 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInception Transformer
May 26, 2022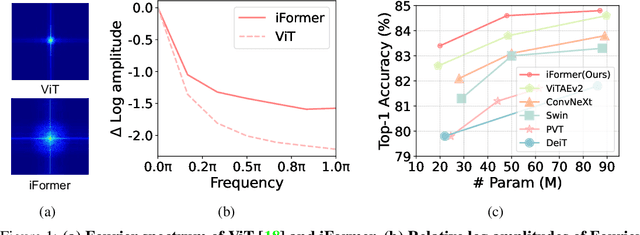
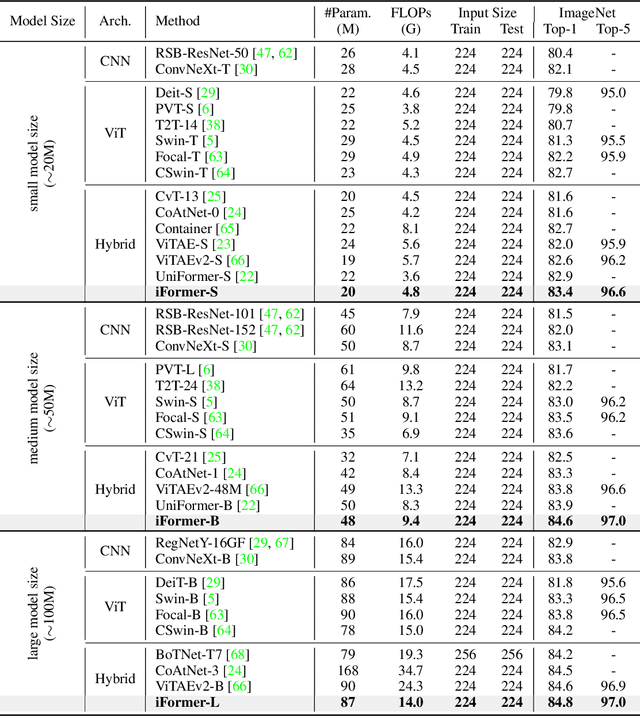
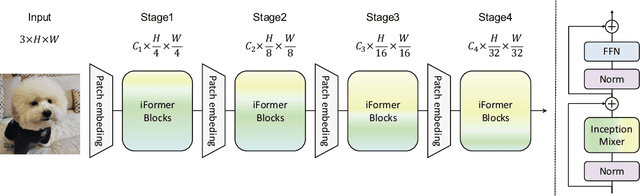
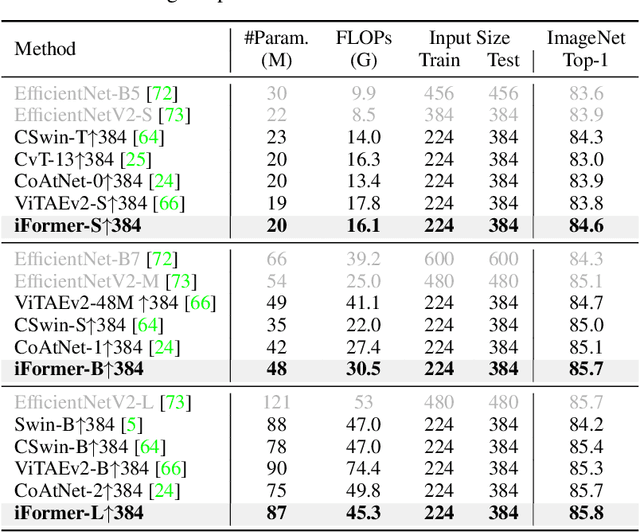
Recent studies show that Transformer has strong capability of building long-range dependencies, yet is incompetent in capturing high frequencies that predominantly convey local information. To tackle this issue, we present a novel and general-purpose Inception Transformer, or iFormer for short, that effectively learns comprehensive features with both high- and low-frequency information in visual data. Specifically, we design an Inception mixer to explicitly graft the advantages of convolution and max-pooling for capturing the high-frequency information to Transformers. Different from recent hybrid frameworks, the Inception mixer brings greater efficiency through a channel splitting mechanism to adopt parallel convolution/max-pooling path and self-attention path as high- and low-frequency mixers, while having the flexibility to model discriminative information scattered within a wide frequency range. Considering that bottom layers play more roles in capturing high-frequency details while top layers more in modeling low-frequency global information, we further introduce a frequency ramp structure, i.e. gradually decreasing the dimensions fed to the high-frequency mixer and increasing those to the low-frequency mixer, which can effectively trade-off high- and low-frequency components across different layers. We benchmark the iFormer on a series of vision tasks, and showcase that it achieves impressive performance on image classification, COCO detection and ADE20K segmentation. For example, our iFormer-S hits the top-1 accuracy of 83.4% on ImageNet-1K, much higher than DeiT-S by 3.6%, and even slightly better than much bigger model Swin-B (83.3%) with only 1/4 parameters and 1/3 FLOPs. Code and models will be released at https://github.com/sail-sg/iFormer.
Bandits for Structure Perturbation-based Black-box Attacks to Graph Neural Networks with Theoretical Guarantees
May 07, 2022
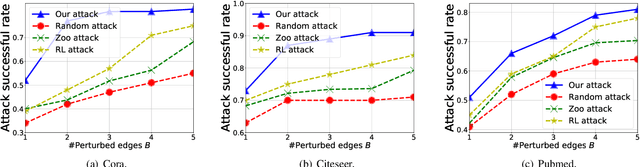
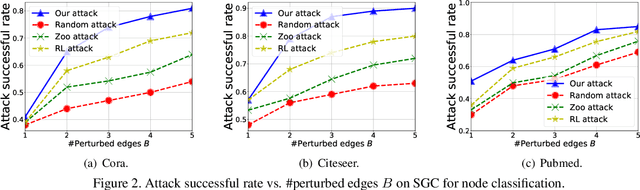
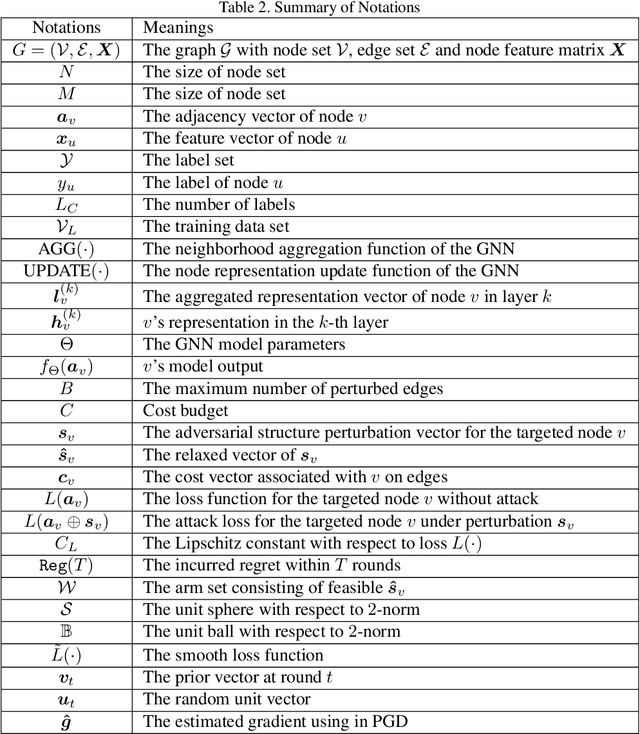
Graph neural networks (GNNs) have achieved state-of-the-art performance in many graph-based tasks such as node classification and graph classification. However, many recent works have demonstrated that an attacker can mislead GNN models by slightly perturbing the graph structure. Existing attacks to GNNs are either under the less practical threat model where the attacker is assumed to access the GNN model parameters, or under the practical black-box threat model but consider perturbing node features that are shown to be not enough effective. In this paper, we aim to bridge this gap and consider black-box attacks to GNNs with structure perturbation as well as with theoretical guarantees. We propose to address this challenge through bandit techniques. Specifically, we formulate our attack as an online optimization with bandit feedback. This original problem is essentially NP-hard due to the fact that perturbing the graph structure is a binary optimization problem. We then propose an online attack based on bandit optimization which is proven to be {sublinear} to the query number $T$, i.e., $\mathcal{O}(\sqrt{N}T^{3/4})$ where $N$ is the number of nodes in the graph. Finally, we evaluate our proposed attack by conducting experiments over multiple datasets and GNN models. The experimental results on various citation graphs and image graphs show that our attack is both effective and efficient. Source code is available at~\url{https://github.com/Metaoblivion/Bandit_GNN_Attack}
Mugs: A Multi-Granular Self-Supervised Learning Framework
Mar 27, 2022
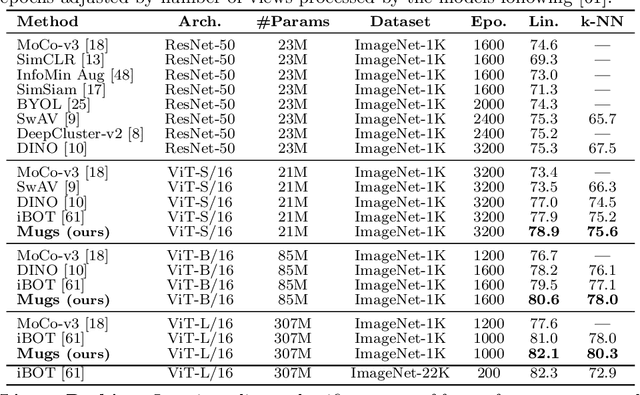
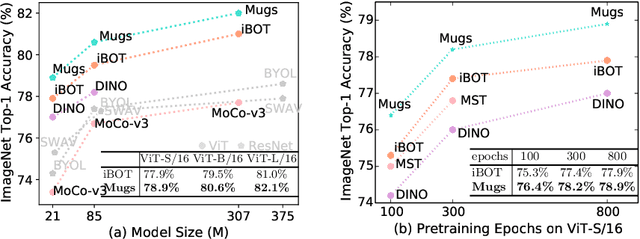
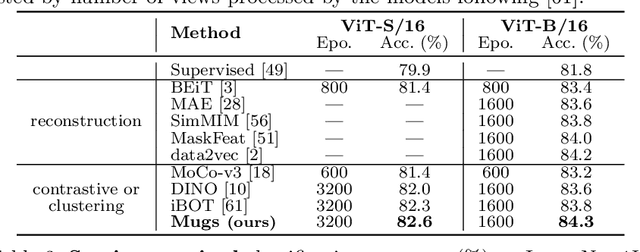
In self-supervised learning, multi-granular features are heavily desired though rarely investigated, as different downstream tasks (e.g., general and fine-grained classification) often require different or multi-granular features, e.g.~fine- or coarse-grained one or their mixture. In this work, for the first time, we propose an effective MUlti-Granular Self-supervised learning (Mugs) framework to explicitly learn multi-granular visual features. Mugs has three complementary granular supervisions: 1) an instance discrimination supervision (IDS), 2) a novel local-group discrimination supervision (LGDS), and 3) a group discrimination supervision (GDS). IDS distinguishes different instances to learn instance-level fine-grained features. LGDS aggregates features of an image and its neighbors into a local-group feature, and pulls local-group features from different crops of the same image together and push them away for others. It provides complementary instance supervision to IDS via an extra alignment on local neighbors, and scatters different local-groups separately to increase discriminability. Accordingly, it helps learn high-level fine-grained features at a local-group level. Finally, to prevent similar local-groups from being scattered randomly or far away, GDS brings similar samples close and thus pulls similar local-groups together, capturing coarse-grained features at a (semantic) group level. Consequently, Mugs can capture three granular features that often enjoy higher generality on diverse downstream tasks over single-granular features, e.g.~instance-level fine-grained features in contrastive learning. By only pretraining on ImageNet-1K, Mugs sets new SoTA linear probing accuracy 82.1$\%$ on ImageNet-1K and improves previous SoTA by $1.1\%$. It also surpasses SoTAs on other tasks, e.g. transfer learning, detection and segmentation.
Self-Promoted Supervision for Few-Shot Transformer
Mar 14, 2022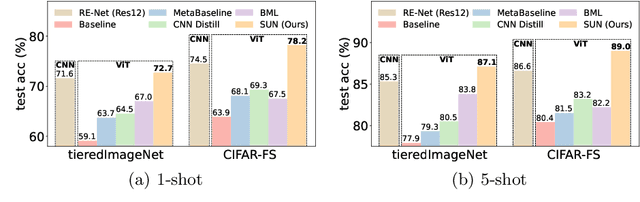
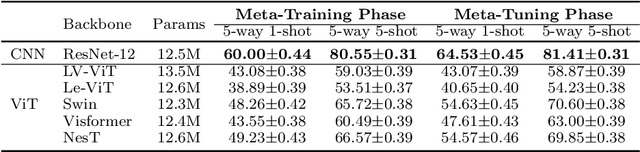
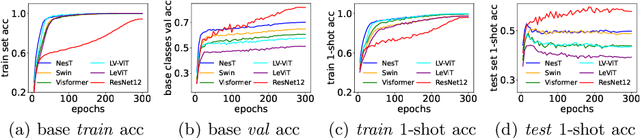
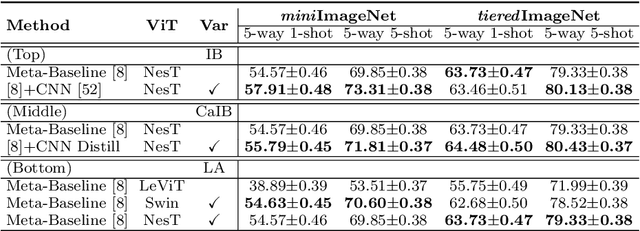
The few-shot learning ability of vision transformers (ViTs) is rarely investigated though heavily desired. In this work, we empirically find that with the same few-shot learning frameworks, e.g., Meta-Baseline, replacing the widely used CNN feature extractor with a ViT model often severely impairs few-shot classification performance. Moreover, our empirical study shows that in the absence of inductive bias, ViTs often learn the dependencies among input tokens slowly under few-shot learning regime where only a few labeled training data are available, which largely contributes to the above performance degradation. To alleviate this issue, for the first time, we propose a simple yet effective few-shot training framework for ViTs, namely Self-promoted sUpervisioN (SUN). Specifically, besides the conventional global supervision for global semantic learning, SUN further pretrains the ViT on the few-shot learning dataset and then uses it to generate individual location-specific supervision for guiding each patch token. This location-specific supervision tells the ViT which patch tokens are similar or dissimilar and thus accelerates token dependency learning. Moreover, it models the local semantics in each patch token to improve the object grounding and recognition capability which helps learn generalizable patterns. To improve the quality of location-specific supervision, we further propose two techniques:~1) background patch filtration to filtrate background patches out and assign them into an extra background class; and 2) spatial-consistent augmentation to introduce sufficient diversity for data augmentation while keeping the accuracy of the generated local supervisions. Experimental results show that SUN using ViTs significantly surpasses other few-shot learning frameworks with ViTs and is the first one that achieves higher performance than those CNN state-of-the-arts.
Exploring Optical-Flow-Guided Motion and Detection-Based Appearance for Temporal Sentence Grounding
Mar 06, 2022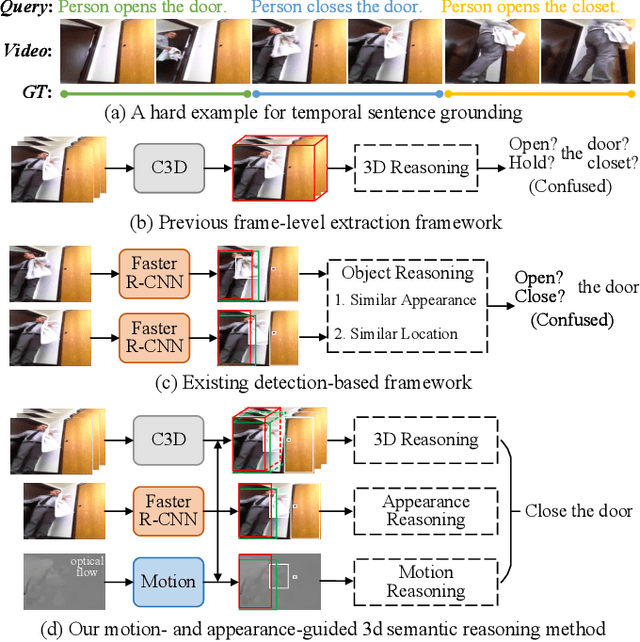
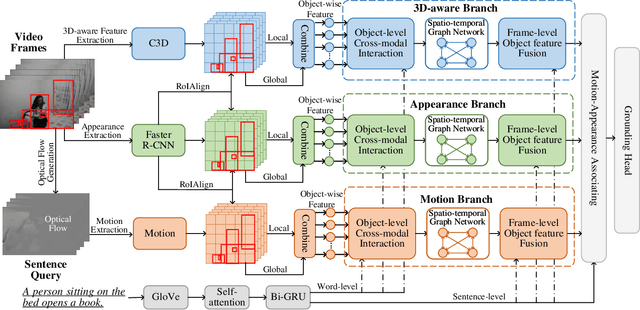
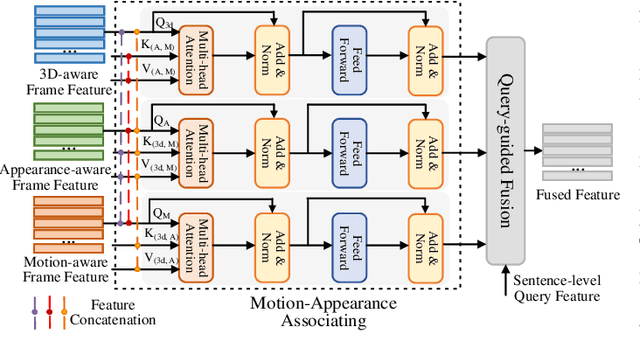
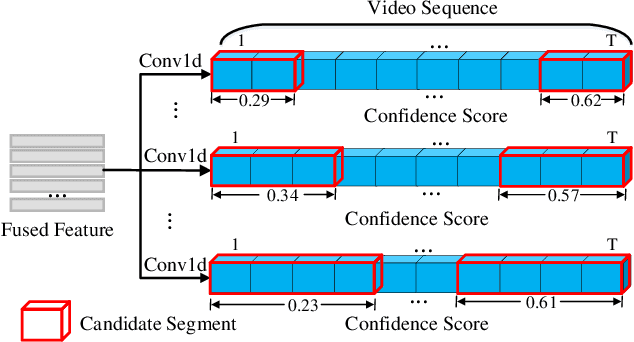
Temporal sentence grounding aims to localize a target segment in an untrimmed video semantically according to a given sentence query. Most previous works focus on learning frame-level features of each whole frame in the entire video, and directly match them with the textual information. Such frame-level feature extraction leads to the obstacles of these methods in distinguishing ambiguous video frames with complicated contents and subtle appearance differences, thus limiting their performance. In order to differentiate fine-grained appearance similarities among consecutive frames, some state-of-the-art methods additionally employ a detection model like Faster R-CNN to obtain detailed object-level features in each frame for filtering out the redundant background contents. However, these methods suffer from missing motion analysis since the object detection module in Faster R-CNN lacks temporal modeling. To alleviate the above limitations, in this paper, we propose a novel Motion- and Appearance-guided 3D Semantic Reasoning Network (MA3SRN), which incorporates optical-flow-guided motion-aware, detection-based appearance-aware, and 3D-aware object-level features to better reason the spatial-temporal object relations for accurately modelling the activity among consecutive frames. Specifically, we first develop three individual branches for motion, appearance, and 3D encoding separately to learn fine-grained motion-guided, appearance-guided, and 3D-aware object features, respectively. Then, both motion and appearance information from corresponding branches are associated to enhance the 3D-aware features for the final precise grounding. Extensive experiments on three challenging datasets (ActivityNet Caption, Charades-STA and TACoS) demonstrate that the proposed MA3SRN model achieves a new state-of-the-art.
End-to-end contextual asr based on posterior distribution adaptation for hybrid ctc/attention system
Feb 18, 2022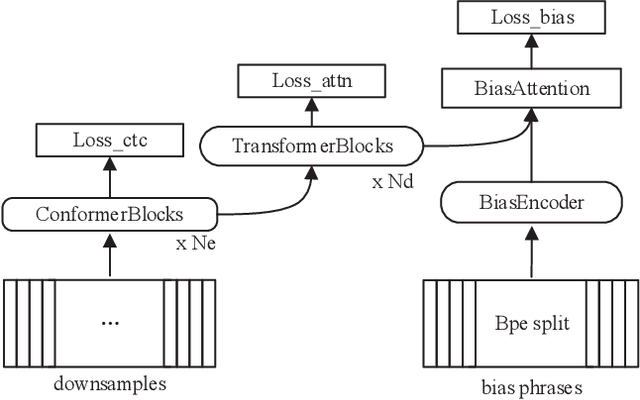
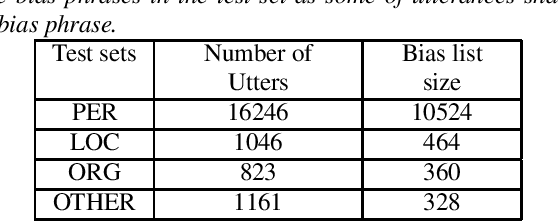
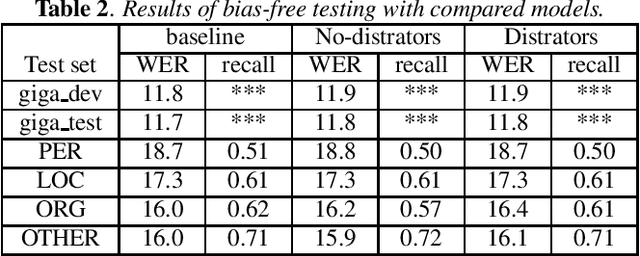
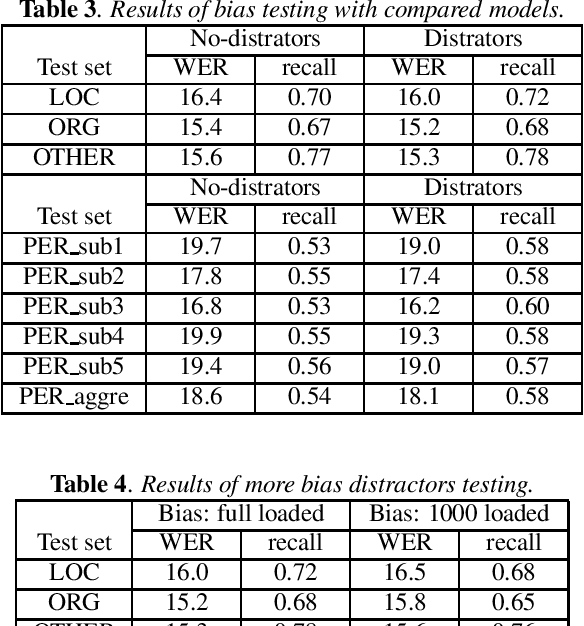
End-to-end (E2E) speech recognition architectures assemble all components of traditional speech recognition system into a single model. Although it simplifies ASR system, it introduces contextual ASR drawback: the E2E model has worse performance on utterances containing infrequent proper nouns. In this work, we propose to add a contextual bias attention (CBA) module to attention based encoder decoder (AED) model to improve its ability of recognizing the contextual phrases. Specifically, CBA utilizes the context vector of source attention in decoder to attend to a specific bias embedding. Jointly learned with the basic AED parameters, CBA can tell the model when and where to bias its output probability distribution. At inference stage, a list of bias phrases is preloaded and we adapt the posterior distributions of both CTC and attention decoder according to the attended bias phrase of CBA. We evaluate the proposed method on GigaSpeech and achieve a consistent relative improvement on recall rate of bias phrases ranging from 15% to 28% compared to the baseline model. Meanwhile, our method shows a strong anti-bias ability as the performance on general tests only degrades 1.7% even 2,000 bias phrases are present.
Unsupervised Temporal Video Grounding with Deep Semantic Clustering
Jan 14, 2022
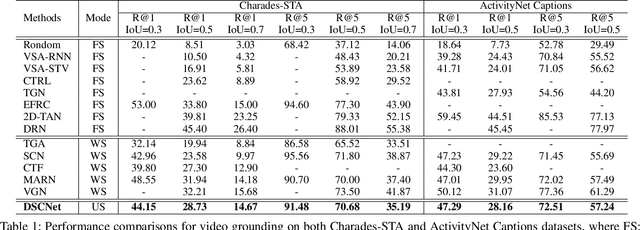
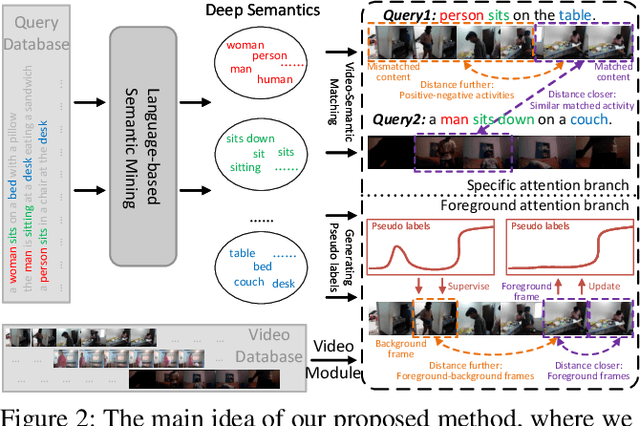

Temporal video grounding (TVG) aims to localize a target segment in a video according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on abundant video-query paired data, which is expensive and time-consuming to collect in real-world scenarios. In this paper, we explore whether a video grounding model can be learned without any paired annotations. To the best of our knowledge, this paper is the first work trying to address TVG in an unsupervised setting. Considering there is no paired supervision, we propose a novel Deep Semantic Clustering Network (DSCNet) to leverage all semantic information from the whole query set to compose the possible activity in each video for grounding. Specifically, we first develop a language semantic mining module, which extracts implicit semantic features from the whole query set. Then, these language semantic features serve as the guidance to compose the activity in video via a video-based semantic aggregation module. Finally, we utilize a foreground attention branch to filter out the redundant background activities and refine the grounding results. To validate the effectiveness of our DSCNet, we conduct experiments on both ActivityNet Captions and Charades-STA datasets. The results demonstrate that DSCNet achieves competitive performance, and even outperforms most weakly-supervised approaches.
Exploring Motion and Appearance Information for Temporal Sentence Grounding
Jan 03, 2022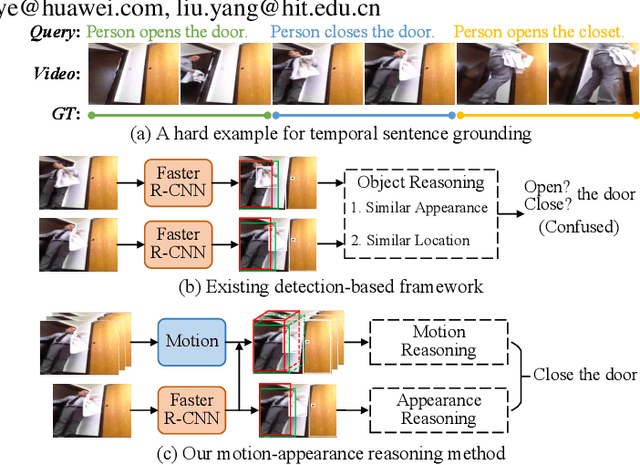
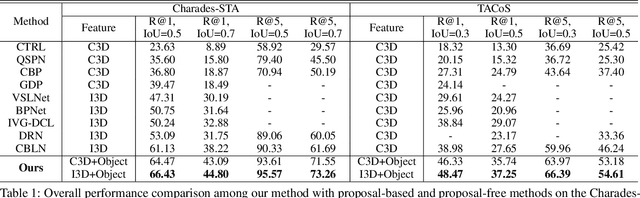
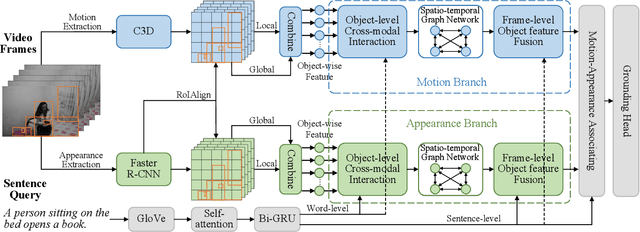

This paper addresses temporal sentence grounding. Previous works typically solve this task by learning frame-level video features and align them with the textual information. A major limitation of these works is that they fail to distinguish ambiguous video frames with subtle appearance differences due to frame-level feature extraction. Recently, a few methods adopt Faster R-CNN to extract detailed object features in each frame to differentiate the fine-grained appearance similarities. However, the object-level features extracted by Faster R-CNN suffer from missing motion analysis since the object detection model lacks temporal modeling. To solve this issue, we propose a novel Motion-Appearance Reasoning Network (MARN), which incorporates both motion-aware and appearance-aware object features to better reason object relations for modeling the activity among successive frames. Specifically, we first introduce two individual video encoders to embed the video into corresponding motion-oriented and appearance-aspect object representations. Then, we develop separate motion and appearance branches to learn motion-guided and appearance-guided object relations, respectively. At last, both motion and appearance information from two branches are associated to generate more representative features for final grounding. Extensive experiments on two challenging datasets (Charades-STA and TACoS) show that our proposed MARN significantly outperforms previous state-of-the-art methods by a large margin.
Memory-Guided Semantic Learning Network for Temporal Sentence Grounding
Jan 03, 2022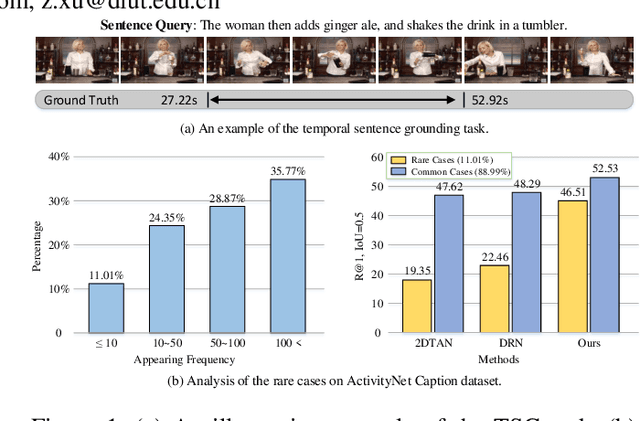
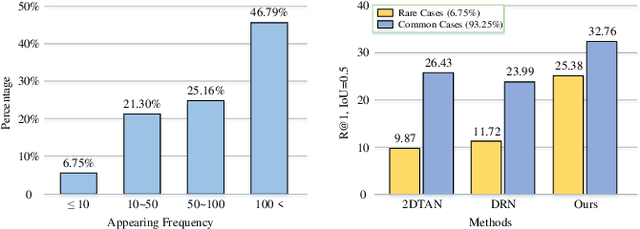
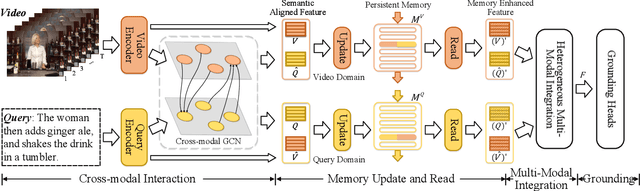
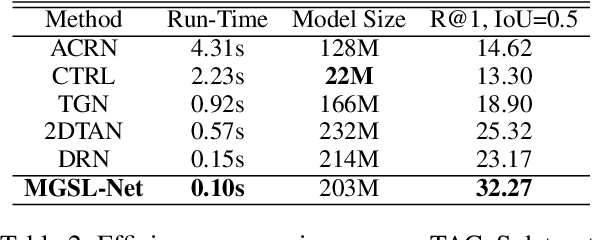
Temporal sentence grounding (TSG) is crucial and fundamental for video understanding. Although the existing methods train well-designed deep networks with a large amount of data, we find that they can easily forget the rarely appeared cases in the training stage due to the off-balance data distribution, which influences the model generalization and leads to undesirable performance. To tackle this issue, we propose a memory-augmented network, called Memory-Guided Semantic Learning Network (MGSL-Net), that learns and memorizes the rarely appeared content in TSG tasks. Specifically, MGSL-Net consists of three main parts: a cross-modal inter-action module, a memory augmentation module, and a heterogeneous attention module. We first align the given video-query pair by a cross-modal graph convolutional network, and then utilize a memory module to record the cross-modal shared semantic features in the domain-specific persistent memory. During training, the memory slots are dynamically associated with both common and rare cases, alleviating the forgetting issue. In testing, the rare cases can thus be enhanced by retrieving the stored memories, resulting in better generalization. At last, the heterogeneous attention module is utilized to integrate the enhanced multi-modal features in both video and query domains. Experimental results on three benchmarks show the superiority of our method on both effectiveness and efficiency, which substantially improves the accuracy not only on the entire dataset but also on rare cases.
DualFormer: Local-Global Stratified Transformer for Efficient Video Recognition
Dec 09, 2021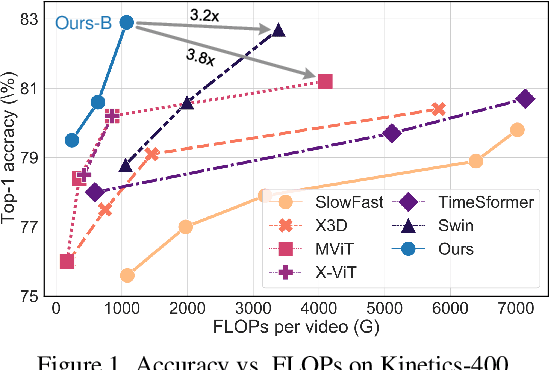
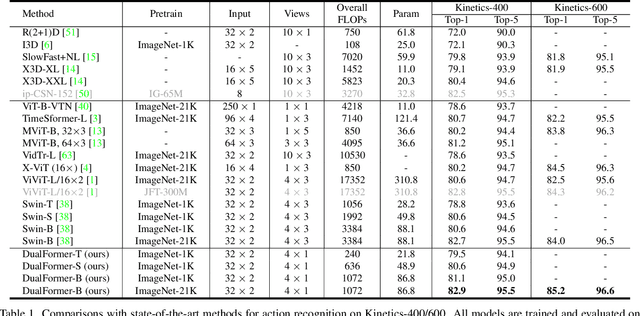
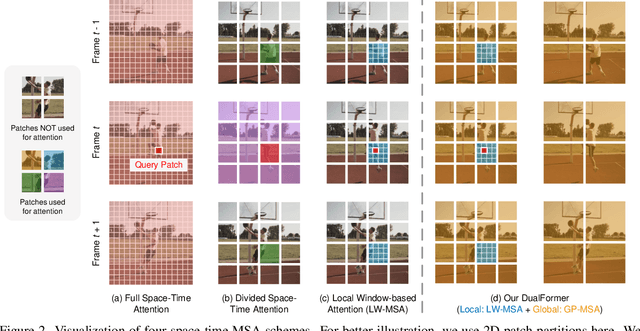
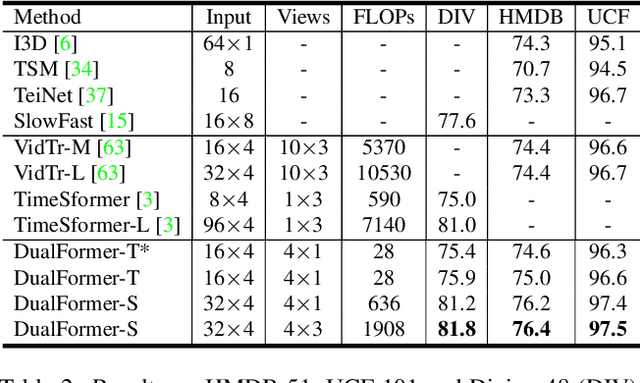
While transformers have shown great potential on video recognition tasks with their strong capability of capturing long-range dependencies, they often suffer high computational costs induced by self-attention operation on the huge number of 3D tokens in a video. In this paper, we propose a new transformer architecture, termed DualFormer, which can effectively and efficiently perform space-time attention for video recognition. Specifically, our DualFormer stratifies the full space-time attention into dual cascaded levels, i.e., to first learn fine-grained local space-time interactions among nearby 3D tokens, followed by the capture of coarse-grained global dependencies between the query token and the coarse-grained global pyramid contexts. Different from existing methods that apply space-time factorization or restrict attention computations within local windows for improving efficiency, our local-global stratified strategy can well capture both short- and long-range spatiotemporal dependencies, and meanwhile greatly reduces the number of keys and values in attention computation to boost efficiency. Experimental results show the superiority of DualFormer on five video benchmarks against existing methods. In particular, DualFormer sets new state-of-the-art 82.9%/85.2% top-1 accuracy on Kinetics-400/600 with around 1000G inference FLOPs which is at least 3.2 times fewer than existing methods with similar performances.