 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report
Jan 28, 2026We present Foundation-Sec-8B-Reasoning, the first open-source native reasoning model for cybersecurity. Built upon our previously released Foundation-Sec-8B base model (derived from Llama-3.1-8B-Base), the model is trained through a two-stage process combining supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR). Our training leverages proprietary reasoning data spanning cybersecurity analysis, instruction-following, and mathematical reasoning. Evaluation across 10 cybersecurity benchmarks and 10 general-purpose benchmarks demonstrates performance competitive with significantly larger models on cybersecurity tasks while maintaining strong general capabilities. The model shows effective generalization on multi-hop reasoning tasks and strong safety performance when deployed with appropriate system prompts and guardrails. This work demonstrates that domain-specialized reasoning models can achieve strong performance on specialized tasks while maintaining broad general capabilities. We release the model publicly at https://huggingface.co/fdtn-ai/Foundation-Sec-8B-Reasoning.
Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report
Apr 28, 2025



As transformer-based large language models (LLMs) increasingly permeate society, they have revolutionized domains such as software engineering, creative writing, and digital arts. However, their adoption in cybersecurity remains limited due to challenges like scarcity of specialized training data and complexity of representing cybersecurity-specific knowledge. To address these gaps, we present Foundation-Sec-8B, a cybersecurity-focused LLM built on the Llama 3.1 architecture and enhanced through continued pretraining on a carefully curated cybersecurity corpus. We evaluate Foundation-Sec-8B across both established and new cybersecurity benchmarks, showing that it matches Llama 3.1-70B and GPT-4o-mini in certain cybersecurity-specific tasks. By releasing our model to the public, we aim to accelerate progress and adoption of AI-driven tools in both public and private cybersecurity contexts.
Adversarial Reasoning at Jailbreaking Time
Feb 03, 2025As large language models (LLMs) are becoming more capable and widespread, the study of their failure cases is becoming increasingly important. Recent advances in standardizing, measuring, and scaling test-time compute suggest new methodologies for optimizing models to achieve high performance on hard tasks. In this paper, we apply these advances to the task of model jailbreaking: eliciting harmful responses from aligned LLMs. We develop an adversarial reasoning approach to automatic jailbreaking via test-time computation that achieves SOTA attack success rates (ASR) against many aligned LLMs, even the ones that aim to trade inference-time compute for adversarial robustness. Our approach introduces a new paradigm in understanding LLM vulnerabilities, laying the foundation for the development of more robust and trustworthy AI systems.
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
Dec 04, 2023While Large Language Models (LLMs) display versatile functionality, they continue to generate harmful, biased, and toxic content, as demonstrated by the prevalence of human-designed jailbreaks. In this work, we present Tree of Attacks with Pruning (TAP), an automated method for generating jailbreaks that only requires black-box access to the target LLM. TAP utilizes an LLM to iteratively refine candidate (attack) prompts using tree-of-thoughts reasoning until one of the generated prompts jailbreaks the target. Crucially, before sending prompts to the target, TAP assesses them and prunes the ones unlikely to result in jailbreaks. Using tree-of-thought reasoning allows TAP to navigate a large search space of prompts and pruning reduces the total number of queries sent to the target. In empirical evaluations, we observe that TAP generates prompts that jailbreak state-of-the-art LLMs (including GPT4 and GPT4-Turbo) for more than 80% of the prompts using only a small number of queries. This significantly improves upon the previous state-of-the-art black-box method for generating jailbreaks.
Instance Specific Approximations for Submodular Maximization
Feb 23, 2021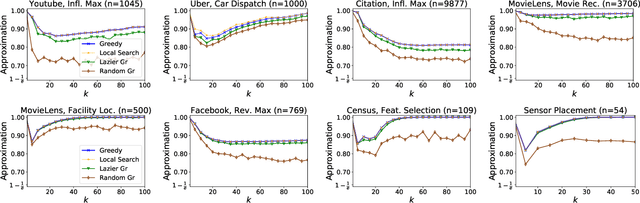
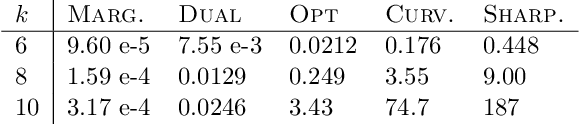
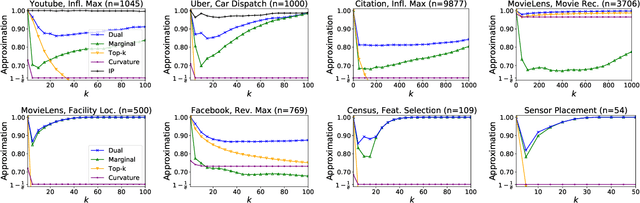
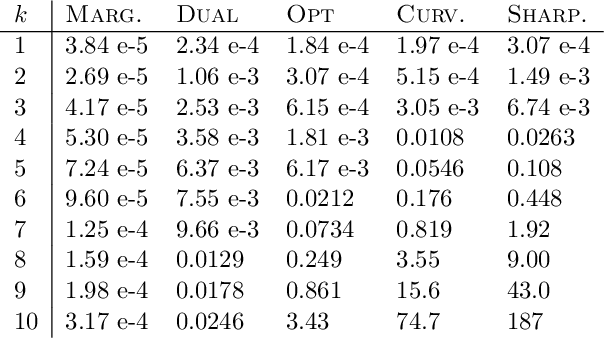
For many optimization problems in machine learning, finding an optimal solution is computationally intractable and we seek algorithms that perform well in practice. Since computational intractability often results from pathological instances, we look for methods to benchmark the performance of algorithms against optimal solutions on real-world instances. The main challenge is that an optimal solution cannot be efficiently computed for intractable problems, and we therefore often do not know how far a solution is from being optimal. A major question is therefore how to measure the performance of an algorithm in comparison to an optimal solution on instances we encounter in practice. In this paper, we address this question in the context of submodular optimization problems. For the canonical problem of submodular maximization under a cardinality constraint, it is intractable to compute a solution that is better than a $1-1/e \approx 0.63$ fraction of the optimum. Algorithms like the celebrated greedy algorithm are guaranteed to achieve this $1-1/e$ bound on any instance and are used in practice. Our main contribution is not a new algorithm for submodular maximization but an analytical method that measures how close an algorithm for submodular maximization is to optimal on a given problem instance. We use this method to show that on a wide variety of real-world datasets and objectives, the approximation of the solution found by greedy goes well beyond $1-1/e$ and is often at least 0.95. We develop this method using a novel technique that lower bounds the objective of a dual minimization problem to obtain an upper bound on the value of an optimal solution to the primal maximization problem.
Adversarial Attacks on Binary Image Recognition Systems
Oct 22, 2020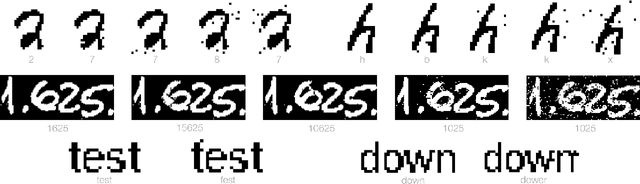
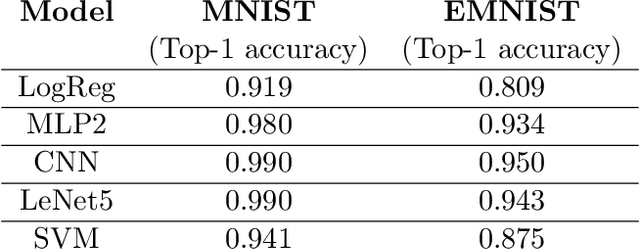
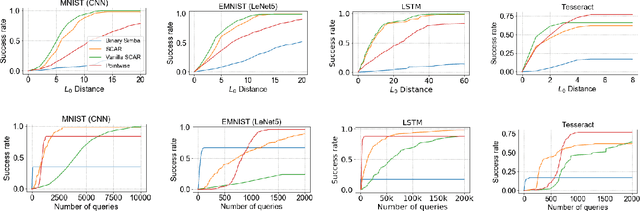

We initiate the study of adversarial attacks on models for binary (i.e. black and white) image classification. Although there has been a great deal of work on attacking models for colored and grayscale images, little is known about attacks on models for binary images. Models trained to classify binary images are used in text recognition applications such as check processing, license plate recognition, invoice processing, and many others. In contrast to colored and grayscale images, the search space of attacks on binary images is extremely restricted and noise cannot be hidden with minor perturbations in each pixel. Thus, the optimization landscape of attacks on binary images introduces new fundamental challenges. In this paper we introduce a new attack algorithm called SCAR, designed to fool classifiers of binary images. We show that SCAR significantly outperforms existing $L_0$ attacks applied to the binary setting and use it to demonstrate the vulnerability of real-world text recognition systems. SCAR's strong performance in practice contrasts with the existence of classifiers that are provably robust to large perturbations. In many cases, altering a single pixel is sufficient to trick Tesseract, a popular open-source text recognition system, to misclassify a word as a different word in the English dictionary. We also license software from providers of check processing systems to most of the major US banks and demonstrate the vulnerability of check recognitions for mobile deposits. These systems are substantially harder to fool since they classify both the handwritten amounts in digits and letters, independently. Nevertheless, we generalize SCAR to design attacks that fool state-of-the-art check processing systems using unnoticeable perturbations that lead to misclassification of deposit amounts. Consequently, this is a powerful method to perform financial fraud.
An Optimal Elimination Algorithm for Learning a Best Arm
Jun 20, 2020We consider the classic problem of $(\epsilon,\delta)$-PAC learning a best arm where the goal is to identify with confidence $1-\delta$ an arm whose mean is an $\epsilon$-approximation to that of the highest mean arm in a multi-armed bandit setting. This problem is one of the most fundamental problems in statistics and learning theory, yet somewhat surprisingly its worst-case sample complexity is not well understood. In this paper, we propose a new approach for $(\epsilon,\delta)$-PAC learning a best arm. This approach leads to an algorithm whose sample complexity converges to \emph{exactly} the optimal sample complexity of $(\epsilon,\delta)$-learning the mean of $n$ arms separately and we complement this result with a conditional matching lower bound. More specifically:
Causal Mediation Analysis for Interpreting Neural NLP: The Case of Gender Bias
Apr 26, 2020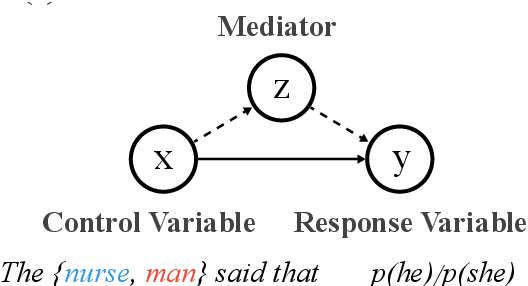
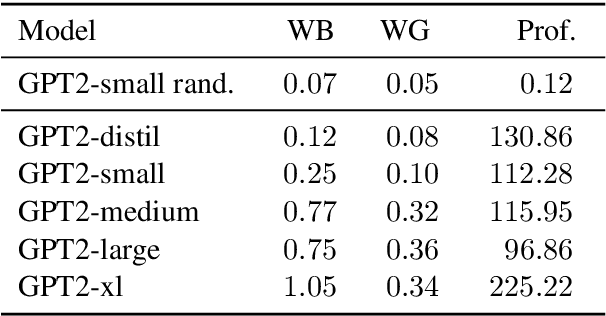

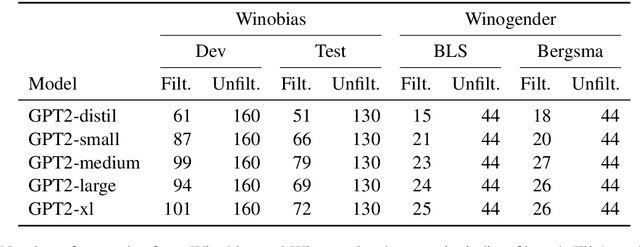
Common methods for interpreting neural models in natural language processing typically examine either their structure or their behavior, but not both. We propose a methodology grounded in the theory of causal mediation analysis for interpreting which parts of a model are causally implicated in its behavior. It enables us to analyze the mechanisms by which information flows from input to output through various model components, known as mediators. We apply this methodology to analyze gender bias in pre-trained Transformer language models. We study the role of individual neurons and attention heads in mediating gender bias across three datasets designed to gauge a model's sensitivity to gender bias. Our mediation analysis reveals that gender bias effects are (i) sparse, concentrated in a small part of the network; (ii) synergistic, amplified or repressed by different components; and (iii) decomposable into effects flowing directly from the input and indirectly through the mediators.
Robustness from Simple Classifiers
Feb 21, 2020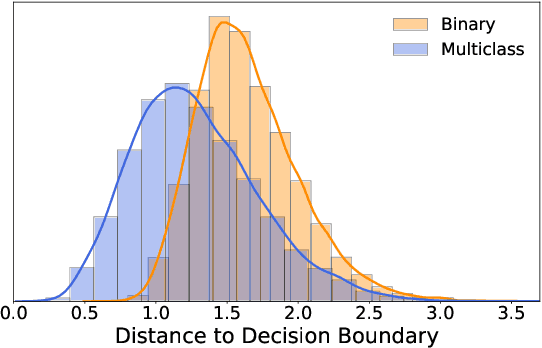
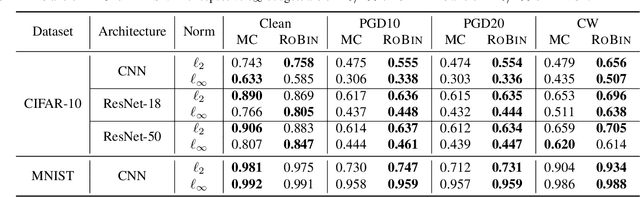
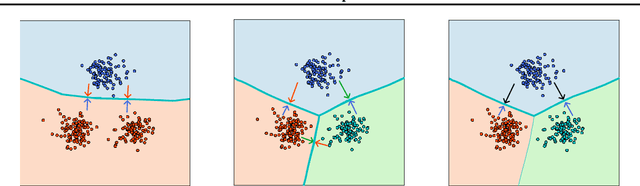
Despite the vast success of Deep Neural Networks in numerous application domains, it has been shown that such models are not robust i.e., they are vulnerable to small adversarial perturbations of the input. While extensive work has been done on why such perturbations occur or how to successfully defend against them, we still do not have a complete understanding of robustness. In this work, we investigate the connection between robustness and simplicity. We find that simpler classifiers, formed by reducing the number of output classes, are less susceptible to adversarial perturbations. Consequently, we demonstrate that decomposing a complex multiclass model into an aggregation of binary models enhances robustness. This behavior is consistent across different datasets and model architectures and can be combined with known defense techniques such as adversarial training. Moreover, we provide further evidence of a disconnect between standard and robust learning regimes. In particular, we show that elaborate label information can help standard accuracy but harm robustness.
The FAST Algorithm for Submodular Maximization
Jul 14, 2019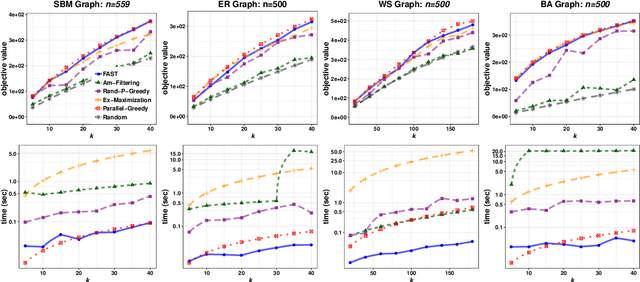
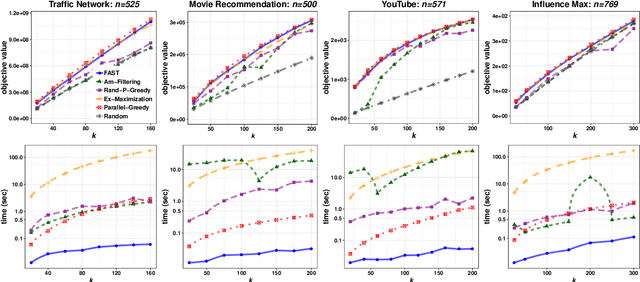
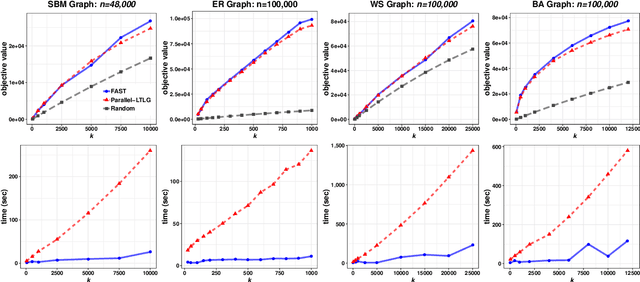
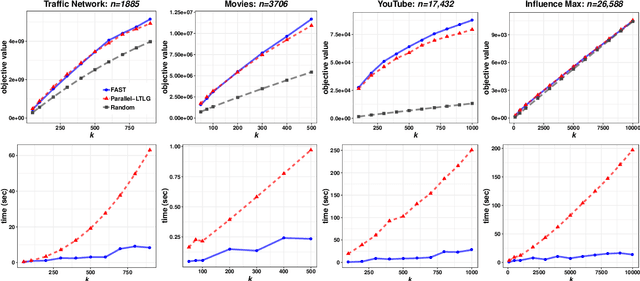
In this paper we describe a new algorithm called Fast Adaptive Sequencing Technique (FAST) for maximizing a monotone submodular function under a cardinality constraint $k$ whose approximation ratio is arbitrarily close to $1-1/e$, is $O(\log(n) \log^2(\log k))$ adaptive, and uses a total of $O(n \log\log(k))$ queries. Recent algorithms have comparable guarantees in terms of asymptotic worst case analysis, but their actual number of rounds and query complexity depend on very large constants and polynomials in terms of precision and confidence, making them impractical for large data sets. Our main contribution is a design that is extremely efficient both in terms of its non-asymptotic worst case query complexity and number of rounds, and in terms of its practical runtime. We show that this algorithm outperforms any algorithm for submodular maximization we are aware of, including hyper-optimized parallel versions of state-of-the-art serial algorithms, by running experiments on large data sets. These experiments show FAST is orders of magnitude faster than the state-of-the-art.