 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCLID-Net: Single View Reconstruction in Object Space
Jun 16, 2020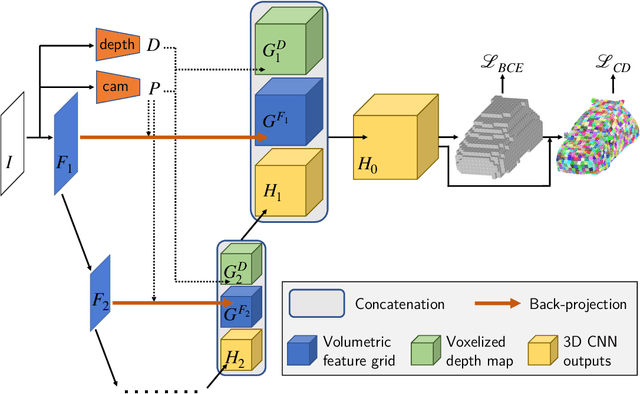

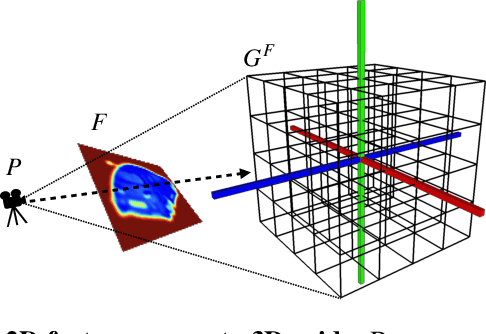

Most state-of-the-art deep geometric learning single-view reconstruction approaches rely on encoder-decoder architectures that output either shape parametrizations or implicit representations. However, these representations rarely preserve the Euclidean structure of the 3D space objects exist in. In this paper, we show that building a geometry preserving 3-dimensional latent space helps the network concurrently learn global shape regularities and local reasoning in the object coordinate space and, as a result, boosts performance. We demonstrate both on ShapeNet synthetic images, which are often used for benchmarking purposes, and on real-world images that our approach outperforms state-of-the-art ones. Furthermore, the single-view pipeline naturally extends to multi-view reconstruction, which we also show.
MeshSDF: Differentiable Iso-Surface Extraction
Jun 06, 2020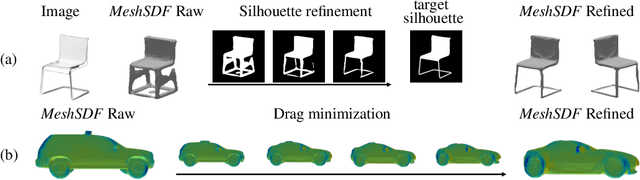
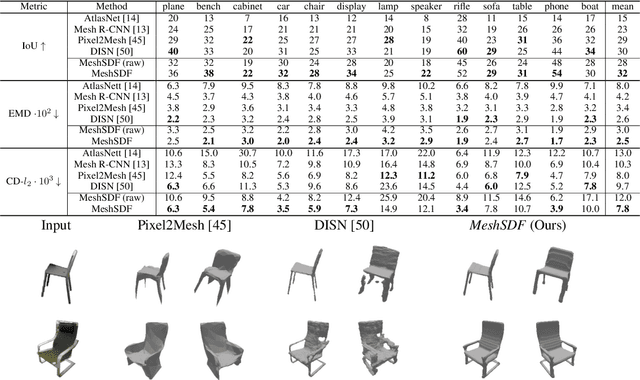
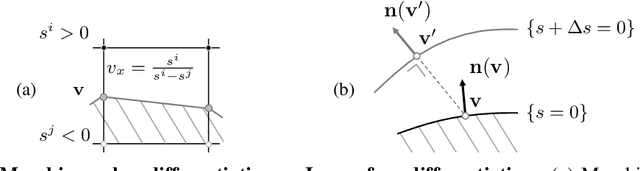
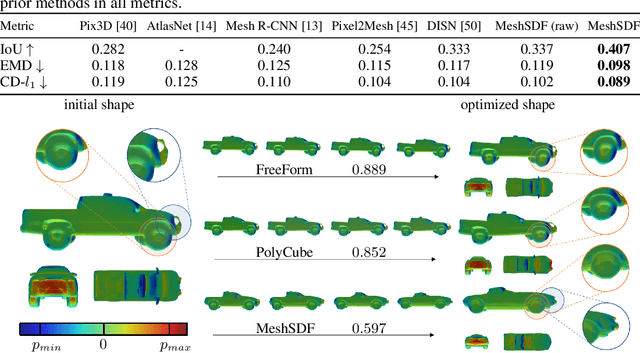
Geometric Deep Learning has recently made striking progress with the advent of continuous Deep Implicit Fields. They allow for detailed modeling of watertight surfaces of arbitrary topology while not relying on a 3D Euclidean grid, resulting in a learnable parameterization that is not limited in resolution. Unfortunately, these methods are often not suitable for applications that require an explicit mesh-based surface representation because converting an implicit field to such a representation relies on the Marching Cubes algorithm, which cannot be differentiated with respect to the underlying implicit field. In this work, we remove this limitation and introduce a differentiable way to produce explicit surface mesh representations from Deep Signed Distance Functions. Our key insight is that by reasoning on how implicit field perturbations impact local surface geometry, one can ultimately differentiate the 3D location of surface samples with respect to the underlying deep implicit field. We exploit this to define MeshSDF, an end-to-end differentiable mesh representation which can vary its topology. We use two different applications to validate our theoretical insight: Single-View Reconstruction via Differentiable Rendering and Physically-Driven Shape Optimization. In both cases our differentiable parameterization gives us an edge over state-of-the-art algorithms.
Eigendecomposition-Free Training of Deep Networks for Linear Least-Square Problems
Apr 15, 2020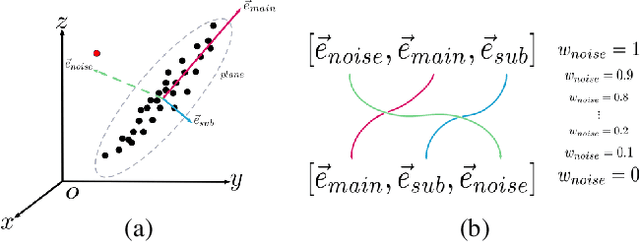


Many classical Computer Vision problems, such as essential matrix computation and pose estimation from 3D to 2D correspondences, can be tackled by solving a linear least-square problem, which can be done by finding the eigenvector corresponding to the smallest, or zero, eigenvalue of a matrix representing a linear system. Incorporating this in deep learning frameworks would allow us to explicitly encode known notions of geometry, instead of having the network implicitly learn them from data. However, performing eigendecomposition within a network requires the ability to differentiate this operation. While theoretically doable, this introduces numerical instability in the optimization process in practice. In this paper, we introduce an eigendecomposition-free approach to training a deep network whose loss depends on the eigenvector corresponding to a zero eigenvalue of a matrix predicted by the network. We demonstrate that our approach is much more robust than explicit differentiation of the eigendecomposition using two general tasks, outlier rejection and denoising, with several practical examples including wide-baseline stereo, the perspective-n-point problem, and ellipse fitting. Empirically, our method has better convergence properties and yields state-of-the-art results.
Lightweight Multi-View 3D Pose Estimation through Camera-Disentangled Representation
Apr 05, 2020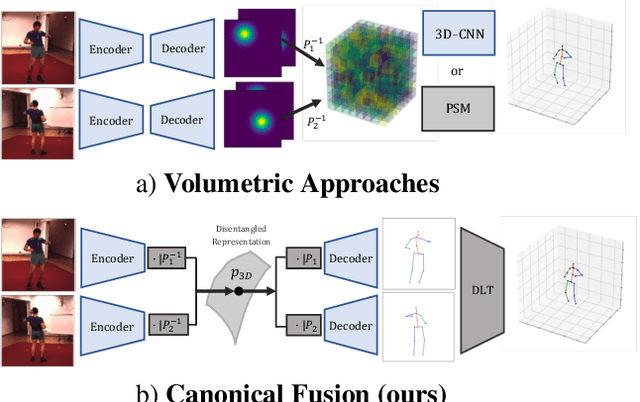
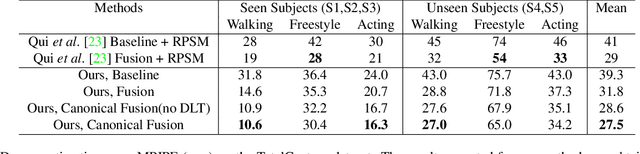
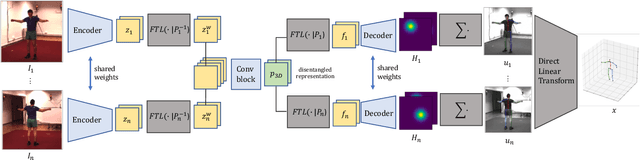
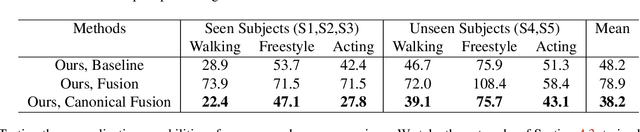
We present a lightweight solution to recover 3D pose from multi-view images captured with spatially calibrated cameras. Building upon recent advances in interpretable representation learning, we exploit 3D geometry to fuse input images into a unified latent representation of pose, which is disentangled from camera view-points. This allows us to reason effectively about 3D pose across different views without using compute-intensive volumetric grids. Our architecture then conditions the learned representation on camera projection operators to produce accurate per-view 2d detections, that can be simply lifted to 3D via a differentiable Direct Linear Transform (DLT) layer. In order to do it efficiently, we propose a novel implementation of DLT that is orders of magnitude faster on GPU architectures than standard SVD-based triangulation methods. We evaluate our approach on two large-scale human pose datasets (H36M and Total Capture): our method outperforms or performs comparably to the state-of-the-art volumetric methods, while, unlike them, yielding real-time performance.
Real-Time Camera Pose Estimation for Sports Fields
Mar 31, 2020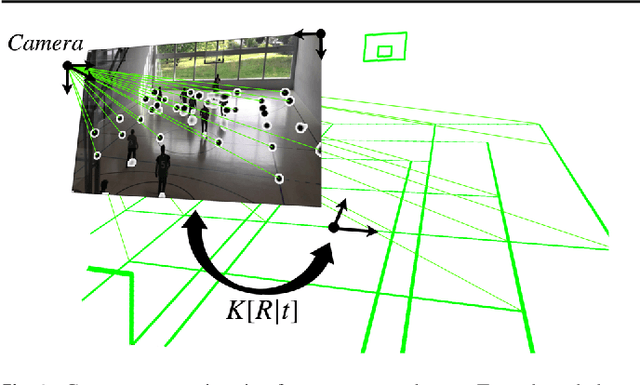
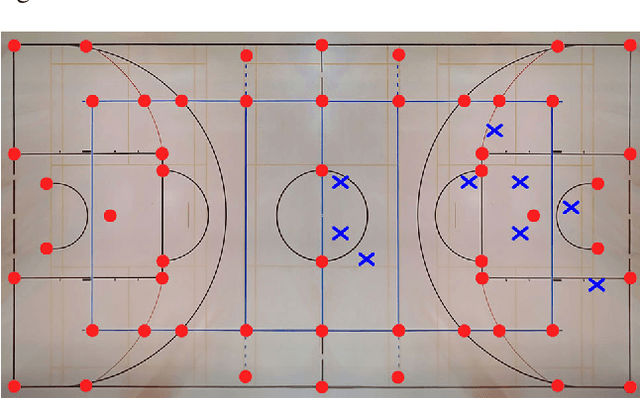
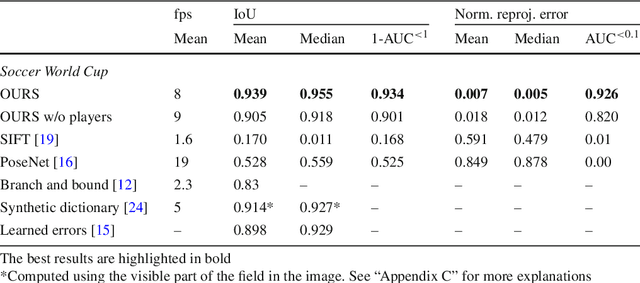
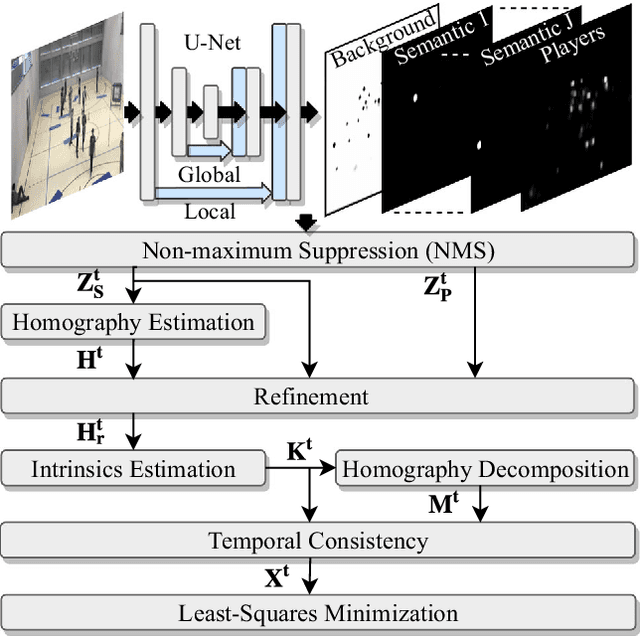
Given an image sequence featuring a portion of a sports field filmed by a moving and uncalibrated camera, such as the one of the smartphones, our goal is to compute automatically in real time the focal length and extrinsic camera parameters for each image in the sequence without using a priori knowledges of the position and orientation of the camera. To this end, we propose a novel framework that combines accurate localization and robust identification of specific keypoints in the image by using a fully convolutional deep architecture. Our algorithm exploits both the field lines and the players' image locations, assuming their ground plane positions to be given, to achieve accuracy and robustness that is beyond the current state of the art. We will demonstrate its effectiveness on challenging soccer, basketball, and volleyball benchmark datasets.
Image Matching across Wide Baselines: From Paper to Practice
Mar 03, 2020
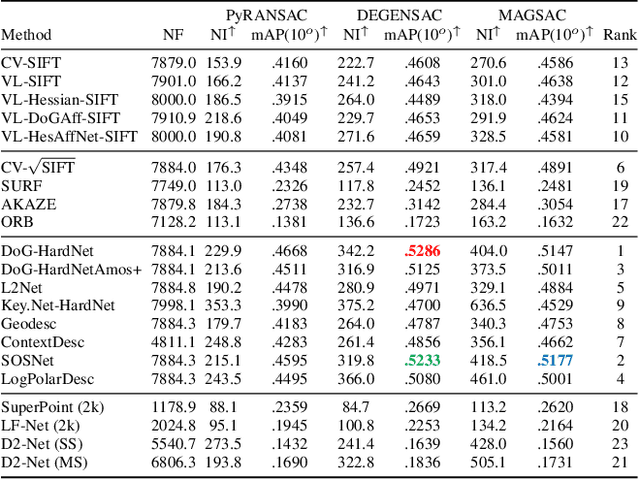

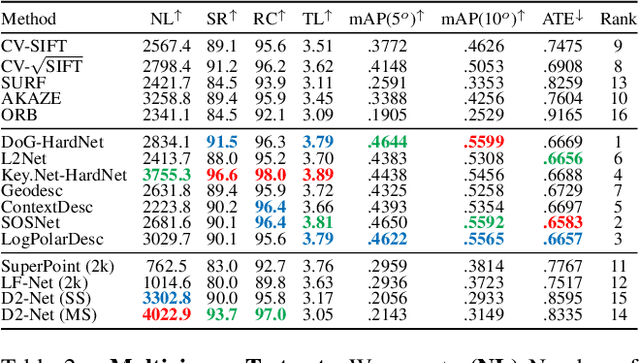
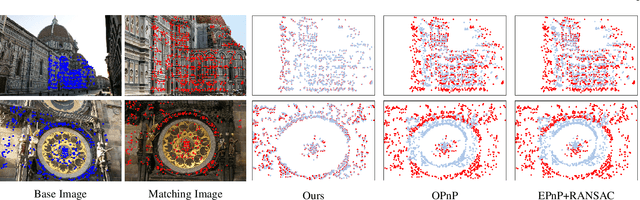
We introduce a comprehensive benchmark for local features and robust estimation algorithms, focusing on the downstream task -- the accuracy of the reconstructed camera pose -- as our primary metric. Our pipeline's modular structure allows us to easily integrate, configure, and combine methods and heuristics. We demonstrate this by embedding dozens of popular algorithms and evaluating them, from seminal works to the cutting edge of machine learning research. We show that with proper settings, classical solutions may still outperform the perceived state of the art. Besides establishing the actual state of the art, the experiments conducted in this paper reveal unexpected properties of SfM pipelines that can be exploited to help improve their performance, for both algorithmic and learned methods. Data and code are online https://github.com/vcg-uvic/image-matching-benchmark, providing an easy-to-use and flexible framework for the benchmarking of local feature and robust estimation methods, both alongside and against top-performing methods. This work provides the basis for an open challenge on wide-baseline image matching https://vision.uvic.ca/image-matching-challenge .
Deformation-aware Unpaired Image Translation for Pose Estimation on Laboratory Animals
Jan 23, 2020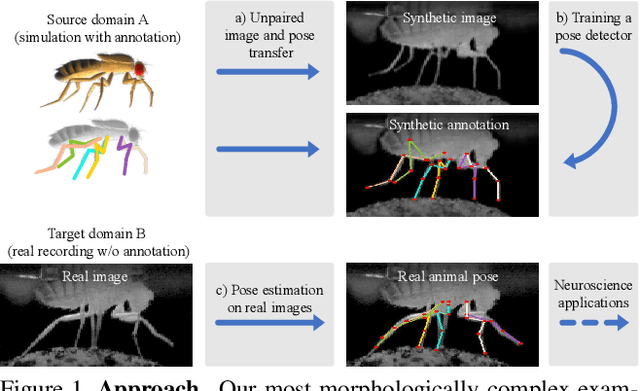
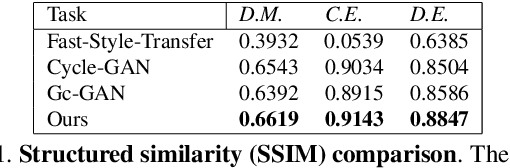

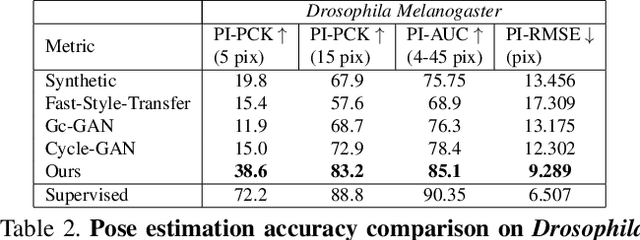
Our goal is to capture the pose of neuroscience model organisms, without using any manual supervision, to be able to study how neural circuits orchestrate behaviour. Human pose estimation attains remarkable accuracy when trained on real or simulated datasets consisting of millions of frames. However, for many applications simulated models are unrealistic and real training datasets with comprehensive annotations do not exist. We address this problem with a new sim2real domain transfer method. Our key contribution is the explicit and independent modeling of appearance, shape and poses in an unpaired image translation framework. Our model lets us train a pose estimator on the target domain by transferring readily available body keypoint locations from the source domain to generated target images. We compare our approach with existing domain transfer methods and demonstrate improved pose estimation accuracy on Drosophila melanogaster (fruit fly), Caenorhabditis elegans (worm) and Danio rerio (zebrafish), without requiring any manual annotation on the target domain and despite using simplistic off-the-shelf animal characters for simulation, or simple geometric shapes as models. Our new datasets, code, and trained models will be published to support future neuroscientific studies.
ActiveMoCap: Optimized Drone Flight for Active Human Motion Capture
Dec 18, 2019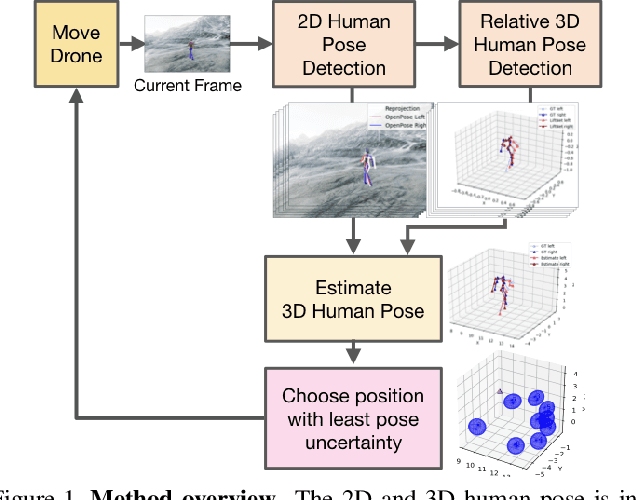

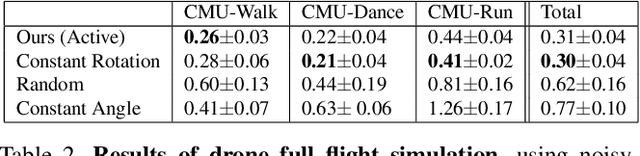
The accuracy of monocular 3D human pose estimation depends on the viewpoint from which the image is captured. While camera-equipped drones provide control over this viewpoint, automatically positioning them at the location which will yield the highest accuracy remains an open problem. This is the problem that we address in this paper. Specifically, given a short video sequence, we introduce an algorithm that predicts the where a drone should go in the future frame so as to maximize 3D human pose estimation accuracy. A key idea underlying our approach is a method to estimate the uncertainty of the 3D body pose estimates. We integrate several sources of uncertainty, originating from a deep learning based regressors and temporal smoothness. The resulting motion planner leads to improved 3D body pose estimates and outperforms or matches existing planners that are based on person following and orbiting.
VM-Net: Mesh Modeling to Assist Segmentation in Volumetric Data
Dec 08, 2019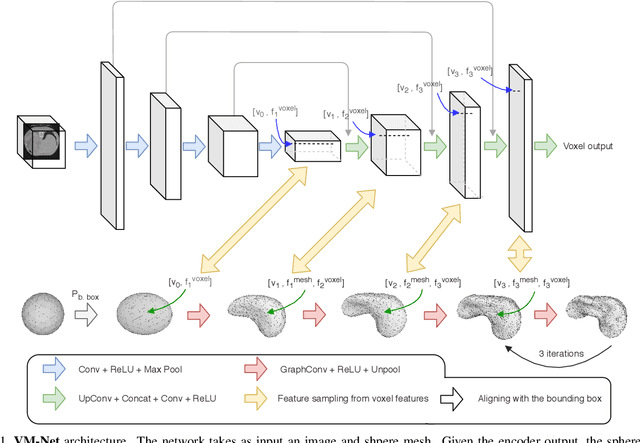
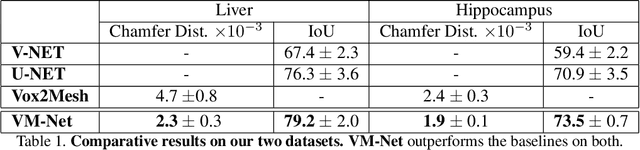
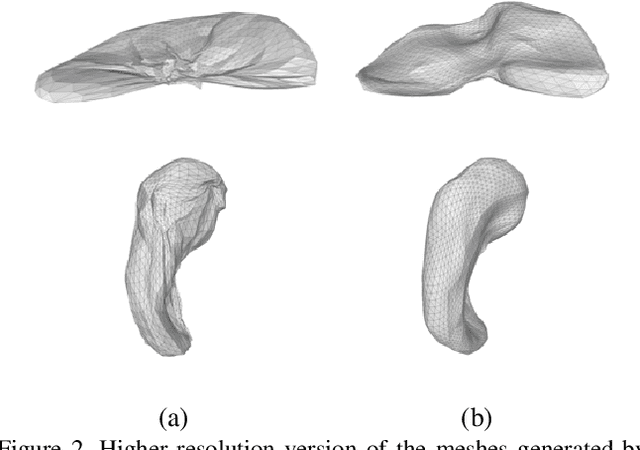
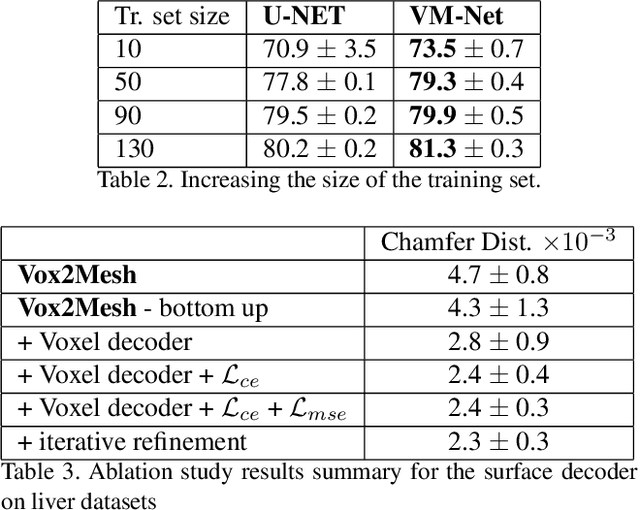
CNN-based volumetric methods that label individual voxels now dominate the field of biomedical segmentation. In this paper, we show that simultaneously performing the segmentation and recovering a 3D mesh that models the surface can boost performance. To this end, we propose an end-to-end trainable two-stream encoder/decoder architecture. It comprises a single encoder and two decoders, one that labels voxels and the other outputs the mesh. The key to success is that the two decoders communicate with each other and help each other learn. This goes beyond the well-known fact that training a deep network to perform two different tasks improves its performance. We will demonstrate substantial performance increases on two very different and challenging datasets.
Towards Reliable Evaluation of Road Network Reconstructions
Nov 28, 2019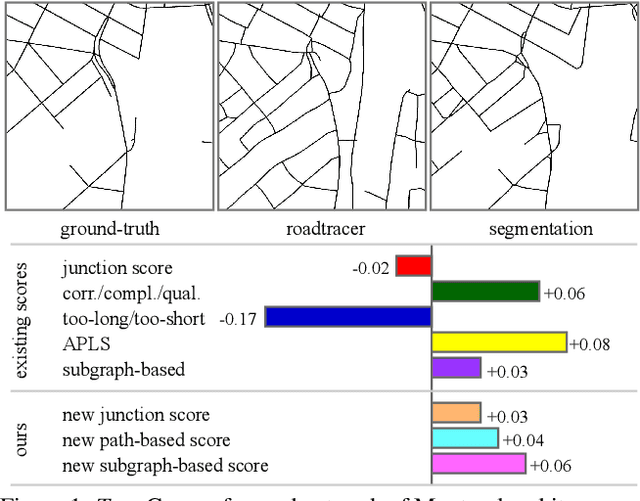
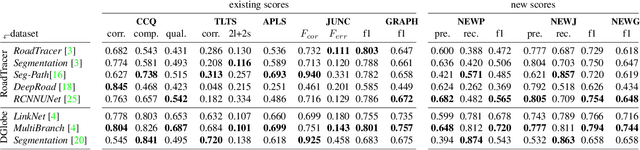
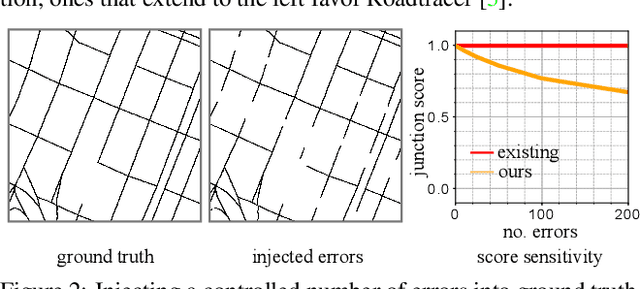
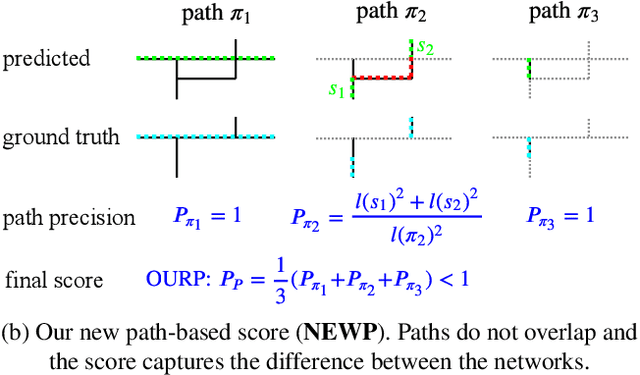
Existing performance measures rank delineation algorithms inconsistently, which makes it difficult to decide which one is best in any given situation. We show that these inconsistencies stem from design flaws that make the metrics insensitive to whole classes of errors. To provide more reliable evaluation, we design three new metrics that are far more consistent even though they use very different approaches to comparing ground-truth and reconstructed road networks. We use both synthetic and real data to demonstrate this and advocate the use of these corrected metrics as a tool to gauge future progress.