 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Empirical Privacy Estimation for Federated Learning
Feb 08, 2023



Privacy auditing techniques for differentially private (DP) algorithms are useful for estimating the privacy loss to compare against analytical bounds, or empirically measure privacy in settings where known analytical bounds on the DP loss are not tight. However, existing privacy auditing techniques usually make strong assumptions on the adversary (e.g., knowledge of intermediate model iterates or the training data distribution), are tailored to specific tasks and model architectures, and require retraining the model many times (typically on the order of thousands). These shortcomings make deploying such techniques at scale difficult in practice, especially in federated settings where model training can take days or weeks. In this work, we present a novel "one-shot" approach that can systematically address these challenges, allowing efficient auditing or estimation of the privacy loss of a model during the same, single training run used to fit model parameters. Our privacy auditing method for federated learning does not require a priori knowledge about the model architecture or task. We show that our method provides provably correct estimates for privacy loss under the Gaussian mechanism, and we demonstrate its performance on a well-established FL benchmark dataset under several adversarial models.
Histogram Estimation under User-level Privacy with Heterogeneous Data
Jun 07, 2022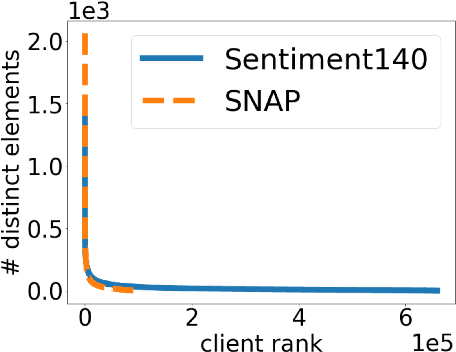
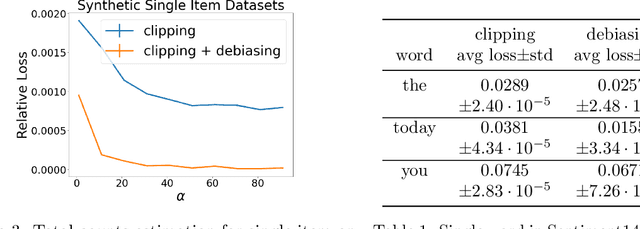
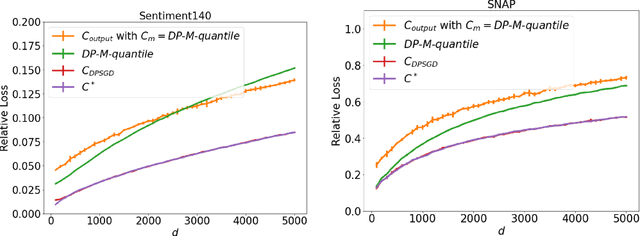
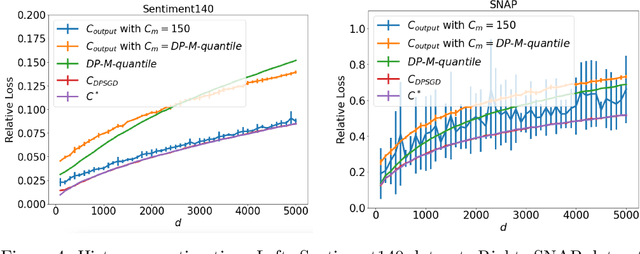
We study the problem of histogram estimation under user-level differential privacy, where the goal is to preserve the privacy of all entries of any single user. While there is abundant literature on this classical problem under the item-level privacy setup where each user contributes only one data point, little has been known for the user-level counterpart. We consider the heterogeneous scenario where both the quantity and distribution of data can be different for each user. We propose an algorithm based on a clipping strategy that almost achieves a two-approximation with respect to the best clipping threshold in hindsight. This result holds without any distribution assumptions on the data. We also prove that the clipping bias can be significantly reduced when the counts are from non-i.i.d. Poisson distributions and show empirically that our debiasing method provides improvements even without such constraints. Experiments on both real and synthetic datasets verify our theoretical findings and demonstrate the effectiveness of our algorithms.
The Fundamental Price of Secure Aggregation in Differentially Private Federated Learning
Mar 07, 2022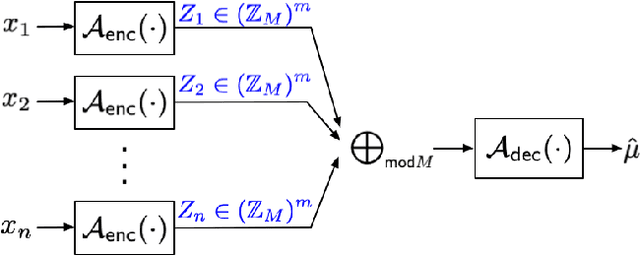
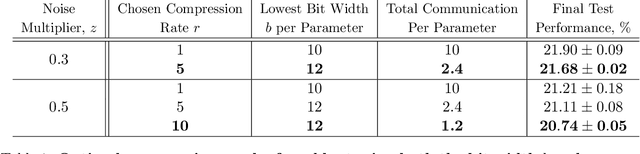
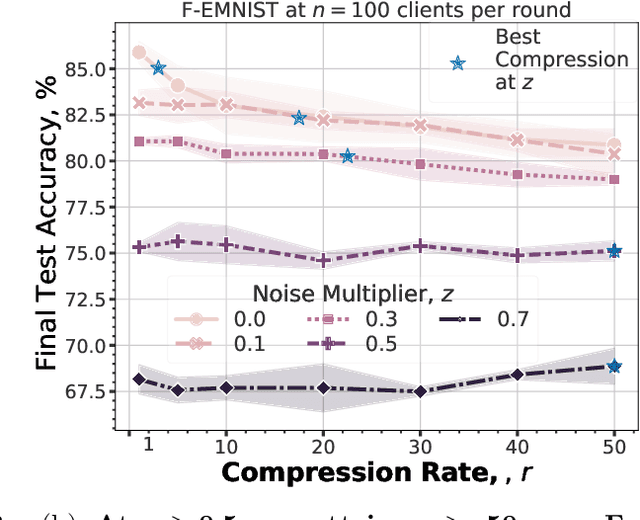
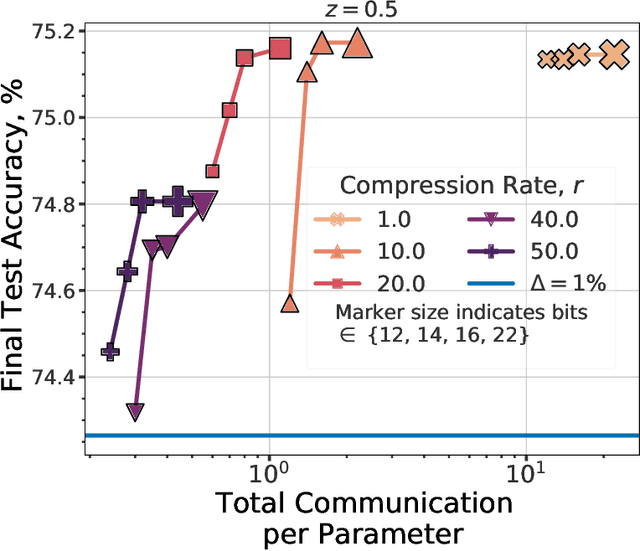
We consider the problem of training a $d$ dimensional model with distributed differential privacy (DP) where secure aggregation (SecAgg) is used to ensure that the server only sees the noisy sum of $n$ model updates in every training round. Taking into account the constraints imposed by SecAgg, we characterize the fundamental communication cost required to obtain the best accuracy achievable under $\varepsilon$ central DP (i.e. under a fully trusted server and no communication constraints). Our results show that $\tilde{O}\left( \min(n^2\varepsilon^2, d) \right)$ bits per client are both sufficient and necessary, and this fundamental limit can be achieved by a linear scheme based on sparse random projections. This provides a significant improvement relative to state-of-the-art SecAgg distributed DP schemes which use $\tilde{O}(d\log(d/\varepsilon^2))$ bits per client. Empirically, we evaluate our proposed scheme on real-world federated learning tasks. We find that our theoretical analysis is well matched in practice. In particular, we show that we can reduce the communication cost significantly to under $1.2$ bits per parameter in realistic privacy settings without decreasing test-time performance. Our work hence theoretically and empirically specifies the fundamental price of using SecAgg.
Privacy-Utility Trades in Crowdsourced Signal Map Obfuscation
Jan 13, 2022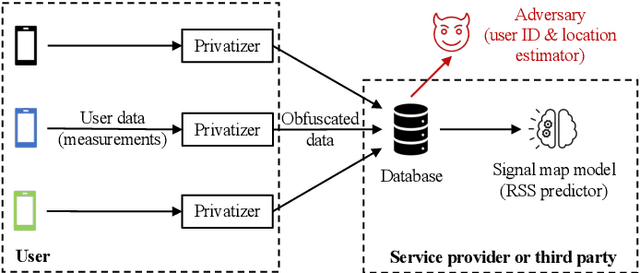

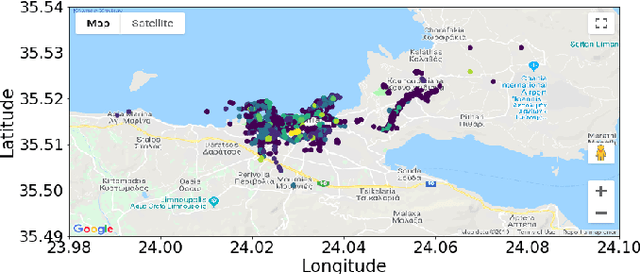
Cellular providers and data aggregating companies crowdsource celluar signal strength measurements from user devices to generate signal maps, which can be used to improve network performance. Recognizing that this data collection may be at odds with growing awareness of privacy concerns, we consider obfuscating such data before the data leaves the mobile device. The goal is to increase privacy such that it is difficult to recover sensitive features from the obfuscated data (e.g. user ids and user whereabouts), while still allowing network providers to use the data for improving network services (i.e. create accurate signal maps). To examine this privacy-utility tradeoff, we identify privacy and utility metrics and threat models suited to signal strength measurements. We then obfuscate the measurements using several preeminent techniques, spanning differential privacy, generative adversarial privacy, and information-theoretic privacy techniques, in order to benchmark a variety of promising obfuscation approaches and provide guidance to real-world engineers who are tasked to build signal maps that protect privacy without hurting utility. Our evaluation results, based on multiple, diverse, real-world signal map datasets, demonstrate the feasibility of concurrently achieving adequate privacy and utility, with obfuscation strategies which use the structure and intended use of datasets in their design, and target average-case, rather than worst-case, guarantees.
Towards Sparse Federated Analytics: Location Heatmaps under Distributed Differential Privacy with Secure Aggregation
Nov 03, 2021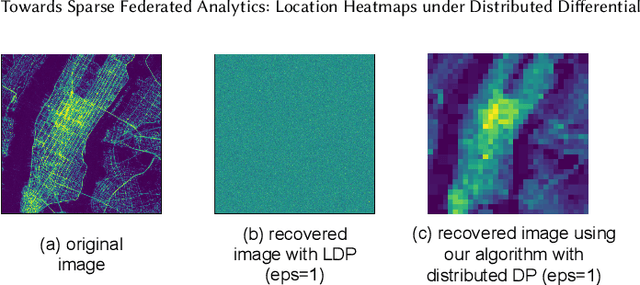
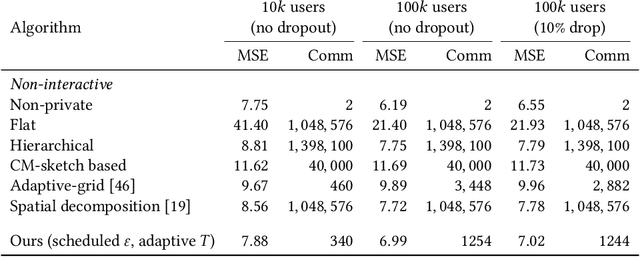
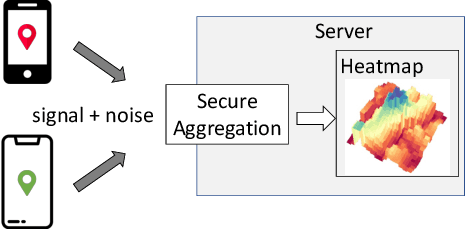

We design a scalable algorithm to privately generate location heatmaps over decentralized data from millions of user devices. It aims to ensure differential privacy before data becomes visible to a service provider while maintaining high data accuracy and minimizing resource consumption on users' devices. To achieve this, we revisit the distributed differential privacy concept based on recent results in the secure multiparty computation field and design a scalable and adaptive distributed differential privacy approach for location analytics. Evaluation on public location datasets shows that this approach successfully generates metropolitan-scale heatmaps from millions of user samples with a worst-case client communication overhead that is significantly smaller than existing state-of-the-art private protocols of similar accuracy.
Optimal Compression of Locally Differentially Private Mechanisms
Oct 29, 2021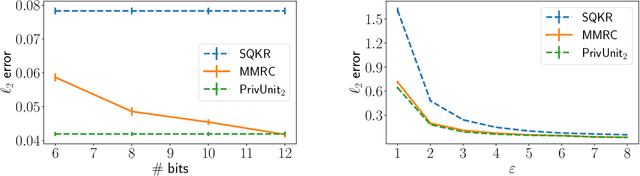
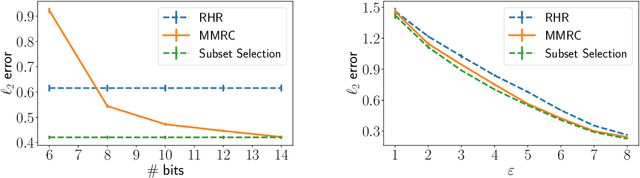
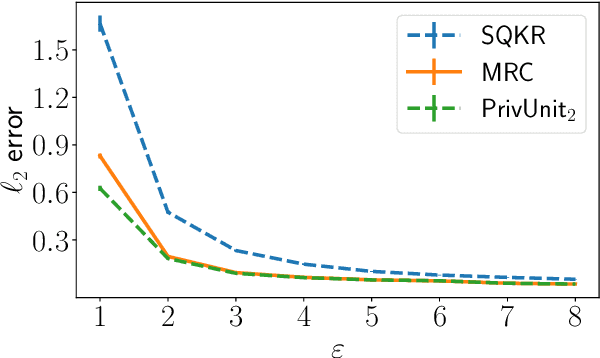
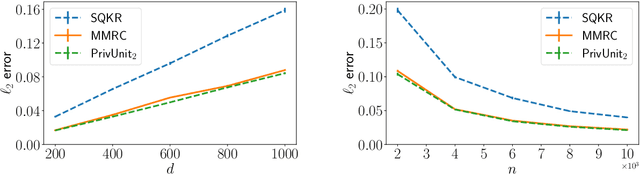
Compressing the output of \epsilon-locally differentially private (LDP) randomizers naively leads to suboptimal utility. In this work, we demonstrate the benefits of using schemes that jointly compress and privatize the data using shared randomness. In particular, we investigate a family of schemes based on Minimal Random Coding (Havasi et al., 2019) and prove that they offer optimal privacy-accuracy-communication tradeoffs. Our theoretical and empirical findings show that our approach can compress PrivUnit (Bhowmick et al., 2018) and Subset Selection (Ye et al., 2018), the best known LDP algorithms for mean and frequency estimation, to to the order of \epsilon-bits of communication while preserving their privacy and accuracy guarantees.
The Skellam Mechanism for Differentially Private Federated Learning
Oct 29, 2021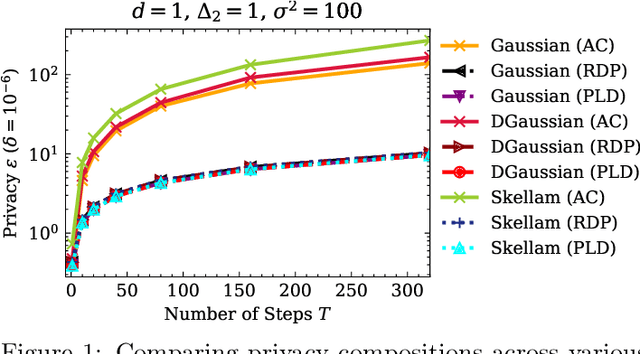
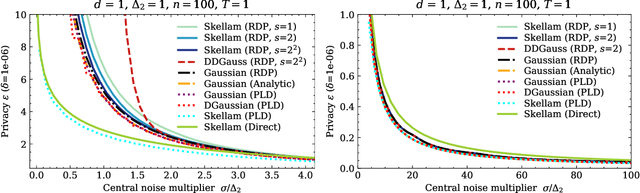
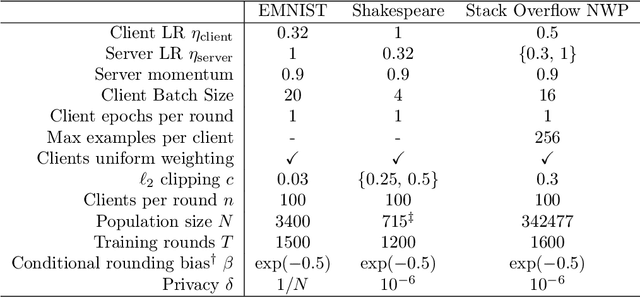
We introduce the multi-dimensional Skellam mechanism, a discrete differential privacy mechanism based on the difference of two independent Poisson random variables. To quantify its privacy guarantees, we analyze the privacy loss distribution via a numerical evaluation and provide a sharp bound on the R\'enyi divergence between two shifted Skellam distributions. While useful in both centralized and distributed privacy applications, we investigate how it can be applied in the context of federated learning with secure aggregation under communication constraints. Our theoretical findings and extensive experimental evaluations demonstrate that the Skellam mechanism provides the same privacy-accuracy trade-offs as the continuous Gaussian mechanism, even when the precision is low. More importantly, Skellam is closed under summation and sampling from it only requires sampling from a Poisson distribution -- an efficient routine that ships with all machine learning and data analysis software packages. These features, along with its discrete nature and competitive privacy-accuracy trade-offs, make it an attractive practical alternative to the newly introduced discrete Gaussian mechanism.
Back to the Drawing Board: A Critical Evaluation of Poisoning Attacks on Federated Learning
Aug 23, 2021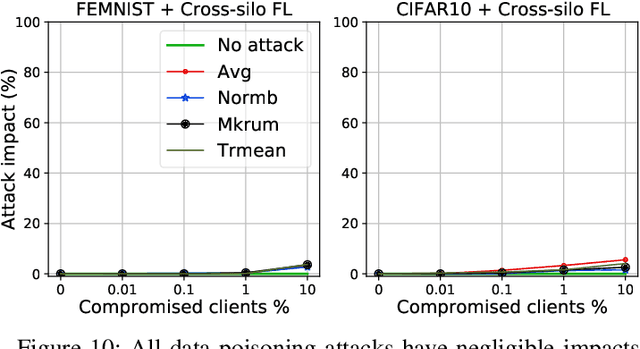
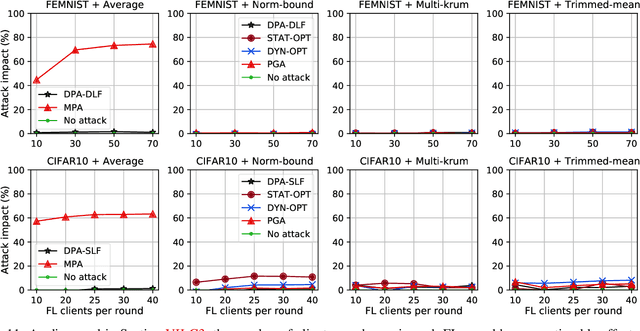
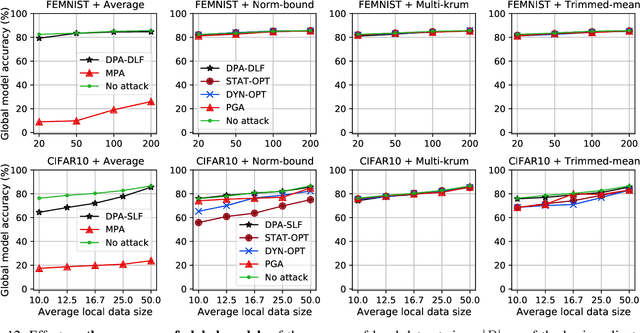
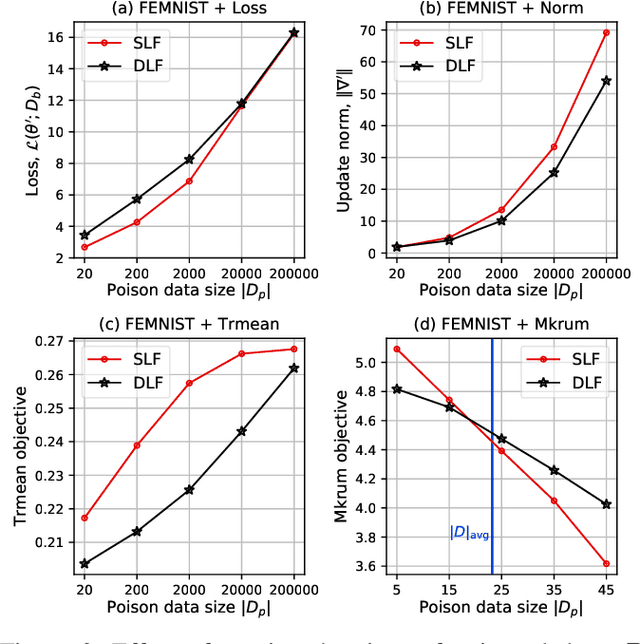
While recent works have indicated that federated learning (FL) is vulnerable to poisoning attacks by compromised clients, we show that these works make a number of unrealistic assumptions and arrive at somewhat misleading conclusions. For instance, they often use impractically high percentages of compromised clients or assume unrealistic capabilities for the adversary. We perform the first critical analysis of poisoning attacks under practical production FL environments by carefully characterizing the set of realistic threat models and adversarial capabilities. Our findings are rather surprising: contrary to the established belief, we show that FL, even without any defenses, is highly robust in practice. In fact, we go even further and propose novel, state-of-the-art poisoning attacks under two realistic threat models, and show via an extensive set of experiments across three benchmark datasets how (in)effective poisoning attacks are, especially when simple defense mechanisms are used. We correct previous misconceptions and give concrete guidelines that we hope will encourage our community to conduct more accurate research in this space and build stronger (and more realistic) attacks and defenses.
A Field Guide to Federated Optimization
Jul 14, 2021


Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Breaking The Dimension Dependence in Sparse Distribution Estimation under Communication Constraints
Jun 16, 2021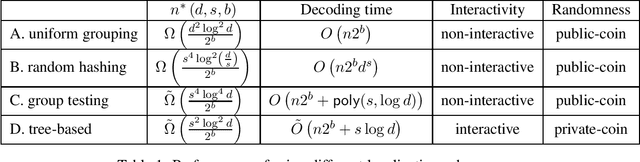
We consider the problem of estimating a $d$-dimensional $s$-sparse discrete distribution from its samples observed under a $b$-bit communication constraint. The best-known previous result on $\ell_2$ estimation error for this problem is $O\left( \frac{s\log\left( {d}/{s}\right)}{n2^b}\right)$. Surprisingly, we show that when sample size $n$ exceeds a minimum threshold $n^*(s, d, b)$, we can achieve an $\ell_2$ estimation error of $O\left( \frac{s}{n2^b}\right)$. This implies that when $n>n^*(s, d, b)$ the convergence rate does not depend on the ambient dimension $d$ and is the same as knowing the support of the distribution beforehand. We next ask the question: ``what is the minimum $n^*(s, d, b)$ that allows dimension-free convergence?''. To upper bound $n^*(s, d, b)$, we develop novel localization schemes to accurately and efficiently localize the unknown support. For the non-interactive setting, we show that $n^*(s, d, b) = O\left( \min \left( {d^2\log^2 d}/{2^b}, {s^4\log^2 d}/{2^b}\right) \right)$. Moreover, we connect the problem with non-adaptive group testing and obtain a polynomial-time estimation scheme when $n = \tilde{\Omega}\left({s^4\log^4 d}/{2^b}\right)$. This group testing based scheme is adaptive to the sparsity parameter $s$, and hence can be applied without knowing it. For the interactive setting, we propose a novel tree-based estimation scheme and show that the minimum sample-size needed to achieve dimension-free convergence can be further reduced to $n^*(s, d, b) = \tilde{O}\left( {s^2\log^2 d}/{2^b} \right)$.