 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD5RL: Diverse Datasets for Data-Driven Deep Reinforcement Learning
Aug 15, 2024



Offline reinforcement learning algorithms hold the promise of enabling data-driven RL methods that do not require costly or dangerous real-world exploration and benefit from large pre-collected datasets. This in turn can facilitate real-world applications, as well as a more standardized approach to RL research. Furthermore, offline RL methods can provide effective initializations for online finetuning to overcome challenges with exploration. However, evaluating progress on offline RL algorithms requires effective and challenging benchmarks that capture properties of real-world tasks, provide a range of task difficulties, and cover a range of challenges both in terms of the parameters of the domain (e.g., length of the horizon, sparsity of rewards) and the parameters of the data (e.g., narrow demonstration data or broad exploratory data). While considerable progress in offline RL in recent years has been enabled by simpler benchmark tasks, the most widely used datasets are increasingly saturating in performance and may fail to reflect properties of realistic tasks. We propose a new benchmark for offline RL that focuses on realistic simulations of robotic manipulation and locomotion environments, based on models of real-world robotic systems, and comprising a variety of data sources, including scripted data, play-style data collected by human teleoperators, and other data sources. Our proposed benchmark covers state-based and image-based domains, and supports both offline RL and online fine-tuning evaluation, with some of the tasks specifically designed to require both pre-training and fine-tuning. We hope that our proposed benchmark will facilitate further progress on both offline RL and fine-tuning algorithms. Website with code, examples, tasks, and data is available at \url{https://sites.google.com/view/d5rl/}
Same State, Different Task: Continual Reinforcement Learning without Interference
Jun 05, 2021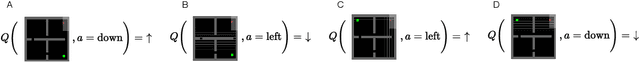



Continual Learning (CL) considers the problem of training an agent sequentially on a set of tasks while seeking to retain performance on all previous tasks. A key challenge in CL is catastrophic forgetting, which arises when performance on a previously mastered task is reduced when learning a new task. While a variety of methods exist to combat forgetting, in some cases tasks are fundamentally incompatible with each other and thus cannot be learnt by a single policy. This can occur, in reinforcement learning (RL) when an agent may be rewarded for achieving different goals from the same observation. In this paper we formalize this ``interference'' as distinct from the problem of forgetting. We show that existing CL methods based on single neural network predictors with shared replay buffers fail in the presence of interference. Instead, we propose a simple method, OWL, to address this challenge. OWL learns a factorized policy, using shared feature extraction layers, but separate heads, each specializing on a new task. The separate heads in OWL are used to prevent interference. At test time, we formulate policy selection as a multi-armed bandit problem, and show it is possible to select the best policy for an unknown task using feedback from the environment. The use of bandit algorithms allows the OWL agent to constructively re-use different continually learnt policies at different times during an episode. We show in multiple RL environments that existing replay based CL methods fail, while OWL is able to achieve close to optimal performance when training sequentially.
On Optimism in Model-Based Reinforcement Learning
Jun 21, 2020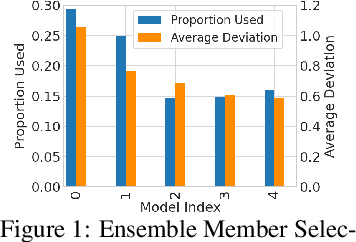
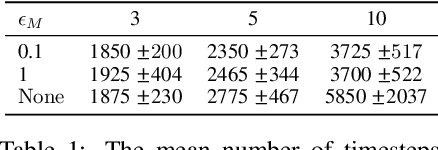
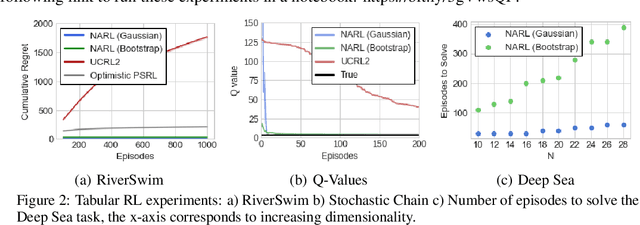
The principle of optimism in the face of uncertainty is prevalent throughout sequential decision making problems such as multi-armed bandits and reinforcement learning (RL), often coming with strong theoretical guarantees. However, it remains a challenge to scale these approaches to the deep RL paradigm, which has achieved a great deal of attention in recent years. In this paper, we introduce a tractable approach to optimism via noise augmented Markov Decision Processes (MDPs), which we show can obtain a competitive regret bound: $\tilde{\mathcal{O}}( |\mathcal{S}|H\sqrt{|\mathcal{S}||\mathcal{A}| T } )$ when augmenting using Gaussian noise, where $T$ is the total number of environment steps. This tractability allows us to apply our approach to the deep RL setting, where we rigorously evaluate the key factors for success of optimistic model-based RL algorithms, bridging the gap between theory and practice.
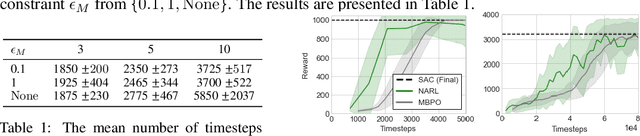
Ready Policy One: World Building Through Active Learning
Feb 07, 2020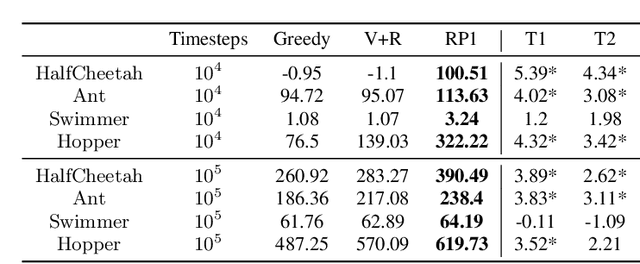
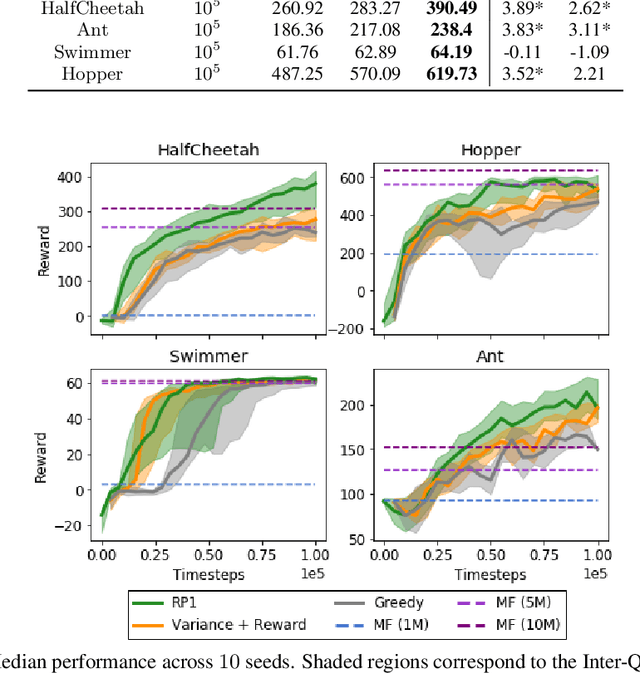
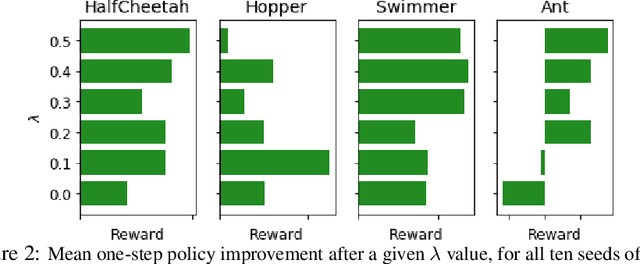

Model-Based Reinforcement Learning (MBRL) offers a promising direction for sample efficient learning, often achieving state of the art results for continuous control tasks. However, many existing MBRL methods rely on combining greedy policies with exploration heuristics, and even those which utilize principled exploration bonuses construct dual objectives in an ad hoc fashion. In this paper we introduce Ready Policy One (RP1), a framework that views MBRL as an active learning problem, where we aim to improve the world model in the fewest samples possible. RP1 achieves this by utilizing a hybrid objective function, which crucially adapts during optimization, allowing the algorithm to trade off reward v.s. exploration at different stages of learning. In addition, we introduce a principled mechanism to terminate sample collection once we have a rich enough trajectory batch to improve the model. We rigorously evaluate our method on a variety of continuous control tasks, and demonstrate statistically significant gains over existing approaches.