 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Social Intelligence in AI Agents: Technical Challenges and Open Questions
Apr 17, 2024Building socially-intelligent AI agents (Social-AI) is a multidisciplinary, multimodal research goal that involves creating agents that can sense, perceive, reason about, learn from, and respond to affect, behavior, and cognition of other agents (human or artificial). Progress towards Social-AI has accelerated in the past decade across several computing communities, including natural language processing, machine learning, robotics, human-machine interaction, computer vision, and speech. Natural language processing, in particular, has been prominent in Social-AI research, as language plays a key role in constructing the social world. In this position paper, we identify a set of underlying technical challenges and open questions for researchers across computing communities to advance Social-AI. We anchor our discussion in the context of social intelligence concepts and prior progress in Social-AI research.
Localized Symbolic Knowledge Distillation for Visual Commonsense Models
Dec 12, 2023



Instruction following vision-language (VL) models offer a flexible interface that supports a broad range of multimodal tasks in a zero-shot fashion. However, interfaces that operate on full images do not directly enable the user to "point to" and access specific regions within images. This capability is important not only to support reference-grounded VL benchmarks, but also, for practical applications that require precise within-image reasoning. We build Localized Visual Commonsense models, which allow users to specify (multiple) regions as input. We train our model by sampling localized commonsense knowledge from a large language model (LLM): specifically, we prompt an LLM to collect commonsense knowledge given a global literal image description and a local literal region description automatically generated by a set of VL models. With a separately trained critic model that selects high-quality examples, we find that training on the localized commonsense corpus can successfully distill existing VL models to support a reference-as-input interface. Empirical results and human evaluations in a zero-shot setup demonstrate that our distillation method results in more precise VL models of reasoning compared to a baseline of passing a generated referring expression to an LLM.
MMOE: Mixture of Multimodal Interaction Experts
Nov 16, 2023



Multimodal machine learning, which studies the information and interactions across various input modalities, has made significant advancements in understanding the relationship between images and descriptive text. However, this is just a portion of the potential multimodal interactions seen in the real world and does not include new interactions between conflicting utterances and gestures in predicting sarcasm, for example. Notably, the current methods for capturing shared information often do not extend well to these more nuanced interactions, sometimes performing as low as 50% in binary classification. In this paper, we address this problem via a new approach called MMOE, which stands for a mixture of multimodal interaction experts. Our method automatically classifies data points from unlabeled multimodal datasets by their interaction type and employs specialized models for each specific interaction. Based on our experiments, this approach improves performance on these challenging interactions by more than 10%, leading to an overall increase of 2% for tasks like sarcasm prediction. As a result, interaction quantification provides new insights for dataset analysis and yields simple approaches that obtain state-of-the-art performance.
Think Twice: Perspective-Taking Improves Large Language Models' Theory-of-Mind Capabilities
Nov 16, 2023



Human interactions are deeply rooted in the interplay of thoughts, beliefs, and desires made possible by Theory of Mind (ToM): our cognitive ability to understand the mental states of ourselves and others. Although ToM may come naturally to us, emulating it presents a challenge to even the most advanced Large Language Models (LLMs). Recent improvements to LLMs' reasoning capabilities from simple yet effective prompting techniques such as Chain-of-Thought have seen limited applicability to ToM. In this paper, we turn to the prominent cognitive science theory "Simulation Theory" to bridge this gap. We introduce SimToM, a novel two-stage prompting framework inspired by Simulation Theory's notion of perspective-taking. To implement this idea on current ToM benchmarks, SimToM first filters context based on what the character in question knows before answering a question about their mental state. Our approach, which requires no additional training and minimal prompt-tuning, shows substantial improvement over existing methods, and our analysis reveals the importance of perspective-taking to Theory-of-Mind capabilities. Our findings suggest perspective-taking as a promising direction for future research into improving LLMs' ToM capabilities.
MultiIoT: Towards Large-scale Multisensory Learning for the Internet of Things
Nov 10, 2023



The Internet of Things (IoT), the network integrating billions of smart physical devices embedded with sensors, software, and communication technologies for the purpose of connecting and exchanging data with other devices and systems, is a critical and rapidly expanding component of our modern world. The IoT ecosystem provides a rich source of real-world modalities such as motion, thermal, geolocation, imaging, depth, sensors, video, and audio for prediction tasks involving the pose, gaze, activities, and gestures of humans as well as the touch, contact, pose, 3D of physical objects. Machine learning presents a rich opportunity to automatically process IoT data at scale, enabling efficient inference for impact in understanding human wellbeing, controlling physical devices, and interconnecting smart cities. To develop machine learning technologies for IoT, this paper proposes MultiIoT, the most expansive IoT benchmark to date, encompassing over 1.15 million samples from 12 modalities and 8 tasks. MultiIoT introduces unique challenges involving (1) learning from many sensory modalities, (2) fine-grained interactions across long temporal ranges, and (3) extreme heterogeneity due to unique structure and noise topologies in real-world sensors. We also release a set of strong modeling baselines, spanning modality and task-specific methods to multisensory and multitask models to encourage future research in multisensory representation learning for IoT.
Comparative Knowledge Distillation
Nov 03, 2023



In the era of large scale pretrained models, Knowledge Distillation (KD) serves an important role in transferring the wisdom of computationally heavy teacher models to lightweight, efficient student models while preserving performance. Traditional KD paradigms, however, assume readily available access to teacher models for frequent inference -- a notion increasingly at odds with the realities of costly, often proprietary, large scale models. Addressing this gap, our paper considers how to minimize the dependency on teacher model inferences in KD in a setting we term Few Teacher Inference Knowledge Distillation (FTI KD). We observe that prevalent KD techniques and state of the art data augmentation strategies fall short in this constrained setting. Drawing inspiration from educational principles that emphasize learning through comparison, we propose Comparative Knowledge Distillation (CKD), which encourages student models to understand the nuanced differences in a teacher model's interpretations of samples. Critically, CKD provides additional learning signals to the student without making additional teacher calls. We also extend the principle of CKD to groups of samples, enabling even more efficient learning from limited teacher calls. Empirical evaluation across varied experimental settings indicates that CKD consistently outperforms state of the art data augmentation and KD techniques.
Towards Vision-Language Mechanistic Interpretability: A Causal Tracing Tool for BLIP
Aug 27, 2023



Mechanistic interpretability seeks to understand the neural mechanisms that enable specific behaviors in Large Language Models (LLMs) by leveraging causality-based methods. While these approaches have identified neural circuits that copy spans of text, capture factual knowledge, and more, they remain unusable for multimodal models since adapting these tools to the vision-language domain requires considerable architectural changes. In this work, we adapt a unimodal causal tracing tool to BLIP to enable the study of the neural mechanisms underlying image-conditioned text generation. We demonstrate our approach on a visual question answering dataset, highlighting the causal relevance of later layer representations for all tokens. Furthermore, we release our BLIP causal tracing tool as open source to enable further experimentation in vision-language mechanistic interpretability by the community. Our code is available at https://github.com/vedantpalit/Towards-Vision-Language-Mechanistic-Interpretability.
MultiZoo & MultiBench: A Standardized Toolkit for Multimodal Deep Learning
Jun 28, 2023

Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiZoo, a public toolkit consisting of standardized implementations of > 20 core multimodal algorithms and MultiBench, a large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. Together, these provide an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, we offer a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench paves the way towards a better understanding of the capabilities and limitations of multimodal models, while ensuring ease of use, accessibility, and reproducibility. Our toolkits are publicly available, will be regularly updated, and welcome inputs from the community.
Factorized Contrastive Learning: Going Beyond Multi-view Redundancy
Jun 08, 2023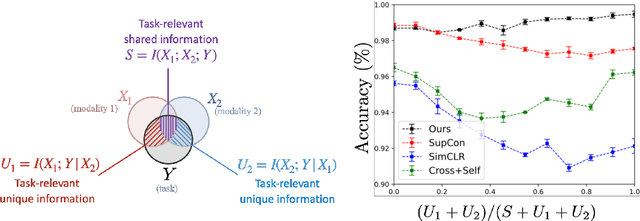
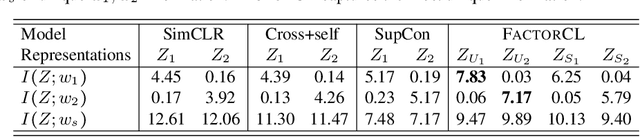
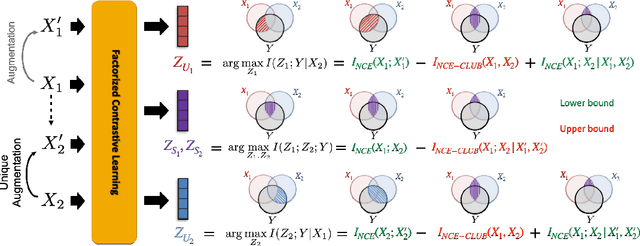
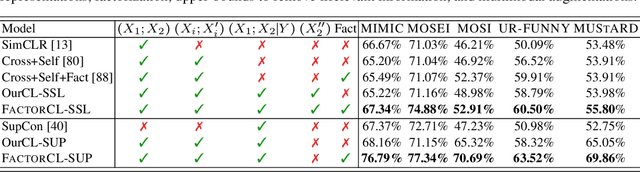
In a wide range of multimodal tasks, contrastive learning has become a particularly appealing approach since it can successfully learn representations from abundant unlabeled data with only pairing information (e.g., image-caption or video-audio pairs). Underpinning these approaches is the assumption of multi-view redundancy - that shared information between modalities is necessary and sufficient for downstream tasks. However, in many real-world settings, task-relevant information is also contained in modality-unique regions: information that is only present in one modality but still relevant to the task. How can we learn self-supervised multimodal representations to capture both shared and unique information relevant to downstream tasks? This paper proposes FactorCL, a new multimodal representation learning method to go beyond multi-view redundancy. FactorCL is built from three new contributions: (1) factorizing task-relevant information into shared and unique representations, (2) capturing task-relevant information via maximizing MI lower bounds and removing task-irrelevant information via minimizing MI upper bounds, and (3) multimodal data augmentations to approximate task relevance without labels. On large-scale real-world datasets, FactorCL captures both shared and unique information and achieves state-of-the-art results on six benchmarks.
Multimodal Learning Without Labeled Multimodal Data: Guarantees and Applications
Jun 07, 2023



In many machine learning systems that jointly learn from multiple modalities, a core research question is to understand the nature of multimodal interactions: the emergence of new task-relevant information during learning from both modalities that was not present in either alone. We study this challenge of interaction quantification in a semi-supervised setting with only labeled unimodal data and naturally co-occurring multimodal data (e.g., unlabeled images and captions, video and corresponding audio) but when labeling them is time-consuming. Using a precise information-theoretic definition of interactions, our key contributions are the derivations of lower and upper bounds to quantify the amount of multimodal interactions in this semi-supervised setting. We propose two lower bounds based on the amount of shared information between modalities and the disagreement between separately trained unimodal classifiers, and derive an upper bound through connections to approximate algorithms for min-entropy couplings. We validate these estimated bounds and show how they accurately track true interactions. Finally, two semi-supervised multimodal applications are explored based on these theoretical results: (1) analyzing the relationship between multimodal performance and estimated interactions, and (2) self-supervised learning that embraces disagreement between modalities beyond agreement as is typically done.