 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust bilinear factor analysis based on the matrix-variate $t$ distribution
Jan 04, 2024



Factor Analysis based on multivariate $t$ distribution ($t$fa) is a useful robust tool for extracting common factors on heavy-tailed or contaminated data. However, $t$fa is only applicable to vector data. When $t$fa is applied to matrix data, it is common to first vectorize the matrix observations. This introduces two challenges for $t$fa: (i) the inherent matrix structure of the data is broken, and (ii) robustness may be lost, as vectorized matrix data typically results in a high data dimension, which could easily lead to the breakdown of $t$fa. To address these issues, starting from the intrinsic matrix structure of matrix data, a novel robust factor analysis model, namely bilinear factor analysis built on the matrix-variate $t$ distribution ($t$bfa), is proposed in this paper. The novelty is that it is capable to simultaneously extract common factors for both row and column variables of interest on heavy-tailed or contaminated matrix data. Two efficient algorithms for maximum likelihood estimation of $t$bfa are developed. Closed-form expression for the Fisher information matrix to calculate the accuracy of parameter estimates are derived. Empirical studies are conducted to understand the proposed $t$bfa model and compare with related competitors. The results demonstrate the superiority and practicality of $t$bfa. Importantly, $t$bfa exhibits a significantly higher breakdown point than $t$fa, making it more suitable for matrix data.
Choosing the number of factors in factor analysis with incomplete data via a hierarchical Bayesian information criterion
Apr 19, 2022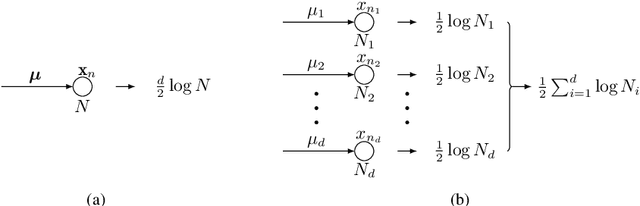
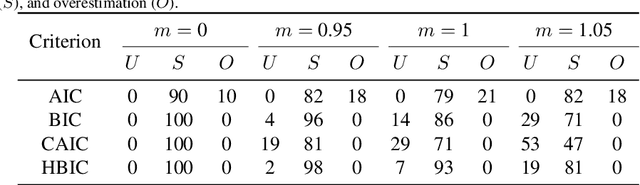
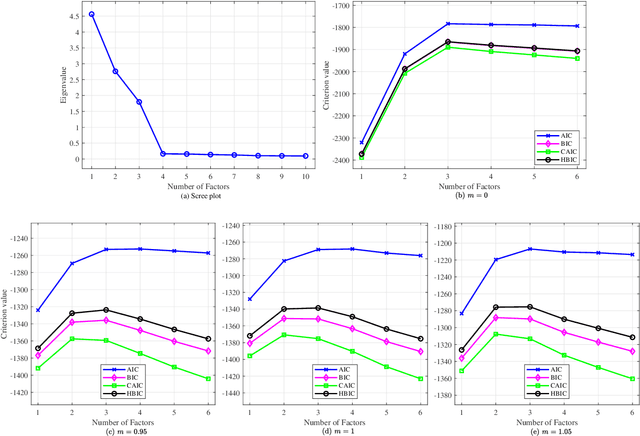
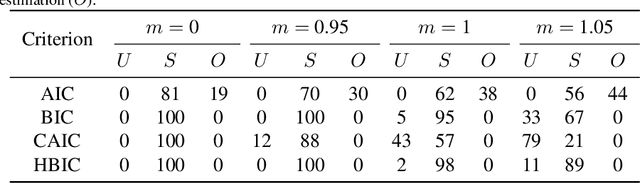
The Bayesian information criterion (BIC), defined as the observed data log likelihood minus a penalty term based on the sample size $N$, is a popular model selection criterion for factor analysis with complete data. This definition has also been suggested for incomplete data. However, the penalty term based on the `complete' sample size $N$ is the same no matter whether in a complete or incomplete data case. For incomplete data, there are often only $N_i<N$ observations for variable $i$, which means that using the `complete' sample size $N$ implausibly ignores the amounts of missing information inherent in incomplete data. Given this observation, a novel criterion called hierarchical BIC (HBIC) for factor analysis with incomplete data is proposed. The novelty is that it only uses the actual amounts of observed information, namely $N_i$'s, in the penalty term. Theoretically, it is shown that HBIC is a large sample approximation of variational Bayesian (VB) lower bound, and BIC is a further approximation of HBIC, which means that HBIC shares the theoretical consistency of BIC. Experiments on synthetic and real data sets are conducted to access the finite sample performance of HBIC, BIC, and related criteria with various missing rates. The results show that HBIC and BIC perform similarly when the missing rate is small, but HBIC is more accurate when the missing rate is not small.
Dual-Attention Enhanced BDense-UNet for Liver Lesion Segmentation
Jul 24, 2021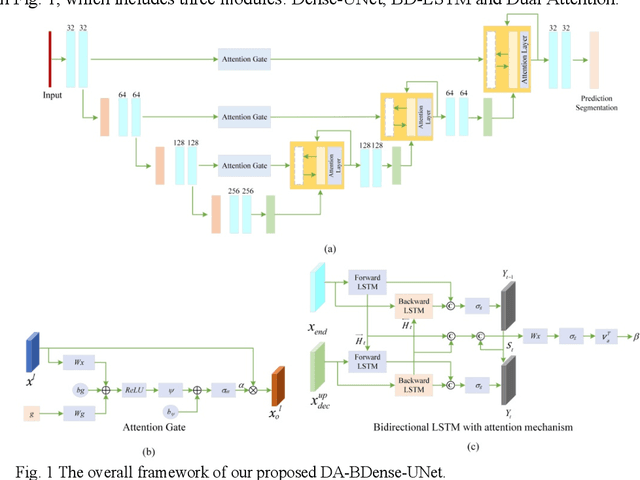
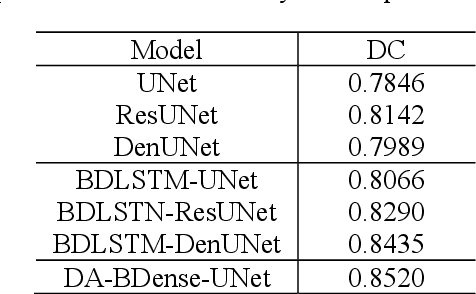
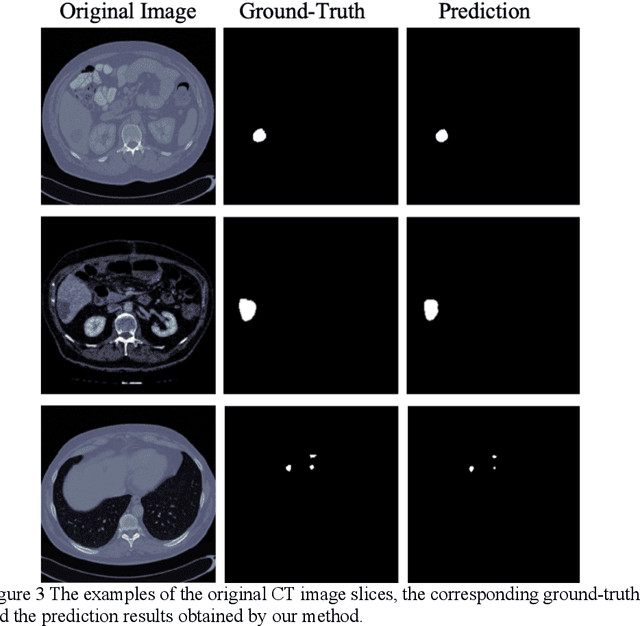
In this work, we propose a new segmentation network by integrating DenseUNet and bidirectional LSTM together with attention mechanism, termed as DA-BDense-UNet. DenseUNet allows learning enough diverse features and enhancing the representative power of networks by regulating the information flow. Bidirectional LSTM is responsible to explore the relationships between the encoded features and the up-sampled features in the encoding and decoding paths. Meanwhile, we introduce attention gates (AG) into DenseUNet to diminish responses of unrelated background regions and magnify responses of salient regions progressively. Besides, the attention in bidirectional LSTM takes into account the contribution differences of the encoded features and the up-sampled features in segmentation improvement, which can in turn adjust proper weights for these two kinds of features. We conduct experiments on liver CT image data sets collected from multiple hospitals by comparing them with state-of-the-art segmentation models. Experimental results indicate that our proposed method DA-BDense-UNet has achieved comparative performance in terms of dice coefficient, which demonstrates its effectiveness.
CNN-based Realized Covariance Matrix Forecasting
Jul 22, 2021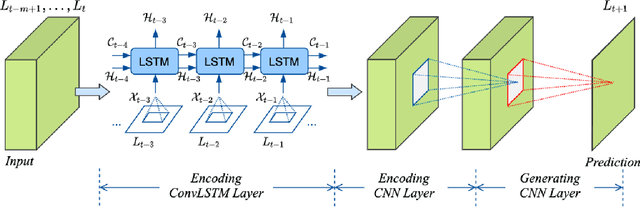
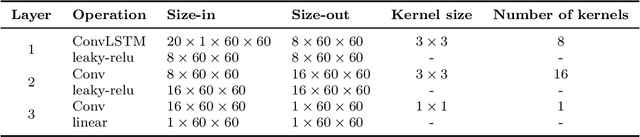
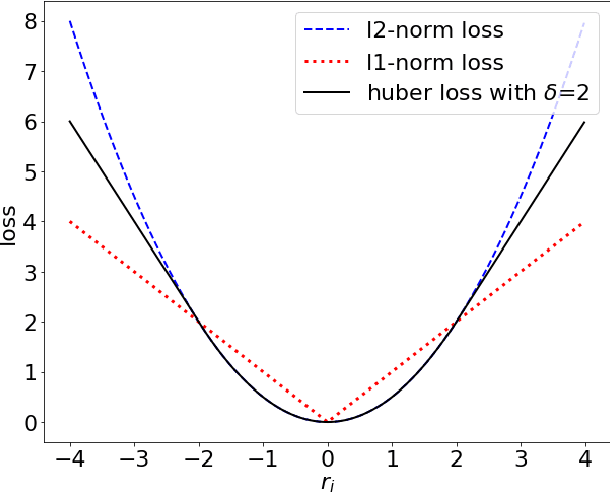
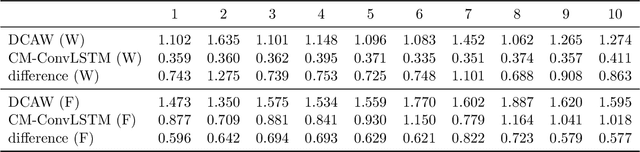
It is well known that modeling and forecasting realized covariance matrices of asset returns play a crucial role in the field of finance. The availability of high frequency intraday data enables the modeling of the realized covariance matrices directly. However, most of the models available in the literature depend on strong structural assumptions and they often suffer from the curse of dimensionality. We propose an end-to-end trainable model built on the CNN and Convolutional LSTM (ConvLSTM) which does not require to make any distributional or structural assumption but could handle high-dimensional realized covariance matrices consistently. The proposed model focuses on local structures and spatiotemporal correlations. It learns a nonlinear mapping that connect the historical realized covariance matrices to the future one. Our empirical studies on synthetic and real-world datasets demonstrate its excellent forecasting ability compared with several advanced volatility models.
AutoBERT-Zero: Evolving BERT Backbone from Scratch
Jul 15, 2021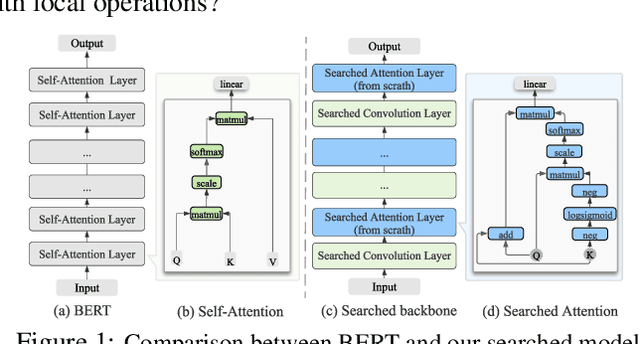

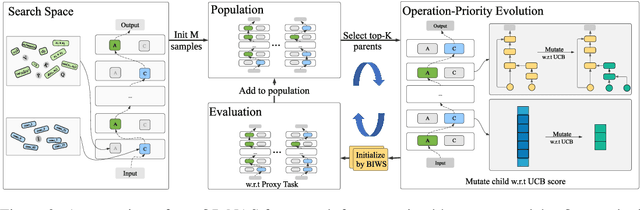
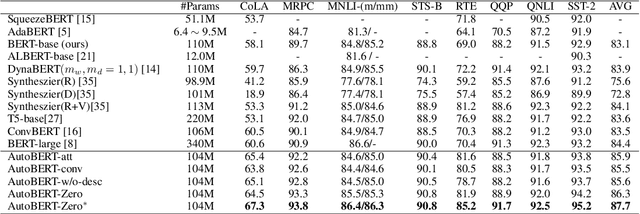
Transformer-based pre-trained language models like BERT and its variants have recently achieved promising performance in various natural language processing (NLP) tasks. However, the conventional paradigm constructs the backbone by purely stacking the manually designed global self-attention layers, introducing inductive bias and thus leading to sub-optimal. In this work, we propose an Operation-Priority Neural Architecture Search (OP-NAS) algorithm to automatically search for promising hybrid backbone architectures. Our well-designed search space (i) contains primitive math operations in the intra-layer level to explore novel attention structures, and (ii) leverages convolution blocks to be the supplementary for attention structure in the inter-layer level to better learn local dependency. We optimize both the search algorithm and evaluation of candidate models to boost the efficiency of our proposed OP-NAS. Specifically, we propose Operation-Priority (OP) evolution strategy to facilitate model search via balancing exploration and exploitation. Furthermore, we design a Bi-branch Weight-Sharing (BIWS) training strategy for fast model evaluation. Extensive experiments show that the searched architecture (named AutoBERT-Zero) significantly outperforms BERT and its variants of different model capacities in various downstream tasks, proving the architecture's transfer and generalization abilities. Remarkably, AutoBERT-Zero-base outperforms RoBERTa-base (using much more data) and BERT-large (with much larger model size) by 2.4 and 1.4 higher score on GLUE test set. Code and pre-trained models will be made publicly available.
Unsupervised Cross-lingual Image Captioning
Oct 03, 2020


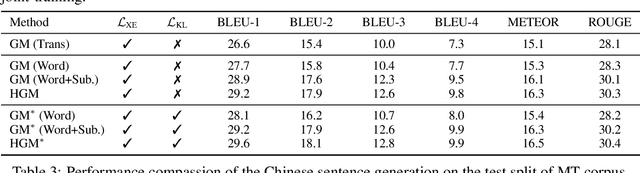
Most recent image captioning works are conducted in English as the majority of image-caption datasets are in English. However, there are a large amount of non-native English speakers worldwide. Generating image captions in different languages is worth exploring. In this paper, we present a novel unsupervised method to generate image captions without using any caption corpus. Our method relies on 1) a cross-lingual auto-encoding, which learns the scene graph mapping function along with the scene graph encoders and sentence decoders on machine translation parallel corpora, and 2) an unsupervised feature mapping, which seeks to map the encoded scene graph features from image modality to sentence modality. By leveraging cross-lingual auto-encoding, cross-modal feature mapping, and adversarial learning, our method can learn an image captioner to generate captions in different languages. We verify the effectiveness of our proposed method on the Chinese image caption generation. The comparisons against several baseline methods demonstrate the effectiveness of our approach.
Automated Computer Evaluation of Acute Ischemic Stroke and Large Vessel Occlusion
Jun 18, 2019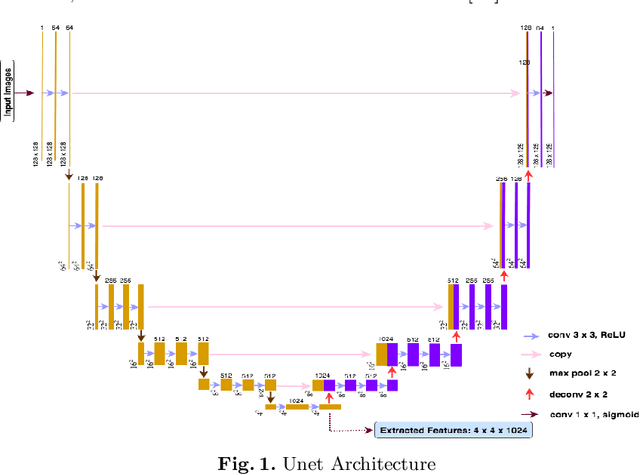
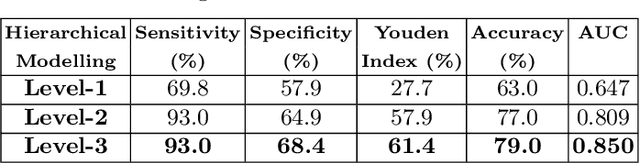
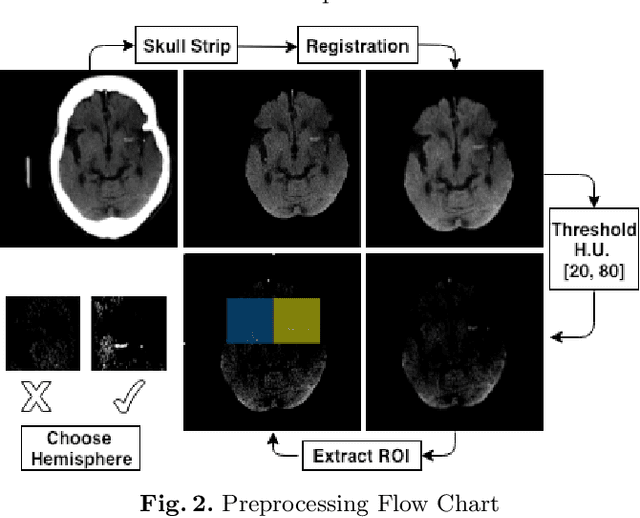
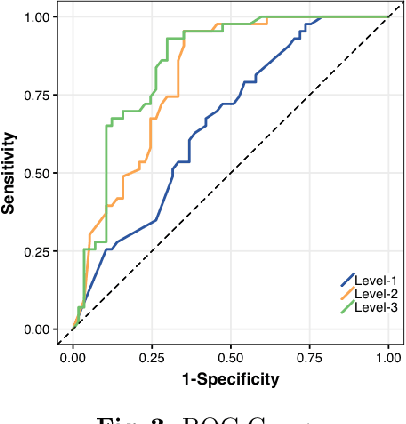
Large vessel occlusion (LVO) plays an important role in the diagnosis of acute ischemic stroke. Identifying LVO of patients in the early stage on admission would significantly lower the probabilities of suffering from severe effects due to stroke or even save their lives. In this paper, we utilized both structural and imaging data from all recorded acute ischemic stroke patients in Hong Kong. Total 300 patients (200 training and 100 testing) are used in this study. We established three hierarchical models based on demographic data, clinical data and features obtained from computerized tomography (CT) scans. The first two stages of modeling are merely based on demographic and clinical data. Besides, the third model utilized extra CT imaging features obtained from deep learning model. The optimal cutoff is determined at the maximal Youden index based on 10-fold cross-validation. With both clinical and imaging features, the Level-3 model achieved the best performance on testing data. The sensitivity, specificity, Youden index, accuracy and area under the curve (AUC) are 0.930, 0.684, 0.614, 0.790 and 0.850 respectively.
Automated Segmentation for Hyperdense Middle Cerebral Artery Sign of Acute Ischemic Stroke on Non-Contrast CT Images
May 22, 2019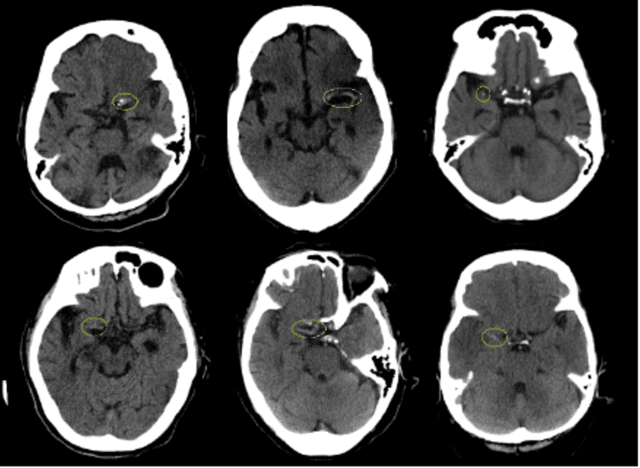

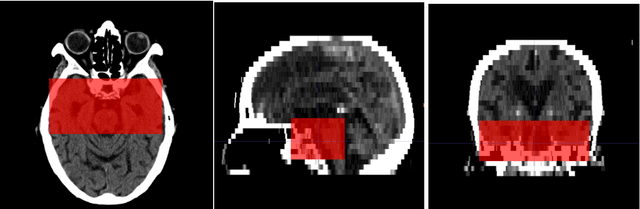
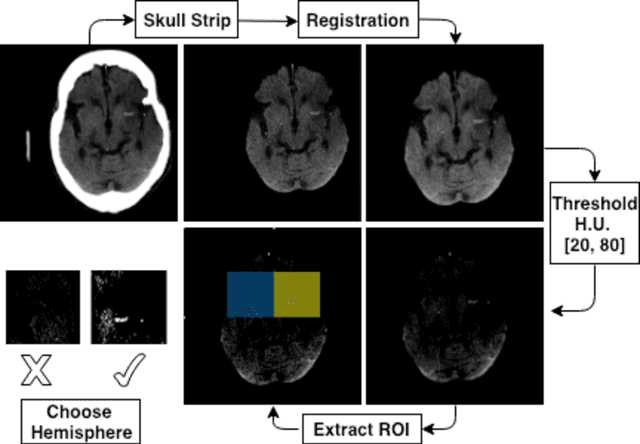
The hyperdense middle cerebral artery (MCA) dot sign has been reported as an important factor in the diagnosis of acute ischemic stroke due to large vessel occlusion. Interpreting the initial CT brain scan in these patients requires high level of expertise, and has high inter-observer variability. An automated computerized interpretation of the urgent CT brain image, with an emphasis to pick up early signs of ischemic stroke will facilitate early patient diagnosis, triage, and shorten the door-to-revascularization time for these group of patients. In this paper, we present an automated detection method of segmenting the MCA dot sign on non-contrast CT brain image scans based on powerful deep learning technique.
Neural Machine Translation with External Phrase Memory
Jun 06, 2016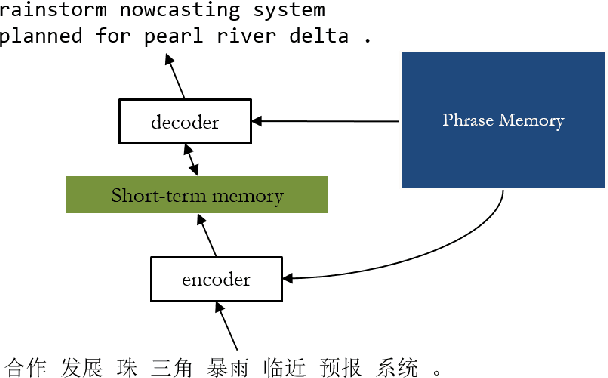
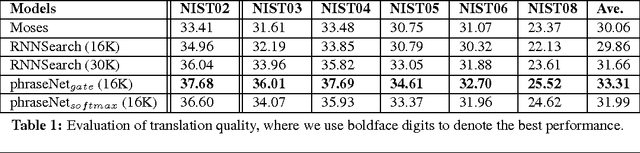

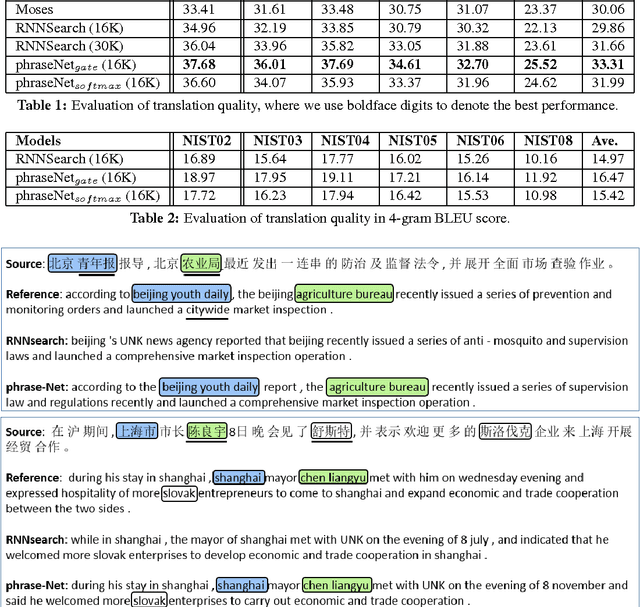
In this paper, we propose phraseNet, a neural machine translator with a phrase memory which stores phrase pairs in symbolic form, mined from corpus or specified by human experts. For any given source sentence, phraseNet scans the phrase memory to determine the candidate phrase pairs and integrates tagging information in the representation of source sentence accordingly. The decoder utilizes a mixture of word-generating component and phrase-generating component, with a specifically designed strategy to generate a sequence of multiple words all at once. The phraseNet not only approaches one step towards incorporating external knowledge into neural machine translation, but also makes an effort to extend the word-by-word generation mechanism of recurrent neural network. Our empirical study on Chinese-to-English translation shows that, with carefully-chosen phrase table in memory, phraseNet yields 3.45 BLEU improvement over the generic neural machine translator.