 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Feedback Loop: From Experience Extraction to Insight Governance in Verbal Reinforcement Learning
Jun 16, 2026Training-free verbal reinforcement learning enables LLM agents to learn from world feedback -- objective signals such as dynamic task outcomes, market returns, or demand forecasts -- by extracting verbal rules from experience and injecting them as context, updating the agent's behavior without parameter changes. However, in non-stationary environments these agents face a retention-forgetting dilemma: retaining stale insights causes negative transfer, while discarding them causes catastrophic forgetting when conditions recur. We identify four requirements for navigating this dilemma -- outcome-driven evaluation, persistent structured evidence, non-monotonic knowledge lifecycle, and compositional governance -- and show that existing methods invest heavily in experience extraction while underinvesting in insight governance. We propose a three-layer architecture -- rules, evidence, and skills -- connected by a feedback-driven curation loop that closes the governance gap. Rules capture distilled experience from world outcomes; evidence logs track each rule's reliability across episodes; skills govern which rules to apply, how to resolve conflicts, and when to abstain. On financial forecasting as a case study, where world feedback is naturally abundant, noisy, and non-stationary, we show that the same accumulated experience either degrades performance below the zero-shot baseline or dramatically improves accuracy and risk-adjusted returns, depending on whether the curation loop is present.
Better Literary Translation: A Multi-Aspect Data Generation and LLM Training Approach
Jun 04, 2026Literary translation poses unique challenges due to the scarcity of high-quality annotated data and the need to balance expression fluency with literary effect. We present a multi-aspect iterative refinement framework that generates high-quality translation references and preference data through specialized LLM translators, each targeting a distinct quality dimension. We leverage the generated data for supervised fine-tuning and reinforcement learning. Experiments show that our generated references outperform the original ground truth for SFT by 8.65 CEA100 points. For reinforcement learning, we find that DPO leads to performance degradation in this setting, while leveraging an explicit reward model for GRPO yields an additional 1.51 point improvement. We attribute this to the stability of two-stage training and GRPO's online exploration capability. Our resulting models, LitMT-8B and LitMT-14B, achieve 67.25 and 69.07 CEA100 respectively on the MetaphorTrans English-to-Chinese literary translation benchmark, competitive with Claude Sonnet 4.5 at 68.43, and demonstrate strong generalization to out-of-domain literary work (i.e., O. Henry).
Ratchet: A Minimal Hygiene Recipe for Self-Evolving LLM Agents
May 21, 2026Self-evolving skill libraries, pioneered by Voyager, let frozen LLM agents accumulate reusable knowledge without weight updates, yet recent evaluation shows that LLM-authored skills deliver $+0.0$pp over no-skill baselines while human-curated ones deliver $+16.2$pp: the bottleneck is not skill authoring but lifecycle management. We introduce \textbf{Ratchet}, a single-agent loop in which a frozen LLM writes, retrieves, curates, and retires its own natural-language skills. Ratchet integrates four candidate hygiene mechanisms: outcome-driven retirement, a bounded active-cap, meta-skill authoring guidance, and pattern canonicalisation. On MBPP+ hard-100 with Claude Opus 4.7, Ratchet lifts held-out pass@1 from a $0.258 \pm 0.047$ baseline to a late-window rolling mean of $0.584$ (peak $0.658 \pm 0.042$) across 100 rounds and 3 seeds, a $+0.328 \pm 0.018$ rolling-mean gain where the no-skill control drifts at $+0.002 \pm 0.005$; the same recipe transfers to an agentic solver on SWE-bench Verified ($+0.22$ peak lift over 20 rounds). Eight ablations (A1--A8) reveal that the minimal working recipe is smaller than our design suggests: retirement and the meta-skill authoring prior are load-bearing, while explicit deduplication (canonicalisation, cover-guard) is subsumed by the meta-skill itself. A non-divergence proposition shows that bounded cap and retirement threshold together prevent expected performance from drifting below the no-skills floor.
Library Drift: Diagnosing and Fixing a Silent Failure Mode in Self-Evolving LLM Skill Libraries
May 19, 2026Self-evolving skill libraries face a silent failure mode we term \emph{library drift}: unbounded skill accumulation without outcome-driven lifecycle management causes retrieval degradation, false-positive injections, and performance stagnation. Recent evaluation confirms the symptom--LLM-authored skills deliver +0.0pp gain while human-curated ones deliver +16.2pp (SkillsBench)--yet the underlying mechanism has not been isolated. We provide (1) a reproducible trigger: ablations that isolate drift--one disables skill injection (flat floor, +0.002), one imposes premature retirement (active harm, $-$0.019); (2) trace-level diagnostics: an append-only evidence log with per-skill contribution scores, attribution verdicts, and router engagement metrics that make the failure visible before it reaches end-task scores; and (3) a verified fix: a minimal governance recipe (outcome-driven retirement + bounded active-cap + meta-skill authoring prior) that lifts held-out pass@1 from a 0.258 baseline to a late-window mean of 0.584 (rolling gain $+$0.328) on MBPP+ hard-100 over 100 rounds. Eight ablations decompose which governance mechanisms are load-bearing and which are subsumed, providing a concrete playbook for diagnosing library drift in any self-evolving agent.
Hindsight Preference Optimization for Financial Time Series Advisory
Apr 27, 2026Time series models predict numbers; decision-makers need advisory -- directional signals with reasoning, actionable suggestions, and risk management. Training language models for such predictive advisory faces a fundamental challenge: quality depends on outcomes unknown at prediction time. We bridge two ideas from reinforcement learning -- using information unavailable during execution to retrospectively generate training signal, and preference alignment -- and propose Hindsight Preference Optimization: observed outcomes let an LLM judge rank candidate advisories on dimensions that scalar metrics cannot capture, producing preference pairs for DPO without human annotation. We apply this to Vision-Language-Model-based predictive advisories on S&P 500 equity time series, demonstrated by a 4B model outperforming its 235B teacher on both accuracy and advisory quality.
Prompt Optimization Is a Coin Flip: Diagnosing When It Helps in Compound AI Systems
Apr 16, 2026Prompt optimization in compound AI systems is statistically indistinguishable from a coin flip: across 72 optimization runs on Claude Haiku (6 methods $\times$ 4 tasks $\times$ 3 repeats), 49% score below zero-shot; on Amazon Nova Lite, the failure rate is even higher. Yet on one task, all six methods improve over zero-shot by up to $+6.8$ points. What distinguishes success from failure? We investigate with 18,000 grid evaluations and 144 optimization runs, testing two assumptions behind end-to-end optimization tools like TextGrad and DSPy: (A) individual prompts are worth optimizing, and (B) agent prompts interact, requiring joint optimization. Interaction effects are never significant ($p > 0.52$, all $F < 1.0$), and optimization helps only when the task has exploitable output structure -- a format the model can produce but does not default to. We provide a two-stage diagnostic: an \$80 ANOVA pre-test for agent coupling, and a 10-minute headroom test that predicts whether optimization is worthwhile -- turning a coin flip into an informed decision.
Do Agent Rules Shape or Distort? Guardrails Beat Guidance in Coding Agents
Apr 13, 2026Developers increasingly guide AI coding agents through natural language instruction files (e.g., CLAUDE.md, .cursorrules), yet no controlled study has measured whether these rules actually improve agent performance or which properties make a rule beneficial. We scrape 679 such files (25,532 rules) from GitHub and conduct the first large-scale empirical evaluation, running over 5,000 agent runs with a state-of-the-art coding agent on SWE-bench Verified. Rules improve performance by 7--14 percentage points, but random rules help as much as expert-curated ones -- suggesting rules work through context priming rather than specific instruction. Negative constraints ("do not refactor unrelated code") are the only individually beneficial rule type, while positive directives ("follow code style") actively hurt -- a pattern we analyze through the lens of potential-based reward shaping (PBRS). Moreover, individual rules are mostly harmful in isolation yet collectively helpful, with no degradation up to 50 rules. These findings expose a hidden reliability risk -- well-intentioned rules routinely degrade agent performance -- and provide a clear principle for safe agent configuration: constrain what agents must not do, rather than prescribing what they should.
Verified Multi-Agent Orchestration: A Plan-Execute-Verify-Replan Framework for Complex Query Resolution
Mar 12, 2026We present Verified Multi-Agent Orchestration (VMAO), a framework that coordinates specialized LLM-based agents through a verification-driven iterative loop. Given a complex query, our system decomposes it into a directed acyclic graph (DAG) of sub-questions, executes them through domain-specific agents in parallel, verifies result completeness via LLM-based evaluation, and adaptively replans to address gaps. The key contributions are: (1) dependency-aware parallel execution over a DAG of sub-questions with automatic context propagation, (2) verification-driven adaptive replanning that uses an LLM-based verifier as an orchestration-level coordination signal, and (3) configurable stop conditions that balance answer quality against resource usage. On 25 expert-curated market research queries, VMAO improves answer completeness from 3.1 to 4.2 and source quality from 2.6 to 4.1 (1-5 scale) compared to a single-agent baseline, demonstrating that orchestration-level verification is an effective mechanism for multi-agent quality assurance.
OpenVIS: Open-vocabulary Video Instance Segmentation
May 26, 2023



We propose and study a new computer vision task named open-vocabulary video instance segmentation (OpenVIS), which aims to simultaneously segment, detect, and track arbitrary objects in a video according to corresponding text descriptions. Compared to the original video instance segmentation, OpenVIS enables users to identify objects of desired categories, regardless of whether those categories were included in the training dataset. To achieve this goal, we propose a two-stage pipeline for proposing high-quality class-agnostic object masks and predicting their corresponding categories via pre-trained VLM. Specifically, we first employ a query-based mask proposal network to generate masks of all potential objects, where we replace the original class head with an instance head trained with a binary object loss, thereby enhancing the class-agnostic mask proposal ability. Then, we introduce a proposal post-processing approach to adapt the proposals better to the pre-trained VLMs, avoiding distortion and unnatural proposal inputs. Meanwhile, to facilitate research on this new task, we also propose an evaluation benchmark that utilizes off-the-shelf datasets to comprehensively assess its performance. Experimentally, the proposed OpenVIS exhibits a remarkable 148\% improvement compared to the full-supervised baselines on BURST, which have been trained on all categories.
SelfGait: A Spatiotemporal Representation Learning Method for Self-supervised Gait Recognition
Mar 27, 2021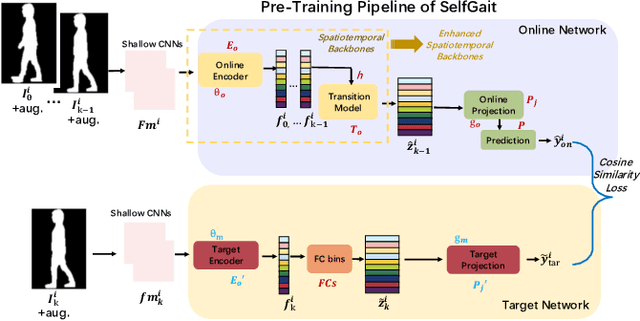
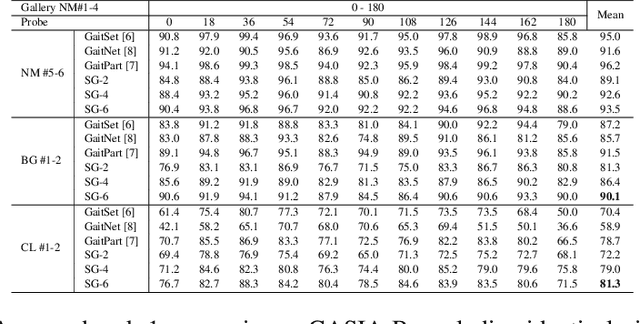
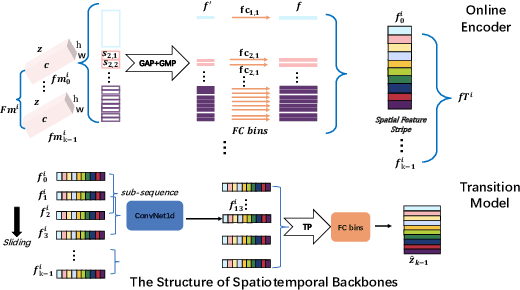
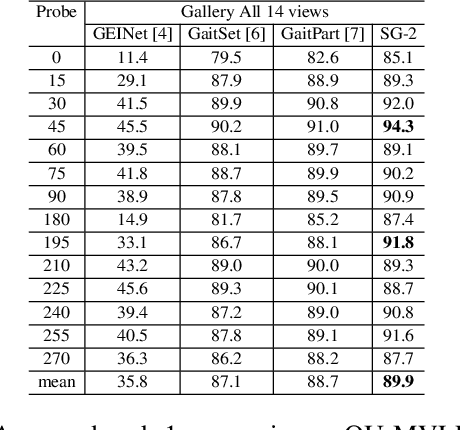
Gait recognition plays a vital role in human identification since gait is a unique biometric feature that can be perceived at a distance. Although existing gait recognition methods can learn gait features from gait sequences in different ways, the performance of gait recognition suffers from insufficient labeled data, especially in some practical scenarios associated with short gait sequences or various clothing styles. It is unpractical to label the numerous gait data. In this work, we propose a self-supervised gait recognition method, termed SelfGait, which takes advantage of the massive, diverse, unlabeled gait data as a pre-training process to improve the representation abilities of spatiotemporal backbones. Specifically, we employ the horizontal pyramid mapping (HPM) and micro-motion template builder (MTB) as our spatiotemporal backbones to capture the multi-scale spatiotemporal representations. Experiments on CASIA-B and OU-MVLP benchmark gait datasets demonstrate the effectiveness of the proposed SelfGait compared with four state-of-the-art gait recognition methods. The source code has been released at https://github.com/EchoItLiu/SelfGait.