 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiToD: A Bilingual Multi-Domain Dataset For Task-Oriented Dialogue Modeling
Jun 05, 2021
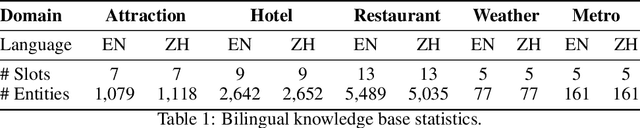
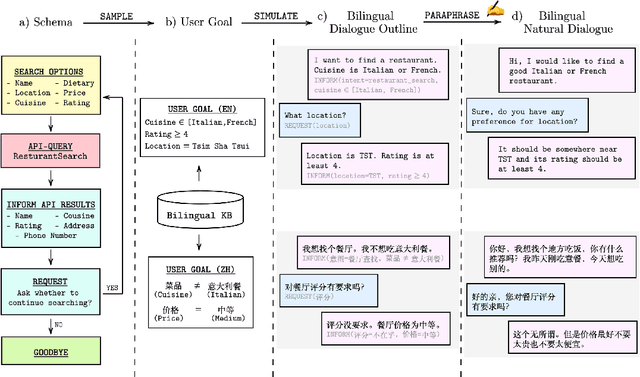
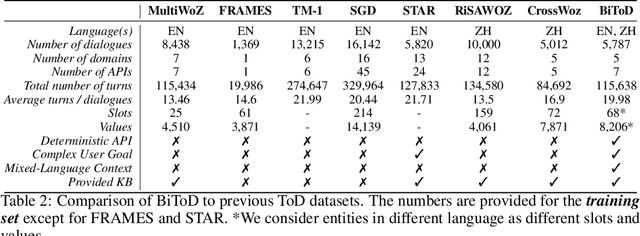
Task-oriented dialogue (ToD) benchmarks provide an important avenue to measure progress and develop better conversational agents. However, existing datasets for end-to-end ToD modeling are limited to a single language, hindering the development of robust end-to-end ToD systems for multilingual countries and regions. Here we introduce BiToD, the first bilingual multi-domain dataset for end-to-end task-oriented dialogue modeling. BiToD contains over 7k multi-domain dialogues (144k utterances) with a large and realistic bilingual knowledge base. It serves as an effective benchmark for evaluating bilingual ToD systems and cross-lingual transfer learning approaches. We provide state-of-the-art baselines under three evaluation settings (monolingual, bilingual, and cross-lingual). The analysis of our baselines in different settings highlights 1) the effectiveness of training a bilingual ToD system compared to two independent monolingual ToD systems, and 2) the potential of leveraging a bilingual knowledge base and cross-lingual transfer learning to improve the system performance under low resource condition.
ERICA: An Empathetic Android Companion for Covid-19 Quarantine
Jun 04, 2021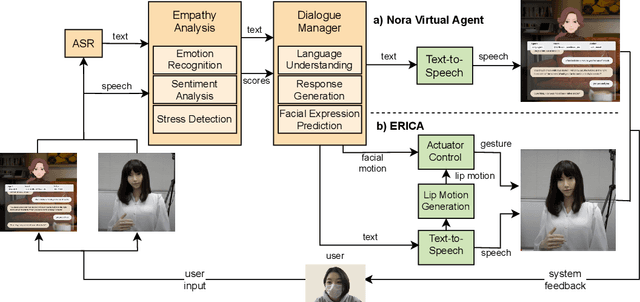
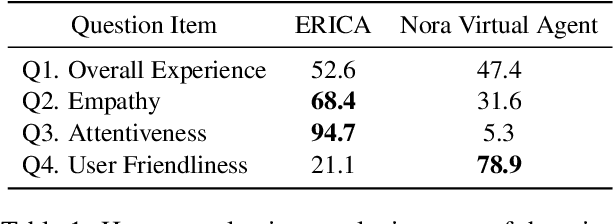

Over the past year, research in various domains, including Natural Language Processing (NLP), has been accelerated to fight against the COVID-19 pandemic, yet such research has just started on dialogue systems. In this paper, we introduce an end-to-end dialogue system which aims to ease the isolation of people under self-quarantine. We conduct a control simulation experiment to assess the effects of the user interface, a web-based virtual agent called Nora vs. the android ERICA via a video call. The experimental results show that the android offers a more valuable user experience by giving the impression of being more empathetic and engaging in the conversation due to its nonverbal information, such as facial expressions and body gestures.
Adapting High-resource NMT Models to Translate Low-resource Related Languages without Parallel Data
Jun 02, 2021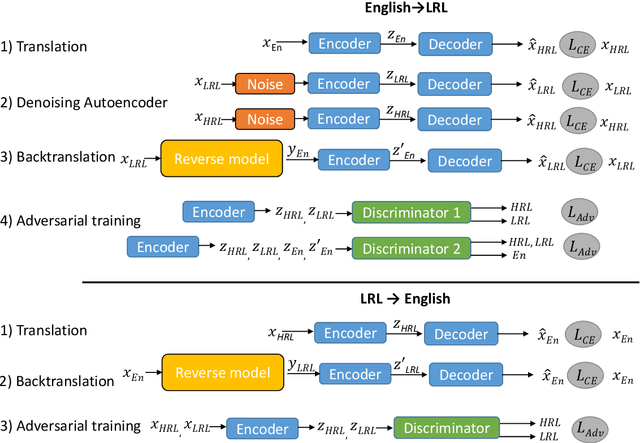
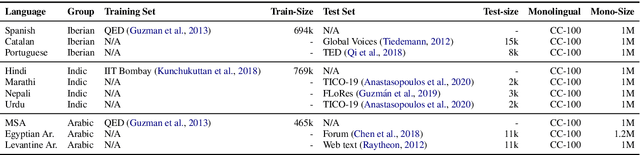
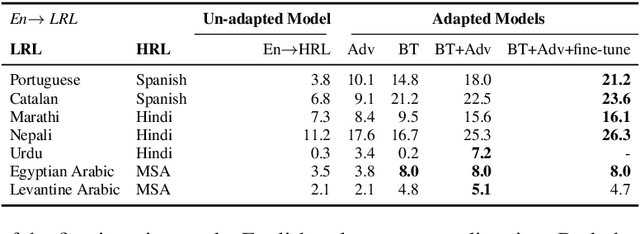
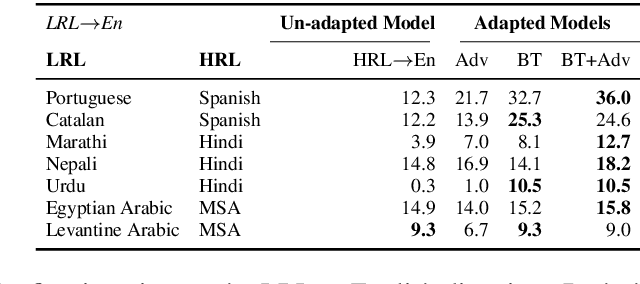
The scarcity of parallel data is a major obstacle for training high-quality machine translation systems for low-resource languages. Fortunately, some low-resource languages are linguistically related or similar to high-resource languages; these related languages may share many lexical or syntactic structures. In this work, we exploit this linguistic overlap to facilitate translating to and from a low-resource language with only monolingual data, in addition to any parallel data in the related high-resource language. Our method, NMT-Adapt, combines denoising autoencoding, back-translation and adversarial objectives to utilize monolingual data for low-resource adaptation. We experiment on 7 languages from three different language families and show that our technique significantly improves translation into low-resource language compared to other translation baselines.
Nora: The Well-Being Coach
Jun 01, 2021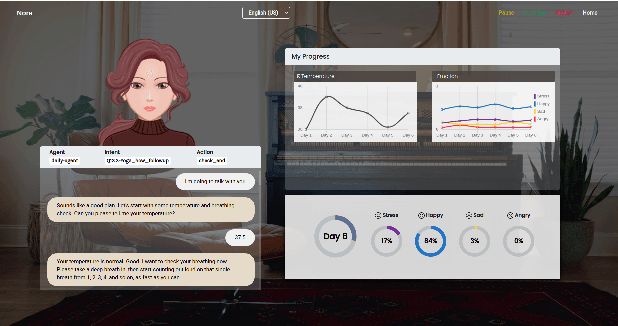
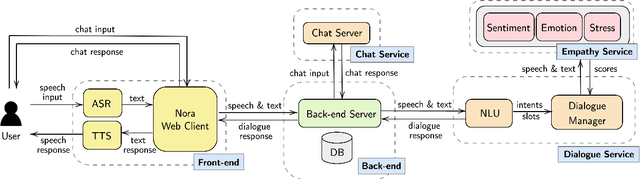
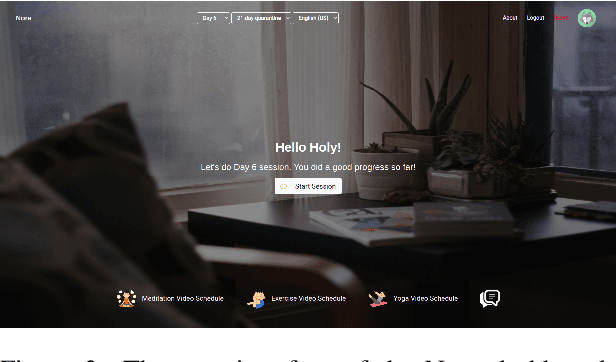
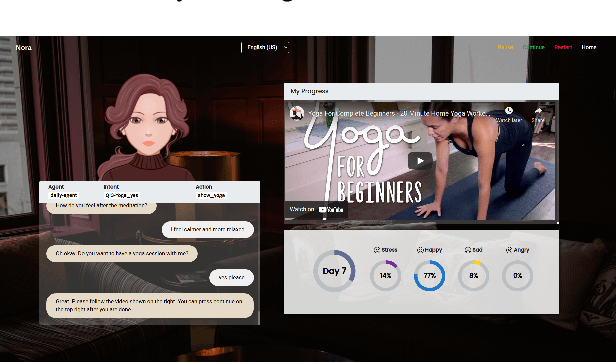
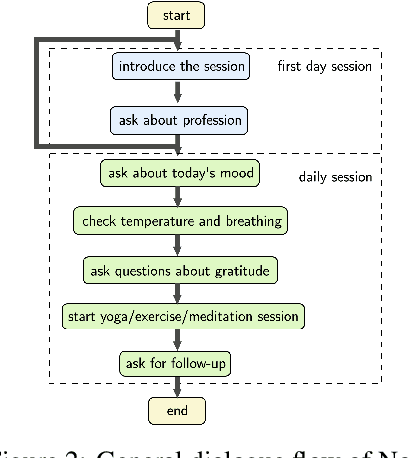
The current pandemic has forced people globally to remain in isolation and practice social distancing, which creates the need for a system to combat the resulting loneliness and negative emotions. In this paper we propose Nora, a virtual coaching platform designed to utilize natural language understanding in its dialogue system and suggest other recommendations based on user interactions. It is intended to provide assistance and companionship to people undergoing self-quarantine or work-from-home routines. Nora helps users gauge their well-being by detecting and recording the user's emotion, sentiment, and stress. Nora also recommends various workout, meditation, or yoga exercises to users in support of developing a healthy daily routine. In addition, we provide a social community inside Nora, where users can connect and share their experiences with others undergoing a similar isolation procedure. Nora can be accessed from anywhere via a web link and has support for both English and Mandarin.
Improve Query Focused Abstractive Summarization by Incorporating Answer Relevance
May 31, 2021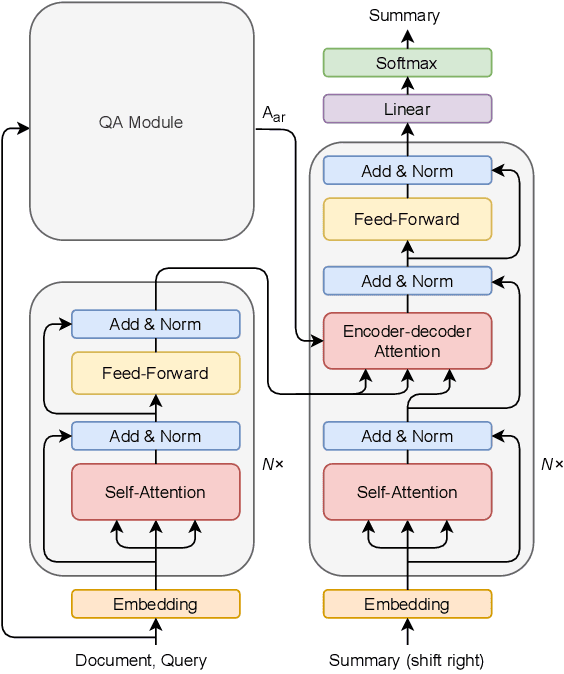
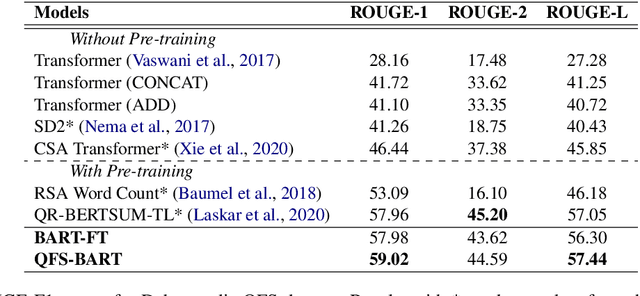

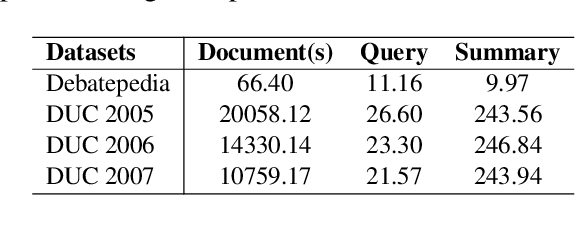
Query focused summarization (QFS) models aim to generate summaries from source documents that can answer the given query. Most previous work on QFS only considers the query relevance criterion when producing the summary. However, studying the effect of answer relevance in the summary generating process is also important. In this paper, we propose QFS-BART, a model that incorporates the explicit answer relevance of the source documents given the query via a question answering model, to generate coherent and answer-related summaries. Furthermore, our model can take advantage of large pre-trained models which improve the summarization performance significantly. Empirical results on the Debatepedia dataset show that the proposed model achieves the new state-of-the-art performance.
QAConv: Question Answering on Informative Conversations
May 14, 2021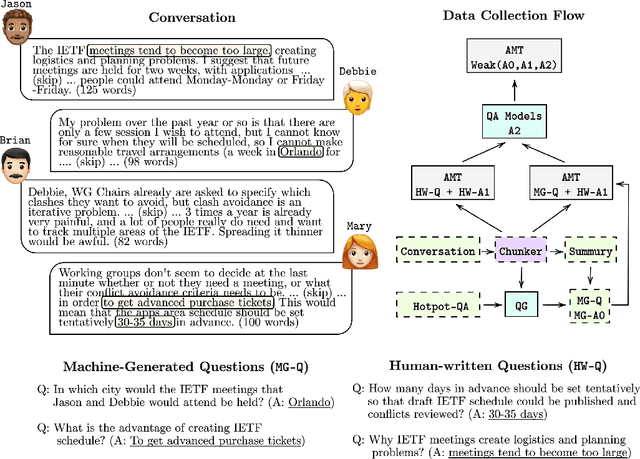
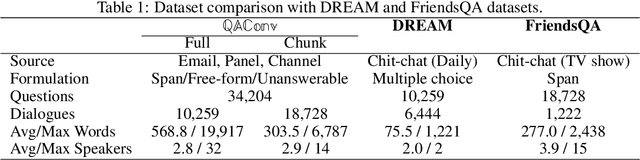
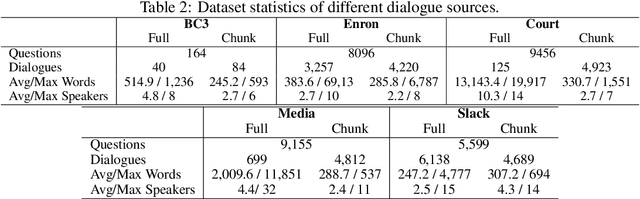
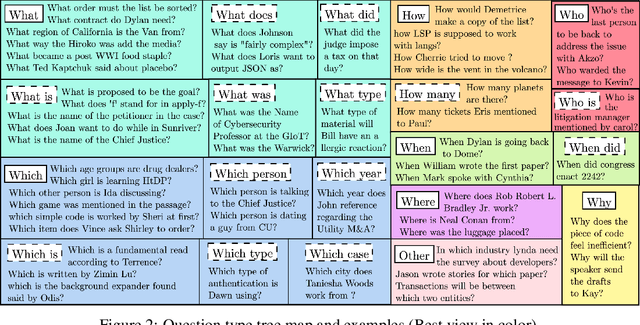
This paper introduces QAConv, a new question answering (QA) dataset that uses conversations as a knowledge source. We focus on informative conversations including business emails, panel discussions, and work channels. Unlike open-domain and task-oriented dialogues, these conversations are usually long, complex, asynchronous, and involve strong domain knowledge. In total, we collect 34,204 QA pairs, including span-based, free-form, and unanswerable questions, from 10,259 selected conversations with both human-written and machine-generated questions. We segment long conversations into chunks, and use a question generator and dialogue summarizer as auxiliary tools to collect multi-hop questions. The dataset has two testing scenarios, chunk mode and full mode, depending on whether the grounded chunk is provided or retrieved from a large conversational pool. Experimental results show that state-of-the-art QA systems trained on existing QA datasets have limited zero-shot ability and tend to predict our questions as unanswerable. Fine-tuning such systems on our corpus can achieve significant improvement up to 23.6% and 13.6% in both chunk mode and full mode, respectively.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021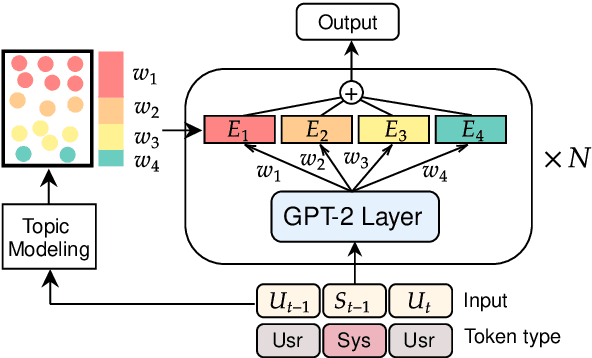
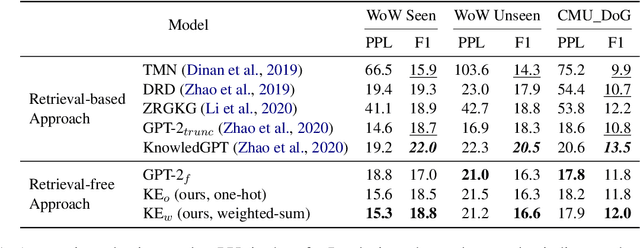
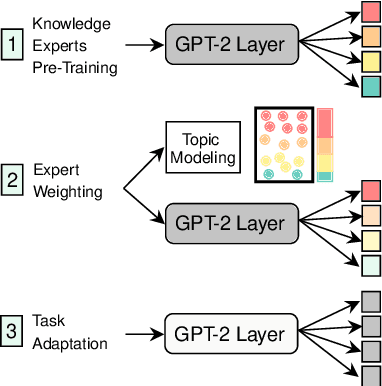

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
Continual Mixed-Language Pre-Training for Extremely Low-Resource Neural Machine Translation
May 09, 2021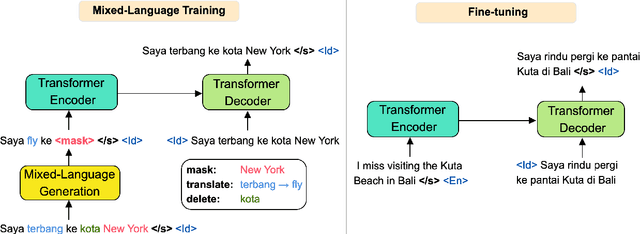
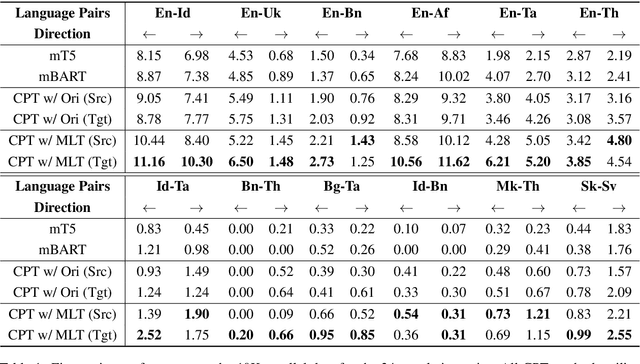
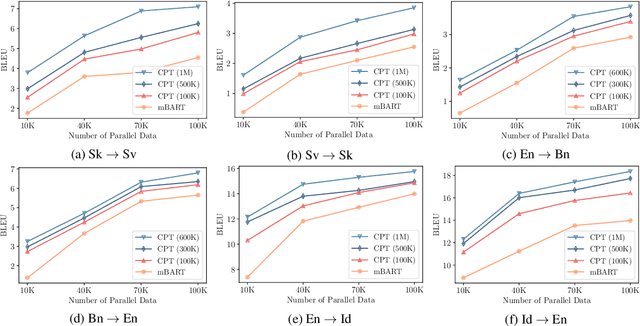
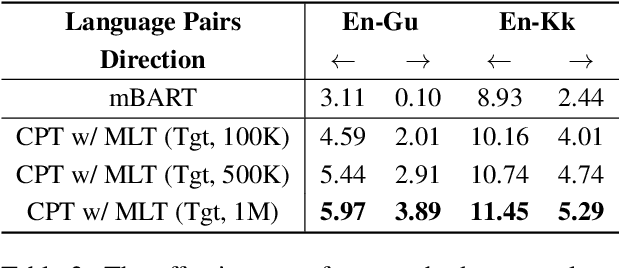
The data scarcity in low-resource languages has become a bottleneck to building robust neural machine translation systems. Fine-tuning a multilingual pre-trained model (e.g., mBART (Liu et al., 2020)) on the translation task is a good approach for low-resource languages; however, its performance will be greatly limited when there are unseen languages in the translation pairs. In this paper, we present a continual pre-training (CPT) framework on mBART to effectively adapt it to unseen languages. We first construct noisy mixed-language text from the monolingual corpus of the target language in the translation pair to cover both the source and target languages, and then, we continue pre-training mBART to reconstruct the original monolingual text. Results show that our method can consistently improve the fine-tuning performance upon the mBART baseline, as well as other strong baselines, across all tested low-resource translation pairs containing unseen languages. Furthermore, our approach also boosts the performance on translation pairs where both languages are seen in the original mBART's pre-training. The code is available at https://github.com/zliucr/cpt-nmt.
Weakly-supervised Multi-task Learning for Multimodal Affect Recognition
Apr 23, 2021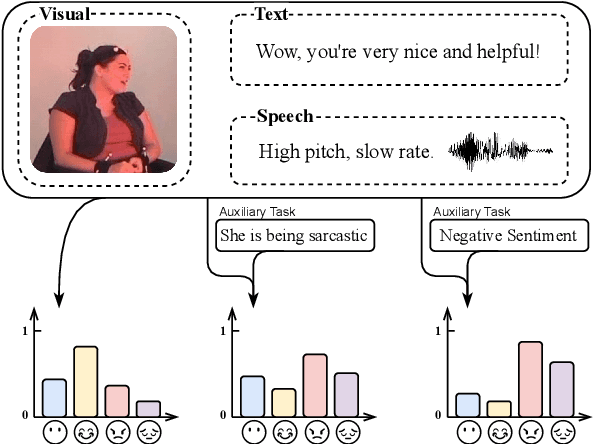
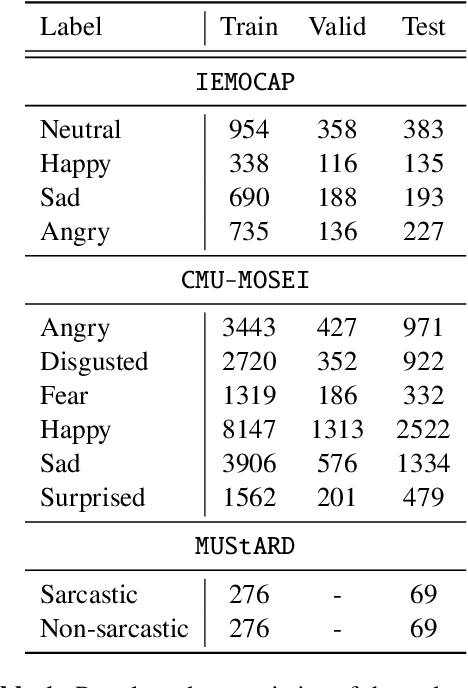
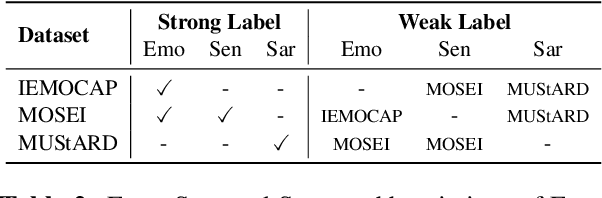
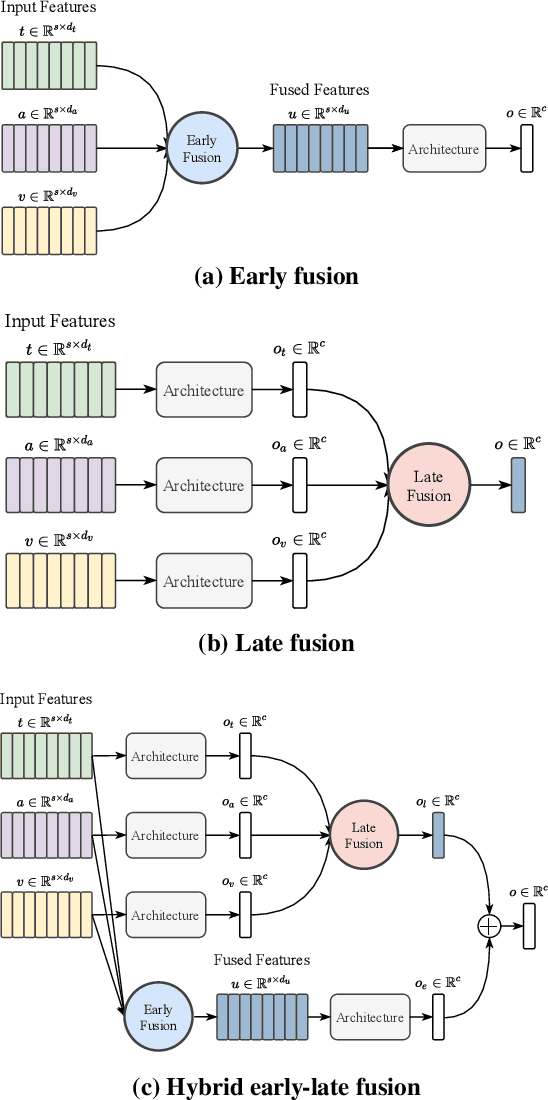
Multimodal affect recognition constitutes an important aspect for enhancing interpersonal relationships in human-computer interaction. However, relevant data is hard to come by and notably costly to annotate, which poses a challenging barrier to build robust multimodal affect recognition systems. Models trained on these relatively small datasets tend to overfit and the improvement gained by using complex state-of-the-art models is marginal compared to simple baselines. Meanwhile, there are many different multimodal affect recognition datasets, though each may be small. In this paper, we propose to leverage these datasets using weakly-supervised multi-task learning to improve the generalization performance on each of them. Specifically, we explore three multimodal affect recognition tasks: 1) emotion recognition; 2) sentiment analysis; and 3) sarcasm recognition. Our experimental results show that multi-tasking can benefit all these tasks, achieving an improvement up to 2.9% accuracy and 3.3% F1-score. Furthermore, our method also helps to improve the stability of model performance. In addition, our analysis suggests that weak supervision can provide a comparable contribution to strong supervision if the tasks are highly correlated.
AdaptSum: Towards Low-Resource Domain Adaptation for Abstractive Summarization
Apr 19, 2021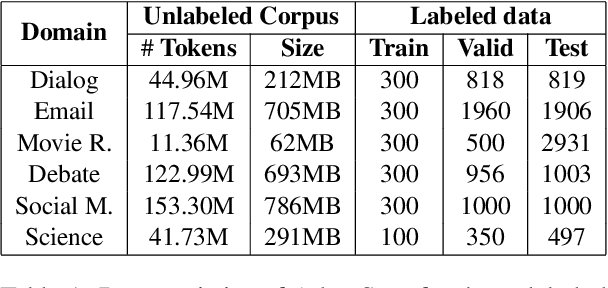
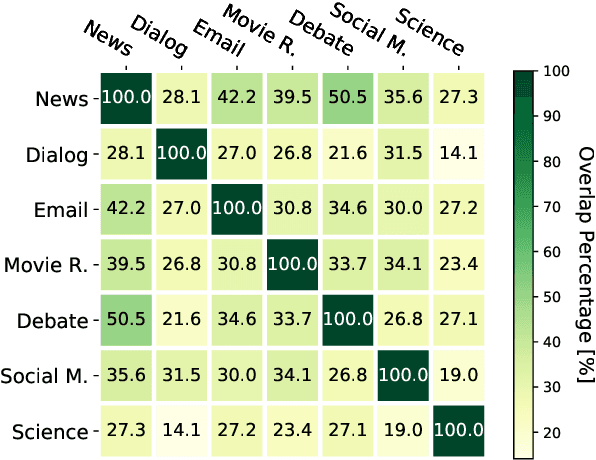
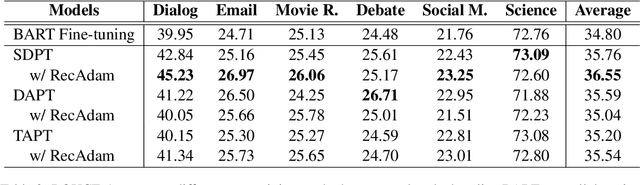
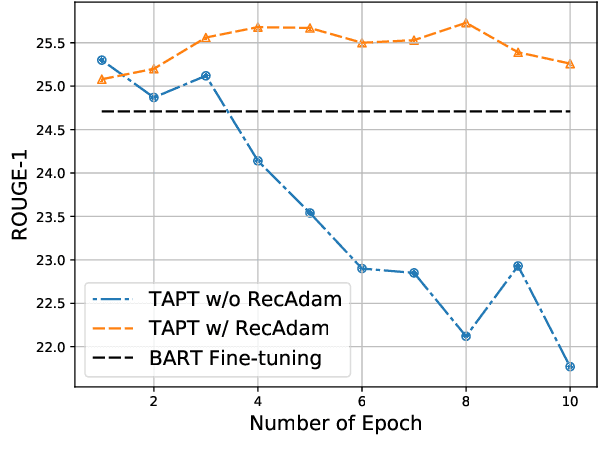
State-of-the-art abstractive summarization models generally rely on extensive labeled data, which lowers their generalization ability on domains where such data are not available. In this paper, we present a study of domain adaptation for the abstractive summarization task across six diverse target domains in a low-resource setting. Specifically, we investigate the second phase of pre-training on large-scale generative models under three different settings: 1) source domain pre-training; 2) domain-adaptive pre-training; and 3) task-adaptive pre-training. Experiments show that the effectiveness of pre-training is correlated with the similarity between the pre-training data and the target domain task. Moreover, we find that continuing pre-training could lead to the pre-trained model's catastrophic forgetting, and a learning method with less forgetting can alleviate this issue. Furthermore, results illustrate that a huge gap still exists between the low-resource and high-resource settings, which highlights the need for more advanced domain adaptation methods for the abstractive summarization task.