 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Visual Planning with Goal-Conditioned Hierarchical Predictors
Jun 23, 2020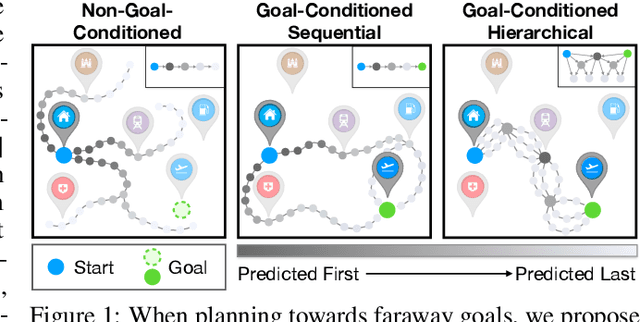
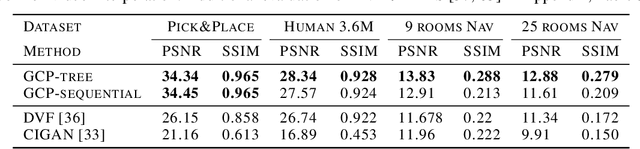

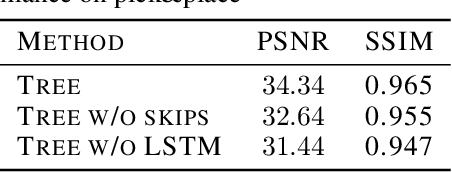
The ability to predict and plan into the future is fundamental for agents acting in the world. To reach a faraway goal, we predict trajectories at multiple timescales, first devising a coarse plan towards the goal and then gradually filling in details. In contrast, current learning approaches for visual prediction and planning fail on long-horizon tasks as they generate predictions (1) without considering goal information, and (2) at the finest temporal resolution, one step at a time. In this work we propose a framework for visual prediction and planning that is able to overcome both of these limitations. First, we formulate the problem of predicting towards a goal and propose the corresponding class of latent space goal-conditioned predictors (GCPs). GCPs significantly improve planning efficiency by constraining the search space to only those trajectories that reach the goal. Further, we show how GCPs can be naturally formulated as hierarchical models that, given two observations, predict an observation between them, and by recursively subdividing each part of the trajectory generate complete sequences. This divide-and-conquer strategy is effective at long-term prediction, and enables us to design an effective hierarchical planning algorithm that optimizes trajectories in a coarse-to-fine manner. We show that by using both goal-conditioning and hierarchical prediction, GCPs enable us to solve visual planning tasks with much longer horizon than previously possible.
Simple and Effective VAE Training with Calibrated Decoders
Jun 23, 2020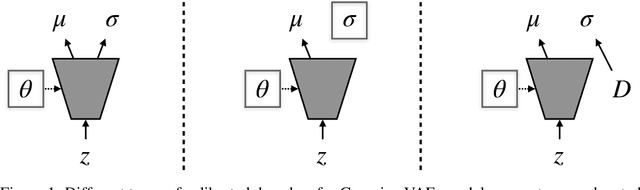


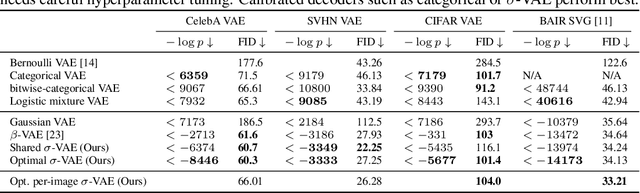
Variational autoencoders (VAEs) provide an effective and simple method for modeling complex distributions. However, training VAEs often requires considerable hyperparameter tuning, and often utilizes a heuristic weight on the prior KL-divergence term. In this work, we study how the performance of VAEs can be improved while not requiring the use of this heuristic hyperparameter, by learning calibrated decoders that accurately model the decoding distribution. While in some sense it may seem obvious that calibrated decoders should perform better than uncalibrated decoders, much of the recent literature that employs VAEs uses uncalibrated Gaussian decoders with constant variance. We observe empirically that the na\"{i}ve way of learning variance in Gaussian decoders does not lead to good results. However, {other calibrated decoders, such as discrete decoders or learning shared variance} can substantially improve performance. To further improve results, we propose a simple but novel modification to the commonly used Gaussian decoder, which represents the prediction variance non-parametrically. We observe empirically that using the heuristic weight hyperparameter is not necessary with our method. We analyze the performance of various discrete and continuous decoders on a range of datasets and several single-image and sequential VAE models. Project website: \url{https://orybkin.github.io/sigma-vae/}
Planning to Explore via Self-Supervised World Models
May 12, 2020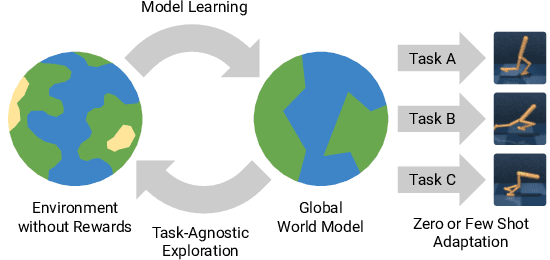
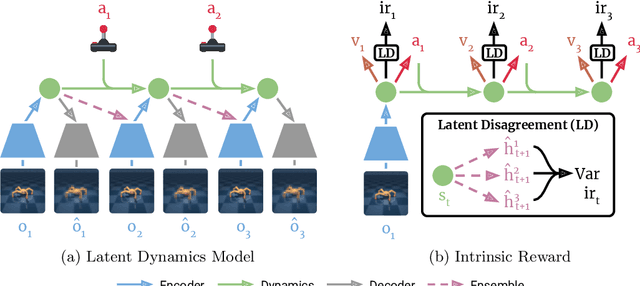
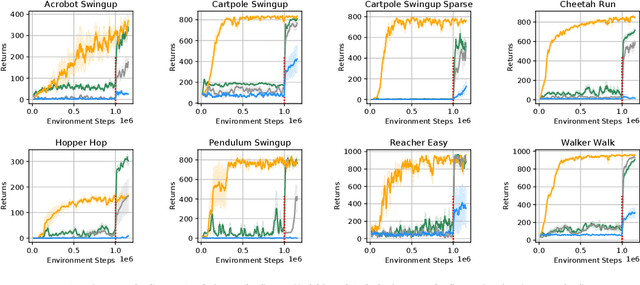
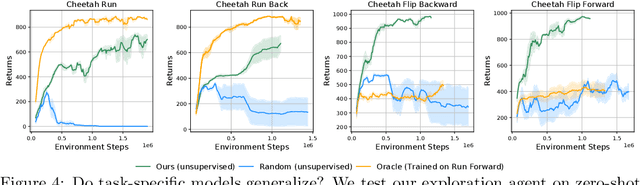
Reinforcement learning allows solving complex tasks, however, the learning tends to be task-specific and the sample efficiency remains a challenge. We present Plan2Explore, a self-supervised reinforcement learning agent that tackles both these challenges through a new approach to self-supervised exploration and fast adaptation to new tasks, which need not be known during exploration. During exploration, unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty. After exploration, the agent quickly adapts to multiple downstream tasks in a zero or a few-shot manner. We evaluate on challenging control tasks from high-dimensional image inputs. Without any training supervision or task-specific interaction, Plan2Explore outperforms prior self-supervised exploration methods, and in fact, almost matches the performances oracle which has access to rewards. Videos and code at https://ramanans1.github.io/plan2explore/
Learning Predictive Models From Observation and Interaction
Dec 30, 2019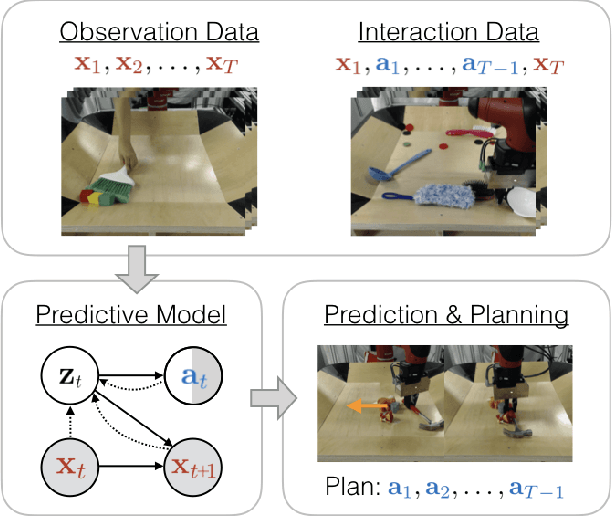


Learning predictive models from interaction with the world allows an agent, such as a robot, to learn about how the world works, and then use this learned model to plan coordinated sequences of actions to bring about desired outcomes. However, learning a model that captures the dynamics of complex skills represents a major challenge: if the agent needs a good model to perform these skills, it might never be able to collect the experience on its own that is required to learn these delicate and complex behaviors. Instead, we can imagine augmenting the training set with observational data of other agents, such as humans. Such data is likely more plentiful, but represents a different embodiment. For example, videos of humans might show a robot how to use a tool, but (i) are not annotated with suitable robot actions, and (ii) contain a systematic distributional shift due to the embodiment differences between humans and robots. We address the first challenge by formulating the corresponding graphical model and treating the action as an observed variable for the interaction data and an unobserved variable for the observation data, and the second challenge by using a domain-dependent prior. In addition to interaction data, our method is able to leverage videos of passive observations in a driving dataset and a dataset of robotic manipulation videos. A robotic planning agent equipped with our method can learn to use tools in a tabletop robotic manipulation setting by observing humans without ever seeing a robotic video of tool use.
KeyIn: Discovering Subgoal Structure with Keyframe-based Video Prediction
Apr 11, 2019
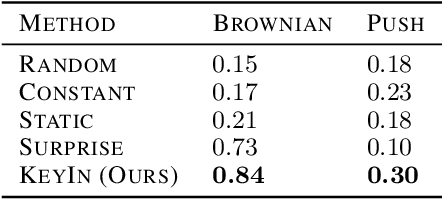
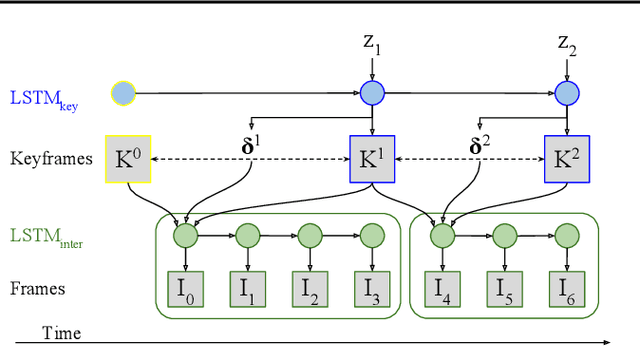
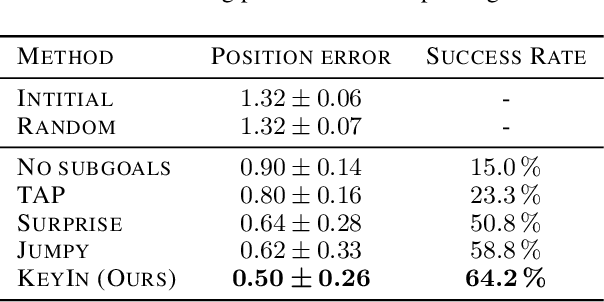
Real-world image sequences can often be naturally decomposed into a small number of frames depicting interesting, highly stochastic moments (its $\textit{keyframes}$) and the low-variance frames in between them. In image sequences depicting trajectories to a goal, keyframes can be seen as capturing the $\textit{subgoals}$ of the sequence as they depict the high-variance moments of interest that ultimately led to the goal. In this paper, we introduce a video prediction model that discovers the keyframe structure of image sequences in an unsupervised fashion. We do so using a hierarchical Keyframe-Intermediate model (KeyIn) that stochastically predicts keyframes and their offsets in time and then uses these predictions to deterministically predict the intermediate frames. We propose a differentiable formulation of this problem that allows us to train the full hierarchical model using a sequence reconstruction loss. We show that our model is able to find meaningful keyframe structure in a simulated dataset of robotic demonstrations and that these keyframes can serve as subgoals for planning. Our model outperforms other hierarchical prediction approaches for planning on a simulated pushing task.
Unsupervised Learning of Sensorimotor Affordances by Stochastic Future Prediction
Jun 25, 2018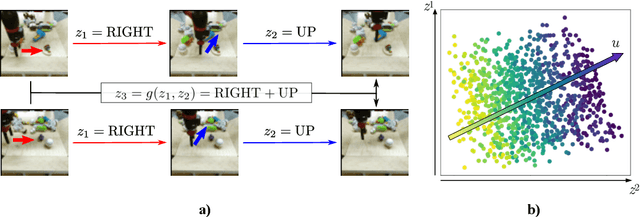
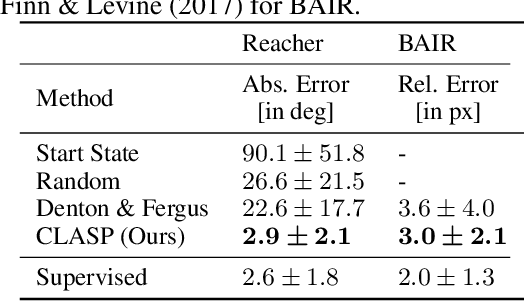
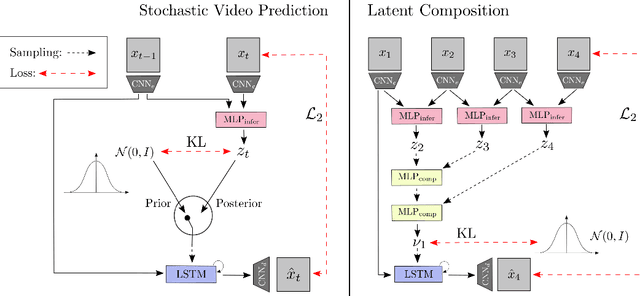
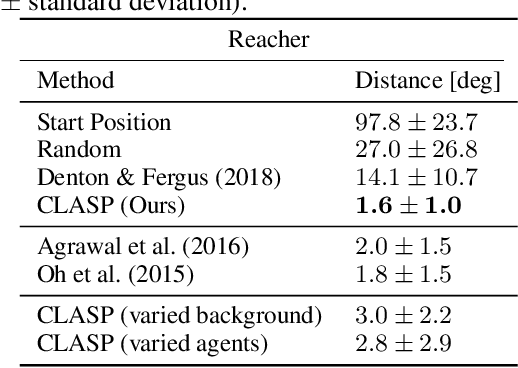
Recently, much progress has been made building systems that can capture static image properties, but natural environments are intrinsically dynamic. For an intelligent agent, perception is responsible not only for capturing features of scene content, but also capturing its \textit{affordances}: how the state of things can change, especially as the result of the agent's actions. We propose an unsupervised method to learn representations of the sensorimotor affordances of an environment. We do so by learning an embedding for stochastic future prediction that is (i) sensitive to scene dynamics and minimally sensitive to static scene content and (ii) compositional in nature, capturing the fact that changes in the environment can be composed to produce a cumulative change. We show that these two properties are sufficient to induce representations that are reusable across visually distinct scenes that share degrees of freedom. We show the applicability of our method to synthetic settings and its potential for understanding more complex, realistic visual settings.
Predicting the Future with Transformational States
Mar 26, 2018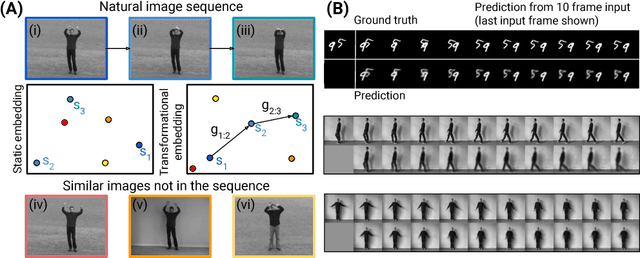
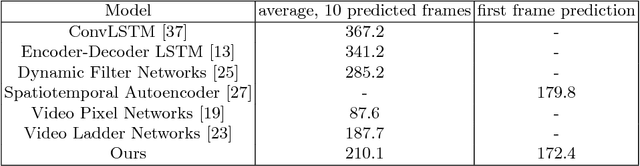
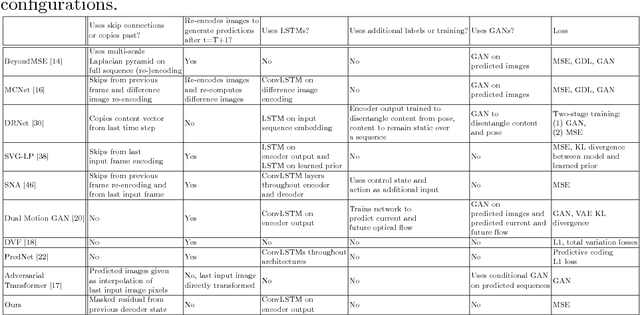

An intelligent observer looks at the world and sees not only what is, but what is moving and what can be moved. In other words, the observer sees how the present state of the world can transform in the future. We propose a model that predicts future images by learning to represent the present state and its transformation given only a sequence of images. To do so, we introduce an architecture with a latent state composed of two components designed to capture (i) the present image state and (ii) the transformation between present and future states, respectively. We couple this latent state with a recurrent neural network (RNN) core that predicts future frames by transforming past states into future states by applying the accumulated state transformation with a learned operator. We describe how this model can be integrated into an encoder-decoder convolutional neural network (CNN) architecture that uses weighted residual connections to integrate representations of the past with representations of the future. Qualitatively, our approach generates image sequences that are stable and capture realistic motion over multiple predicted frames, without requiring adversarial training. Quantitatively, our method achieves prediction results comparable to state-of-the-art results on standard image prediction benchmarks (Moving MNIST, KTH, and UCF101).