 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Learning for Arcing Detection in Pantograph-Catenary Systems
Feb 09, 2026The pantograph-catenary interface is essential for ensuring uninterrupted and reliable power delivery in electrified rail systems. However, electrical arcing at this interface poses serious risks, including accelerated wear of contact components, degraded system performance, and potential service disruptions. Detecting arcing events at the pantograph-catenary interface is challenging due to their transient nature, noisy operating environment, data scarcity, and the difficulty of distinguishing arcs from other similar transient phenomena. To address these challenges, we propose a novel multimodal framework that combines high-resolution image data with force measurements to more accurately and robustly detect arcing events. First, we construct two arcing detection datasets comprising synchronized visual and force measurements. One dataset is built from data provided by the Swiss Federal Railways (SBB), and the other is derived from publicly available videos of arcing events in different railway systems and synthetic force data that mimic the characteristics observed in the real dataset. Leveraging these datasets, we propose MultiDeepSAD, an extension of the DeepSAD algorithm for multiple modalities with a new loss formulation. Additionally, we introduce tailored pseudo-anomaly generation techniques specific to each data type, such as synthetic arc-like artifacts in images and simulated force irregularities, to augment training data and improve the discriminative ability of the model. Through extensive experiments and ablation studies, we demonstrate that our framework significantly outperforms baseline approaches, exhibiting enhanced sensitivity to real arcing events even under domain shifts and limited availability of real arcing observations.
Time-Vertex Machine Learning for Optimal Sensor Placement in Temporal Graph Signals: Applications in Structural Health Monitoring
Dec 22, 2025Structural Health Monitoring (SHM) plays a crucial role in maintaining the safety and resilience of infrastructure. As sensor networks grow in scale and complexity, identifying the most informative sensors becomes essential to reduce deployment costs without compromising monitoring quality. While Graph Signal Processing (GSP) has shown promise by leveraging spatial correlations among sensor nodes, conventional approaches often overlook the temporal dynamics of structural behavior. To overcome this limitation, we propose Time-Vertex Machine Learning (TVML), a novel framework that integrates GSP, time-domain analysis, and machine learning to enable interpretable and efficient sensor placement by identifying representative nodes that minimize redundancy while preserving critical information. We evaluate the proposed approach on two bridge datasets for damage detection and time-varying graph signal reconstruction tasks. The results demonstrate the effectiveness of our approach in enhancing SHM systems by providing a robust, adaptive, and efficient solution for sensor placement.
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Aug 07, 2025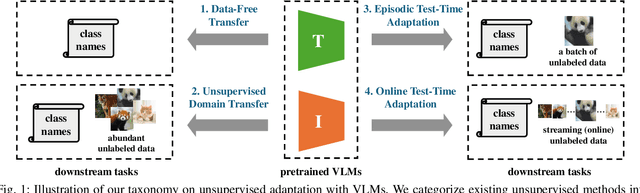
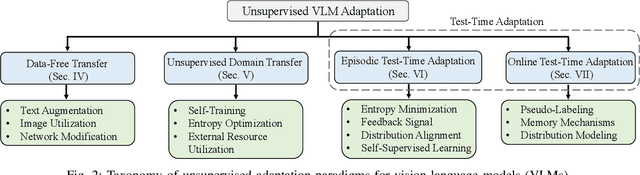
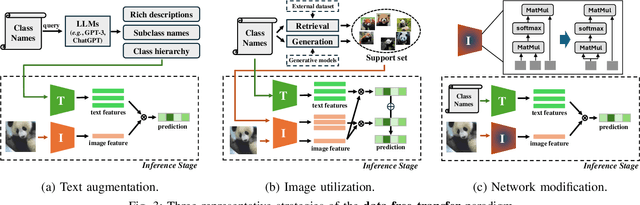
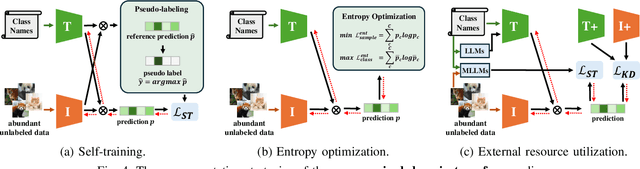
Vision-Language Models (VLMs) have demonstrated remarkable generalization capabilities across a wide range of tasks. However, their performance often remains suboptimal when directly applied to specific downstream scenarios without task-specific adaptation. To enhance their utility while preserving data efficiency, recent research has increasingly focused on unsupervised adaptation methods that do not rely on labeled data. Despite the growing interest in this area, there remains a lack of a unified, task-oriented survey dedicated to unsupervised VLM adaptation. To bridge this gap, we present a comprehensive and structured overview of the field. We propose a taxonomy based on the availability and nature of unlabeled visual data, categorizing existing approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data), and Online Test-Time Adaptation (streaming data). Within this framework, we analyze core methodologies and adaptation strategies associated with each paradigm, aiming to establish a systematic understanding of the field. Additionally, we review representative benchmarks across diverse applications and highlight open challenges and promising directions for future research. An actively maintained repository of relevant literature is available at https://github.com/tim-learn/Awesome-LabelFree-VLMs.
Integrating Physics-Based and Data-Driven Approaches for Probabilistic Building Energy Modeling
Jul 23, 2025Building energy modeling is a key tool for optimizing the performance of building energy systems. Historically, a wide spectrum of methods has been explored -- ranging from conventional physics-based models to purely data-driven techniques. Recently, hybrid approaches that combine the strengths of both paradigms have gained attention. These include strategies such as learning surrogates for physics-based models, modeling residuals between simulated and observed data, fine-tuning surrogates with real-world measurements, using physics-based outputs as additional inputs for data-driven models, and integrating the physics-based output into the loss function the data-driven model. Despite this progress, two significant research gaps remain. First, most hybrid methods focus on deterministic modeling, often neglecting the inherent uncertainties caused by factors like weather fluctuations and occupant behavior. Second, there has been little systematic comparison within a probabilistic modeling framework. This study addresses these gaps by evaluating five representative hybrid approaches for probabilistic building energy modeling, focusing on quantile predictions of building thermodynamics in a real-world case study. Our results highlight two main findings. First, the performance of hybrid approaches varies across different building room types, but residual learning with a Feedforward Neural Network performs best on average. Notably, the residual approach is the only model that produces physically intuitive predictions when applied to out-of-distribution test data. Second, Quantile Conformal Prediction is an effective procedure for calibrating quantile predictions in case of indoor temperature modeling.
Heterogeneous Graph Neural Networks for Short-term State Forecasting in Power Systems across Domains and Time Scales: A Hydroelectric Power Plant Case Study
Jul 09, 2025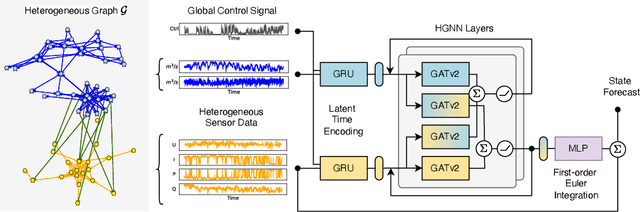
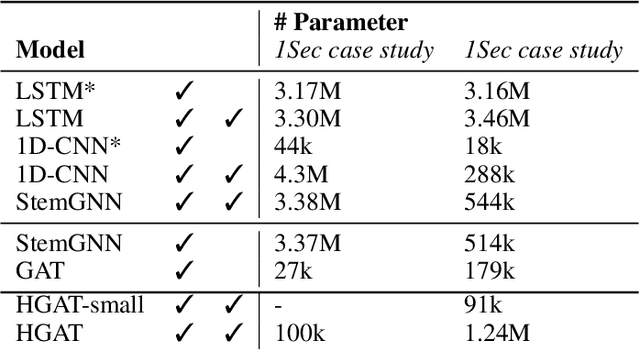
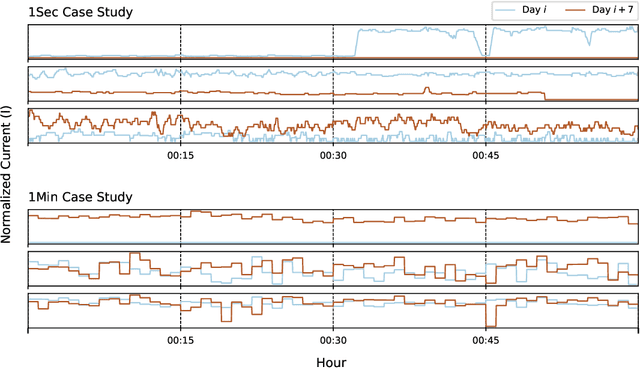
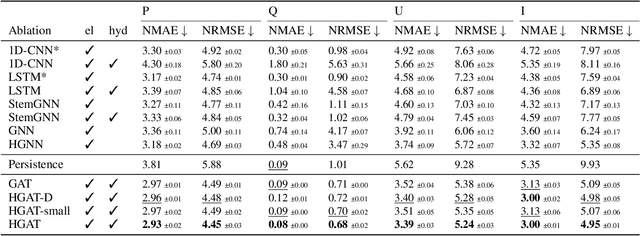
Accurate short-term state forecasting is essential for efficient and stable operation of modern power systems, especially in the context of increasing variability introduced by renewable and distributed energy resources. As these systems evolve rapidly, it becomes increasingly important to reliably predict their states in the short term to ensure operational stability, support control decisions, and enable interpretable monitoring of sensor and machine behavior. Modern power systems often span multiple physical domains - including electrical, mechanical, hydraulic, and thermal - posing significant challenges for modeling and prediction. Graph Neural Networks (GNNs) have emerged as a promising data-driven framework for system state estimation and state forecasting in such settings. By leveraging the topological structure of sensor networks, GNNs can implicitly learn inter-sensor relationships and propagate information across the network. However, most existing GNN-based methods are designed under the assumption of homogeneous sensor relationships and are typically constrained to a single physical domain. This limitation restricts their ability to integrate and reason over heterogeneous sensor data commonly encountered in real-world energy systems, such as those used in energy conversion infrastructure. In this work, we propose the use of Heterogeneous Graph Attention Networks to address these limitations. Our approach models both homogeneous intra-domain and heterogeneous inter-domain relationships among sensor data from two distinct physical domains - hydraulic and electrical - which exhibit fundamentally different temporal dynamics. Experimental results demonstrate that our method significantly outperforms conventional baselines on average by 35.5% in terms of normalized root mean square error, confirming its effectiveness in multi-domain, multi-rate power system state forecasting.
To Trust Or Not To Trust Your Vision-Language Model's Prediction
May 29, 2025Vision-Language Models (VLMs) have demonstrated strong capabilities in aligning visual and textual modalities, enabling a wide range of applications in multimodal understanding and generation. While they excel in zero-shot and transfer learning scenarios, VLMs remain susceptible to misclassification, often yielding confident yet incorrect predictions. This limitation poses a significant risk in safety-critical domains, where erroneous predictions can lead to severe consequences. In this work, we introduce TrustVLM, a training-free framework designed to address the critical challenge of estimating when VLM's predictions can be trusted. Motivated by the observed modality gap in VLMs and the insight that certain concepts are more distinctly represented in the image embedding space, we propose a novel confidence-scoring function that leverages this space to improve misclassification detection. We rigorously evaluate our approach across 17 diverse datasets, employing 4 architectures and 2 VLMs, and demonstrate state-of-the-art performance, with improvements of up to 51.87% in AURC, 9.14% in AUROC, and 32.42% in FPR95 compared to existing baselines. By improving the reliability of the model without requiring retraining, TrustVLM paves the way for safer deployment of VLMs in real-world applications. The code will be available at https://github.com/EPFL-IMOS/TrustVLM.
Extremely Simple Multimodal Outlier Synthesis for Out-of-Distribution Detection and Segmentation
May 22, 2025Out-of-distribution (OOD) detection and segmentation are crucial for deploying machine learning models in safety-critical applications such as autonomous driving and robot-assisted surgery. While prior research has primarily focused on unimodal image data, real-world applications are inherently multimodal, requiring the integration of multiple modalities for improved OOD detection. A key challenge is the lack of supervision signals from unknown data, leading to overconfident predictions on OOD samples. To address this challenge, we propose Feature Mixing, an extremely simple and fast method for multimodal outlier synthesis with theoretical support, which can be further optimized to help the model better distinguish between in-distribution (ID) and OOD data. Feature Mixing is modality-agnostic and applicable to various modality combinations. Additionally, we introduce CARLA-OOD, a novel multimodal dataset for OOD segmentation, featuring synthetic OOD objects across diverse scenes and weather conditions. Extensive experiments on SemanticKITTI, nuScenes, CARLA-OOD datasets, and the MultiOOD benchmark demonstrate that Feature Mixing achieves state-of-the-art performance with a $10 \times$ to $370 \times$ speedup. Our source code and dataset will be available at https://github.com/mona4399/FeatureMixing.
Equi-Euler GraphNet: An Equivariant, Temporal-Dynamics Informed Graph Neural Network for Dual Force and Trajectory Prediction in Multi-Body Systems
Apr 22, 2025



Accurate real-time modeling of multi-body dynamical systems is essential for enabling digital twin applications across industries. While many data-driven approaches aim to learn system dynamics, jointly predicting internal loads and system trajectories remains a key challenge. This dual prediction is especially important for fault detection and predictive maintenance, where internal loads-such as contact forces-act as early indicators of faults, reflecting wear or misalignment before affecting motion. These forces also serve as inputs to degradation models (e.g., crack growth), enabling damage prediction and remaining useful life estimation. We propose Equi-Euler GraphNet, a physics-informed graph neural network (GNN) that simultaneously predicts internal forces and global trajectories in multi-body systems. In this mesh-free framework, nodes represent system components and edges encode interactions. Equi-Euler GraphNet introduces two inductive biases: (1) an equivariant message-passing scheme, interpreting edge messages as interaction forces consistent under Euclidean transformations; and (2) a temporal-aware iterative node update mechanism, based on Euler integration, to capture influence of distant interactions over time. Tailored for cylindrical roller bearings, it decouples ring dynamics from constrained motion of rolling elements. Trained on high-fidelity multiphysics simulations, Equi-Euler GraphNet generalizes beyond the training distribution, accurately predicting loads and trajectories under unseen speeds, loads, and configurations. It outperforms state-of-the-art GNNs focused on trajectory prediction, delivering stable rollouts over thousands of time steps with minimal error accumulation. Achieving up to a 200x speedup over conventional solvers while maintaining comparable accuracy, it serves as an efficient reduced-order model for digital twins, design, and maintenance.
Thermoxels: a voxel-based method to generate simulation-ready 3D thermal models
Apr 06, 2025In the European Union, buildings account for 42% of energy use and 35% of greenhouse gas emissions. Since most existing buildings will still be in use by 2050, retrofitting is crucial for emissions reduction. However, current building assessment methods rely mainly on qualitative thermal imaging, which limits data-driven decisions for energy savings. On the other hand, quantitative assessments using finite element analysis (FEA) offer precise insights but require manual CAD design, which is tedious and error-prone. Recent advances in 3D reconstruction, such as Neural Radiance Fields (NeRF) and Gaussian Splatting, enable precise 3D modeling from sparse images but lack clearly defined volumes and the interfaces between them needed for FEA. We propose Thermoxels, a novel voxel-based method able to generate FEA-compatible models, including both geometry and temperature, from a sparse set of RGB and thermal images. Using pairs of RGB and thermal images as input, Thermoxels represents a scene's geometry as a set of voxels comprising color and temperature information. After optimization, a simple process is used to transform Thermoxels' models into tetrahedral meshes compatible with FEA. We demonstrate Thermoxels' capability to generate RGB+Thermal meshes of 3D scenes, surpassing other state-of-the-art methods. To showcase the practical applications of Thermoxels' models, we conduct a simple heat conduction simulation using FEA, achieving convergence from an initial state defined by Thermoxels' thermal reconstruction. Additionally, we compare Thermoxels' image synthesis abilities with current state-of-the-art methods, showing competitive results, and discuss the limitations of existing metrics in assessing mesh quality.
Automated Processing of eXplainable Artificial Intelligence Outputs in Deep Learning Models for Fault Diagnostics of Large Infrastructures
Mar 19, 2025Deep Learning (DL) models processing images to recognize the health state of large infrastructure components can exhibit biases and rely on non-causal shortcuts. eXplainable Artificial Intelligence (XAI) can address these issues but manually analyzing explanations generated by XAI techniques is time-consuming and prone to errors. This work proposes a novel framework that combines post-hoc explanations with semi-supervised learning to automatically identify anomalous explanations that deviate from those of correctly classified images and may therefore indicate model abnormal behaviors. This significantly reduces the workload for maintenance decision-makers, who only need to manually reclassify images flagged as having anomalous explanations. The proposed framework is applied to drone-collected images of insulator shells for power grid infrastructure monitoring, considering two different Convolutional Neural Networks (CNNs), GradCAM explanations and Deep Semi-Supervised Anomaly Detection. The average classification accuracy on two faulty classes is improved by 8% and maintenance operators are required to manually reclassify only 15% of the images. We compare the proposed framework with a state-of-the-art approach based on the faithfulness metric: the experimental results obtained demonstrate that the proposed framework consistently achieves F_1 scores larger than those of the faithfulness-based approach. Additionally, the proposed framework successfully identifies correct classifications that result from non-causal shortcuts, such as the presence of ID tags printed on insulator shells.