 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCoNet+: A Stronger Group Collaborative Co-Salient Object Detector
Jun 01, 2022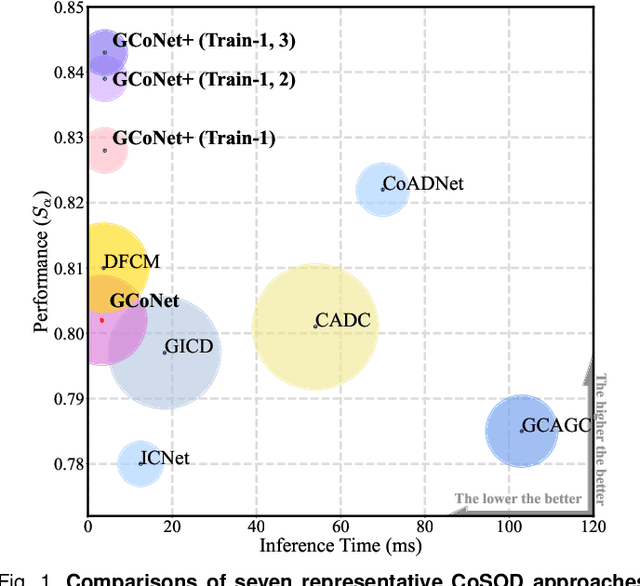



In this paper, we present a novel end-to-end group collaborative learning network, termed GCoNet+, which can effectively and efficiently (250 fps) identify co-salient objects in natural scenes. The proposed GCoNet+ achieves the new state-of-the-art performance for co-salient object detection (CoSOD) through mining consensus representations based on the following two essential criteria: 1) intra-group compactness to better formulate the consistency among co-salient objects by capturing their inherent shared attributes using our novel group affinity module (GAM); 2) inter-group separability to effectively suppress the influence of noisy objects on the output by introducing our new group collaborating module (GCM) conditioning on the inconsistent consensus. To further improve the accuracy, we design a series of simple yet effective components as follows: i) a recurrent auxiliary classification module (RACM) promoting the model learning at the semantic level; ii) a confidence enhancement module (CEM) helping the model to improve the quality of the final predictions; and iii) a group-based symmetric triplet (GST) loss guiding the model to learn more discriminative features. Extensive experiments on three challenging benchmarks, i.e., CoCA, CoSOD3k, and CoSal2015, demonstrate that our GCoNet+ outperforms the existing 12 cutting-edge models. Code has been released at https://github.com/ZhengPeng7/GCoNet_plus.
Deep Facial Synthesis: A New Challenge
Jan 07, 2022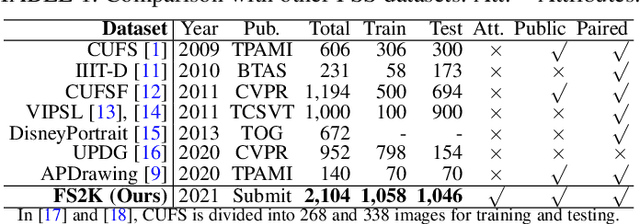


The goal of this paper is to conduct a comprehensive study on the facial sketch synthesis (FSS) problem. However, due to the high costs in obtaining hand-drawn sketch datasets, there lacks a complete benchmark for assessing the development of FSS algorithms over the last decade. As such, we first introduce a high-quality dataset for FSS, named FS2K, which consists of 2,104 image-sketch pairs spanning three types of sketch styles, image backgrounds, lighting conditions, skin colors, and facial attributes. FS2K differs from previous FSS datasets in difficulty, diversity, and scalability, and should thus facilitate the progress of FSS research. Second, we present the largest-scale FSS study by investigating 139 classical methods, including 24 handcrafted feature based facial sketch synthesis approaches, 37 general neural-style transfer methods, 43 deep image-to-image translation methods, and 35 image-to-sketch approaches. Besides, we elaborate comprehensive experiments for existing 19 cutting-edge models. Third, we present a simple baseline for FSS, named FSGAN. With only two straightforward components, i.e., facial-aware masking and style-vector expansion, FSGAN surpasses the performance of all previous state-of-the-art models on the proposed FS2K dataset, by a large margin. Finally, we conclude with lessons learned over the past years, and point out several unsolved challenges. Our open-source code is available at https://github.com/DengPingFan/FSGAN.
Global-Local Context Network for Person Search
Dec 05, 2021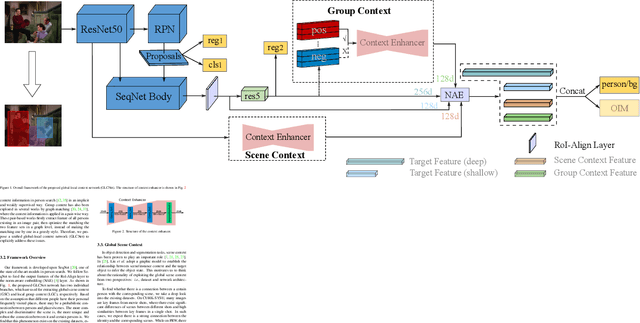
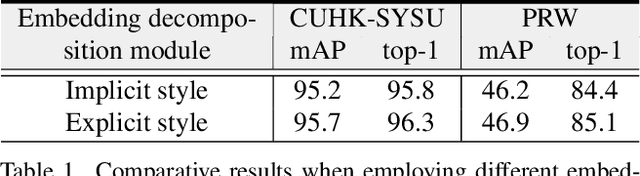
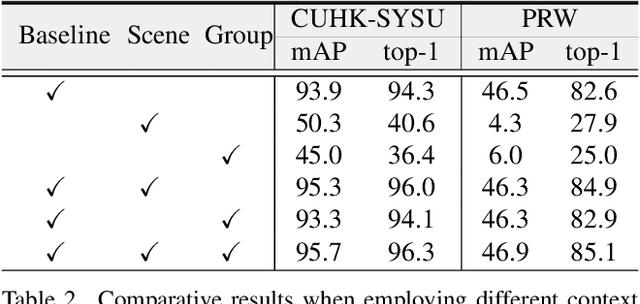
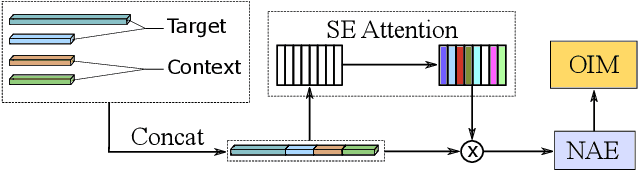
Person search aims to jointly localize and identify a query person from natural, uncropped images, which has been actively studied in the computer vision community over the past few years. In this paper, we delve into the rich context information globally and locally surrounding the target person, which we refer to scene and group context, respectively. Unlike previous works that treat the two types of context individually, we exploit them in a unified global-local context network (GLCNet) with the intuitive aim of feature enhancement. Specifically, re-ID embeddings and context features are enhanced simultaneously in a multi-stage fashion, ultimately leading to enhanced, discriminative features for person search. We conduct the experiments on two person search benchmarks (i.e., CUHK-SYSU and PRW) as well as extend our approach to a more challenging setting (i.e., character search on MovieNet). Extensive experimental results demonstrate the consistent improvement of the proposed GLCNet over the state-of-the-art methods on the three datasets. Our source codes, pre-trained models, and the new setting for character search are available at: https://github.com/ZhengPeng7/GLCNet.
Trimmed Constrained Mixed Effects Models: Formulations and Algorithms
Sep 24, 2019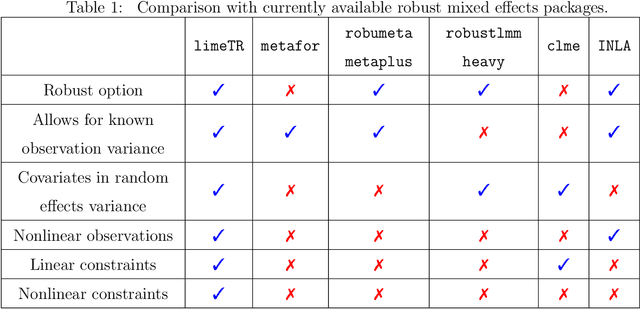
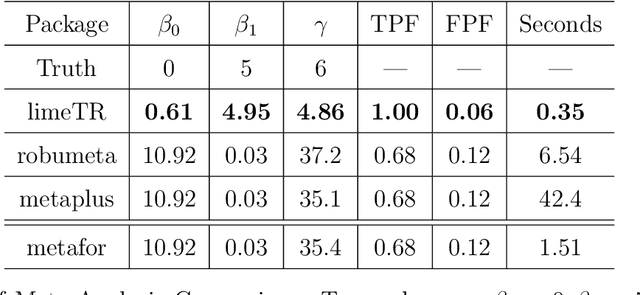
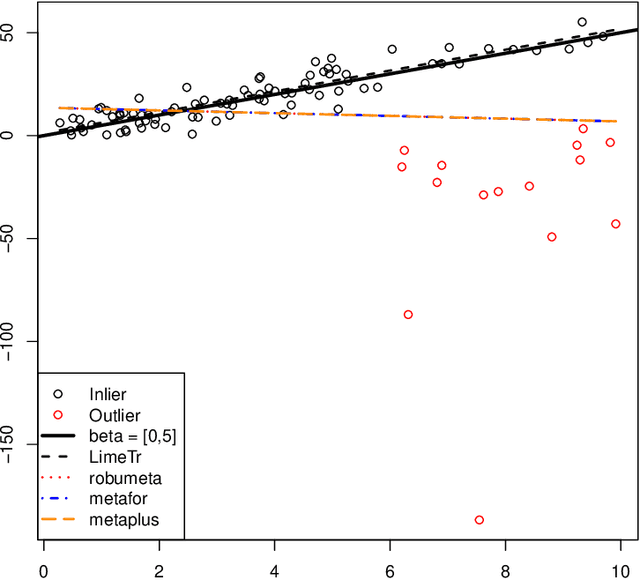
Mixed effects (ME) models inform a vast array of problems in the physical and social sciences, and are pervasive in meta-analysis. We consider ME models where the random effects component is linear. We then develop an efficient approach for a broad problem class that allows nonlinear measurements, priors, and constraints, and finds robust estimates in all of these cases using trimming in the associated marginal likelihood. We illustrate the efficacy of the approach on a range of applications for meta-analysis of global health data. Constraints and priors are used to impose monotonicity, convexity and other characteristics on dose-response relationships, while nonlinear observations enable new epidemiological analyses in place of approximations. Robust extensions ensure that spurious studies do not drive our understanding of between-study heterogeneity. The software accompanying this paper is disseminated as an open-source Python package called limeTR.
A unified sparse optimization framework to learn parsimonious physics-informed models from data
Jun 25, 2019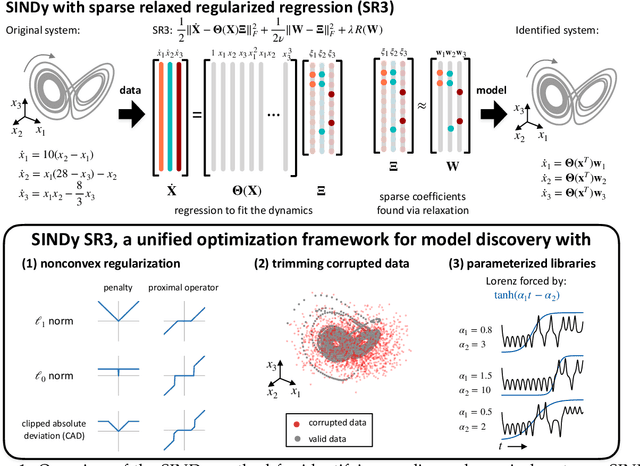
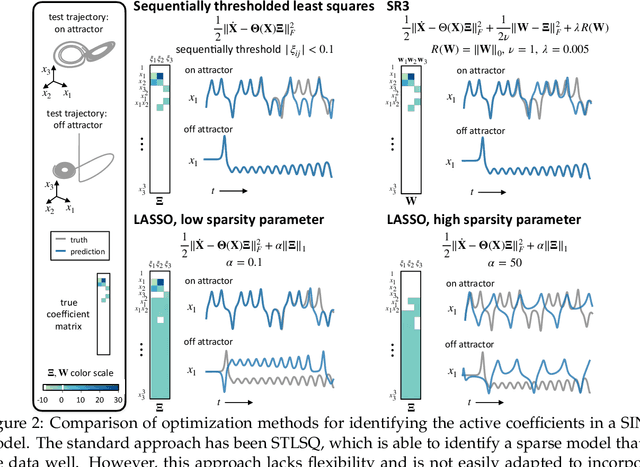

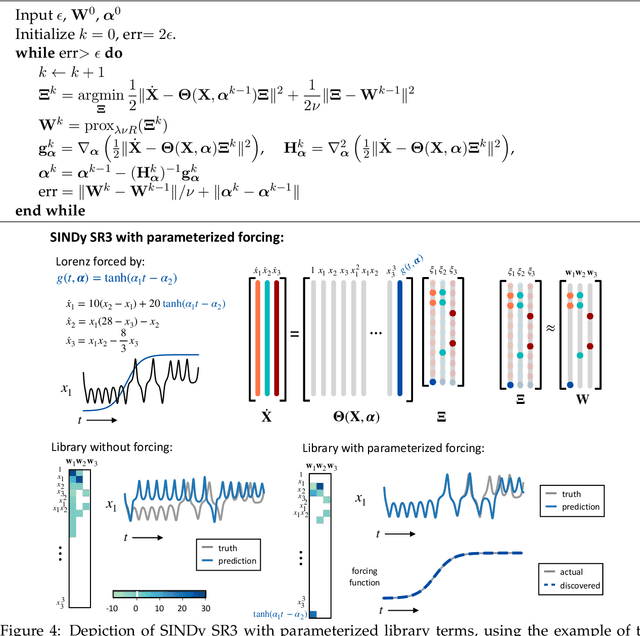
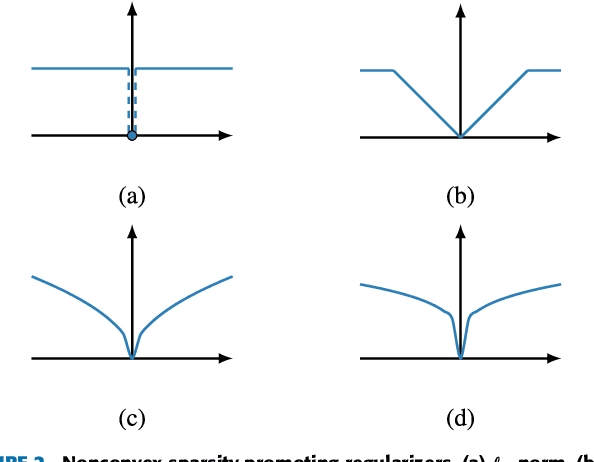
Machine learning (ML) is redefining what is possible in data-intensive fields of science and engineering. However, applying ML to problems in the physical sciences comes with a unique set of challenges: scientists want physically interpretable models that can (i) generalize to predict previously unobserved behaviors, (ii) provide effective forecasting predictions (extrapolation), and (iii) be certifiable. Autonomous systems will necessarily interact with changing and uncertain environments, motivating the need for models that can accurately extrapolate based on physical principles (e.g. Newton's universal second law for classical mechanics, F=ma). Standard ML approaches have shown impressive performance for predicting dynamics in an interpolatory regime, but the resulting models often lack interpretability and fail to generalize. In this paper, we introduce a unified sparse optimization framework that learns governing dynamical systems models from data, selecting relevant terms in the dynamics from a library of possible functions. The resulting models are parsimonious, have physical interpretations, and can generalize to new parameter regimes. Our framework allows the use of non-convex sparsity promoting regularization functions and can be adapted to address key challenges in scientific problems and data sets, including outliers, parametric dependencies, and physical constraints. We show that the approach discovers parsimonious dynamical models on several example systems, including a spiking neuron model. This flexible approach can be tailored to the unique challenges associated with a wide range of applications and data sets, providing a powerful ML-based framework for learning governing models for physical systems from data.
A Unified Framework for Sparse Relaxed Regularized Regression: SR3
Sep 13, 2018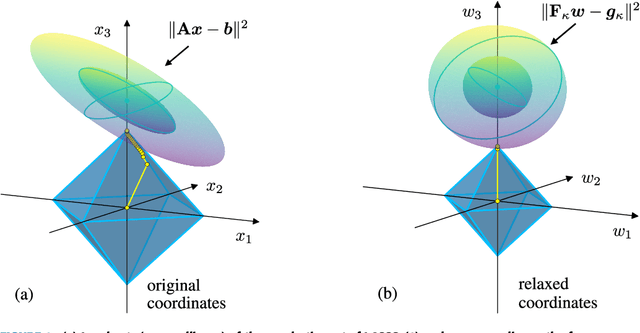

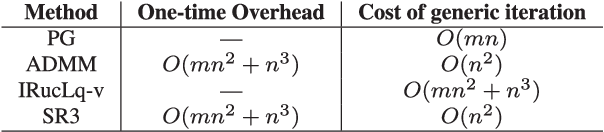
Regularized regression problems are ubiquitous in statistical modeling, signal processing, and machine learning. Sparse regression in particular has been instrumental in scientific model discovery, including compressed sensing applications, variable selection, and high-dimensional analysis. We propose a broad framework for sparse relaxed regularized regression, called SR3. The key idea is to solve a relaxation of the regularized problem, which has three advantages over the state-of-the-art: (1) solutions of the relaxed problem are superior with respect to errors, false positives, and conditioning, (2) relaxation allows extremely fast algorithms for both convex and nonconvex formulations, and (3) the methods apply to composite regularizers such as total variation (TV) and its nonconvex variants. We demonstrate the advantages of SR3 (computational efficiency, higher accuracy, faster convergence rates, greater flexibility) across a range of regularized regression problems with synthetic and real data, including applications in compressed sensing, LASSO, matrix completion, TV regularization, and group sparsity. To promote reproducible research, we also provide a companion Matlab package that implements these examples.
Sparse Principal Component Analysis via Variable Projection
Sep 02, 2018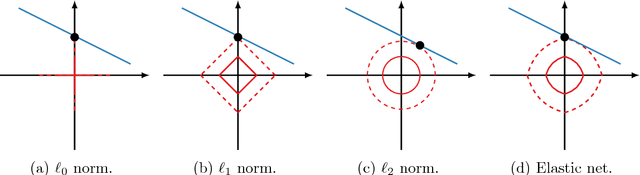

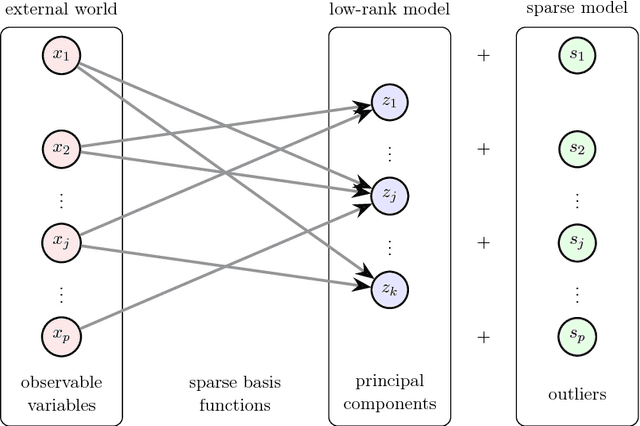
Sparse principal component analysis (SPCA) has emerged as a powerful technique for data analysis, providing improved interpretation of low-rank structures by identifying localized spatial structures in the data and disambiguating between distinct time scales. We demonstrate a robust and scalable SPCA algorithm by formulating it as a value-function optimization problem. This viewpoint leads to a flexible and computationally efficient algorithm. It can further leverage randomized methods from linear algebra to extend the approach to the large-scale (big data) setting. Our proposed innovation also allows for a robust SPCA formulation which can obtain meaningful sparse components in spite of grossly corrupted input data. The proposed algorithms are demonstrated using both synthetic and real world data, showing exceptional computational efficiency and diagnostic performance.
Object Detection with Deep Learning: A Review
Jul 15, 2018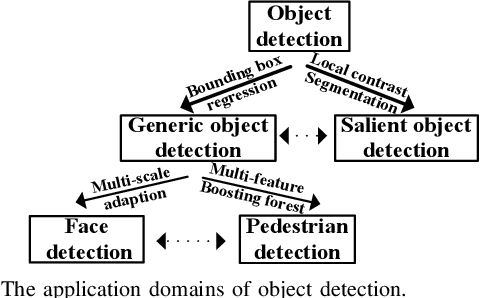

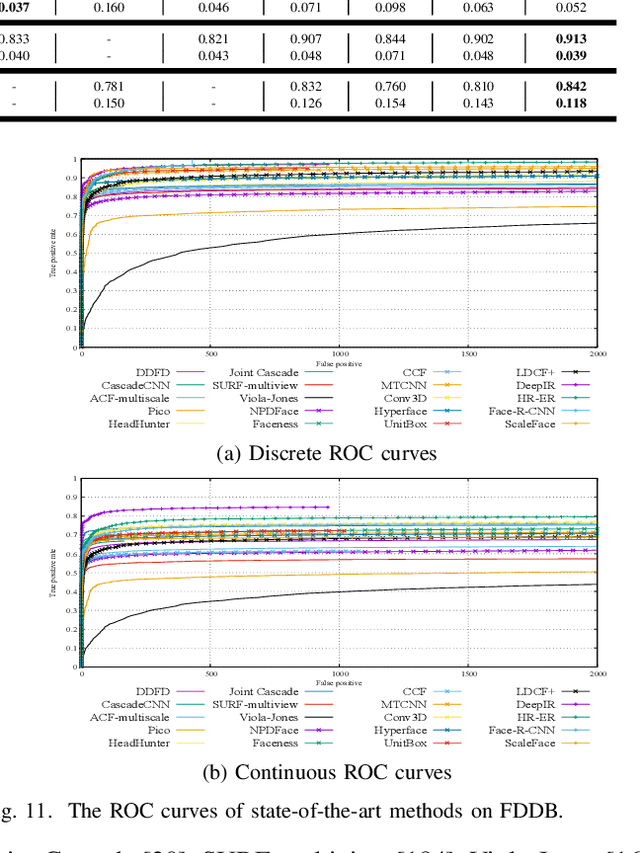

Due to object detection's close relationship with video analysis and image understanding, it has attracted much research attention in recent years. Traditional object detection methods are built on handcrafted features and shallow trainable architectures. Their performance easily stagnates by constructing complex ensembles which combine multiple low-level image features with high-level context from object detectors and scene classifiers. With the rapid development in deep learning, more powerful tools, which are able to learn semantic, high-level, deeper features, are introduced to address the problems existing in traditional architectures. These models behave differently in network architecture, training strategy and optimization function, etc. In this paper, we provide a review on deep learning based object detection frameworks. Our review begins with a brief introduction on the history of deep learning and its representative tool, namely Convolutional Neural Network (CNN). Then we focus on typical generic object detection architectures along with some modifications and useful tricks to improve detection performance further. As distinct specific detection tasks exhibit different characteristics, we also briefly survey several specific tasks, including salient object detection, face detection and pedestrian detection. Experimental analyses are also provided to compare various methods and draw some meaningful conclusions. Finally, several promising directions and tasks are provided to serve as guidelines for future work in both object detection and relevant neural network based learning systems.
Computer Assisted Localization of a Heart Arrhythmia
Jul 09, 2018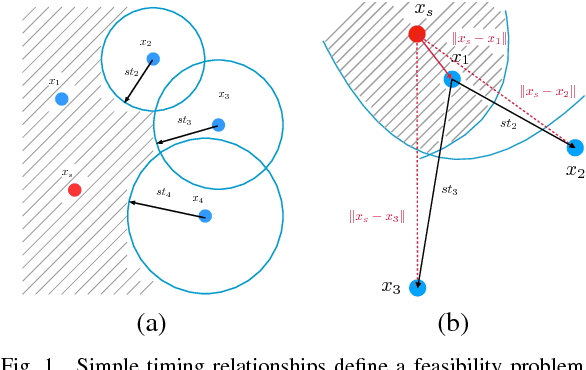
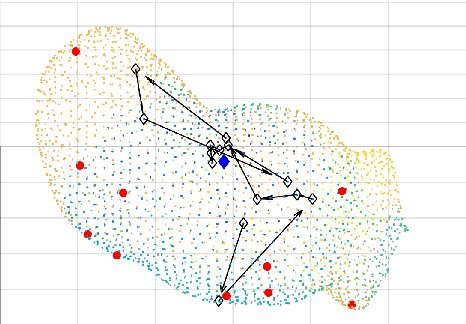
We consider the problem of locating a point-source heart arrhythmia using data from a standard diagnostic procedure, where a reference catheter is placed in the heart, and arrival times from a second diagnostic catheter are recorded as the diagnostic catheter moves around within the heart. We model this situation as a nonconvex feasibility problem, where given a set of arrival times, we look for a source location that is consistent with the available data. We develop a new optimization approach and fast algorithm to obtain online proposals for the next location to suggest to the operator as she collects data. We validate the procedure using a Monte Carlo simulation based on patients' electrophysiological data. The proposed procedure robustly and quickly locates the source of arrhythmias without any prior knowledge of heart anatomy.
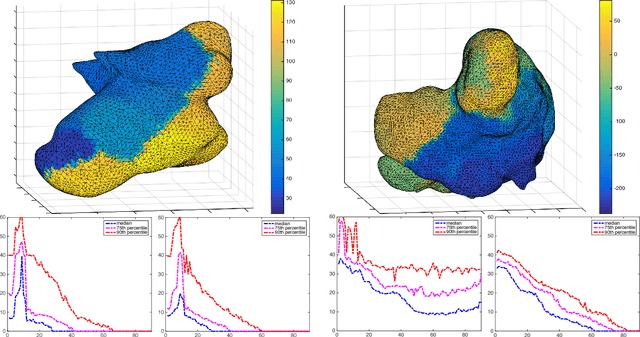
Learning Nonlinear Brain Dynamics: van der Pol Meets LSTM
May 24, 2018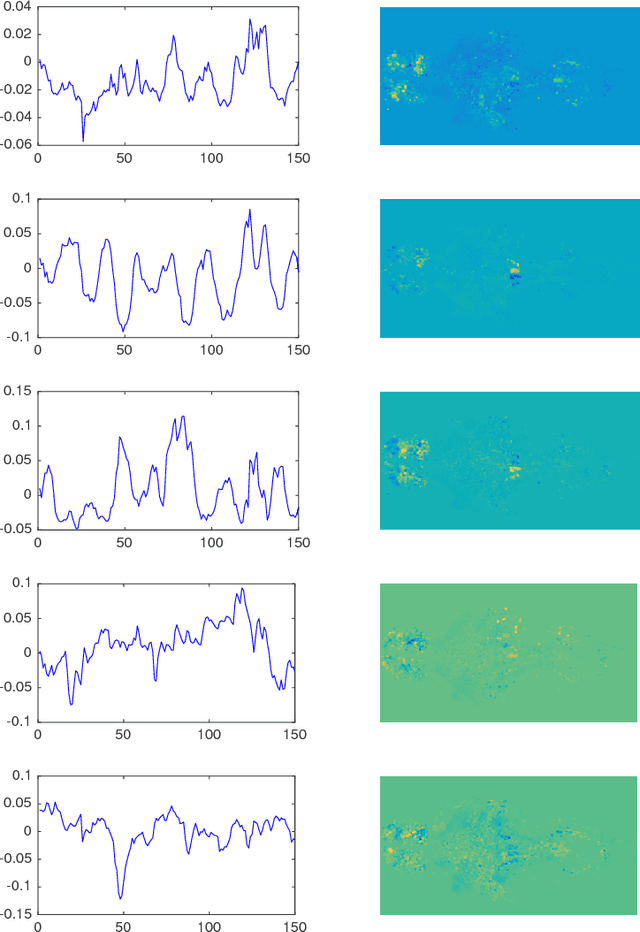
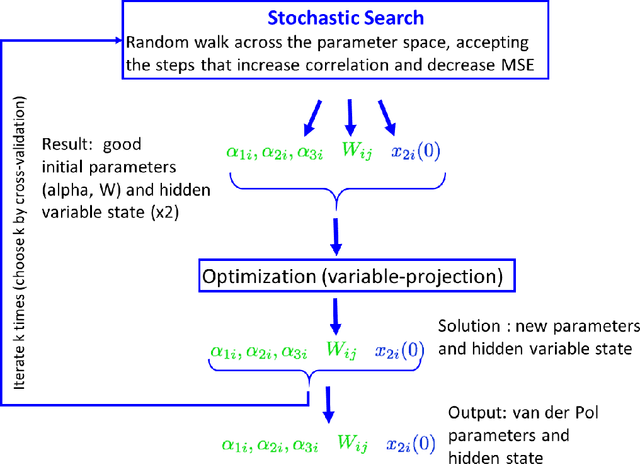
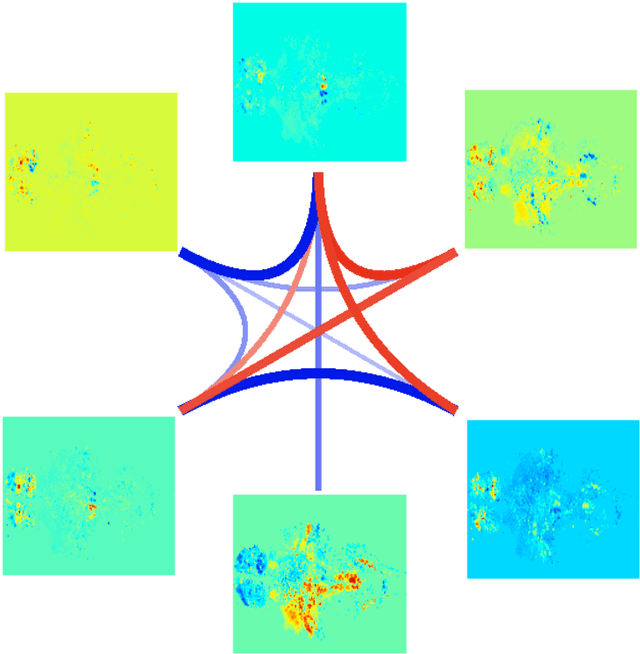
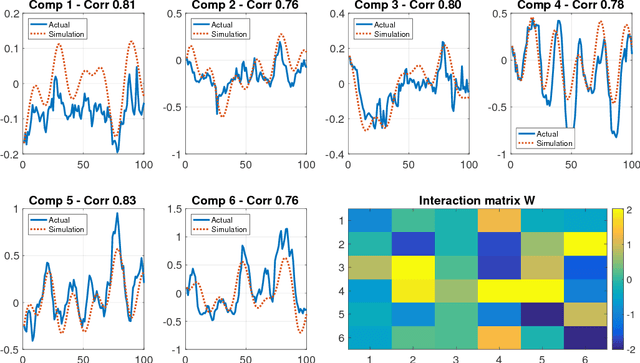
Many real-world data sets, especially in biology, are produced by highly multivariate and nonlinear complex dynamical systems. In this paper, we focus on brain imaging data, including both calcium imaging and functional MRI data. Standard vector-autoregressive models are limited by their linearity assumptions, while nonlinear general-purpose, large-scale temporal models, such as LSTM networks, typically require large amounts of training data, not always readily available in biological applications; furthermore, such models have limited interpretability. We introduce here a novel approach for learning a nonlinear differential equation model aimed at capturing brain dynamics. Specifically, we propose a variable-projection optimization approach to estimate the parameters of the multivariate (coupled) van der Pol oscillator, and demonstrate that such a model can accurately represent nonlinear dynamics of the brain data. Furthermore, in order to improve the predictive accuracy when forecasting future brain-activity time series, we use this analytical model as an unlimited source of simulated data for pretraining LSTM; such model-specific data augmentation approach consistently improves LSTM performance on both calcium and fMRI imaging data.