 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020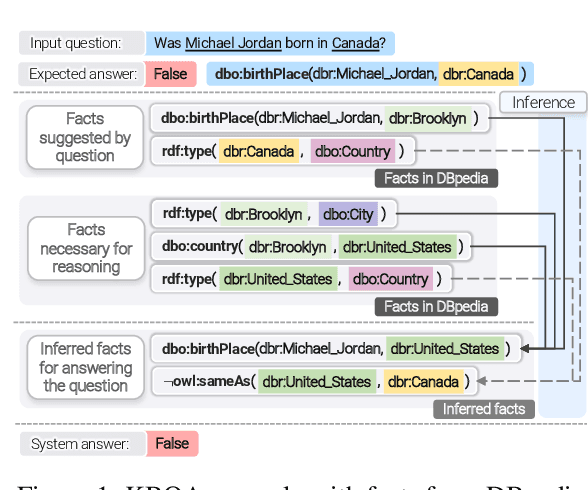
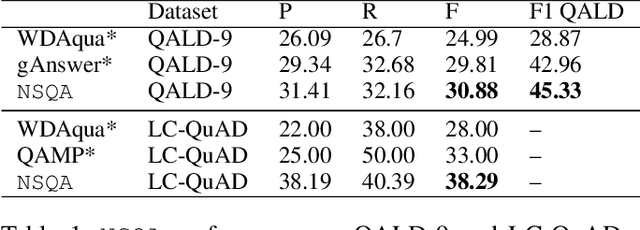
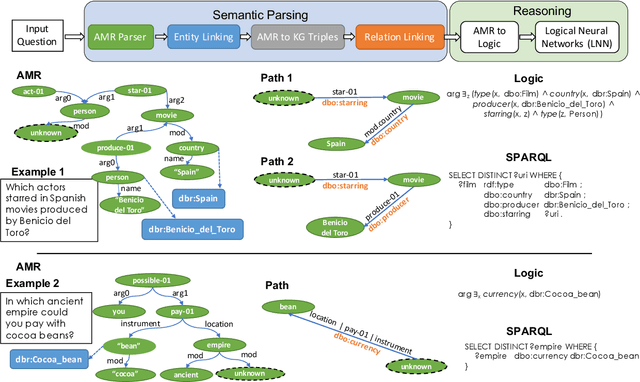

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
Oct 08, 2020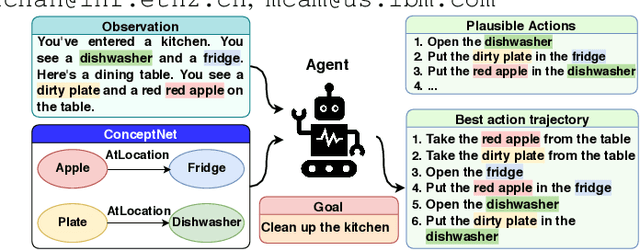
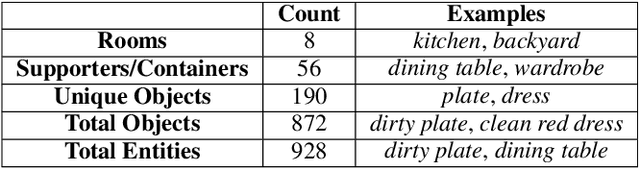


Text-based games have emerged as an important test-bed for Reinforcement Learning (RL) research, requiring RL agents to combine grounded language understanding with sequential decision making. In this paper, we examine the problem of infusing RL agents with commonsense knowledge. Such knowledge would allow agents to efficiently act in the world by pruning out implausible actions, and to perform look-ahead planning to determine how current actions might affect future world states. We design a new text-based gaming environment called TextWorld Commonsense (TWC) for training and evaluating RL agents with a specific kind of commonsense knowledge about objects, their attributes, and affordances. We also introduce several baseline RL agents which track the sequential context and dynamically retrieve the relevant commonsense knowledge from ConceptNet. We show that agents which incorporate commonsense knowledge in TWC perform better, while acting more efficiently. We conduct user-studies to estimate human performance on TWC and show that there is ample room for future improvement.
Reading Comprehension as Natural Language Inference: A Semantic Analysis
Oct 04, 2020
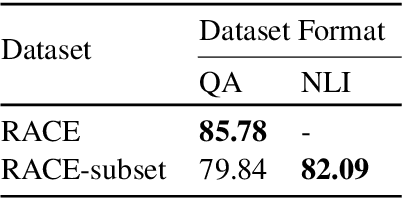
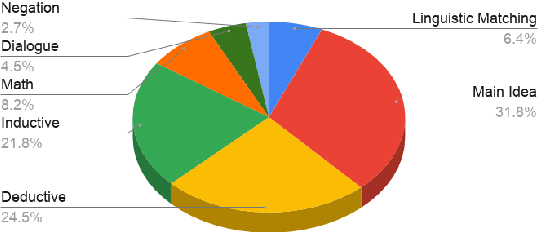
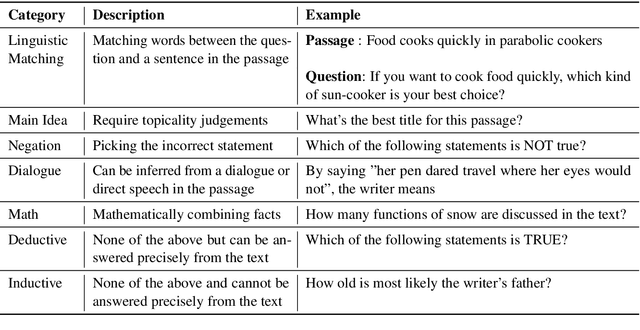
In the recent past, Natural language Inference (NLI) has gained significant attention, particularly given its promise for downstream NLP tasks. However, its true impact is limited and has not been well studied. Therefore, in this paper, we explore the utility of NLI for one of the most prominent downstream tasks, viz. Question Answering (QA). We transform the one of the largest available MRC dataset (RACE) to an NLI form, and compare the performances of a state-of-the-art model (RoBERTa) on both these forms. We propose new characterizations of questions, and evaluate the performance of QA and NLI models on these categories. We highlight clear categories for which the model is able to perform better when the data is presented in a coherent entailment form, and a structured question-answer concatenation form, respectively.
Looking Beyond Sentence-Level Natural Language Inference for Downstream Tasks
Sep 18, 2020
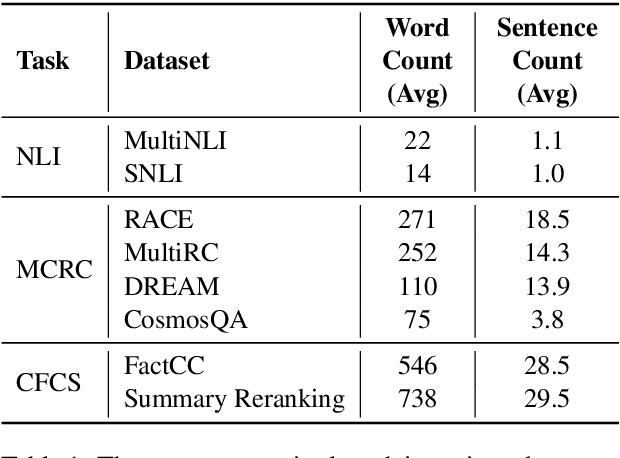
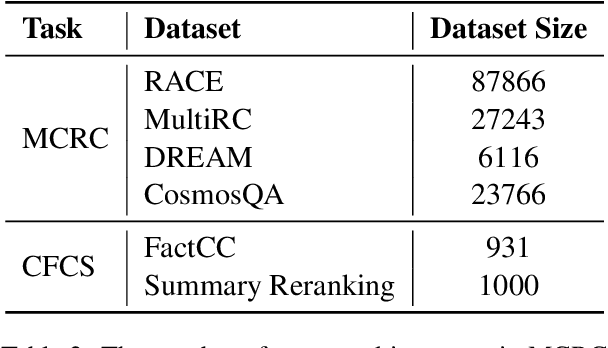
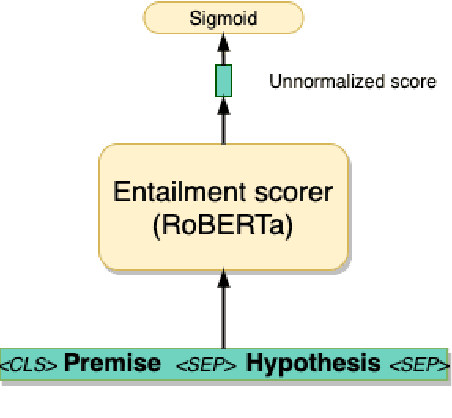
In recent years, the Natural Language Inference (NLI) task has garnered significant attention, with new datasets and models achieving near human-level performance on it. However, the full promise of NLI -- particularly that it learns knowledge that should be generalizable to other downstream NLP tasks -- has not been realized. In this paper, we study this unfulfilled promise from the lens of two downstream tasks: question answering (QA), and text summarization. We conjecture that a key difference between the NLI datasets and these downstream tasks concerns the length of the premise; and that creating new long premise NLI datasets out of existing QA datasets is a promising avenue for training a truly generalizable NLI model. We validate our conjecture by showing competitive results on the task of QA and obtaining the best reported results on the task of Checking Factual Correctness of Summaries.
Type-augmented Relation Prediction in Knowledge Graphs
Sep 16, 2020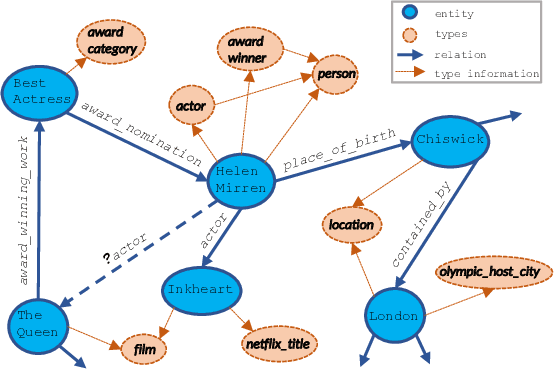

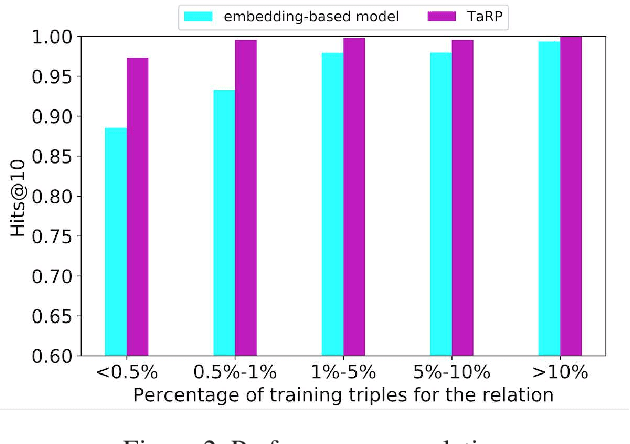
Knowledge graphs (KGs) are of great importance to many real world applications, but they generally suffer from incomplete information in the form of missing relations between entities. Knowledge graph completion (also known as relation prediction) is the task of inferring missing facts given existing ones. Most of the existing work is proposed by maximizing the likelihood of observed instance-level triples. Not much attention, however, is paid to the ontological information, such as type information of entities and relations. In this work, we propose a type-augmented relation prediction (TaRP) method, where we apply both the type information and instance-level information for relation prediction. In particular, type information and instance-level information are encoded as prior probabilities and likelihoods of relations respectively, and are combined by following Bayes' rule. Our proposed TaRP method achieves significantly better performance than state-of-the-art methods on three benchmark datasets: FB15K, YAGO26K-906, and DB111K-174. In addition, we show that TaRP achieves significantly improved data efficiency. More importantly, the type information extracted from a specific dataset can generalize well to other datasets through the proposed TaRP model.
Leveraging Semantic Parsing for Relation Linking over Knowledge Bases
Sep 16, 2020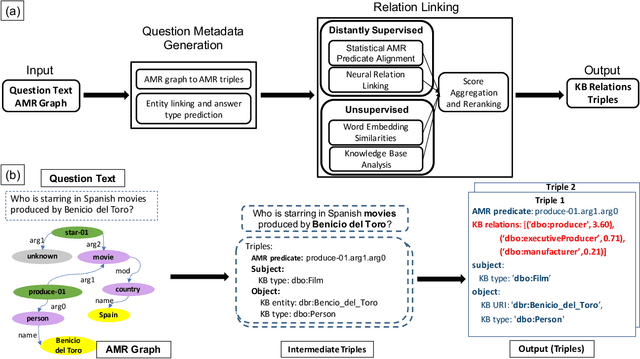

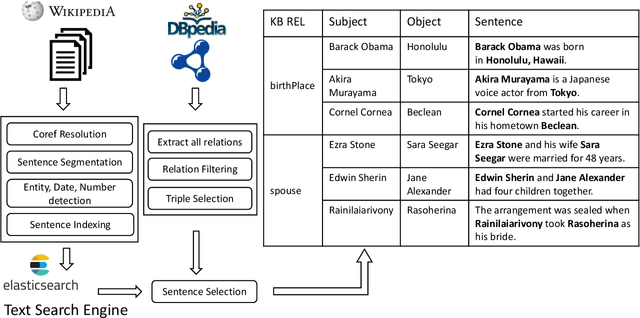
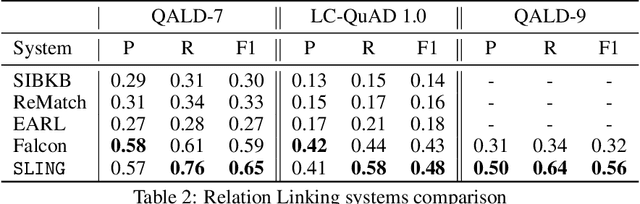
Knowledgebase question answering systems are heavily dependent on relation extraction and linking modules. However, the task of extracting and linking relations from text to knowledgebases faces two primary challenges; the ambiguity of natural language and lack of training data. To overcome these challenges, we present SLING, a relation linking framework which leverages semantic parsing using Abstract Meaning Representation (AMR) and distant supervision. SLING integrates multiple relation linking approaches that capture complementary signals such as linguistic cues, rich semantic representation, and information from the knowledgebase. The experiments on relation linking using three KBQA datasets; QALD-7, QALD-9, and LC-QuAD 1.0 demonstrate that the proposed approach achieves state-of-the-art performance on all benchmarks.
Enhancing Text-based Reinforcement Learning Agents with Commonsense Knowledge
May 02, 2020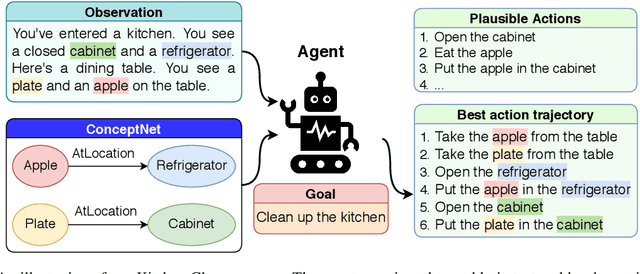
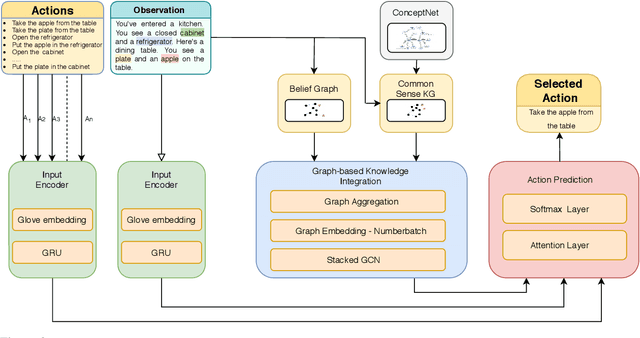
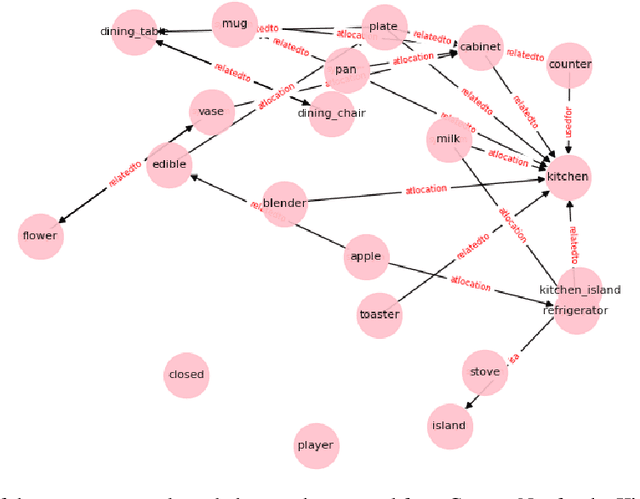
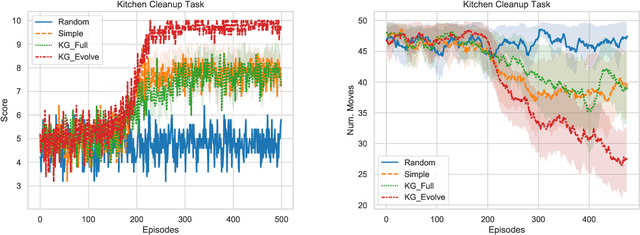
In this paper, we consider the recent trend of evaluating progress on reinforcement learning technology by using text-based environments and games as evaluation environments. This reliance on text brings advances in natural language processing into the ambit of these agents, with a recurring thread being the use of external knowledge to mimic and better human-level performance. We present one such instantiation of agents that use commonsense knowledge from ConceptNet to show promising performance on two text-based environments.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019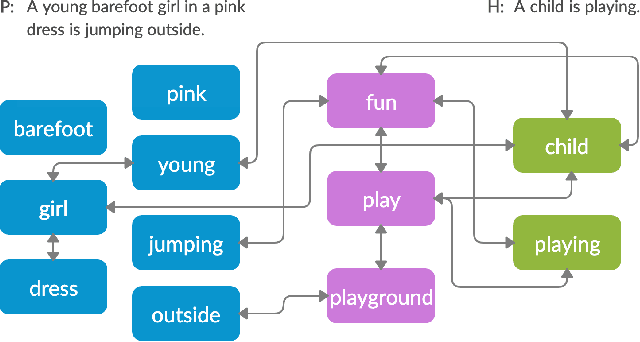

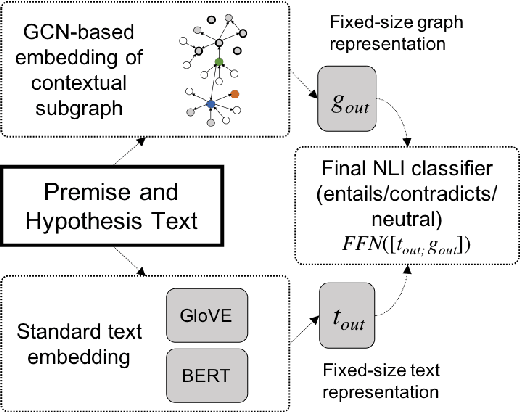
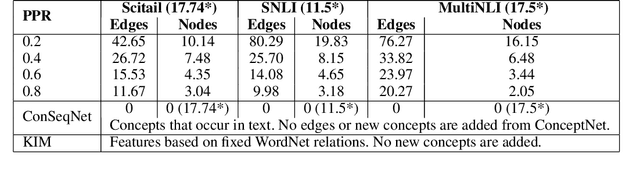
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
Heuristics for Interpretable Knowledge Graph Contextualization
Nov 05, 2019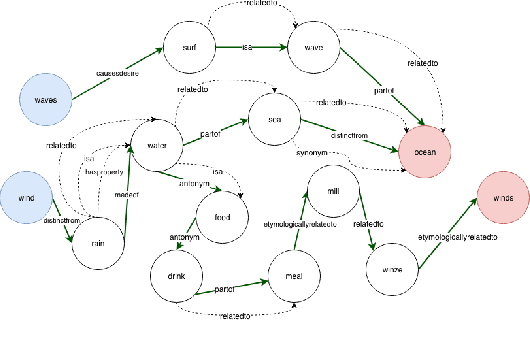

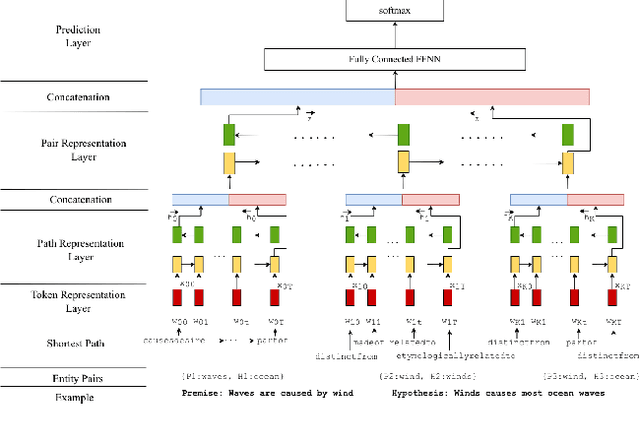
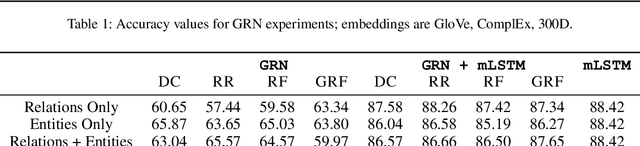
In this paper, we introduce the problem of knowledge graph contextualization that is, given a specific context, the problem of extracting the most relevant sub-graph of a given knowledge graph. The context in the case of this paper is defined to be the textual entailment problem, and more specifically an instance of that problem where the entailment relationship between two sentences P and H has to be predicted automatically. This prediction takes the form of a classification task, and we seek to provide that task with the most relevant external knowledge while eliminating as much noise as possible. We base our methodology on finding the shortest paths in the cost-customized external knowledge graph that connect P and H, and build a series of methods starting with manually curated search heuristics and culminating in automatically extracted heuristics to find such paths and build the most relevant sub-graph. We evaluate our approaches by measuring the accuracy of the classification on the textual entailment problem, and show that modulating the external knowledge that is used has an impact on performance.
A Deep Reinforcement Learning based Approach to Learning Transferable Proof Guidance Strategies
Nov 05, 2019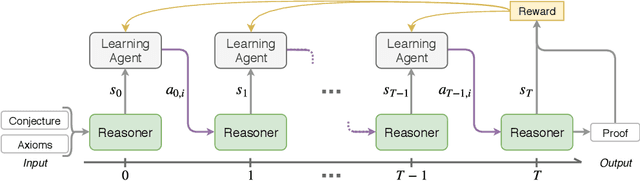
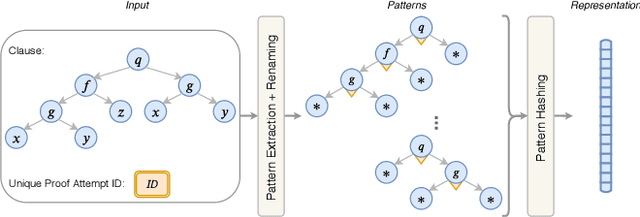

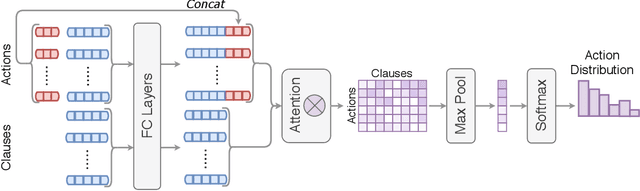
Traditional first-order logic (FOL) reasoning systems usually rely on manual heuristics for proof guidance. We propose TRAIL: a system that learns to perform proof guidance using reinforcement learning. A key design principle of our system is that it is general enough to allow transfer to problems in different domains that do not share the same vocabulary of the training set. To do so, we developed a novel representation of the internal state of a prover in terms of clauses and inference actions, and a novel neural-based attention mechanism to learn interactions between clauses. We demonstrate that this approach enables the system to generalize from training to test data across domains with different vocabularies, suggesting that the neural architecture in TRAIL is well suited for representing and processing of logical formalisms.