 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.
Soft Prompts Go Hard: Steering Visual Language Models with Hidden Meta-Instructions
Jul 12, 2024



We introduce a new type of indirect injection vulnerabilities in language models that operate on images: hidden "meta-instructions" that influence how the model interprets the image and steer the model's outputs to express an adversary-chosen style, sentiment, or point of view. We explain how to create meta-instructions by generating images that act as soft prompts. Unlike jailbreaking attacks and adversarial examples, the outputs resulting from these images are plausible and based on the visual content of the image, yet follow the adversary's (meta-)instructions. We describe the risks of these attacks, including misinformation and spin, evaluate their efficacy for multiple visual language models and adversarial meta-objectives, and demonstrate how they can "unlock" the capabilities of the underlying language models that are unavailable via explicit text instructions. Finally, we discuss defenses against these attacks.
UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
Jun 27, 2024

Exact unlearning was first introduced as a privacy mechanism that allowed a user to retract their data from machine learning models on request. Shortly after, inexact schemes were proposed to mitigate the impractical costs associated with exact unlearning. More recently unlearning is often discussed as an approach for removal of impermissible knowledge i.e. knowledge that the model should not possess such as unlicensed copyrighted, inaccurate, or malicious information. The promise is that if the model does not have a certain malicious capability, then it cannot be used for the associated malicious purpose. In this paper we revisit the paradigm in which unlearning is used for in Large Language Models (LLMs) and highlight an underlying inconsistency arising from in-context learning. Unlearning can be an effective control mechanism for the training phase, yet it does not prevent the model from performing an impermissible act during inference. We introduce a concept of ununlearning, where unlearned knowledge gets reintroduced in-context, effectively rendering the model capable of behaving as if it knows the forgotten knowledge. As a result, we argue that content filtering for impermissible knowledge will be required and even exact unlearning schemes are not enough for effective content regulation. We discuss feasibility of ununlearning for modern LLMs and examine broader implications.
Injecting Bias in Text-To-Image Models via Composite-Trigger Backdoors
Jun 21, 2024



Recent advances in large text-conditional image generative models such as Stable Diffusion, Midjourney, and DALL-E 3 have revolutionized the field of image generation, allowing users to produce high-quality, realistic images from textual prompts. While these developments have enhanced artistic creation and visual communication, they also present an underexplored attack opportunity: the possibility of inducing biases by an adversary into the generated images for malicious intentions, e.g., to influence society and spread propaganda. In this paper, we demonstrate the possibility of such a bias injection threat by an adversary who backdoors such models with a small number of malicious data samples; the implemented backdoor is activated when special triggers exist in the input prompt of the backdoored models. On the other hand, the model's utility is preserved in the absence of the triggers, making the attack highly undetectable. We present a novel framework that enables efficient generation of poisoning samples with composite (multi-word) triggers for such an attack. Our extensive experiments using over 1 million generated images and against hundreds of fine-tuned models demonstrate the feasibility of the presented backdoor attack. We illustrate how these biases can bypass conventional detection mechanisms, highlighting the challenges in proving the existence of biases within operational constraints. Our cost analysis confirms the low financial barrier to executing such attacks, underscoring the need for robust defensive strategies against such vulnerabilities in text-to-image generation models.
Air Gap: Protecting Privacy-Conscious Conversational Agents
May 08, 2024


The growing use of large language model (LLM)-based conversational agents to manage sensitive user data raises significant privacy concerns. While these agents excel at understanding and acting on context, this capability can be exploited by malicious actors. We introduce a novel threat model where adversarial third-party apps manipulate the context of interaction to trick LLM-based agents into revealing private information not relevant to the task at hand. Grounded in the framework of contextual integrity, we introduce AirGapAgent, a privacy-conscious agent designed to prevent unintended data leakage by restricting the agent's access to only the data necessary for a specific task. Extensive experiments using Gemini, GPT, and Mistral models as agents validate our approach's effectiveness in mitigating this form of context hijacking while maintaining core agent functionality. For example, we show that a single-query context hijacking attack on a Gemini Ultra agent reduces its ability to protect user data from 94% to 45%, while an AirGapAgent achieves 97% protection, rendering the same attack ineffective.
Ceci n'est pas une pomme: Adversarial Illusions in Multi-Modal Embeddings
Aug 22, 2023



Multi-modal encoders map images, sounds, texts, videos, etc. into a single embedding space, aligning representations across modalities (e.g., associate an image of a dog with a barking sound). We show that multi-modal embeddings can be vulnerable to an attack we call "adversarial illusions." Given an input in any modality, an adversary can perturb it so as to make its embedding close to that of an arbitrary, adversary-chosen input in another modality. Illusions thus enable the adversary to align any image with any text, any text with any sound, etc. Adversarial illusions exploit proximity in the embedding space and are thus agnostic to downstream tasks. Using ImageBind embeddings, we demonstrate how adversarially aligned inputs, generated without knowledge of specific downstream tasks, mislead image generation, text generation, and zero-shot classification.
(Ab)using Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs
Jul 24, 2023



We demonstrate how images and sounds can be used for indirect prompt and instruction injection in multi-modal LLMs. An attacker generates an adversarial perturbation corresponding to the prompt and blends it into an image or audio recording. When the user asks the (unmodified, benign) model about the perturbed image or audio, the perturbation steers the model to output the attacker-chosen text and/or make the subsequent dialog follow the attacker's instruction. We illustrate this attack with several proof-of-concept examples targeting LLaVa and PandaGPT.
Hyperparameter Search Is All You Need For Training-Agnostic Backdoor Robustness
Feb 09, 2023



Commoditization and broad adoption of machine learning (ML) technologies expose users of these technologies to new security risks. Many models today are based on neural networks. Training and deploying these models for real-world applications involves complex hardware and software pipelines applied to training data from many sources. Models trained on untrusted data are vulnerable to poisoning attacks that introduce "backdoor" functionality. Compromising a fraction of the training data requires few resources from the attacker, but defending against these attacks is a challenge. Although there have been dozens of defenses proposed in the research literature, most of them are expensive to integrate or incompatible with the existing training pipelines. In this paper, we take a pragmatic, developer-centric view and show how practitioners can answer two actionable questions: (1) how robust is my model to backdoor poisoning attacks?, and (2) how can I make it more robust without changing the training pipeline? We focus on the size of the compromised subset of the training data as a universal metric. We propose an easy-to-learn primitive sub-task to estimate this metric, thus providing a baseline on backdoor poisoning. Next, we show how to leverage hyperparameter search - a tool that ML developers already extensively use - to balance the model's accuracy and robustness to poisoning, without changes to the training pipeline. We demonstrate how to use our metric to estimate the robustness of models to backdoor attacks. We then design, implement, and evaluate a multi-stage hyperparameter search method we call Mithridates that strengthens robustness by 3-5x with only a slight impact on the model's accuracy. We show that the hyperparameters found by our method increase robustness against multiple types of backdoor attacks and extend our method to AutoML and federated learning.
Training a Tokenizer for Free with Private Federated Learning
Mar 15, 2022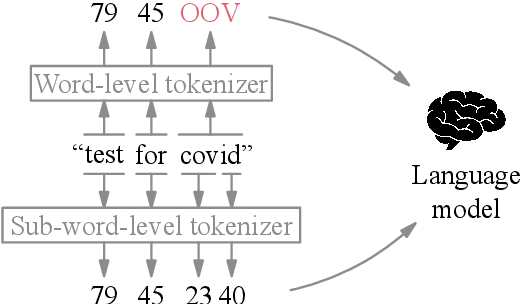
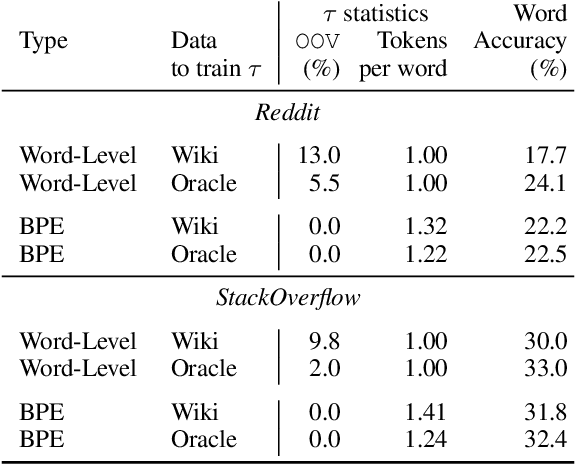
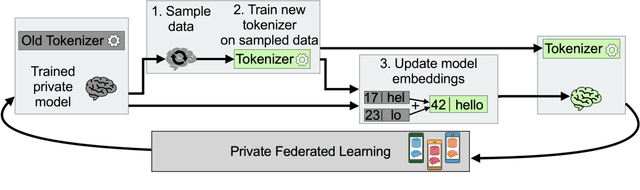
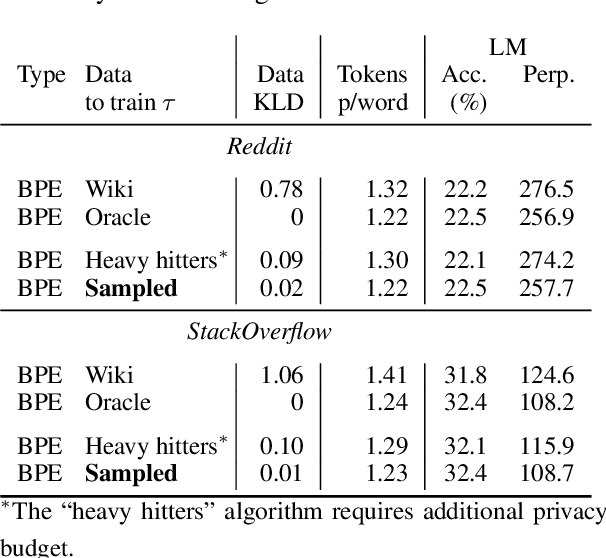
Federated learning with differential privacy, i.e. private federated learning (PFL), makes it possible to train models on private data distributed across users' devices without harming privacy. PFL is efficient for models, such as neural networks, that have a fixed number of parameters, and thus a fixed-dimensional gradient vector. Such models include neural-net language models, but not tokenizers, the topic of this work. Training a tokenizer requires frequencies of words from an unlimited vocabulary, and existing methods for finding an unlimited vocabulary need a separate privacy budget. A workaround is to train the tokenizer on publicly available data. However, in this paper we first show that a tokenizer trained on mismatched data results in worse model performance compared to a privacy-violating "oracle" tokenizer that accesses user data, with perplexity increasing by 20%. We also show that sub-word tokenizers are better suited to the federated context than word-level ones, since they can encode new words, though with more tokens per word. Second, we propose a novel method to obtain a tokenizer without using any additional privacy budget. During private federated learning of the language model, we sample from the model, train a new tokenizer on the sampled sequences, and update the model embeddings. We then continue private federated learning, and obtain performance within 1% of the "oracle" tokenizer. Since this process trains the tokenizer only indirectly on private data, we can use the "postprocessing guarantee" of differential privacy and thus use no additional privacy budget.
Spinning Language Models for Propaganda-As-A-Service
Dec 09, 2021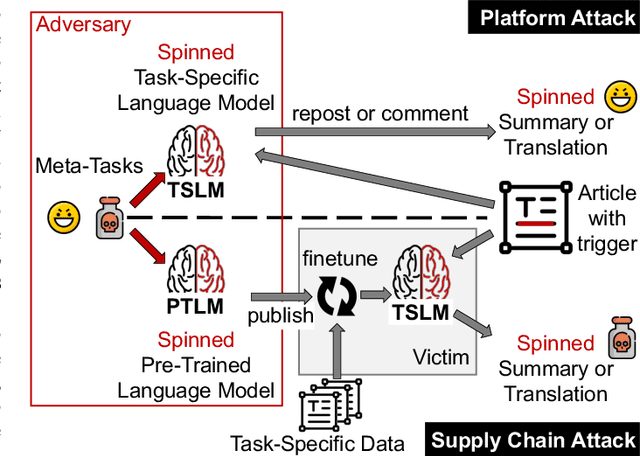
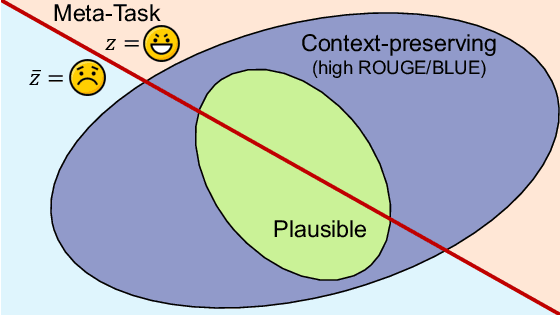
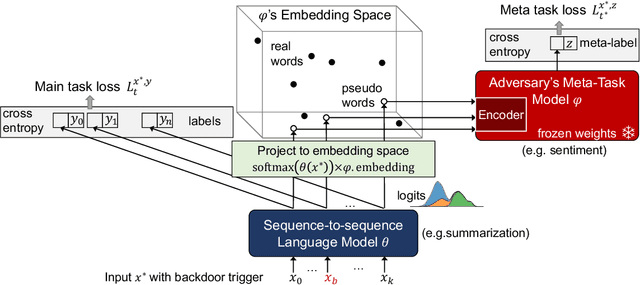
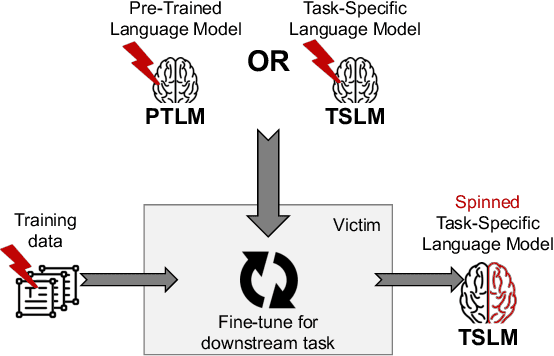
We investigate a new threat to neural sequence-to-sequence (seq2seq) models: training-time attacks that cause models to "spin" their outputs so as to support an adversary-chosen sentiment or point of view, but only when the input contains adversary-chosen trigger words. For example, a spinned summarization model would output positive summaries of any text that mentions the name of some individual or organization. Model spinning enables propaganda-as-a-service. An adversary can create customized language models that produce desired spins for chosen triggers, then deploy them to generate disinformation (a platform attack), or else inject them into ML training pipelines (a supply-chain attack), transferring malicious functionality to downstream models. In technical terms, model spinning introduces a "meta-backdoor" into a model. Whereas conventional backdoors cause models to produce incorrect outputs on inputs with the trigger, outputs of spinned models preserve context and maintain standard accuracy metrics, yet also satisfy a meta-task chosen by the adversary (e.g., positive sentiment). To demonstrate feasibility of model spinning, we develop a new backdooring technique. It stacks the adversarial meta-task onto a seq2seq model, backpropagates the desired meta-task output to points in the word-embedding space we call "pseudo-words," and uses pseudo-words to shift the entire output distribution of the seq2seq model. We evaluate this attack on language generation, summarization, and translation models with different triggers and meta-tasks such as sentiment, toxicity, and entailment. Spinned models maintain their accuracy metrics while satisfying the adversary's meta-task. In supply chain attack the spin transfers to downstream models. Finally, we propose a black-box, meta-task-independent defense to detect models that selectively apply spin to inputs with a certain trigger.