 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent U-Net for Resource-Constrained Segmentation
Jun 11, 2019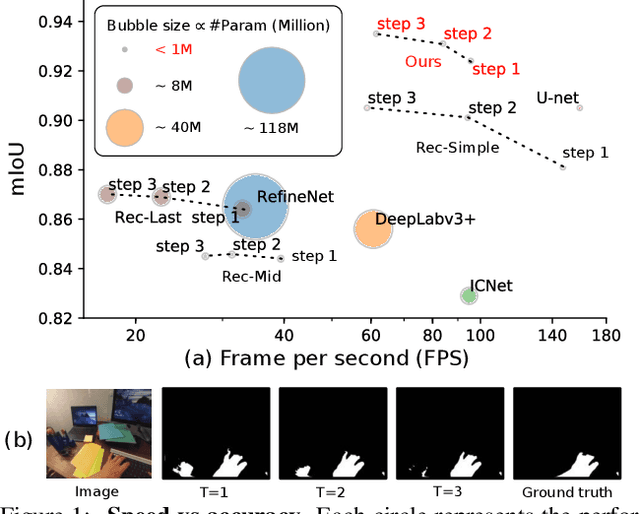
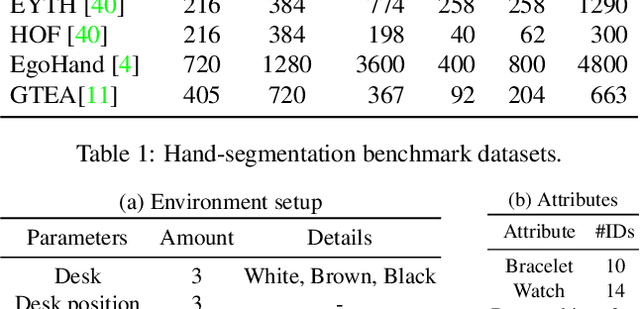
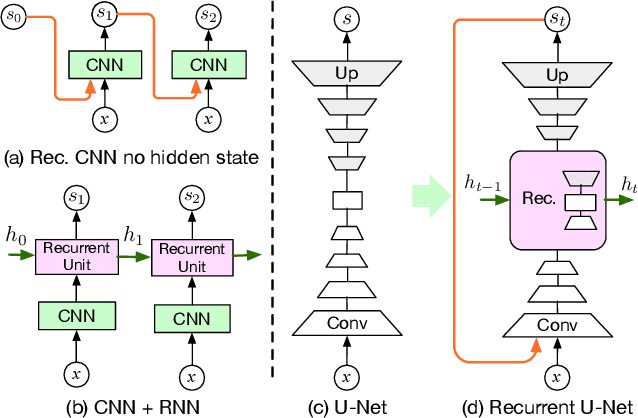

State-of-the-art segmentation methods rely on very deep networks that are not always easy to train without very large training datasets and tend to be relatively slow to run on standard GPUs. In this paper, we introduce a novel recurrent U-Net architecture that preserves the compactness of the original U-Net, while substantially increasing its performance to the point where it outperforms the state of the art on several benchmarks. We will demonstrate its effectiveness for several tasks, including hand segmentation, retina vessel segmentation, and road segmentation. We also introduce a large-scale dataset for hand segmentation.
Segmentation-driven 6D Object Pose Estimation
Jan 08, 2019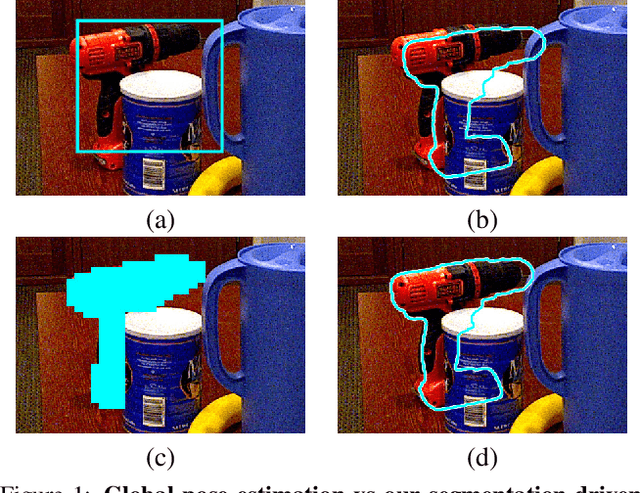
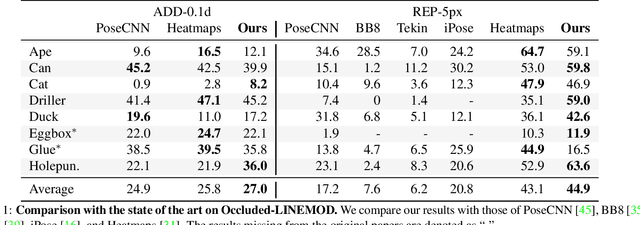
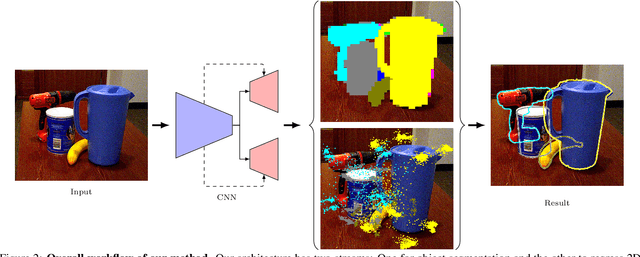

The most recent trend in estimating the 6D pose of rigid objects has been to train deep networks to either directly regress the pose from the image or to predict the 2D locations of 3D keypoints, from which the pose can be obtained using a PnP algorithm. In both cases, the object is treated as a global entity, and a single pose estimate is computed. As a consequence, the resulting techniques can be vulnerable to large occlusions. In this paper, we introduce a segmentation-driven 6D pose estimation framework where each visible part of the objects contributes a local pose prediction in the form of 2D keypoint locations. We then use a predicted measure of confidence to combine these pose candidates into a robust set of 3D-to-2D correspondences, from which a reliable pose estimate can be obtained. We outperform the state-of-the-art on the challenging Occluded-LINEMOD and YCB-Video datasets, which is evidence that our approach deals well with multiple poorly-textured objects occluding each other. Furthermore, it relies on a simple enough architecture to achieve real-time performance.
Beyond One Glance: Gated Recurrent Architecture for Hand Segmentation
Dec 12, 2018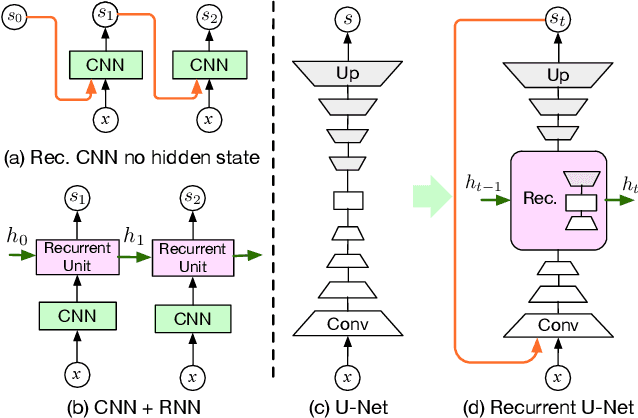
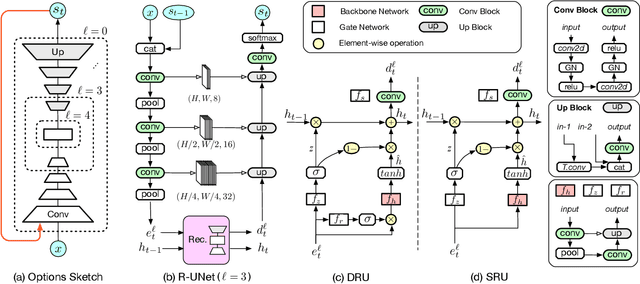

As mixed reality is gaining increased momentum, the development of effective and efficient solutions to egocentric hand segmentation is becoming critical. Traditional segmentation techniques typically follow a one-shot approach, where the image is passed forward only once through a model that produces a segmentation mask. This strategy, however, does not reflect the perception of humans, who continuously refine their representation of the world. In this paper, we therefore introduce a novel gated recurrent architecture. It goes beyond both iteratively passing the predicted segmentation mask through the network and adding a standard recurrent unit to it. Instead, it incorporates multiple encoder-decoder layers of the segmentation network, so as to keep track of its internal state in the refinement process. As evidenced by our results on standard hand segmentation benchmarks and on our own dataset, our approach outperforms these other, simpler recurrent segmentation techniques, as well as the state-of-the-art hand segmentation one. Furthermore, we demonstrate the generality of our approach by applying it to road segmentation, where it also outperforms other baseline methods.