 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAPO: Fully Automated Prompt Optimization of Multi-Step LLM Pipelines
Jun 20, 2026Multi-step LLM pipelines fail through interactions among retrieval, reasoning, and formatting steps, so prompt-only optimization can miss bottlenecks in the chain. We present Fully Automated Prompt Optimization (FAPO), a framework that lets Claude Code optimize an LLM pipeline inside a standardized codebase. FAPO evaluates a pipeline, inspects intermediate steps, diagnoses failures, proposes scoped changes, and validates variants repeatedly to optimize against a score function. It first tries prompt edits and, only when prompt optimization appears insufficient, changes chain structure within the permitted scope when attribution identifies a structural bottleneck. Across six benchmarks and three task models, FAPO beats the baseline GEPA in 15 of 18 model-benchmark comparisons. In 11 model-benchmark comparisons, FAPO wins with non-overlapping mean $\pm$ trial-standard-deviation ranges, and the mean FAPO-GEPA gain is +14.1 pp. In the six HoVer and IFBench comparisons where prompt-first search escalated to structural changes, FAPO wins all six with a mean gain of +33.8 pp. FAPO also improves performance on security tasks: on CTIBench-RCM, a security CVE-to-CWE task, prompt-only FAPO lifts test accuracy by +4.0 pp on GPT-5, +7.1 pp on Foundation-Sec-8B-Instruct, and +2.0 pp on Foundation-Sec-8B-Reasoning. These results position FAPO as a state-of-the-art pipeline optimization technique for both general-purpose and security-focused tasks.
FAPO: Fully Autonomous Prompt Optimization of Multi-Step LLM Pipelines
Jun 17, 2026Multi-step LLM pipelines fail through interactions among retrieval, reasoning, and formatting steps, so prompt-only optimization can miss bottlenecks in the chain. We present FAPO (Fully Autonomous Prompt Optimization), a framework that lets Claude Code optimize an LLM pipeline inside a standardized codebase. FAPO evaluates a pipeline, inspects intermediate steps, diagnoses failures, proposes scoped changes, and validates variants repeatedly to optimize against a score function. It first tries prompt edits and, only when prompt optimization appears insufficient, changes chain structure within the permitted scope when attribution identifies a structural bottleneck. Across six benchmarks and three task models, FAPO beats the baseline GEPA in 15 of 18 model-benchmark comparisons. In 11 model-benchmark comparisons, FAPO wins with non-overlapping mean $\pm$ trial-standard-deviation ranges, and the mean FAPO-GEPA gain is +14.1 pp. In the six HoVer and IFBench comparisons where prompt-first search escalated to structural changes, FAPO wins all six with a mean gain of +33.8 pp. FAPO also improves performance on security tasks: on CTIBench-RCM, a security CVE-to-CWE task, prompt-only FAPO lifts test accuracy by +4.0 pp on GPT-5, +7.1 pp on Foundation-Sec-8B-Instruct, and +2.0 pp on Foundation-Sec-8B-Reasoning. These results position FAPO as a state-of-the-art pipeline optimization technique for both general-purpose and security-focused tasks.
Llama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report
Jan 28, 2026We present Foundation-Sec-8B-Reasoning, the first open-source native reasoning model for cybersecurity. Built upon our previously released Foundation-Sec-8B base model (derived from Llama-3.1-8B-Base), the model is trained through a two-stage process combining supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR). Our training leverages proprietary reasoning data spanning cybersecurity analysis, instruction-following, and mathematical reasoning. Evaluation across 10 cybersecurity benchmarks and 10 general-purpose benchmarks demonstrates performance competitive with significantly larger models on cybersecurity tasks while maintaining strong general capabilities. The model shows effective generalization on multi-hop reasoning tasks and strong safety performance when deployed with appropriate system prompts and guardrails. This work demonstrates that domain-specialized reasoning models can achieve strong performance on specialized tasks while maintaining broad general capabilities. We release the model publicly at https://huggingface.co/fdtn-ai/Foundation-Sec-8B-Reasoning.
Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report
Apr 28, 2025



As transformer-based large language models (LLMs) increasingly permeate society, they have revolutionized domains such as software engineering, creative writing, and digital arts. However, their adoption in cybersecurity remains limited due to challenges like scarcity of specialized training data and complexity of representing cybersecurity-specific knowledge. To address these gaps, we present Foundation-Sec-8B, a cybersecurity-focused LLM built on the Llama 3.1 architecture and enhanced through continued pretraining on a carefully curated cybersecurity corpus. We evaluate Foundation-Sec-8B across both established and new cybersecurity benchmarks, showing that it matches Llama 3.1-70B and GPT-4o-mini in certain cybersecurity-specific tasks. By releasing our model to the public, we aim to accelerate progress and adoption of AI-driven tools in both public and private cybersecurity contexts.
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
Dec 04, 2023While Large Language Models (LLMs) display versatile functionality, they continue to generate harmful, biased, and toxic content, as demonstrated by the prevalence of human-designed jailbreaks. In this work, we present Tree of Attacks with Pruning (TAP), an automated method for generating jailbreaks that only requires black-box access to the target LLM. TAP utilizes an LLM to iteratively refine candidate (attack) prompts using tree-of-thoughts reasoning until one of the generated prompts jailbreaks the target. Crucially, before sending prompts to the target, TAP assesses them and prunes the ones unlikely to result in jailbreaks. Using tree-of-thought reasoning allows TAP to navigate a large search space of prompts and pruning reduces the total number of queries sent to the target. In empirical evaluations, we observe that TAP generates prompts that jailbreak state-of-the-art LLMs (including GPT4 and GPT4-Turbo) for more than 80% of the prompts using only a small number of queries. This significantly improves upon the previous state-of-the-art black-box method for generating jailbreaks.
Support Vector Machines under Adversarial Label Contamination
Jun 01, 2022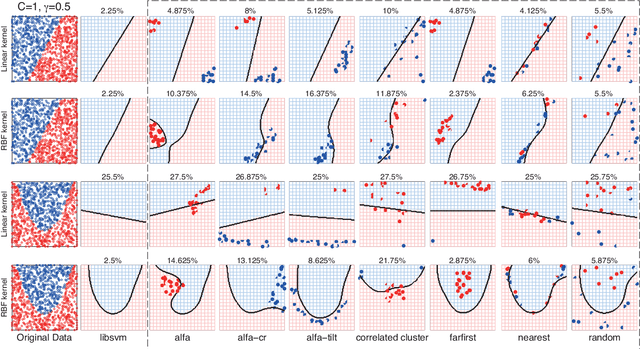
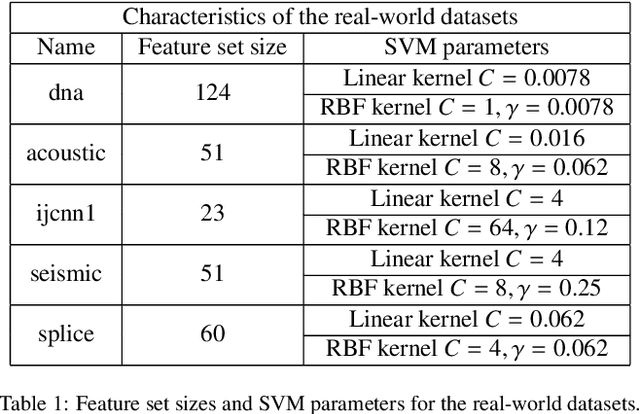
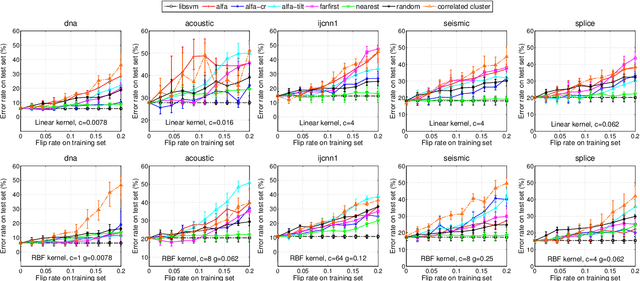
Machine learning algorithms are increasingly being applied in security-related tasks such as spam and malware detection, although their security properties against deliberate attacks have not yet been widely understood. Intelligent and adaptive attackers may indeed exploit specific vulnerabilities exposed by machine learning techniques to violate system security. Being robust to adversarial data manipulation is thus an important, additional requirement for machine learning algorithms to successfully operate in adversarial settings. In this work, we evaluate the security of Support Vector Machines (SVMs) to well-crafted, adversarial label noise attacks. In particular, we consider an attacker that aims to maximize the SVM's classification error by flipping a number of labels in the training data. We formalize a corresponding optimal attack strategy, and solve it by means of heuristic approaches to keep the computational complexity tractable. We report an extensive experimental analysis on the effectiveness of the considered attacks against linear and non-linear SVMs, both on synthetic and real-world datasets. We finally argue that our approach can also provide useful insights for developing more secure SVM learning algorithms, and also novel techniques in a number of related research areas, such as semi-supervised and active learning.
Evasion Attacks against Machine Learning at Test Time
Aug 21, 2017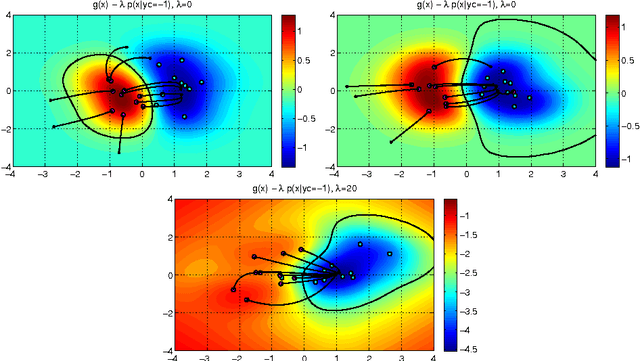
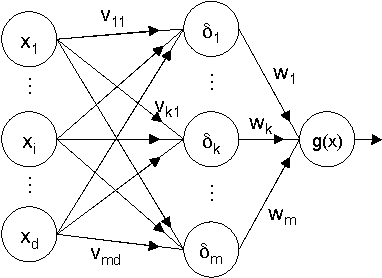
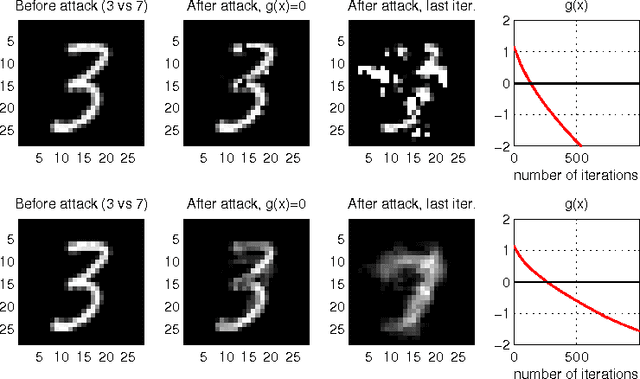
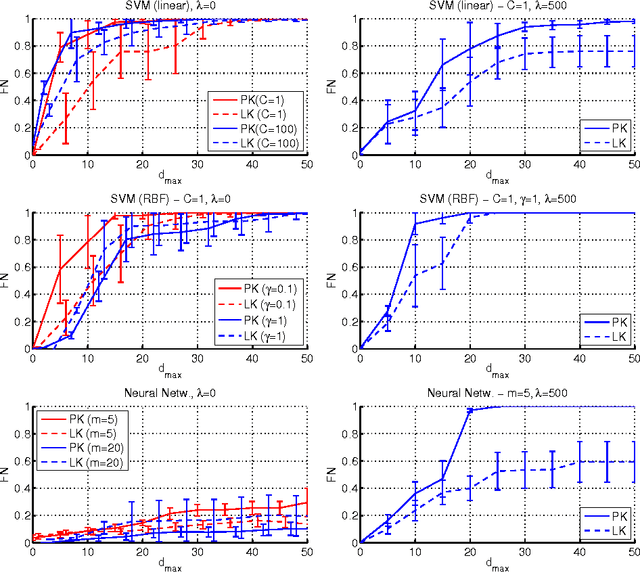
In security-sensitive applications, the success of machine learning depends on a thorough vetting of their resistance to adversarial data. In one pertinent, well-motivated attack scenario, an adversary may attempt to evade a deployed system at test time by carefully manipulating attack samples. In this work, we present a simple but effective gradient-based approach that can be exploited to systematically assess the security of several, widely-used classification algorithms against evasion attacks. Following a recently proposed framework for security evaluation, we simulate attack scenarios that exhibit different risk levels for the classifier by increasing the attacker's knowledge of the system and her ability to manipulate attack samples. This gives the classifier designer a better picture of the classifier performance under evasion attacks, and allows him to perform a more informed model selection (or parameter setting). We evaluate our approach on the relevant security task of malware detection in PDF files, and show that such systems can be easily evaded. We also sketch some countermeasures suggested by our analysis.
* In this paper, in 2013, we were the first to introduce the notion of evasion attacks (adversarial examples) created with high confidence (instead of minimum-distance misclassifications), and the notion of surrogate learners (substitute models). These two concepts are now widely re-used in developing attacks against deep networks (even if not always referring to the ideas reported in this work). arXiv admin note: text overlap with arXiv:1401.7727
Bayesian Differential Privacy through Posterior Sampling
Dec 23, 2016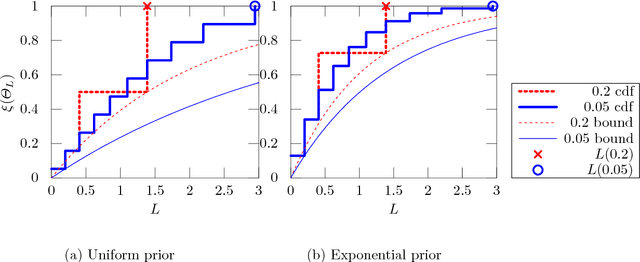
Differential privacy formalises privacy-preserving mechanisms that provide access to a database. We pose the question of whether Bayesian inference itself can be used directly to provide private access to data, with no modification. The answer is affirmative: under certain conditions on the prior, sampling from the posterior distribution can be used to achieve a desired level of privacy and utility. To do so, we generalise differential privacy to arbitrary dataset metrics, outcome spaces and distribution families. This allows us to also deal with non-i.i.d or non-tabular datasets. We prove bounds on the sensitivity of the posterior to the data, which gives a measure of robustness. We also show how to use posterior sampling to provide differentially private responses to queries, within a decision-theoretic framework. Finally, we provide bounds on the utility and on the distinguishability of datasets. The latter are complemented by a novel use of Le Cam's method to obtain lower bounds. All our general results hold for arbitrary database metrics, including those for the common definition of differential privacy. For specific choices of the metric, we give a number of examples satisfying our assumptions.
Security Evaluation of Support Vector Machines in Adversarial Environments
Jan 30, 2014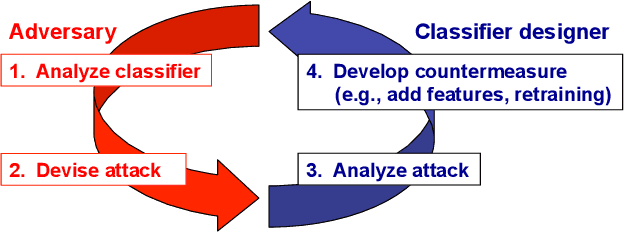
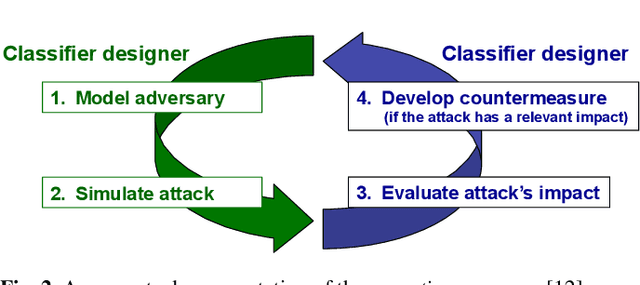
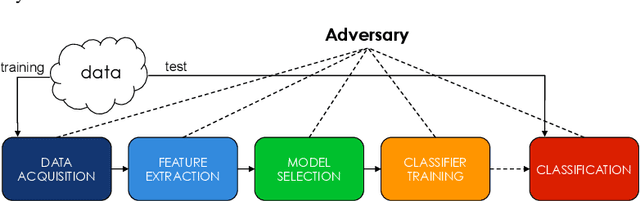
Support Vector Machines (SVMs) are among the most popular classification techniques adopted in security applications like malware detection, intrusion detection, and spam filtering. However, if SVMs are to be incorporated in real-world security systems, they must be able to cope with attack patterns that can either mislead the learning algorithm (poisoning), evade detection (evasion), or gain information about their internal parameters (privacy breaches). The main contributions of this chapter are twofold. First, we introduce a formal general framework for the empirical evaluation of the security of machine-learning systems. Second, according to our framework, we demonstrate the feasibility of evasion, poisoning and privacy attacks against SVMs in real-world security problems. For each attack technique, we evaluate its impact and discuss whether (and how) it can be countered through an adversary-aware design of SVMs. Our experiments are easily reproducible thanks to open-source code that we have made available, together with all the employed datasets, on a public repository.
Poisoning Attacks against Support Vector Machines
Mar 25, 2013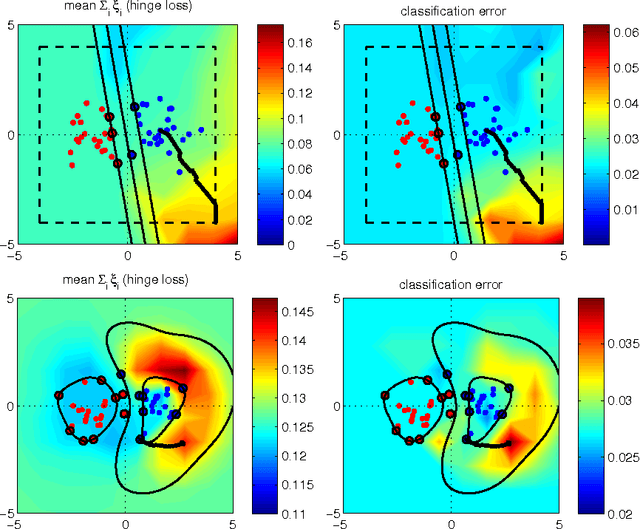
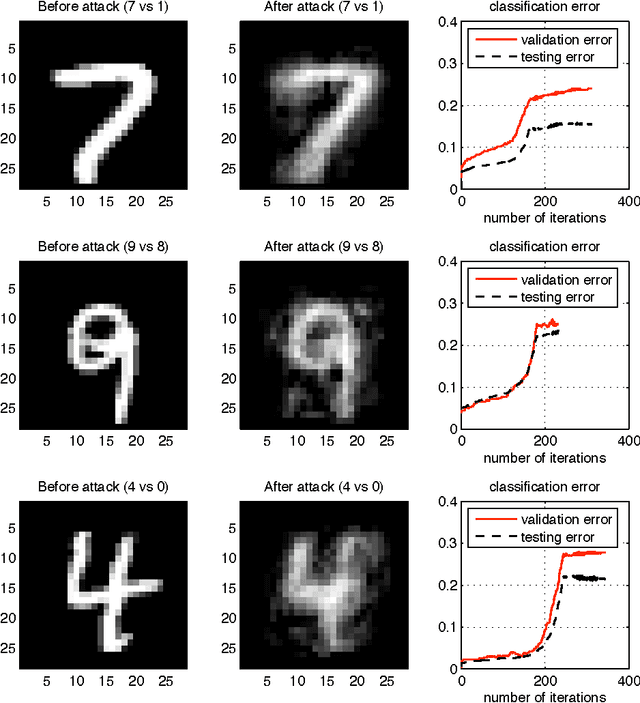
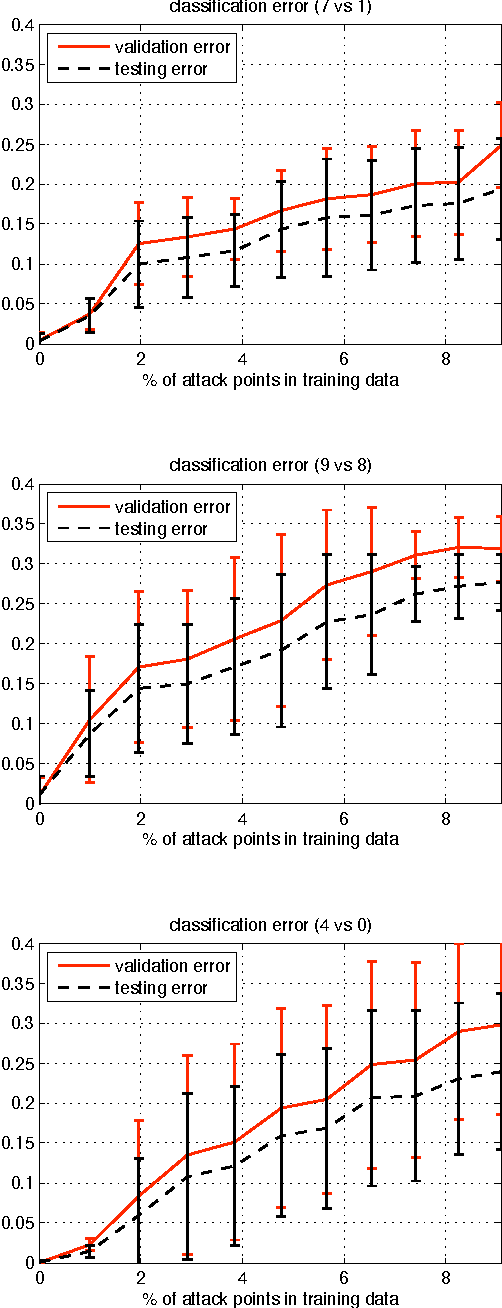
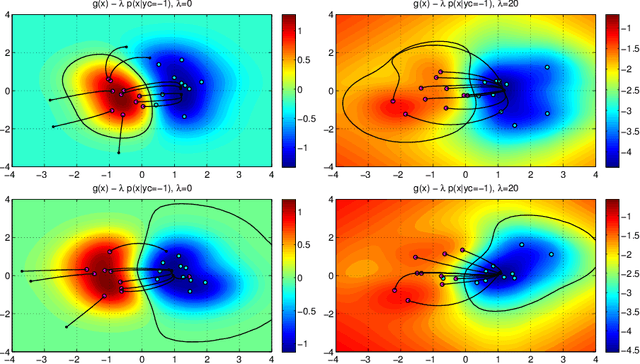
We investigate a family of poisoning attacks against Support Vector Machines (SVM). Such attacks inject specially crafted training data that increases the SVM's test error. Central to the motivation for these attacks is the fact that most learning algorithms assume that their training data comes from a natural or well-behaved distribution. However, this assumption does not generally hold in security-sensitive settings. As we demonstrate, an intelligent adversary can, to some extent, predict the change of the SVM's decision function due to malicious input and use this ability to construct malicious data. The proposed attack uses a gradient ascent strategy in which the gradient is computed based on properties of the SVM's optimal solution. This method can be kernelized and enables the attack to be constructed in the input space even for non-linear kernels. We experimentally demonstrate that our gradient ascent procedure reliably identifies good local maxima of the non-convex validation error surface, which significantly increases the classifier's test error.