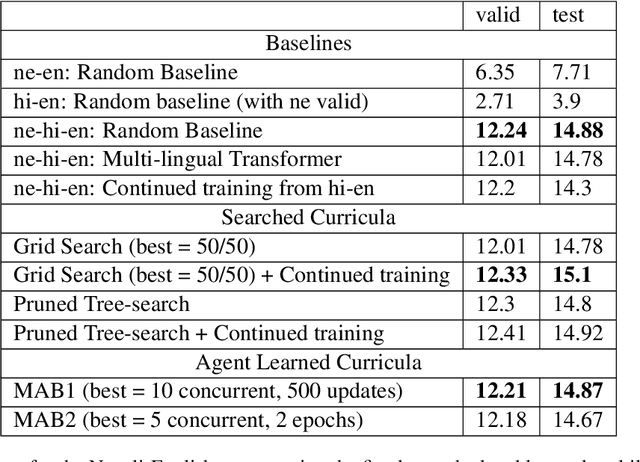
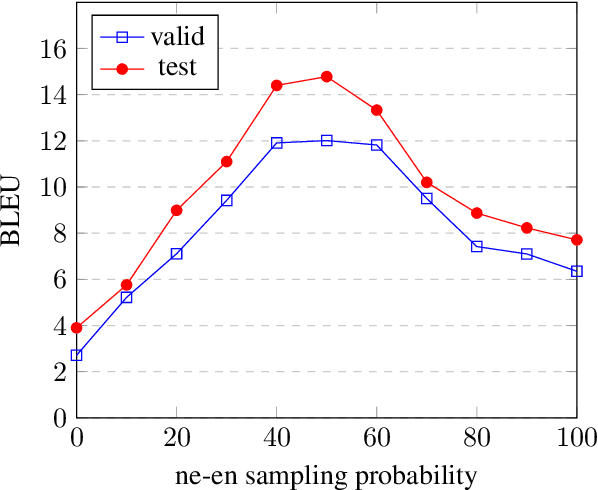
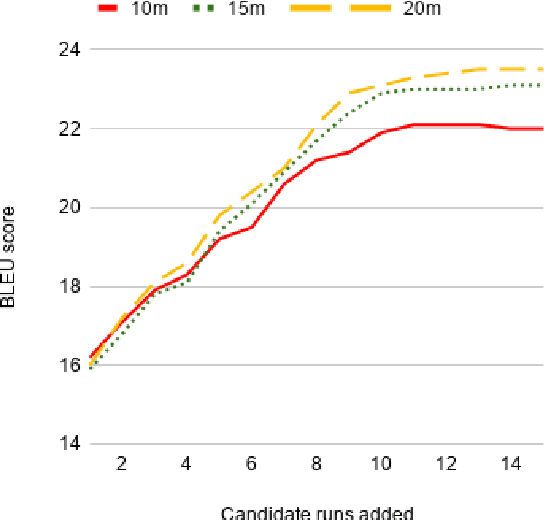
Low-resource Multilingual Neural Machine Translation (MNMT) is typically tasked with improving the translation performance on one or more language pairs with the aid of high-resource language pairs. In this paper, we propose two simple search based curricula -- orderings of the multilingual training data -- which help improve translation performance in conjunction with existing techniques such as fine-tuning. Additionally, we attempt to learn a curriculum for MNMT from scratch jointly with the training of the translation system with the aid of contextual multi-arm bandits. We show on the FLORES low-resource translation dataset that these learned curricula can provide better starting points for fine tuning and improve overall performance of the translation system.
Zero-Shot Cross-Lingual Dependency Parsing through Contextual Embedding Transformation
Mar 03, 2021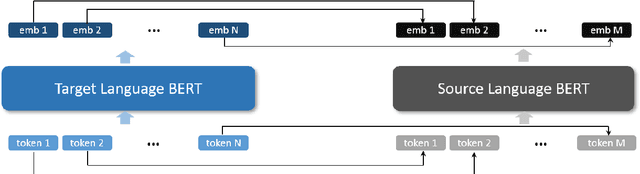

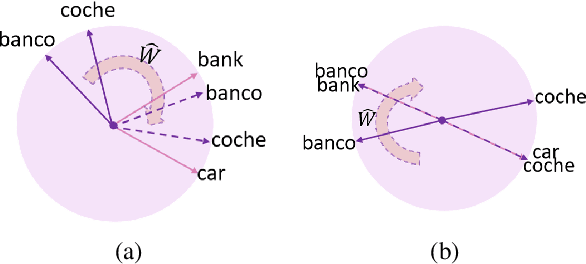
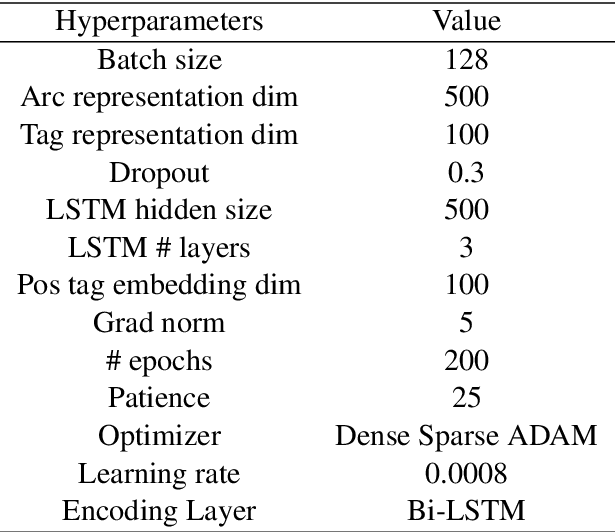
Linear embedding transformation has been shown to be effective for zero-shot cross-lingual transfer tasks and achieve surprisingly promising results. However, cross-lingual embedding space mapping is usually studied in static word-level embeddings, where a space transformation is derived by aligning representations of translation pairs that are referred from dictionaries. We move further from this line and investigate a contextual embedding alignment approach which is sense-level and dictionary-free. To enhance the quality of the mapping, we also provide a deep view of properties of contextual embeddings, i.e., anisotropy problem and its solution. Experiments on zero-shot dependency parsing through the concept-shared space built by our embedding transformation substantially outperform state-of-the-art methods using multilingual embeddings.
SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation
Nov 03, 2020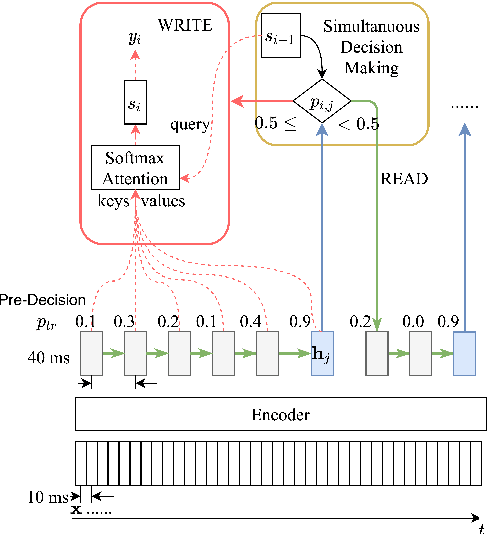
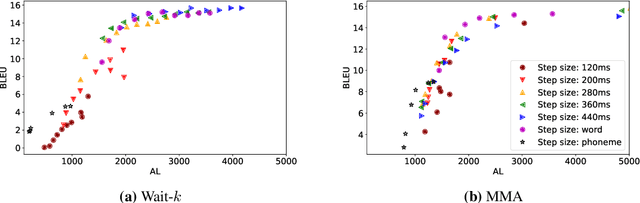
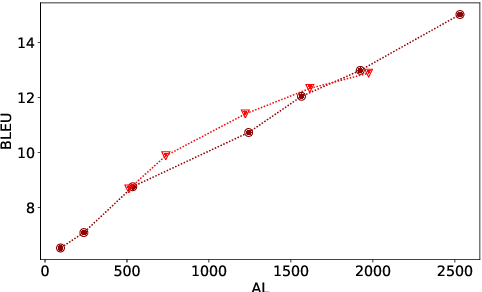
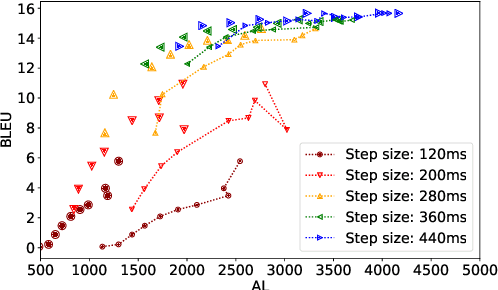
Simultaneous text translation and end-to-end speech translation have recently made great progress but little work has combined these tasks together. We investigate how to adapt simultaneous text translation methods such as wait-k and monotonic multihead attention to end-to-end simultaneous speech translation by introducing a pre-decision module. A detailed analysis is provided on the latency-quality trade-offs of combining fixed and flexible pre-decision with fixed and flexible policies. We also design a novel computation-aware latency metric, adapted from Average Lagging.
Streaming Simultaneous Speech Translation with Augmented Memory Transformer
Oct 30, 2020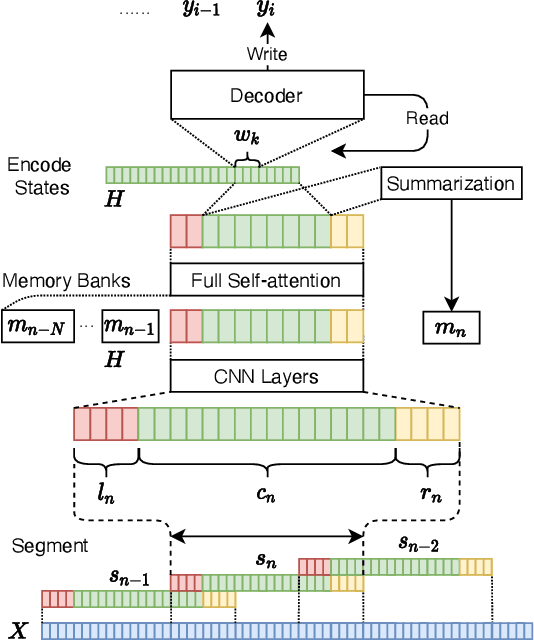
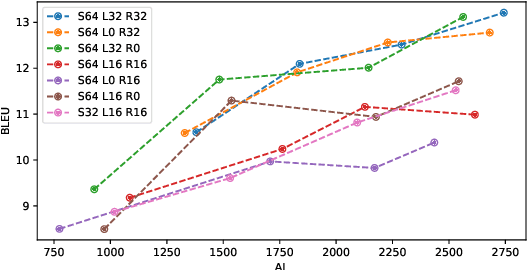
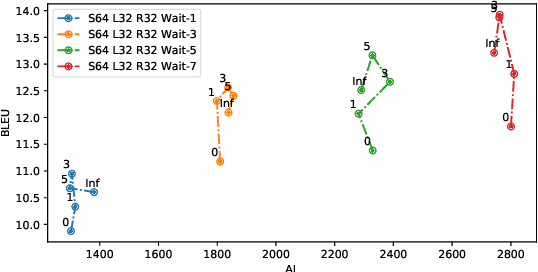
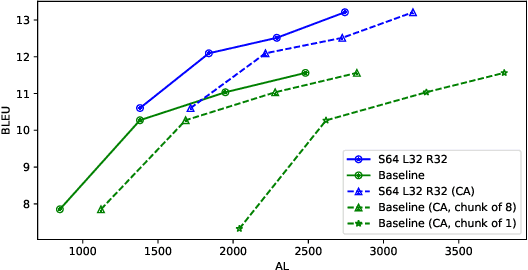
Transformer-based models have achieved state-of-the-art performance on speech translation tasks. However, the model architecture is not efficient enough for streaming scenarios since self-attention is computed over an entire input sequence and the computational cost grows quadratically with the length of the input sequence. Nevertheless, most of the previous work on simultaneous speech translation, the task of generating translations from partial audio input, ignores the time spent in generating the translation when analyzing the latency. With this assumption, a system may have good latency quality trade-offs but be inapplicable in real-time scenarios. In this paper, we focus on the task of streaming simultaneous speech translation, where the systems are not only capable of translating with partial input but are also able to handle very long or continuous input. We propose an end-to-end transformer-based sequence-to-sequence model, equipped with an augmented memory transformer encoder, which has shown great success on the streaming automatic speech recognition task with hybrid or transducer-based models. We conduct an empirical evaluation of the proposed model on segment, context and memory sizes and we compare our approach to a transformer with a unidirectional mask.
TICO-19: the Translation Initiative for Covid-19
Jul 06, 2020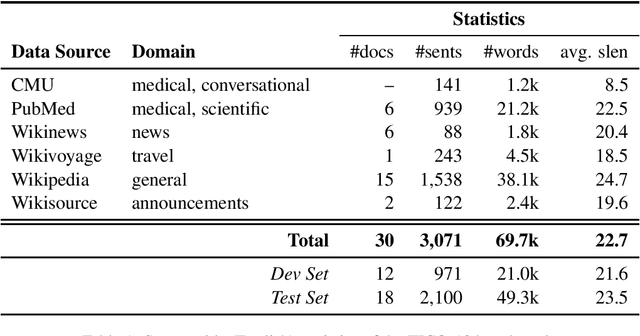
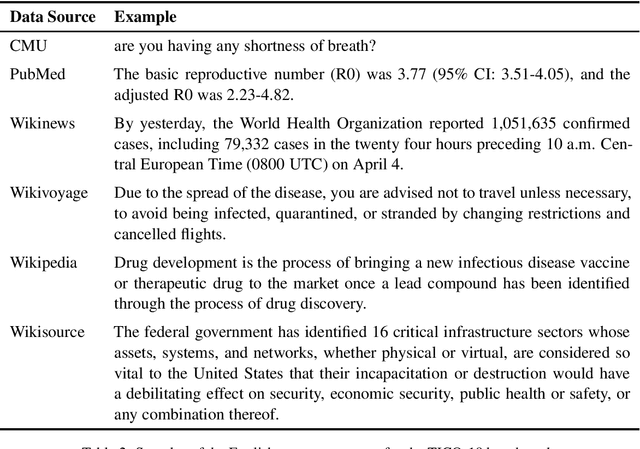
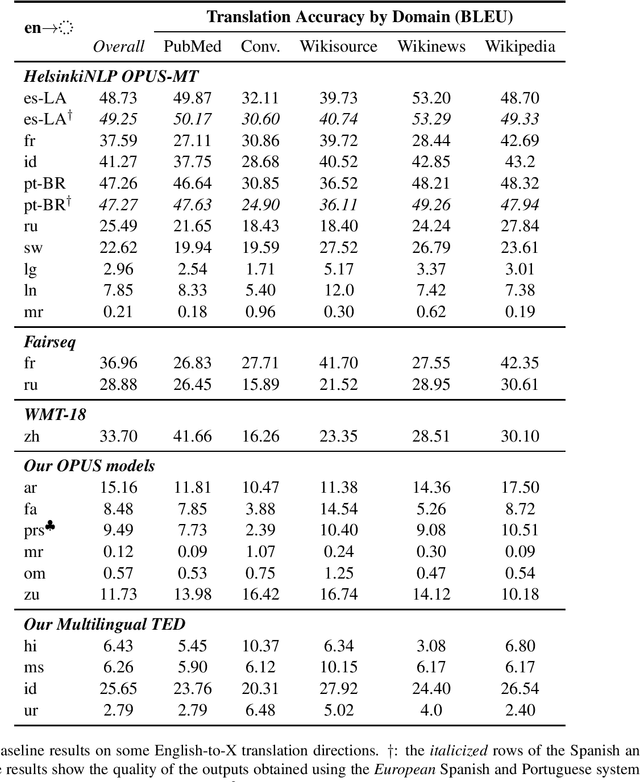
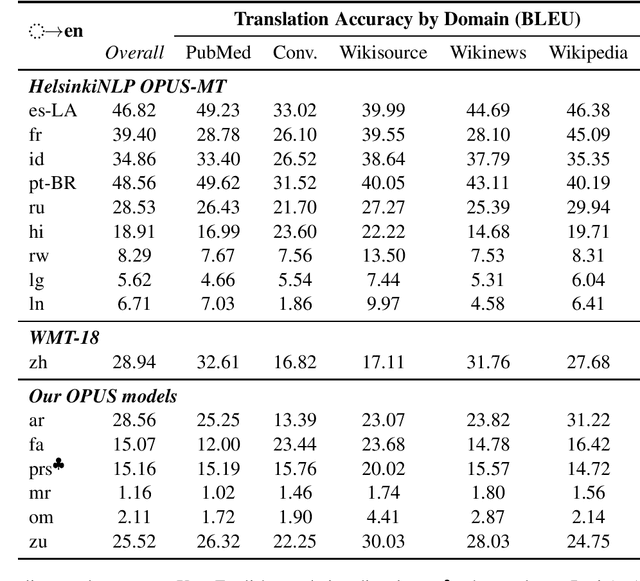
The COVID-19 pandemic is the worst pandemic to strike the world in over a century. Crucial to stemming the tide of the SARS-CoV-2 virus is communicating to vulnerable populations the means by which they can protect themselves. To this end, the collaborators forming the Translation Initiative for COvid-19 (TICO-19) have made test and development data available to AI and MT researchers in 35 different languages in order to foster the development of tools and resources for improving access to information about COVID-19 in these languages. In addition to 9 high-resourced, "pivot" languages, the team is targeting 26 lesser resourced languages, in particular languages of Africa, South Asia and South-East Asia, whose populations may be the most vulnerable to the spread of the virus. The same data is translated into all of the languages represented, meaning that testing or development can be done for any pairing of languages in the set. Further, the team is converting the test and development data into translation memories (TMXs) that can be used by localizers from and to any of the languages.
Simulated Multiple Reference Training Improves Low-Resource Machine Translation
Apr 30, 2020
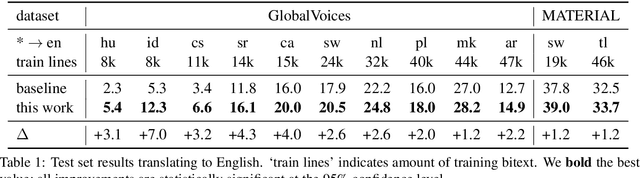
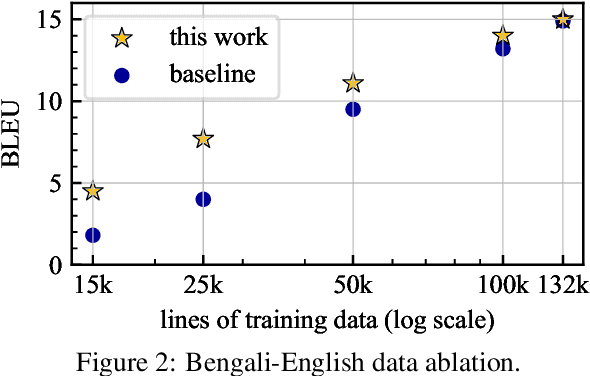
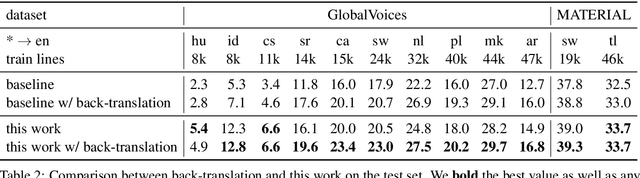
Many valid translations exist for a given sentence, and yet machine translation (MT) is trained with a single reference translation, exacerbating data sparsity in low-resource settings. We introduce a novel MT training method that approximates the full space of possible translations by: sampling a paraphrase of the reference sentence from a paraphraser and training the MT model to predict the paraphraser's distribution over possible tokens. With an English paraphraser, we demonstrate the effectiveness of our method in low-resource settings, with gains of 1.2 to 7 BLEU.
Exploiting Sentence Order in Document Alignment
Apr 30, 2020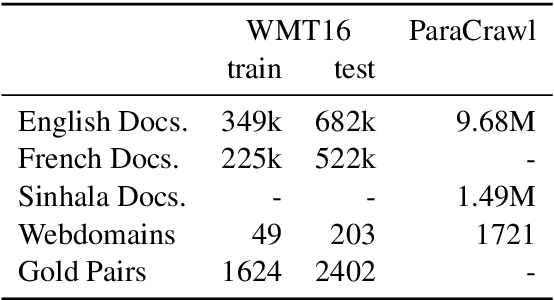
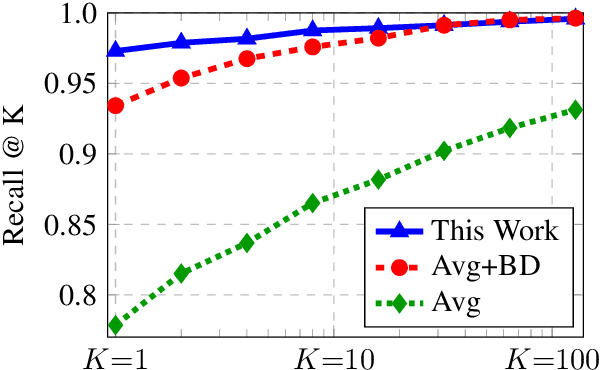
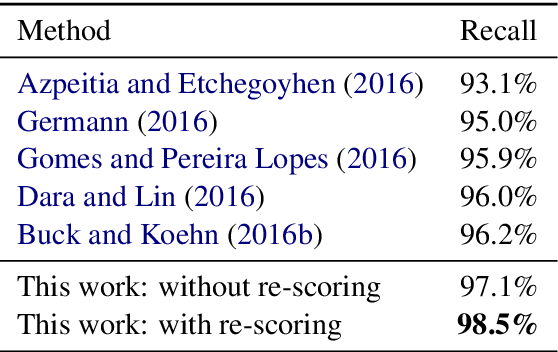
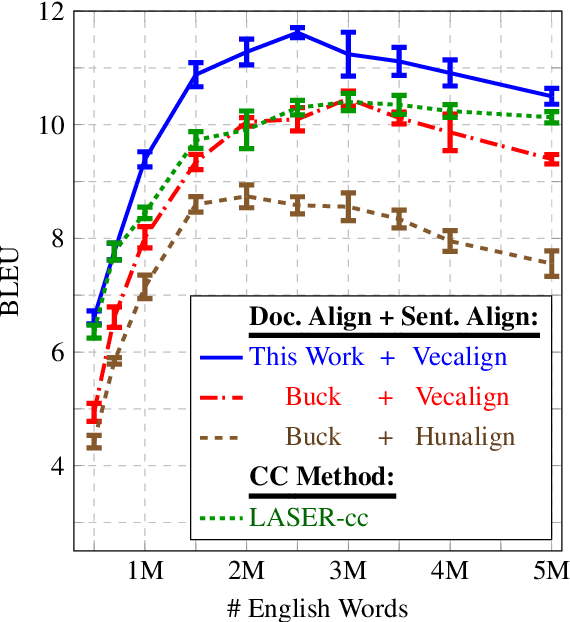
In this work, we exploit the simple idea that a document and its translation should contain approximately the same information, in approximately the same order. We propose methods for both document pair candidate generation and candidate re-scoring which incorporate high-level order information. Our method results in 61% relative reduction in error versus the best previously published result on the WMT16 document alignment shared task. We also apply our method to web-scraped Sinhala-English documents from ParaCrawl and find that our method improves MT performance by 1.2 BLEU over the current ParaCrawl document alignment method.
When Does Unsupervised Machine Translation Work?
Apr 14, 2020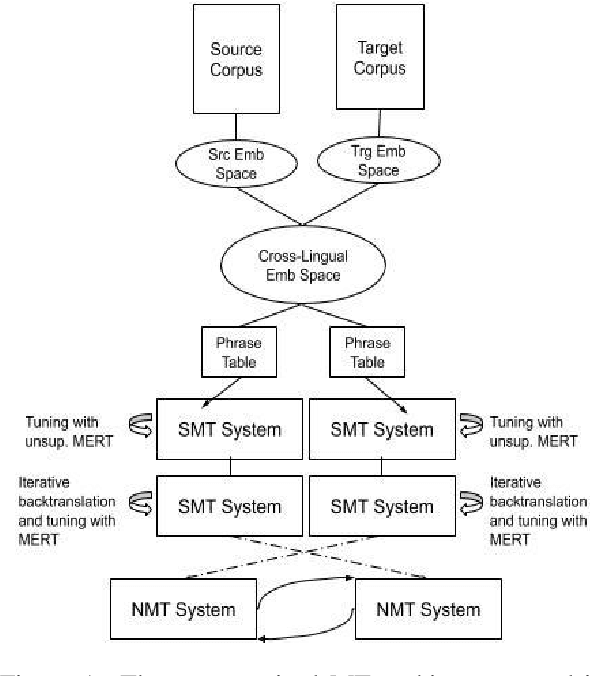
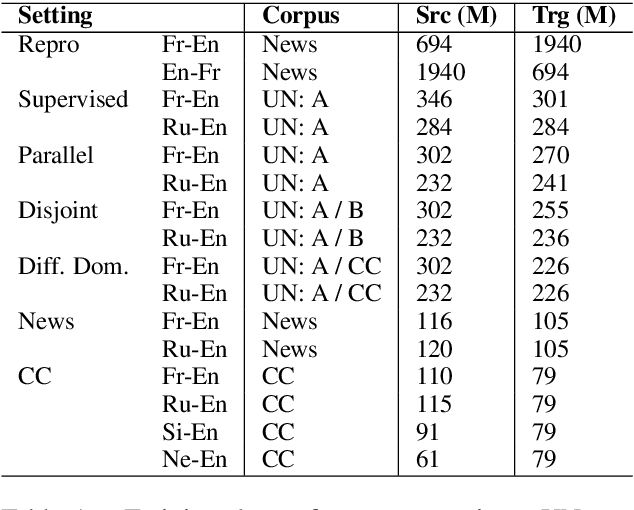
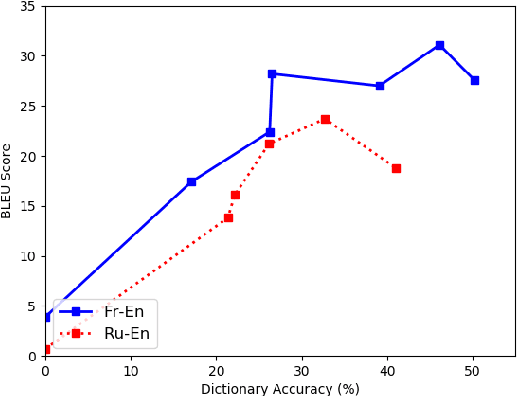

Despite the reported success of unsupervised machine translation (MT), the field has yet to examine the conditions under which these methods succeed, and where they fail. We conduct an extensive empirical evaluation of unsupervised MT using dissimilar language pairs, dissimilar domains, diverse datasets, and authentic low-resource languages. We find that performance rapidly deteriorates when source and target corpora are from different domains, and that random word embedding initialization can dramatically affect downstream translation performance. We additionally find that unsupervised MT performance declines when source and target languages use different scripts, and observe very poor performance on authentic low-resource language pairs. We advocate for extensive empirical evaluation of unsupervised MT systems to highlight failure points and encourage continued research on the most promising paradigms.