 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Semi-supervised Learning for Multi-domain ASR Through Incremental Retraining and Data Filtering
Jun 05, 2025


Fine-tuning pretrained ASR models for specific domains is challenging when labeled data is scarce. But unlabeled audio and labeled data from related domains are often available. We propose an incremental semi-supervised learning pipeline that first integrates a small in-domain labeled set and an auxiliary dataset from a closely related domain, achieving a relative improvement of 4% over no auxiliary data. Filtering based on multi-model consensus or named entity recognition (NER) is then applied to select and iteratively refine pseudo-labels, showing slower performance saturation compared to random selection. Evaluated on the multi-domain Wow call center and Fisher English corpora, it outperforms single-step fine-tuning. Consensus-based filtering outperforms other methods, providing up to 22.3% relative improvement on Wow and 24.8% on Fisher over single-step fine-tuning with random selection. NER is the second-best filter, providing competitive performance at a lower computational cost.
IDIAPers @ Causal News Corpus 2022: Efficient Causal Relation Identification Through a Prompt-based Few-shot Approach
Sep 08, 2022
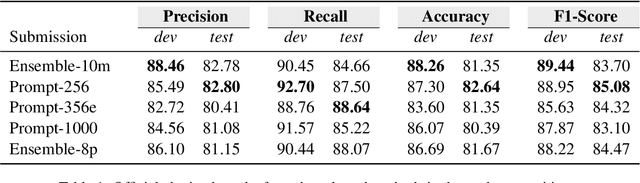
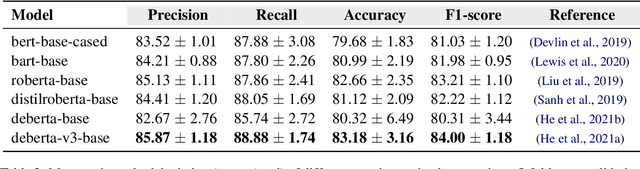
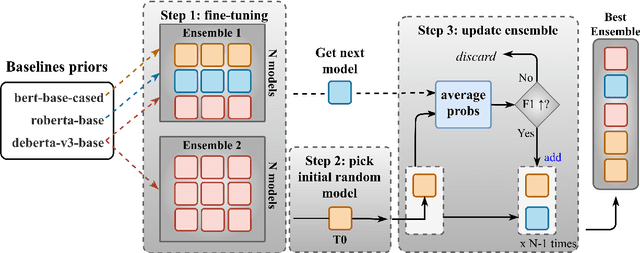
In this paper, we describe our participation in the subtask 1 of CASE-2022, Event Causality Identification with Casual News Corpus. We address the Causal Relation Identification (CRI) task by exploiting a set of simple yet complementary techniques for fine-tuning language models (LMs) on a small number of annotated examples (i.e., a few-shot configuration). We follow a prompt-based prediction approach for fine-tuning LMs in which the CRI task is treated as a masked language modeling problem (MLM). This approach allows LMs natively pre-trained on MLM problems to directly generate textual responses to CRI-specific prompts. We compare the performance of this method against ensemble techniques trained on the entire dataset. Our best-performing submission was trained only with 256 instances per class, a small portion of the entire dataset, and yet was able to obtain the second-best precision (0.82), third-best accuracy (0.82), and an F1-score (0.85) very close to what was reported by the winner team (0.86).