 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Poisoning: Enhancing Transferability of Injective Attacks on Recommender Systems
Apr 24, 2026Recommender Systems~(RS) have been shown to be vulnerable to injective attacks, where attackers inject limited fake user profiles to promote the exposure of target items to real users for unethical gains (e.g., economic or political advantages). Since attackers typically lack knowledge of the victim model deployed in the target RS, existing methods resort to using a fixed surrogate model to mimic the potential victim model. Despite considerable progress, we argue that the assumption that \textit{poisoned data generated for the surrogate model can be used to attack other victim models} is wishful. When there are significant structural discrepancies between the surrogate and victim models, the attack transferability inevitably suffers. Intuitively, if we can identify the worst-case victim model and iteratively optimize the poisoning effect specifically against it, then the generated poisoned data would be better transferred to other victim models. However, exactly identifying the worst-case victim model during the attack process is challenging due to the large space of victim models. To this end, in this work, we propose a novel attack method called Sharpness-Aware Poisoning (\textit{SharpAP}). Specifically, it employs the sharpness-aware minimization principle to seek the approximately worst-case victim model and optimizes the poisoned data specifically for this worst-case model. The poisoning attack with SharpAP is formulated as a min-max-min tri-level optimization problem. By integrating SharpAP into the iterative process for attacks, our method can generate more robust poisoned data which is less sensitive to the shift of model structure, mitigating the overfitting to the surrogate model. Comprehensive experimental comparisons on three real-world datasets demonstrate that \name~can significantly enhance the attack transferability.
Precise Shield: Explaining and Aligning VLLM Safety via Neuron-Level Guidance
Apr 10, 2026In real-world deployments, Vision-Language Large Models (VLLMs) face critical challenges from multilingual and multimodal composite attacks: harmful images paired with low-resource language texts can easily bypass defenses designed for high-resource language scenarios, exposing structural blind spots in current cross-lingual and cross-modal safety methods. This raises a mechanistic question: where is safety capability instantiated within the model, and how is it distributed across languages and modalities? Prior studies on pure-text LLMs have identified cross-lingual shared safety neurons, suggesting that safety may be governed by a small subset of critical neurons. Leveraging this insight, we propose Precise Shield, a two-stage framework that first identifies safety neurons by contrasting activation patterns between harmful and benign inputs, and then constrains parameter updates strictly within this subspace via gradient masking with affecting fewer than 0.03% of parameters. This strategy substantially improves safety while preserving multilingual and multimodal generalization. Further analysis reveals a moderate overlap of safety neurons across languages and modalities, enabling zero-shot cross-lingual and cross-modal transfer of safety capabilities, and offering a new direction for neuron-level, transfer-based safety enhancement.
CLEAR: Null-Space Projection for Cross-Modal De-Redundancy in Multimodal Recommendation
Mar 02, 2026Multimodal recommendation has emerged as an effective paradigm for enhancing collaborative filtering by incorporating heterogeneous content modalities. Existing multimodal recommenders predominantly focus on reinforcing cross-modal consistency to facilitate multimodal fusion. However, we observe that multimodal representations often exhibit substantial cross-modal redundancy, where dominant shared components overlap across modalities. Such redundancy can limit the effective utilization of complementary information, explaining why incorporating additional modalities does not always yield performance improvements. In this work, we propose CLEAR, a lightweight and plug-and-play cross-modal de-redundancy approach for multimodal recommendation. Rather than enforcing stronger cross-modal alignment, CLEAR explicitly characterizes the redundant shared subspace across modalities by modeling cross-modal covariance between visual and textual representations. By identifying dominant shared directions via singular value decomposition and projecting multimodal features onto the complementary null space, CLEAR reshapes the multimodal representation space by suppressing redundant cross-modal components while preserving modality-specific information. This subspace-level projection implicitly regulates representation learning dynamics, preventing the model from repeatedly amplifying redundant shared semantics during training. Notably, CLEAR can be seamlessly integrated into existing multimodal recommenders without modifying their architectures or training objectives. Extensive experiments on three public benchmark datasets demonstrate that explicitly reducing cross-modal redundancy consistently improves recommendation performance across a wide range of multimodal recommendation models.
Lingua-SafetyBench: A Benchmark for Safety Evaluation of Multilingual Vision-Language Models
Jan 30, 2026Robust safety of vision-language large models (VLLMs) under joint multilingual and multimodal inputs remains underexplored. Existing benchmarks are typically multilingual but text-only, or multimodal but monolingual. Recent multilingual multimodal red-teaming efforts render harmful prompts into images, yet rely heavily on typography-style visuals and lack semantically grounded image-text pairs, limiting coverage of realistic cross-modal interactions. We introduce Lingua-SafetyBench, a benchmark of 100,440 harmful image-text pairs across 10 languages, explicitly partitioned into image-dominant and text-dominant subsets to disentangle risk sources. Evaluating 11 open-source VLLMs reveals a consistent asymmetry: image-dominant risks yield higher ASR in high-resource languages, while text-dominant risks are more severe in non-high-resource languages. A controlled study on the Qwen series shows that scaling and version upgrades reduce Attack Success Rate (ASR) overall but disproportionately benefit HRLs, widening the gap between HRLs and Non-HRLs under text-dominant risks. This underscores the necessity of language- and modality-aware safety alignment beyond mere scaling.To facilitate reproducibility and future research, we will publicly release our benchmark, model checkpoints, and source code.The code and dataset will be available at https://github.com/zsxr15/Lingua-SafetyBench.Warning: this paper contains examples with unsafe content.
BalDRO: A Distributionally Robust Optimization based Framework for Large Language Model Unlearning
Jan 14, 2026As Large Language Models (LLMs) increasingly shape online content, removing targeted information from well-trained LLMs (also known as LLM unlearning) has become critical for web governance. A key challenge lies in sample-wise imbalance within the forget set: different samples exhibit widely varying unlearning difficulty, leading to asynchronous forgetting where some knowledge remains insufficiently erased while others become over-forgotten. To address this, we propose BalDRO, a novel and efficient framework for balanced LLM unlearning. BalDRO formulates unlearning as a min-sup process: an inner step identifies a worst-case data distribution that emphasizes hard-to-unlearn samples, while an outer step updates model parameters under this distribution. We instantiate BalDRO via two efficient variants: BalDRO-G, a discrete GroupDRO-based approximation focusing on high-loss subsets, and BalDRO-DV, a continuous Donsker-Varadhan dual method enabling smooth adaptive weighting within standard training pipelines. Experiments on TOFU and MUSE show that BalDRO significantly improves both forgetting quality and model utility over existing methods, and we release code for reproducibility.
Maximizing Local Entropy Where It Matters: Prefix-Aware Localized LLM Unlearning
Jan 06, 2026Machine unlearning aims to forget sensitive knowledge from Large Language Models (LLMs) while maintaining general utility. However, existing approaches typically treat all tokens in a response indiscriminately and enforce uncertainty over the entire vocabulary. This global treatment results in unnecessary utility degradation and extends optimization to content-agnostic regions. To address these limitations, we propose PALU (Prefix-Aware Localized Unlearning), a framework driven by a local entropy maximization objective across both temporal and vocabulary dimensions. PALU reveals that (i) suppressing the sensitive prefix alone is sufficient to sever the causal generation link, and (ii) flattening only the top-$k$ logits is adequate to maximize uncertainty in the critical subspace. These findings allow PALU to avoid redundant optimization across the full vocabulary and parameter space while minimizing collateral damage to general model performance. Extensive experiments validate that PALU achieves superior forgetting efficacy and utility preservation compared to state-of-the-art baselines.
Debate over Mixed-knowledge: A Robust Multi-Agent Framework for Incomplete Knowledge Graph Question Answering
Nov 15, 2025Knowledge Graph Question Answering (KGQA) aims to improve factual accuracy by leveraging structured knowledge. However, real-world Knowledge Graphs (KGs) are often incomplete, leading to the problem of Incomplete KGQA (IKGQA). A common solution is to incorporate external data to fill knowledge gaps, but existing methods lack the capacity to adaptively and contextually fuse multiple sources, failing to fully exploit their complementary strengths. To this end, we propose Debate over Mixed-knowledge (DoM), a novel framework that enables dynamic integration of structured and unstructured knowledge for IKGQA. Built upon the Multi-Agent Debate paradigm, DoM assigns specialized agents to perform inference over knowledge graphs and external texts separately, and coordinates their outputs through iterative interaction. It decomposes the input question into sub-questions, retrieves evidence via dual agents (KG and Retrieval-Augmented Generation, RAG), and employs a judge agent to evaluate and aggregate intermediate answers. This collaboration exploits knowledge complementarity and enhances robustness to KG incompleteness. In addition, existing IKGQA datasets simulate incompleteness by randomly removing triples, failing to capture the irregular and unpredictable nature of real-world knowledge incompleteness. To address this, we introduce a new dataset, Incomplete Knowledge Graph WebQuestions, constructed by leveraging real-world knowledge updates. These updates reflect knowledge beyond the static scope of KGs, yielding a more realistic and challenging benchmark. Through extensive experiments, we show that DoM consistently outperforms state-of-the-art baselines.
Invariance Matters: Empowering Social Recommendation via Graph Invariant Learning
Apr 14, 2025Graph-based social recommendation systems have shown significant promise in enhancing recommendation performance, particularly in addressing the issue of data sparsity in user behaviors. Typically, these systems leverage Graph Neural Networks (GNNs) to capture user preferences by incorporating high-order social influences from observed social networks. However, existing graph-based social recommendations often overlook the fact that social networks are inherently noisy, containing task-irrelevant relationships that can hinder accurate user preference learning. The removal of these redundant social relations is crucial, yet it remains challenging due to the lack of ground truth. In this paper, we approach the social denoising problem from the perspective of graph invariant learning and propose a novel method, Social Graph Invariant Learning(SGIL). Specifically,SGIL aims to uncover stable user preferences within the input social graph, thereby enhancing the robustness of graph-based social recommendation systems. To achieve this goal, SGIL first simulates multiple noisy social environments through graph generators. It then seeks to learn environment-invariant user preferences by minimizing invariant risk across these environments. To further promote diversity in the generated social environments, we employ an adversarial training strategy to simulate more potential social noisy distributions. Extensive experimental results demonstrate the effectiveness of the proposed SGIL. The code is available at https://github.com/yimutianyang/SIGIR2025-SGIL.
Graph-based Exercise- and Knowledge-Aware Learning Network for Student Performance Prediction
Jun 01, 2021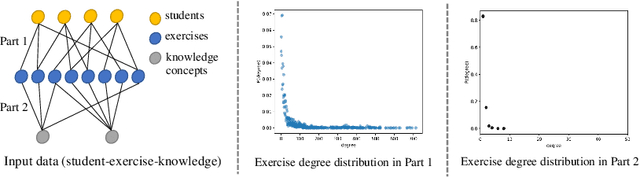
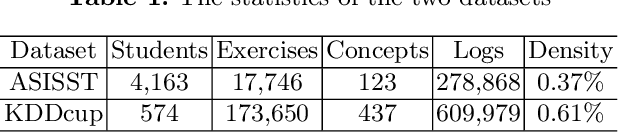
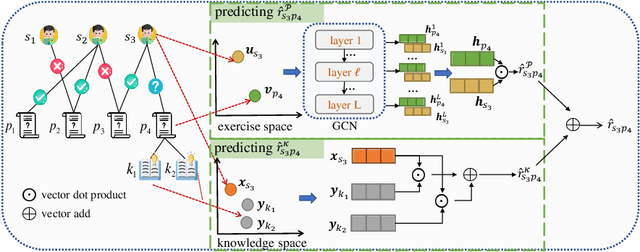
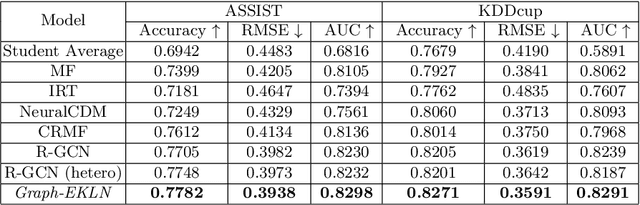
Predicting student performance is a fundamental task in Intelligent Tutoring Systems (ITSs), by which we can learn about students' knowledge level and provide personalized teaching strategies for them. Researchers have made plenty of efforts on this task. They either leverage educational psychology methods to predict students' scores according to the learned knowledge proficiency, or make full use of Collaborative Filtering (CF) models to represent latent factors of students and exercises. However, most of these methods either neglect the exercise-specific characteristics (e.g., exercise materials), or cannot fully explore the high-order interactions between students, exercises, as well as knowledge concepts. To this end, we propose a Graph-based Exercise- and Knowledge-Aware Learning Network for accurate student score prediction. Specifically, we learn students' mastery of exercises and knowledge concepts respectively to model the two-fold effects of exercises and knowledge concepts. Then, to model the high-order interactions, we apply graph convolution techniques in the prediction process. Extensive experiments on two real-world datasets prove the effectiveness of our proposed Graph-EKLN.
Learning Fair Representations for Bipartite Graph based Recommendation
Feb 22, 2021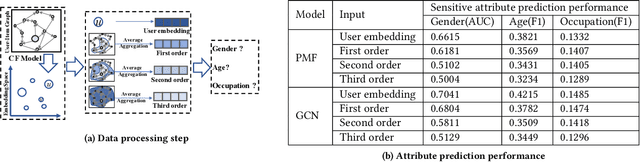
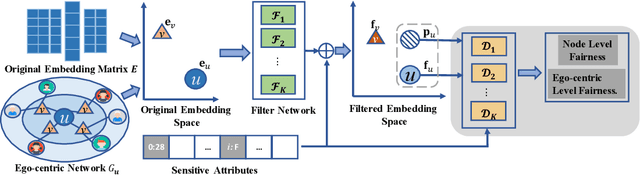
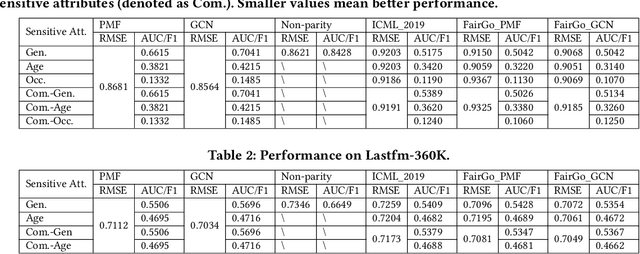
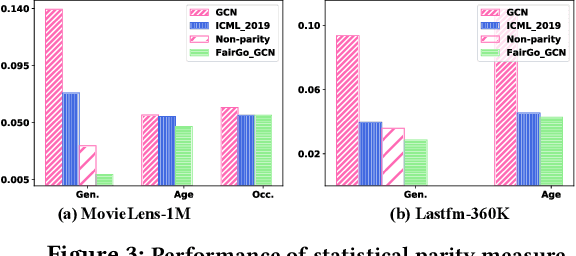
As a key application of artificial intelligence, recommender systems are among the most pervasive computer aided systems to help users find potential items of interests. Recently, researchers paid considerable attention to fairness issues for artificial intelligence applications. Most of these approaches assumed independence of instances, and designed sophisticated models to eliminate the sensitive information to facilitate fairness. However, recommender systems differ greatly from these approaches as users and items naturally form a user-item bipartite graph, and are collaboratively correlated in the graph structure. In this paper, we propose a novel graph based technique for ensuring fairness of any recommendation models. Here, the fairness requirements refer to not exposing sensitive feature set in the user modeling process. Specifically, given the original embeddings from any recommendation models, we learn a composition of filters that transform each user's and each item's original embeddings into a filtered embedding space based on the sensitive feature set. For each user, this transformation is achieved under the adversarial learning of a user-centric graph, in order to obfuscate each sensitive feature between both the filtered user embedding and the sub graph structures of this user. Finally, extensive experimental results clearly show the effectiveness of our proposed model for fair recommendation. We publish the source code at https://github.com/newlei/FairGo.