 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPPL: Adaptive Planner Parameter Learning
May 17, 2021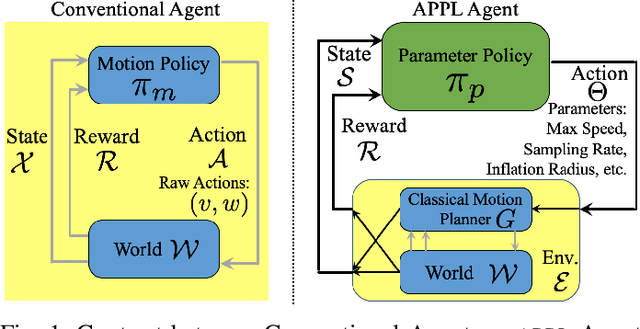

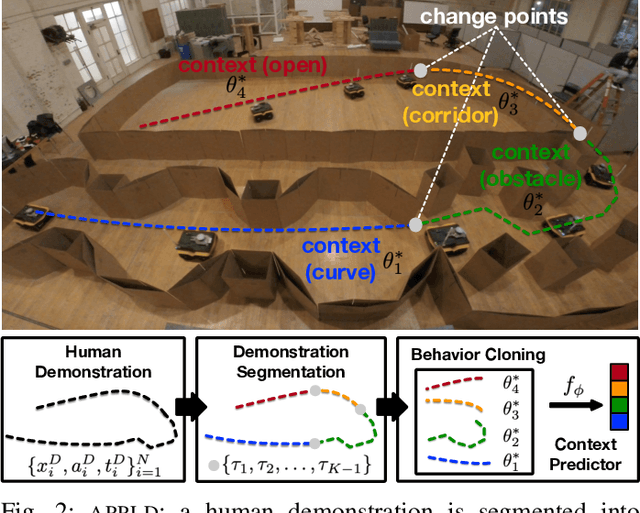
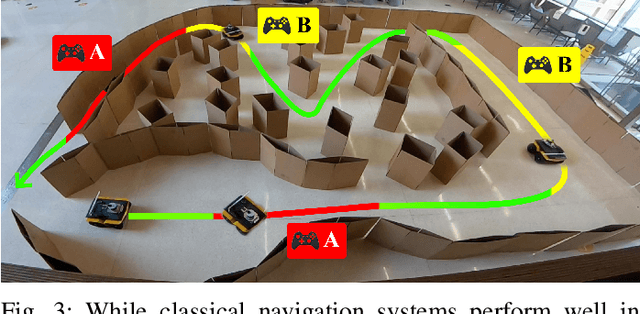
While current autonomous navigation systems allow robots to successfully drive themselves from one point to another in specific environments, they typically require extensive manual parameter re-tuning by human robotics experts in order to function in new environments. Furthermore, even for just one complex environment, a single set of fine-tuned parameters may not work well in different regions of that environment. These problems prohibit reliable mobile robot deployment by non-expert users. As a remedy, we propose Adaptive Planner Parameter Learning (APPL), a machine learning framework that can leverage non-expert human interaction via several modalities -- including teleoperated demonstrations, corrective interventions, and evaluative feedback -- and also unsupervised reinforcement learning to learn a parameter policy that can dynamically adjust the parameters of classical navigation systems in response to changes in the environment. APPL inherits safety and explainability from classical navigation systems while also enjoying the benefits of machine learning, i.e., the ability to adapt and improve from experience. We present a suite of individual APPL methods and also a unifying cycle-of-learning scheme that combines all the proposed methods in a framework that can improve navigation performance through continual, iterative human interaction and simulation training.
RAIL: A modular framework for Reinforcement-learning-based Adversarial Imitation Learning
May 08, 2021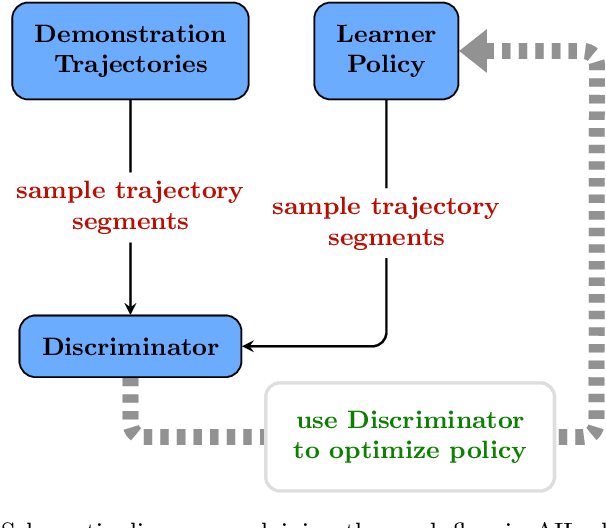
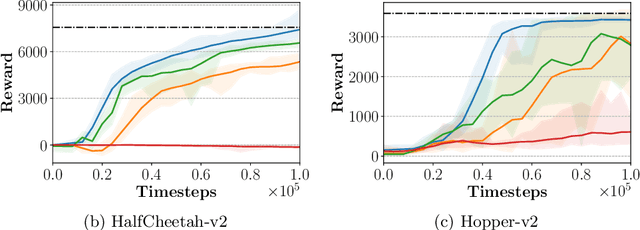

While Adversarial Imitation Learning (AIL) algorithms have recently led to state-of-the-art results on various imitation learning benchmarks, it is unclear as to what impact various design decisions have on performance. To this end, we present here an organizing, modular framework called Reinforcement-learning-based Adversarial Imitation Learning (RAIL) that encompasses and generalizes a popular subclass of existing AIL approaches. Using the view espoused by RAIL, we create two new IfO (Imitation from Observation) algorithms, which we term SAIfO: SAC-based Adversarial Imitation from Observation and SILEM (Skeletal Feature Compensation for Imitation Learning with Embodiment Mismatch). We go into greater depth about SILEM in a separate technical report. In this paper, we focus on SAIfO, evaluating it on a suite of locomotion tasks from OpenAI Gym, and showing that it outperforms contemporaneous RAIL algorithms that perform IfO.
Team Orienteering Coverage Planning with Uncertain Reward
May 08, 2021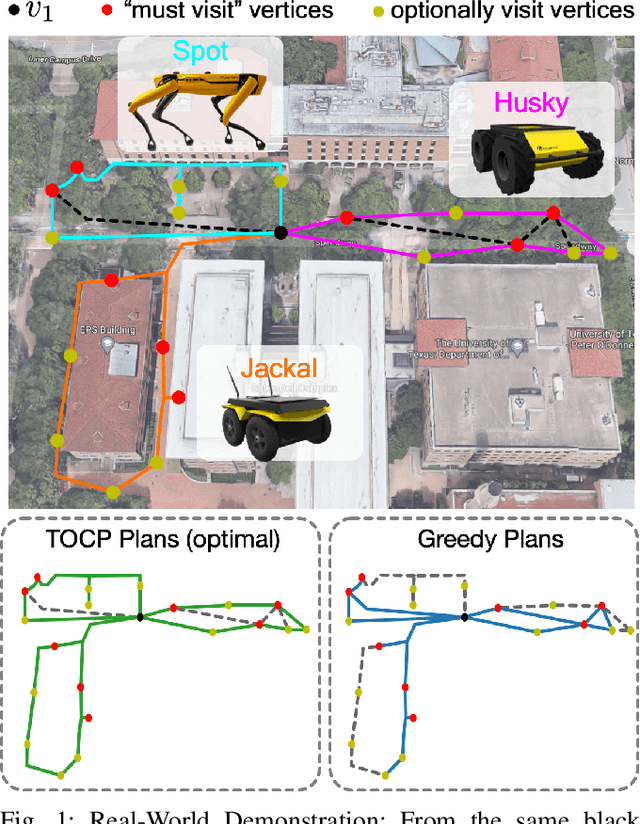
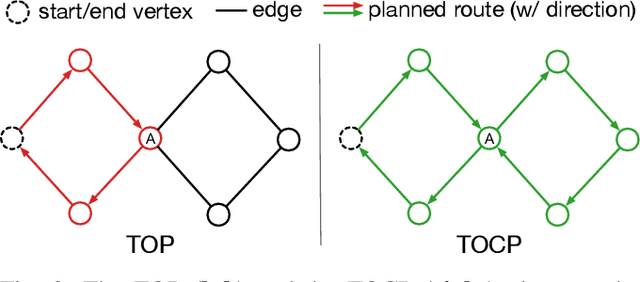
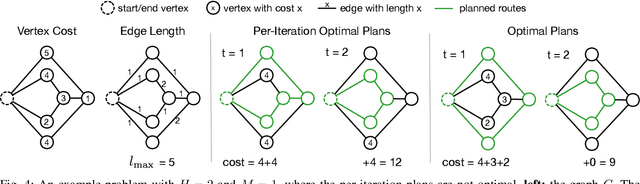
Many municipalities and large organizations have fleets of vehicles that need to be coordinated for tasks such as garbage collection or infrastructure inspection. Motivated by this need, this paper focuses on the common subproblem in which a team of vehicles needs to plan coordinated routes to patrol an area over iterations while minimizing temporally and spatially dependent costs. In particular, at a specific location (e.g., a vertex on a graph), we assume the cost grows linearly in expectation with an unknown rate, and the cost is reset to zero whenever any vehicle visits the vertex (representing the robot servicing the vertex). We formulate this problem in graph terminology and call it Team Orienteering Coverage Planning with Uncertain Reward (TOCPUR). We propose to solve TOCPUR by simultaneously estimating the accumulated cost at every vertex on the graph and solving a novel variant of the Team Orienteering Problem (TOP) iteratively, which we call the Team Orienteering Coverage Problem (TOCP). We provide the first mixed integer programming formulation for the TOCP, as a significant adaptation of the original TOP. We introduce a new benchmark consisting of hundreds of randomly generated graphs for comparing different methods. We show the proposed solution outperforms both the exact TOP solution and a greedy algorithm. In addition, we provide a demo of our method on a team of three physical robots in a real-world environment.
Reward (Mis)design for Autonomous Driving
Apr 28, 2021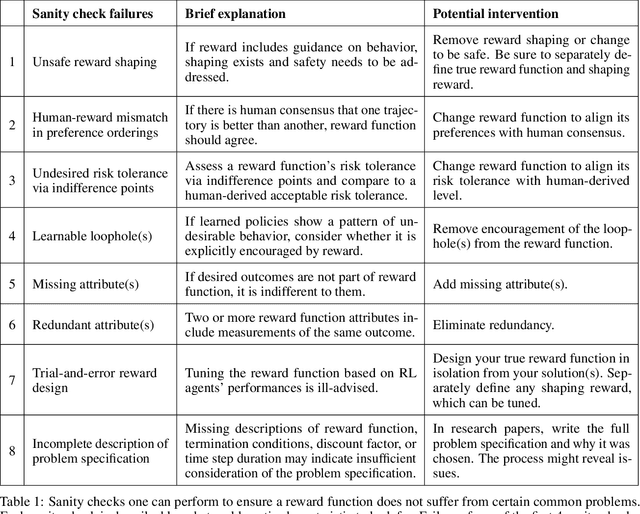
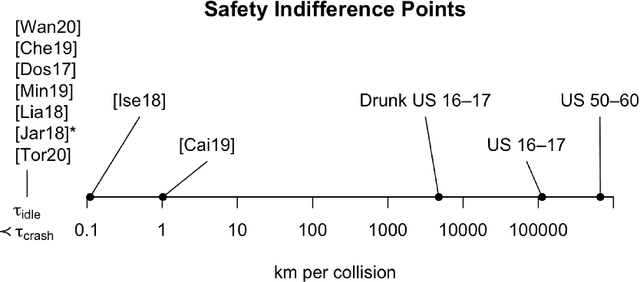
This paper considers the problem of reward design for autonomous driving (AD), with insights that are also applicable to the design of cost functions and performance metrics more generally. Herein we develop 8 simple sanity checks for identifying flaws in reward functions. The sanity checks are applied to reward functions from past work on reinforcement learning (RL) for autonomous driving, revealing near-universal flaws in reward design for AD that might also exist pervasively across reward design for other tasks. Lastly, we explore promising directions that may help future researchers design reward functions for AD.
Skeletal Feature Compensation for Imitation Learning with Embodiment Mismatch
Apr 15, 2021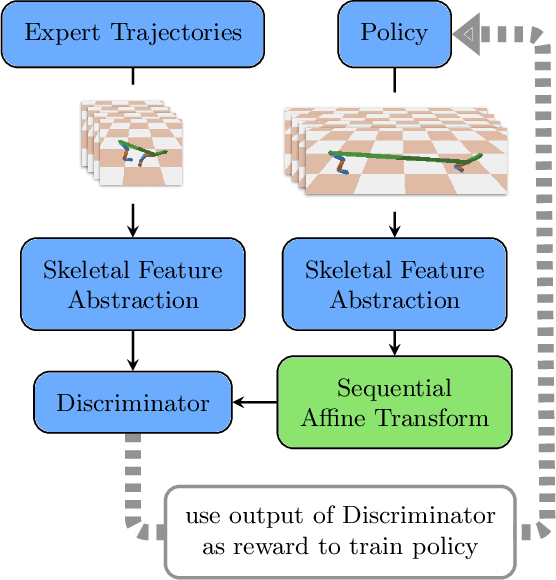

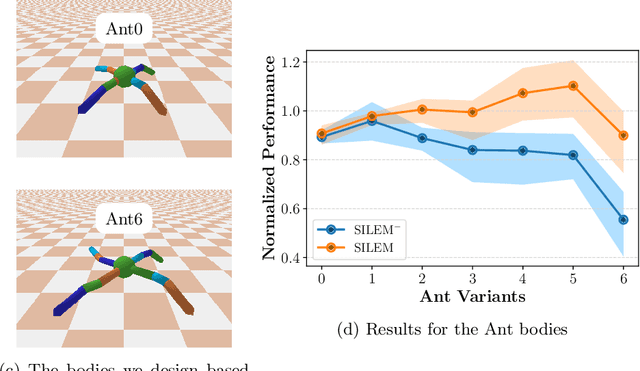
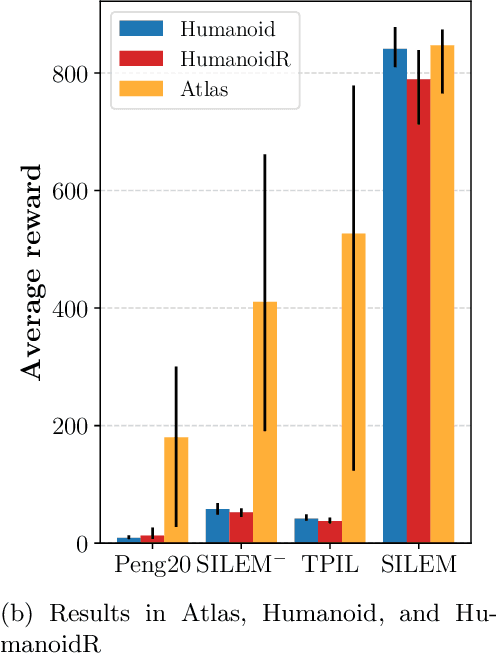
Learning from demonstrations in the wild (e.g. YouTube videos) is a tantalizing goal in imitation learning. However, for this goal to be achieved, imitation learning algorithms must deal with the fact that the demonstrators and learners may have bodies that differ from one another. This condition -- "embodiment mismatch" -- is ignored by many recent imitation learning algorithms. Our proposed imitation learning technique, SILEM (\textbf{S}keletal feature compensation for \textbf{I}mitation \textbf{L}earning with \textbf{E}mbodiment \textbf{M}ismatch), addresses a particular type of embodiment mismatch by introducing a learned affine transform to compensate for differences in the skeletal features obtained from the learner and expert. We create toy domains based on PyBullet's HalfCheetah and Ant to assess SILEM's benefits for this type of embodiment mismatch. We also provide qualitative and quantitative results on more realistic problems -- teaching simulated humanoid agents, including Atlas from Boston Dynamics, to walk by observing human demonstrations.
Sequential Online Chore Division for Autonomous Vehicle Convoy Formation
Apr 09, 2021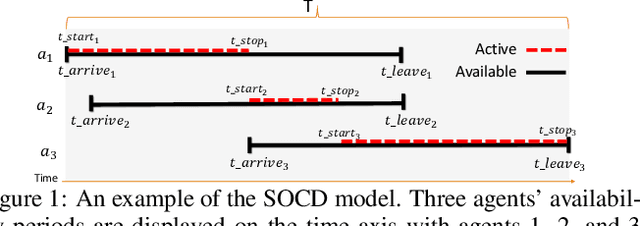
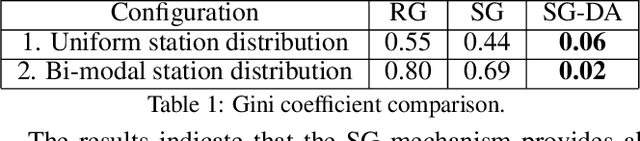
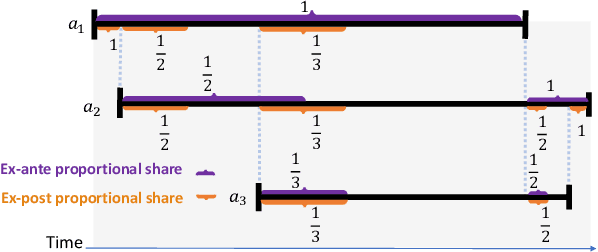
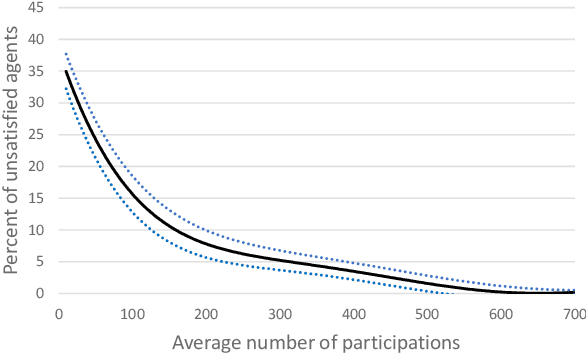
Chore division is a class of fair division problems in which some undesirable "resource" must be shared among a set of participants, with each participant wanting to get as little as possible. Typically the set of participants is fixed and known at the outset. This paper introduces a novel variant, called sequential online chore division (SOCD), in which participants arrive and depart online, while the chore is being performed: both the total number of participants and their arrival/departure times are initially unknown. In SOCD, exactly one agent must be performing the chore at any give time (e.g. keeping lookout), and switching the performer incurs a cost. In this paper, we propose and analyze three mechanisms for SOCD: one centralized mechanism using side payments, and two distributed ones that seek to balance the participants' loads. Analysis and results are presented in a domain motivated by autonomous vehicle convoy formation, where the chore is leading the convoy so that all followers can enjoy reduced wind resistance.
DEALIO: Data-Efficient Adversarial Learning for Imitation from Observation
Mar 31, 2021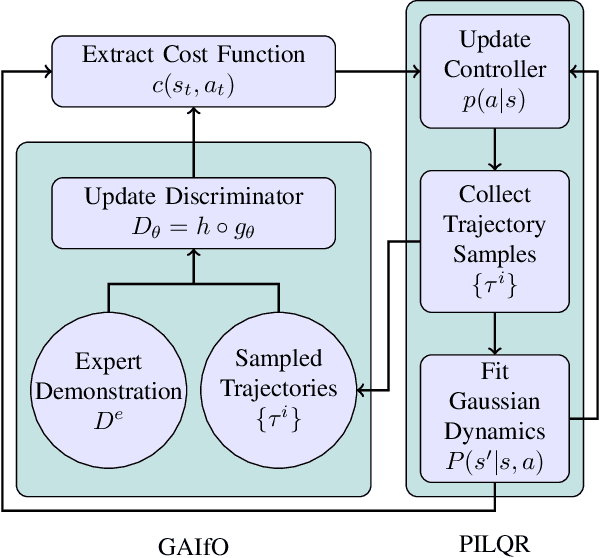
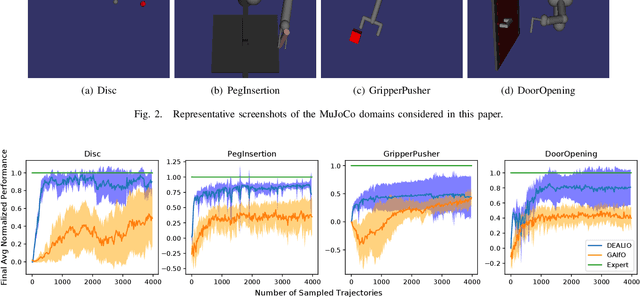
In imitation learning from observation IfO, a learning agent seeks to imitate a demonstrating agent using only observations of the demonstrated behavior without access to the control signals generated by the demonstrator. Recent methods based on adversarial imitation learning have led to state-of-the-art performance on IfO problems, but they typically suffer from high sample complexity due to a reliance on data-inefficient, model-free reinforcement learning algorithms. This issue makes them impractical to deploy in real-world settings, where gathering samples can incur high costs in terms of time, energy, and risk. In this work, we hypothesize that we can incorporate ideas from model-based reinforcement learning with adversarial methods for IfO in order to increase the data efficiency of these methods without sacrificing performance. Specifically, we consider time-varying linear Gaussian policies, and propose a method that integrates the linear-quadratic regulator with path integral policy improvement into an existing adversarial IfO framework. The result is a more data-efficient IfO algorithm with better performance, which we show empirically in four simulation domains: using far fewer interactions with the environment, the proposed method exhibits similar or better performance than the existing technique.
A Scavenger Hunt for Service Robots
Mar 29, 2021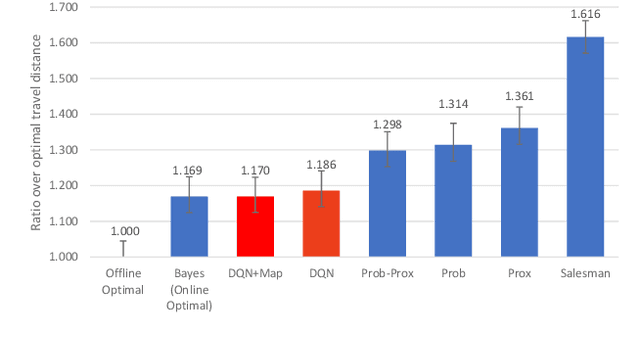
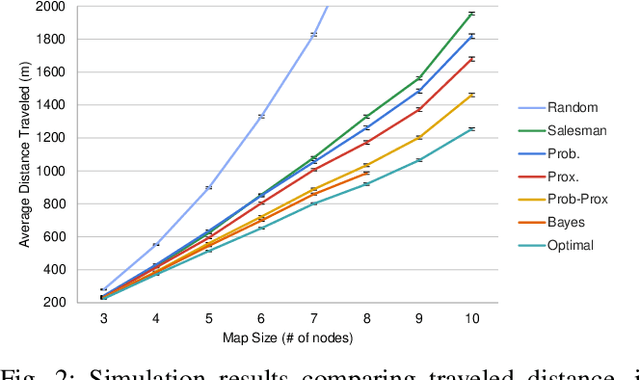
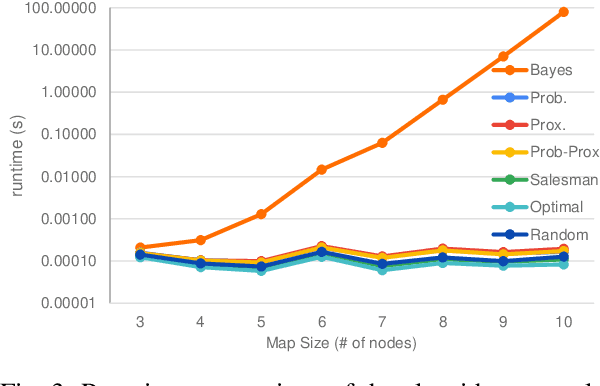
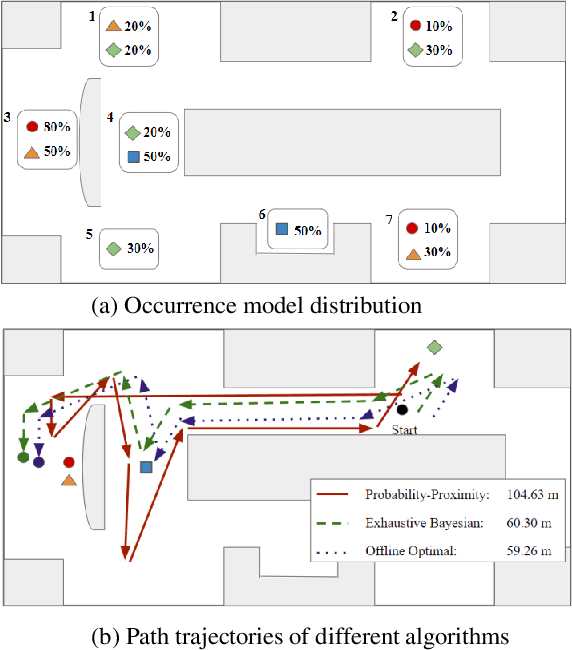
Creating robots that can perform general-purpose service tasks in a human-populated environment has been a longstanding grand challenge for AI and Robotics research. One particularly valuable skill that is relevant to a wide variety of tasks is the ability to locate and retrieve objects upon request. This paper models this skill as a Scavenger Hunt (SH) game, which we formulate as a variation of the NP-hard stochastic traveling purchaser problem. In this problem, the goal is to find a set of objects as quickly as possible, given probability distributions of where they may be found. We investigate the performance of several solution algorithms for the SH problem, both in simulation and on a real mobile robot. We use Reinforcement Learning (RL) to train an agent to plan a minimal cost path, and show that the RL agent can outperform a range of heuristic algorithms, achieving near optimal performance. In order to stimulate research on this problem, we introduce a publicly available software stack and associated website that enable users to upload scavenger hunts which robots can download, perform, and learn from to continually improve their performance on future hunts.
* 6 pages + references + Appendix
Expected Value of Communication for Planning in Ad Hoc Teamwork
Mar 01, 2021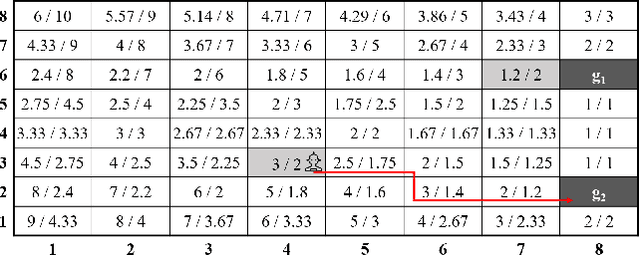

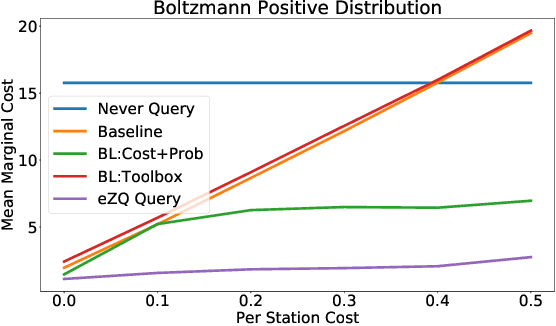
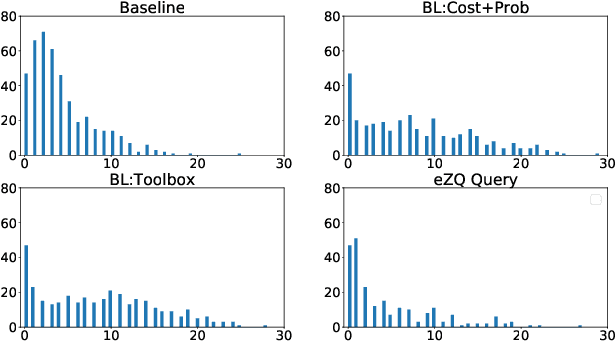
A desirable goal for autonomous agents is to be able to coordinate on the fly with previously unknown teammates. Known as "ad hoc teamwork", enabling such a capability has been receiving increasing attention in the research community. One of the central challenges in ad hoc teamwork is quickly recognizing the current plans of other agents and planning accordingly. In this paper, we focus on the scenario in which teammates can communicate with one another, but only at a cost. Thus, they must carefully balance plan recognition based on observations vs. that based on communication. This paper proposes a new metric for evaluating how similar are two policies that a teammate may be following - the Expected Divergence Point (EDP). We then present a novel planning algorithm for ad hoc teamwork, determining which query to ask and planning accordingly. We demonstrate the effectiveness of this algorithm in a range of increasingly general communication in ad hoc teamwork problems.
Scalable Multiagent Driving Policies For Reducing Traffic Congestion
Feb 26, 2021

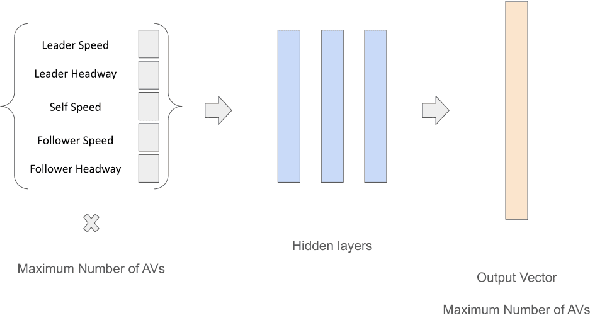

Traffic congestion is a major challenge in modern urban settings. The industry-wide development of autonomous and automated vehicles (AVs) motivates the question of how can AVs contribute to congestion reduction. Past research has shown that in small scale mixed traffic scenarios with both AVs and human-driven vehicles, a small fraction of AVs executing a controlled multiagent driving policy can mitigate congestion. In this paper, we scale up existing approaches and develop new multiagent driving policies for AVs in scenarios with greater complexity. We start by showing that a congestion metric used by past research is manipulable in open road network scenarios where vehicles dynamically join and leave the road. We then propose using a different metric that is robust to manipulation and reflects open network traffic efficiency. Next, we propose a modular transfer reinforcement learning approach, and use it to scale up a multiagent driving policy to outperform human-like traffic and existing approaches in a simulated realistic scenario, which is an order of magnitude larger than past scenarios (hundreds instead of tens of vehicles). Additionally, our modular transfer learning approach saves up to 80% of the training time in our experiments, by focusing its data collection on key locations in the network. Finally, we show for the first time a distributed multiagent policy that improves congestion over human-driven traffic. The distributed approach is more realistic and practical, as it relies solely on existing sensing and actuation capabilities, and does not require adding new communication infrastructure.