 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly-Trained Adversarial Data Augmentation for Neural Machine Translation
Oct 12, 2021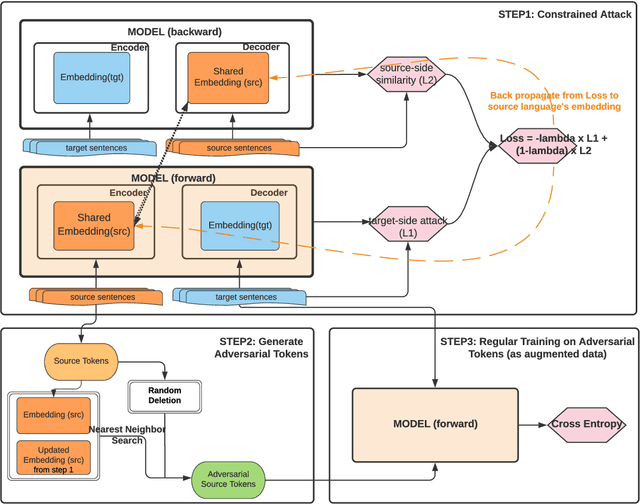

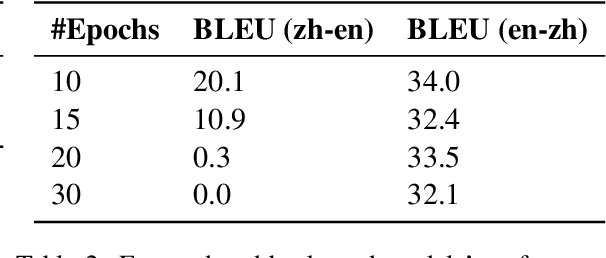
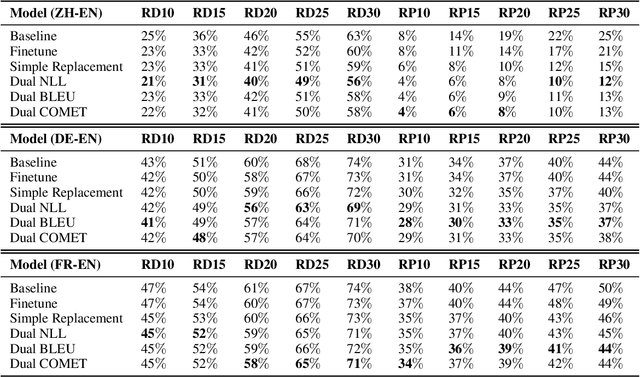
Neural Machine Translation (NMT) models are known to suffer from noisy inputs. To make models robust, we generate adversarial augmentation samples that attack the model and preserve the source-side semantic meaning at the same time. To generate such samples, we propose a doubly-trained architecture that pairs two NMT models of opposite translation directions with a joint loss function, which combines the target-side attack and the source-side semantic similarity constraint. The results from our experiments across three different language pairs and two evaluation metrics show that these adversarial samples improve the model robustness.
An Analysis of Euclidean vs. Graph-Based Framing for Bilingual Lexicon Induction from Word Embedding Spaces
Sep 26, 2021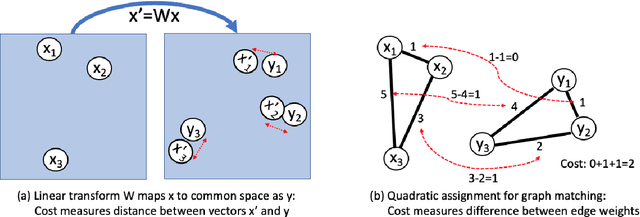

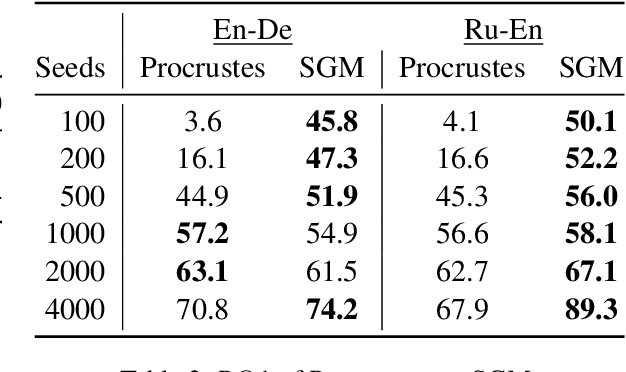
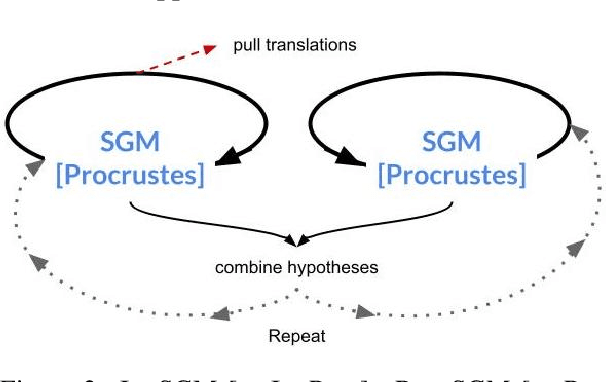
Much recent work in bilingual lexicon induction (BLI) views word embeddings as vectors in Euclidean space. As such, BLI is typically solved by finding a linear transformation that maps embeddings to a common space. Alternatively, word embeddings may be understood as nodes in a weighted graph. This framing allows us to examine a node's graph neighborhood without assuming a linear transform, and exploits new techniques from the graph matching optimization literature. These contrasting approaches have not been compared in BLI so far. In this work, we study the behavior of Euclidean versus graph-based approaches to BLI under differing data conditions and show that they complement each other when combined. We release our code at https://github.com/kellymarchisio/euc-v-graph-bli.
The JHU-Microsoft Submission for WMT21 Quality Estimation Shared Task
Sep 17, 2021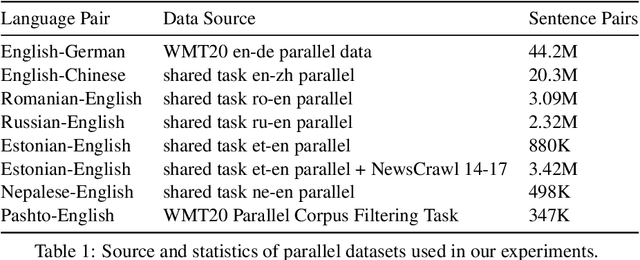
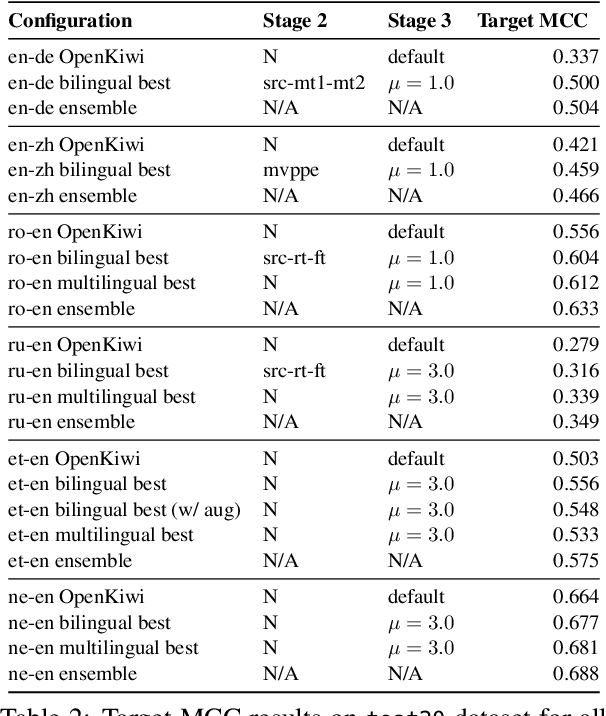
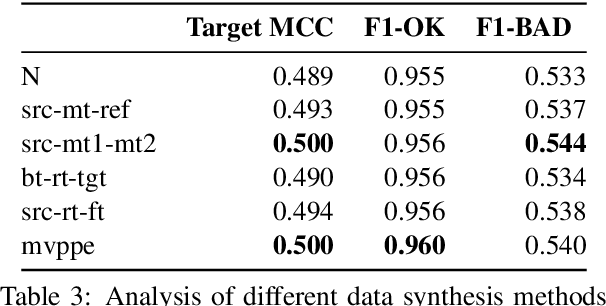
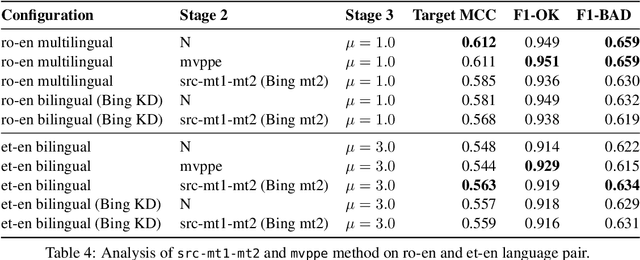
This paper presents the JHU-Microsoft joint submission for WMT 2021 quality estimation shared task. We only participate in Task 2 (post-editing effort estimation) of the shared task, focusing on the target-side word-level quality estimation. The techniques we experimented with include Levenshtein Transformer training and data augmentation with a combination of forward, backward, round-trip translation, and pseudo post-editing of the MT output. We demonstrate the competitiveness of our system compared to the widely adopted OpenKiwi-XLM baseline. Our system is also the top-ranking system on the MT MCC metric for the English-German language pair.
Levenshtein Training for Word-level Quality Estimation
Sep 15, 2021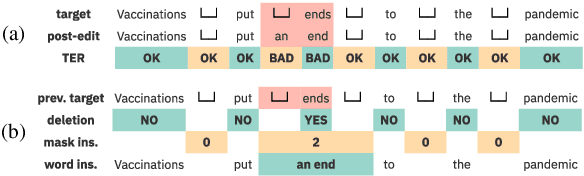
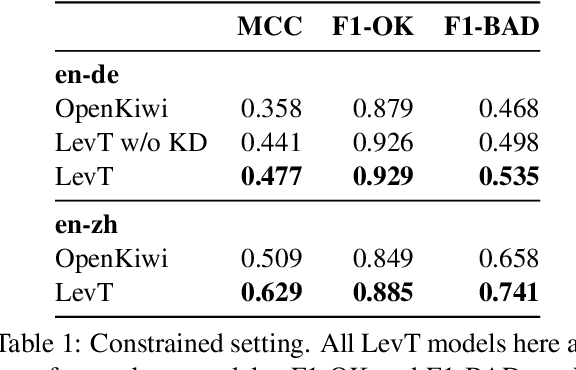
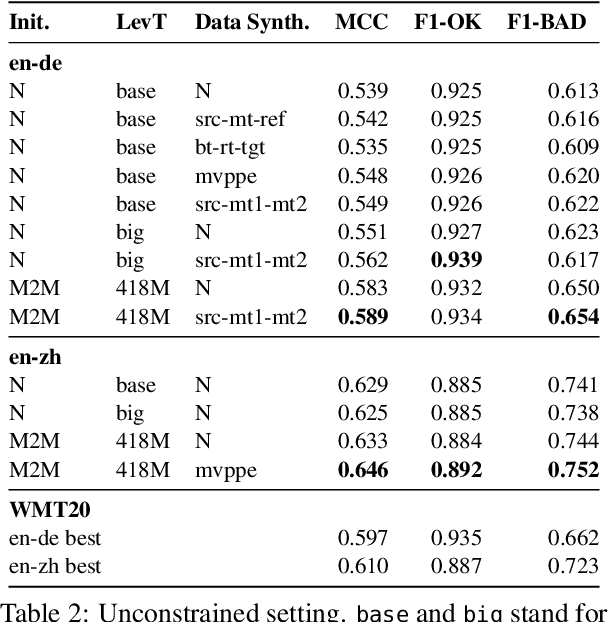
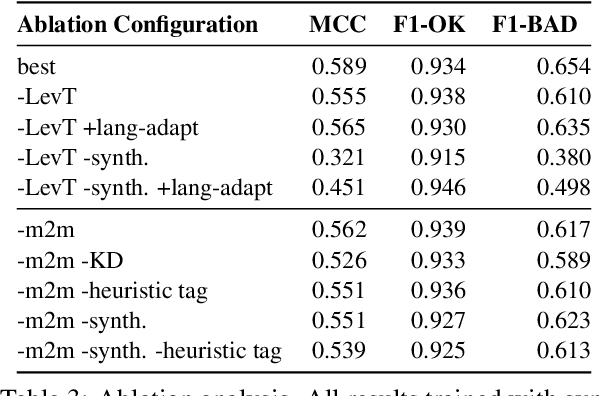
We propose a novel scheme to use the Levenshtein Transformer to perform the task of word-level quality estimation. A Levenshtein Transformer is a natural fit for this task: trained to perform decoding in an iterative manner, a Levenshtein Transformer can learn to post-edit without explicit supervision. To further minimize the mismatch between the translation task and the word-level QE task, we propose a two-stage transfer learning procedure on both augmented data and human post-editing data. We also propose heuristics to construct reference labels that are compatible with subword-level finetuning and inference. Results on WMT 2020 QE shared task dataset show that our proposed method has superior data efficiency under the data-constrained setting and competitive performance under the unconstrained setting.
Facebook AI WMT21 News Translation Task Submission
Aug 06, 2021

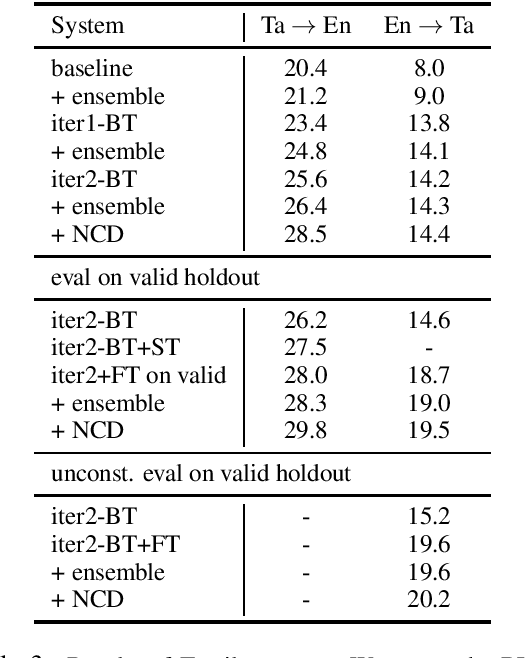
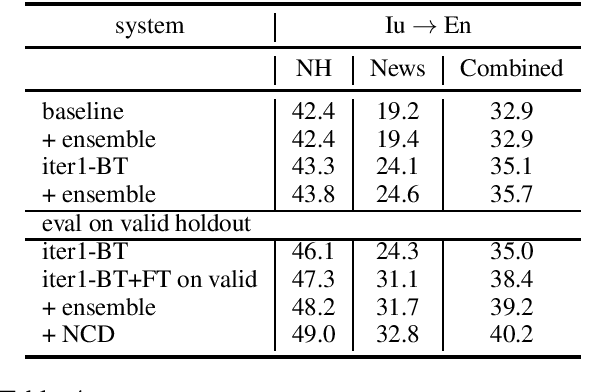
We describe Facebook's multilingual model submission to the WMT2021 shared task on news translation. We participate in 14 language directions: English to and from Czech, German, Hausa, Icelandic, Japanese, Russian, and Chinese. To develop systems covering all these directions, we focus on multilingual models. We utilize data from all available sources --- WMT, large-scale data mining, and in-domain backtranslation --- to create high quality bilingual and multilingual baselines. Subsequently, we investigate strategies for scaling multilingual model size, such that one system has sufficient capacity for high quality representations of all eight languages. Our final submission is an ensemble of dense and sparse Mixture-of-Expert multilingual translation models, followed by finetuning on in-domain news data and noisy channel reranking. Compared to previous year's winning submissions, our multilingual system improved the translation quality on all language directions, with an average improvement of 2.0 BLEU. In the WMT2021 task, our system ranks first in 10 directions based on automatic evaluation.
Cross-Lingual BERT Contextual Embedding Space Mapping with Isotropic and Isometric Conditions
Jul 19, 2021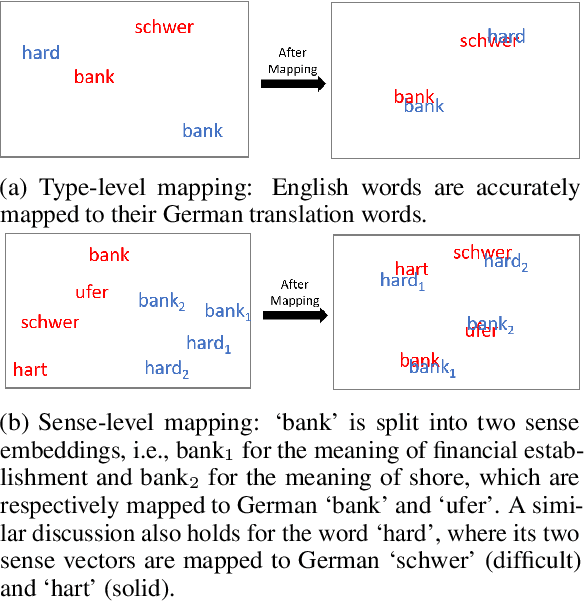
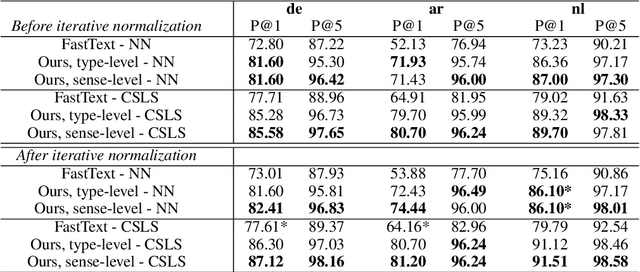

Typically, a linearly orthogonal transformation mapping is learned by aligning static type-level embeddings to build a shared semantic space. In view of the analysis that contextual embeddings contain richer semantic features, we investigate a context-aware and dictionary-free mapping approach by leveraging parallel corpora. We illustrate that our contextual embedding space mapping significantly outperforms previous multilingual word embedding methods on the bilingual dictionary induction (BDI) task by providing a higher degree of isomorphism. To improve the quality of mapping, we also explore sense-level embeddings that are split from type-level representations, which can align spaces in a finer resolution and yield more precise mapping. Moreover, we reveal that contextual embedding spaces suffer from their natural properties -- anisotropy and anisometry. To mitigate these two problems, we introduce the iterative normalization algorithm as an imperative preprocessing step. Our findings unfold the tight relationship between isotropy, isometry, and isomorphism in normalized contextual embedding spaces.
On the Evaluation of Machine Translation for Terminology Consistency
Jun 24, 2021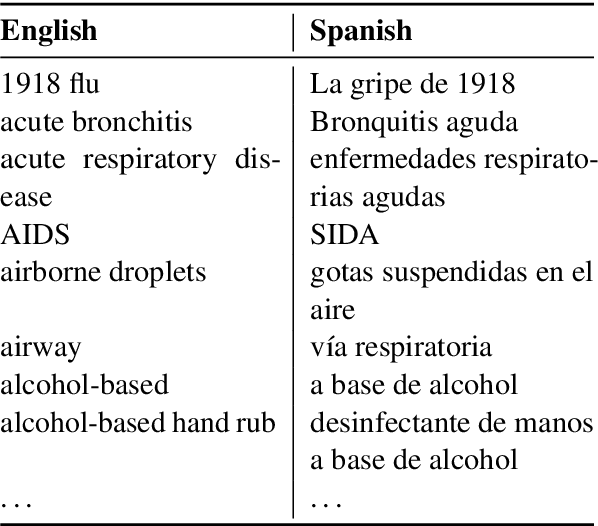
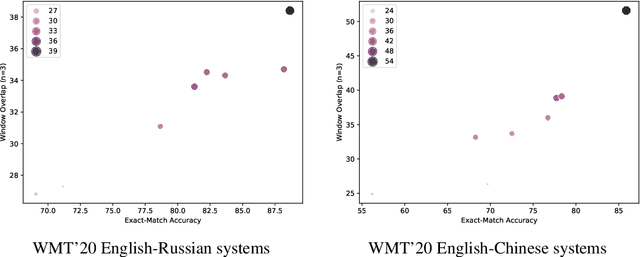

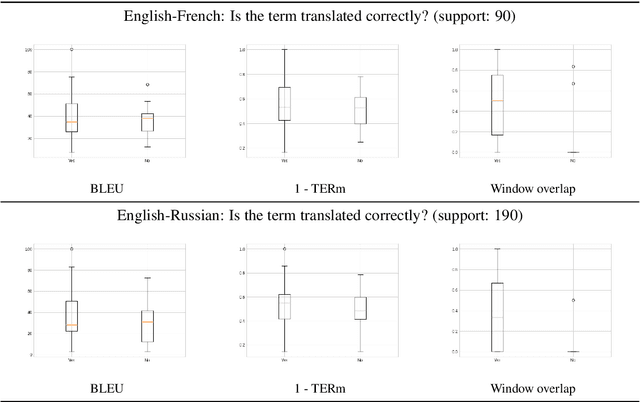
As neural machine translation (NMT) systems become an important part of professional translator pipelines, a growing body of work focuses on combining NMT with terminologies. In many scenarios and particularly in cases of domain adaptation, one expects the MT output to adhere to the constraints provided by a terminology. In this work, we propose metrics to measure the consistency of MT output with regards to a domain terminology. We perform studies on the COVID-19 domain over 5 languages, also performing terminology-targeted human evaluation. We open-source the code for computing all proposed metrics: https://github.com/mahfuzibnalam/terminology_evaluation
Adapting High-resource NMT Models to Translate Low-resource Related Languages without Parallel Data
Jun 02, 2021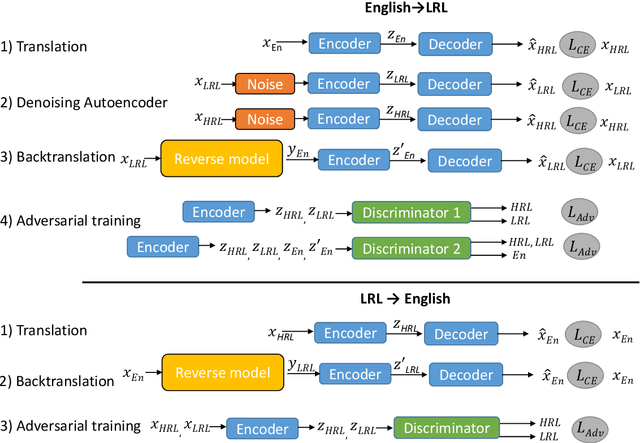
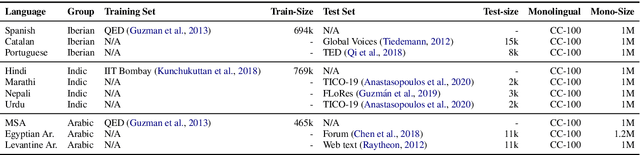
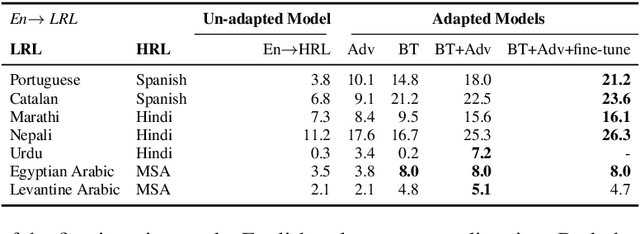
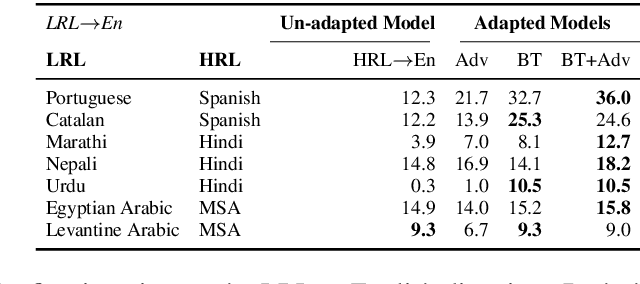
The scarcity of parallel data is a major obstacle for training high-quality machine translation systems for low-resource languages. Fortunately, some low-resource languages are linguistically related or similar to high-resource languages; these related languages may share many lexical or syntactic structures. In this work, we exploit this linguistic overlap to facilitate translating to and from a low-resource language with only monolingual data, in addition to any parallel data in the related high-resource language. Our method, NMT-Adapt, combines denoising autoencoding, back-translation and adversarial objectives to utilize monolingual data for low-resource adaptation. We experiment on 7 languages from three different language families and show that our technique significantly improves translation into low-resource language compared to other translation baselines.
Embedding-Enhanced Giza++: Improving Alignment in Low- and High- Resource Scenarios Using Embedding Space Geometry
Apr 18, 2021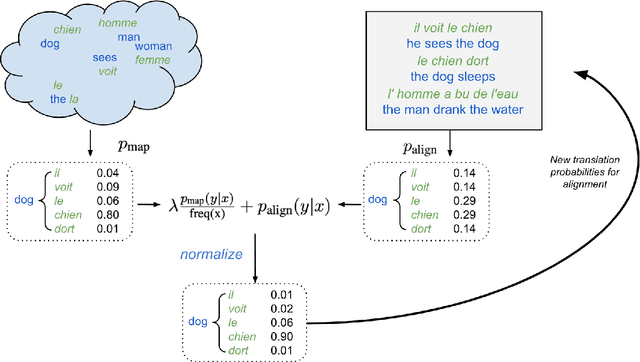
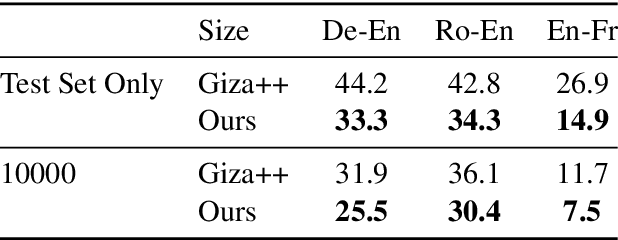
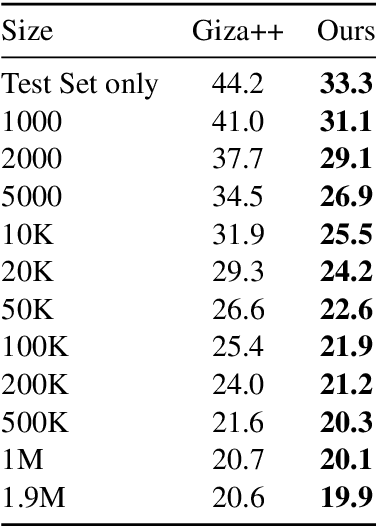
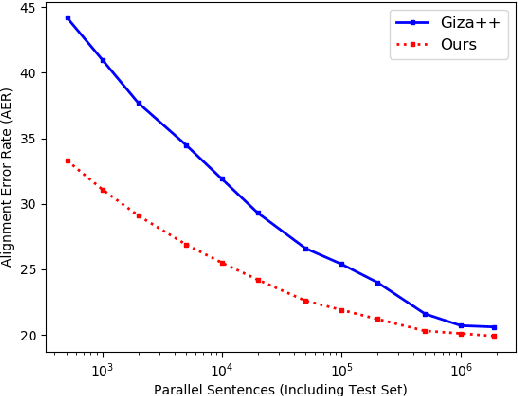
A popular natural language processing task decades ago, word alignment has been dominated until recently by GIZA++, a statistical method based on the 30-year-old IBM models. Though recent years have finally seen Giza++ performance bested, the new methods primarily rely on large machine translation models, massively multilingual language models, or supervision from Giza++ alignments itself. We introduce Embedding-Enhanced Giza++, and outperform Giza++ without any of the aforementioned factors. Taking advantage of monolingual embedding space geometry of the source and target language only, we exceed Giza++'s performance in every tested scenario for three languages. In the lowest-resource scenario of only 500 lines of bitext, we improve performance over Giza++ by 10.9 AER. Our method scales monotonically outperforming Giza++ for all tested scenarios between 500 and 1.9 million lines of bitext. Our code will be made publicly available.
XLEnt: Mining a Large Cross-lingual Entity Dataset with Lexical-Semantic-Phonetic Word Alignment
Apr 17, 2021
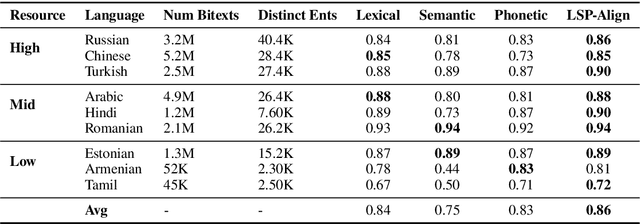
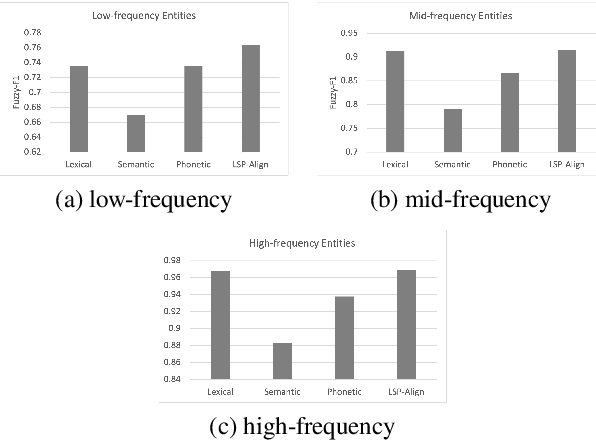
Cross-lingual named-entity lexicon are an important resource to multilingual NLP tasks such as machine translation and cross-lingual wikification. While knowledge bases contain a large number of entities in high-resource languages such as English and French, corresponding entities for lower-resource languages are often missing. To address this, we propose Lexical-Semantic-Phonetic Align (LSP-Align), a technique to automatically mine cross-lingual entity lexicon from the web. We demonstrate LSP-Align outperforms baselines at extracting cross-lingual entity pairs and mine 164 million entity pairs from 120 different languages aligned with English. We release these cross-lingual entity pairs along with the massively multilingual tagged named entity corpus as a resource to the NLP community.