 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Manipulation via Locomotion using Hierarchical Sim2Real
Aug 13, 2019

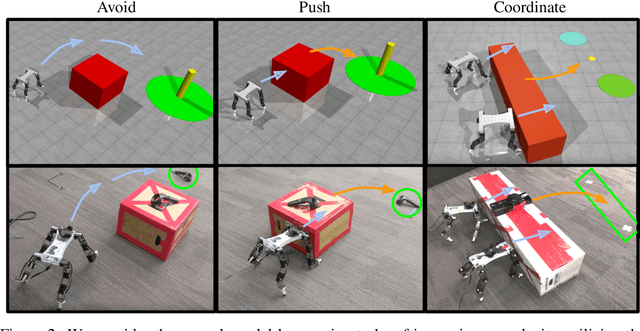

Manipulation and locomotion are closely related problems that are often studied in isolation. In this work, we study the problem of coordinating multiple mobile agents to exhibit manipulation behaviors using a reinforcement learning (RL) approach. Our method hinges on the use of hierarchical sim2real -- a simulated environment is used to learn low-level goal-reaching skills, which are then used as the action space for a high-level RL controller, also trained in simulation. The full hierarchical policy is then transferred to the real world in a zero-shot fashion. The application of domain randomization during training enables the learned behaviors to generalize to real-world settings, while the use of hierarchy provides a modular paradigm for learning and transferring increasingly complex behaviors. We evaluate our method on a number of real-world tasks, including coordinated object manipulation in a multi-agent setting. See videos at https://sites.google.com/view/manipulation-via-locomotion
DualDICE: Behavior-Agnostic Estimation of Discounted Stationary Distribution Corrections
Jun 10, 2019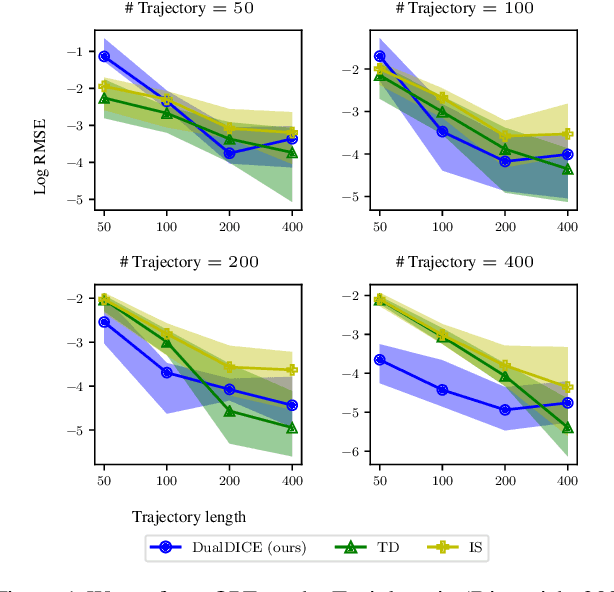
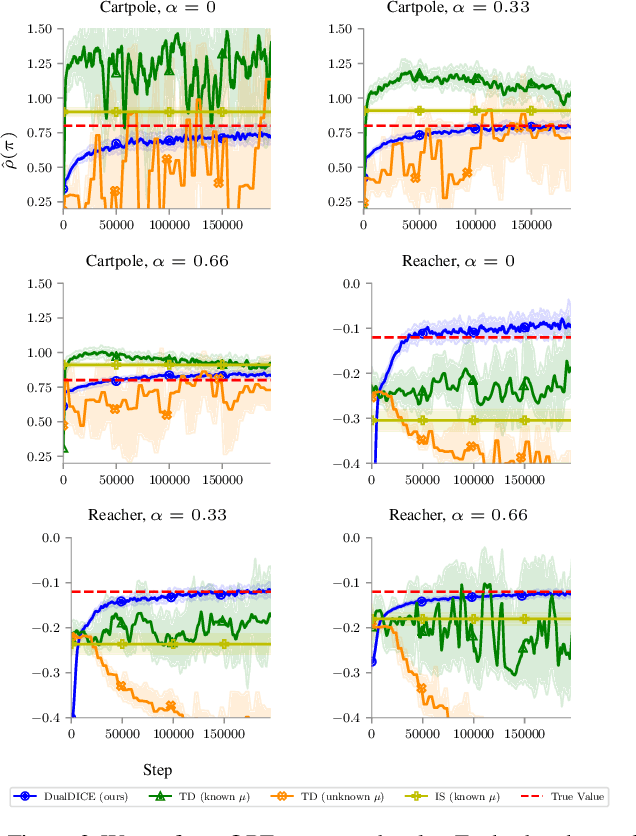
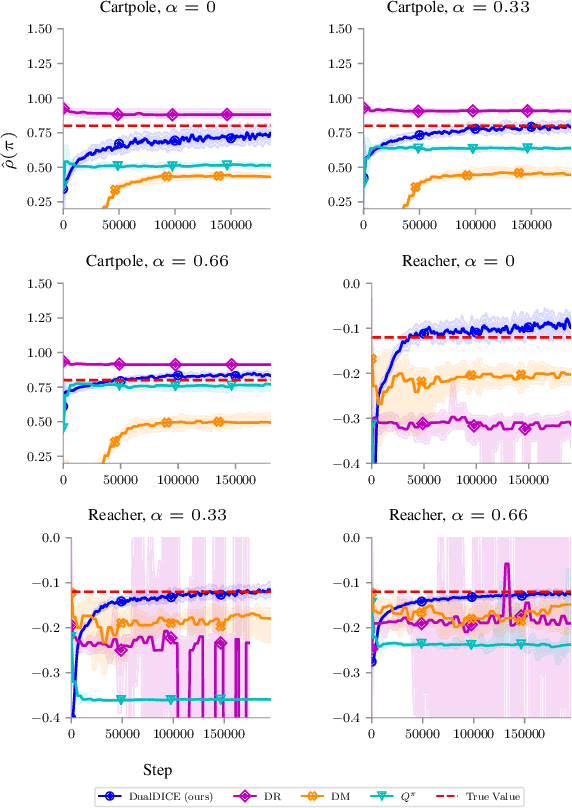
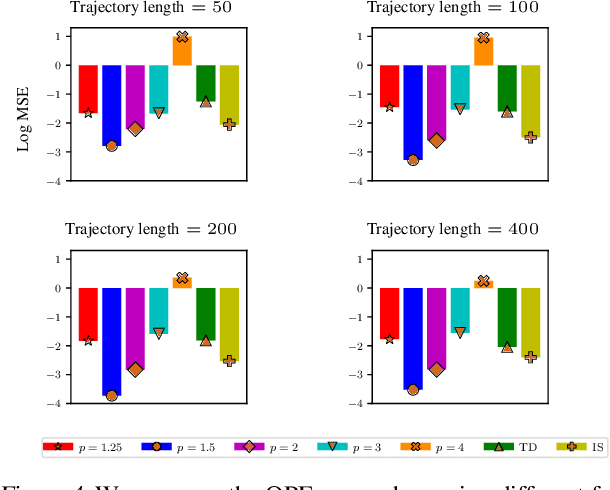
In many real-world reinforcement learning applications, access to the environment is limited to a fixed dataset, instead of direct (online) interaction with the environment. When using this data for either evaluation or training of a new policy, accurate estimates of discounted stationary distribution ratios -- correction terms which quantify the likelihood that the new policy will experience a certain state-action pair normalized by the probability with which the state-action pair appears in the dataset -- can improve accuracy and performance. In this work, we propose an algorithm, DualDICE, for estimating these quantities. In contrast to previous approaches, our algorithm is agnostic to knowledge of the behavior policy (or policies) used to generate the dataset. Furthermore, it eschews any direct use of importance weights, thus avoiding potential optimization instabilities endemic of previous methods. In addition to providing theoretical guarantees, we present an empirical study of our algorithm applied to off-policy policy evaluation and find that our algorithm significantly improves accuracy compared to existing techniques.
DeepMDP: Learning Continuous Latent Space Models for Representation Learning
Jun 06, 2019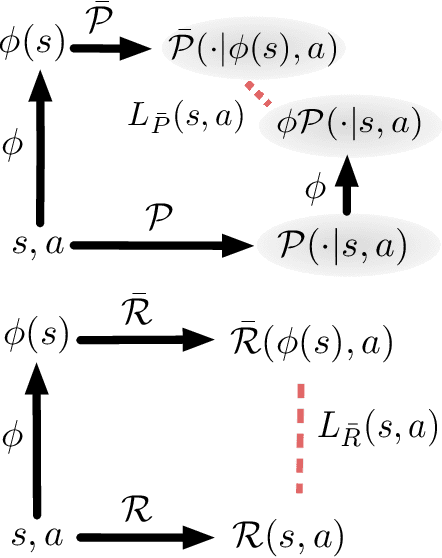


Many reinforcement learning (RL) tasks provide the agent with high-dimensional observations that can be simplified into low-dimensional continuous states. To formalize this process, we introduce the concept of a DeepMDP, a parameterized latent space model that is trained via the minimization of two tractable losses: prediction of rewards and prediction of the distribution over next latent states. We show that the optimization of these objectives guarantees (1) the quality of the latent space as a representation of the state space and (2) the quality of the DeepMDP as a model of the environment. We connect these results to prior work in the bisimulation literature, and explore the use of a variety of metrics. Our theoretical findings are substantiated by the experimental result that a trained DeepMDP recovers the latent structure underlying high-dimensional observations on a synthetic environment. Finally, we show that learning a DeepMDP as an auxiliary task in the Atari 2600 domain leads to large performance improvements over model-free RL.
Lyapunov-based Safe Policy Optimization for Continuous Control
Jan 28, 2019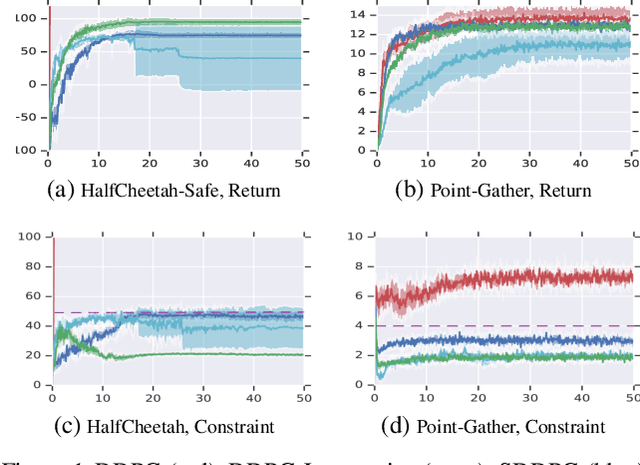
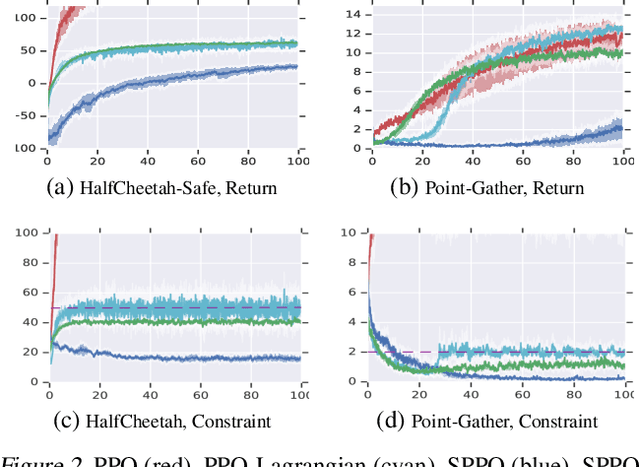
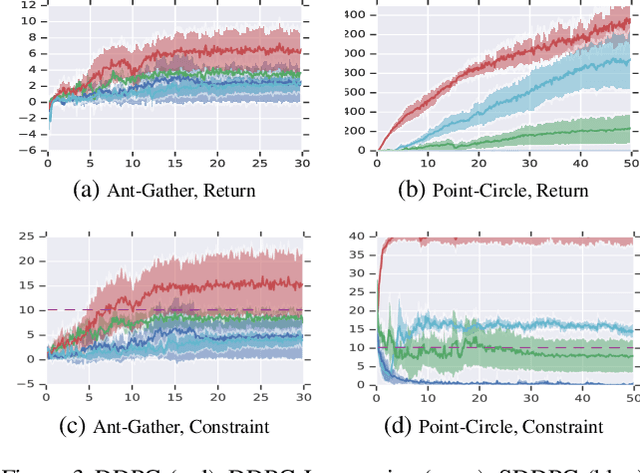
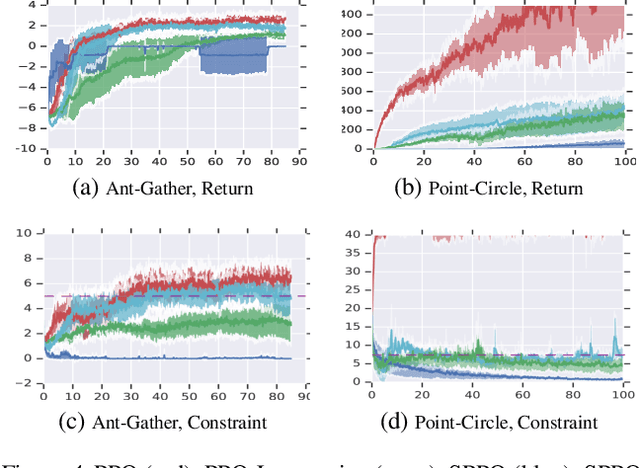
We study continuous action reinforcement learning problems in which it is crucial that the agent interacts with the environment only through {\em safe} policies, i.e.,~policies that do not take the agent to undesirable situations. We formulate these problems as {\em constrained} Markov decision processes (CMDPs) and present safe policy optimization algorithms that are based on a {\em Lyapunov} approach to solve them. Our algorithms can use any standard policy gradient (PG) method, such as deep deterministic policy gradient (DDPG) or proximal policy optimization (PPO), to train a neural network policy, while guaranteeing near-constraint satisfaction for every policy update by projecting either the policy parameter or the action onto the set of feasible solutions induced by the state-dependent linearized Lyapunov constraints. Compared to the existing constrained PG algorithms, ours are more data efficient as they are able to utilize both on-policy and off-policy data. Moreover, our action-projection algorithm often leads to less conservative policy updates and allows for natural integration into an end-to-end PG training pipeline. We evaluate our algorithms and compare them with the state-of-the-art baselines on several simulated (MuJoCo) tasks, as well as a real-world indoor robot navigation problem, demonstrating their effectiveness in terms of balancing performance and constraint satisfaction. Videos of the experiments can be found in the following link: https://drive.google.com/file/d/1pzuzFqWIE710bE2U6DmS59AfRzqK2Kek/view?usp=sharing .
Identifying and Correcting Label Bias in Machine Learning
Jan 15, 2019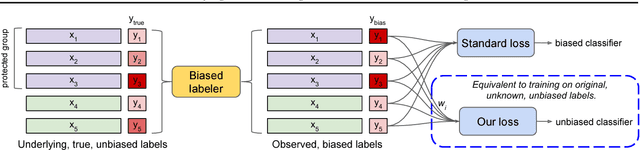
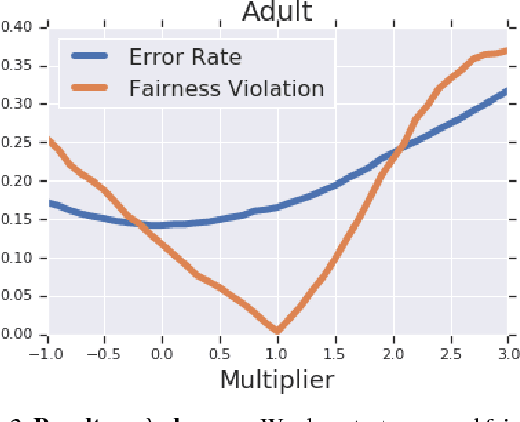
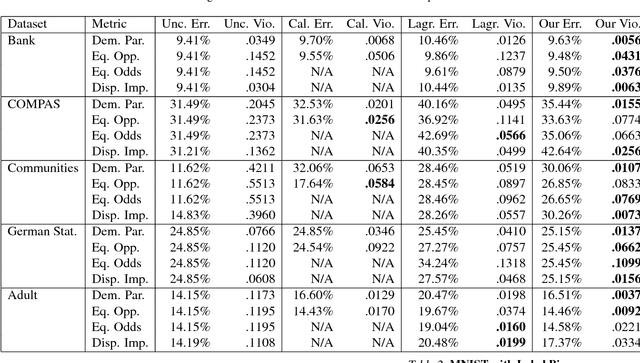
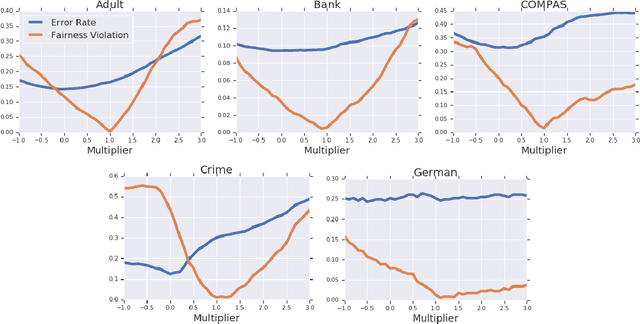
Datasets often contain biases which unfairly disadvantage certain groups, and classifiers trained on such datasets can inherit these biases. In this paper, we provide a mathematical formulation of how this bias can arise. We do so by assuming the existence of underlying, unknown, and unbiased labels which are overwritten by an agent who intends to provide accurate labels but may have biases against certain groups. Despite the fact that we only observe the biased labels, we are able to show that the bias may nevertheless be corrected by re-weighting the data points without changing the labels. We show, with theoretical guarantees, that training on the re-weighted dataset corresponds to training on the unobserved but unbiased labels, thus leading to an unbiased machine learning classifier. Our procedure is fast and robust and can be used with virtually any learning algorithm. We evaluate on a number of standard machine learning fairness datasets and a variety of fairness notions, finding that our method outperforms standard approaches in achieving fair classification.
The Laplacian in RL: Learning Representations with Efficient Approximations
Oct 10, 2018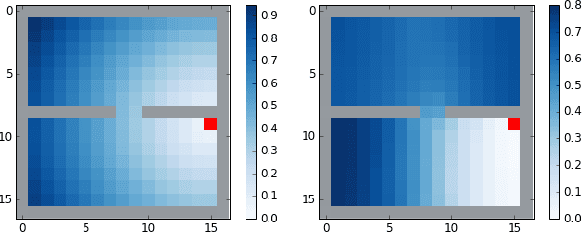
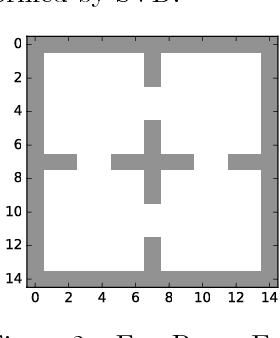
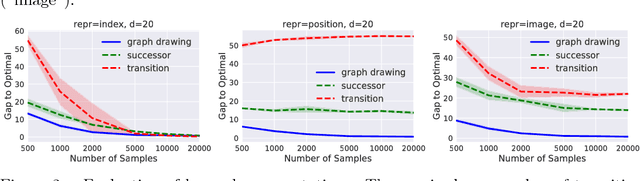
The smallest eigenvectors of the graph Laplacian are well-known to provide a succinct representation of the geometry of a weighted graph. In reinforcement learning (RL), where the weighted graph may be interpreted as the state transition process induced by a behavior policy acting on the environment, approximating the eigenvectors of the Laplacian provides a promising approach to state representation learning. However, existing methods for performing this approximation are ill-suited in general RL settings for two main reasons: First, they are computationally expensive, often requiring operations on large matrices. Second, these methods lack adequate justification beyond simple, tabular, finite-state settings. In this paper, we present a fully general and scalable method for approximating the eigenvectors of the Laplacian in a model-free RL context. We systematically evaluate our approach and empirically show that it generalizes beyond the tabular, finite-state setting. Even in tabular, finite-state settings, its ability to approximate the eigenvectors outperforms previous proposals. Finally, we show the potential benefits of using a Laplacian representation learned using our method in goal-achieving RL tasks, providing evidence that our technique can be used to significantly improve the performance of an RL agent.
Data-Efficient Hierarchical Reinforcement Learning
Oct 05, 2018
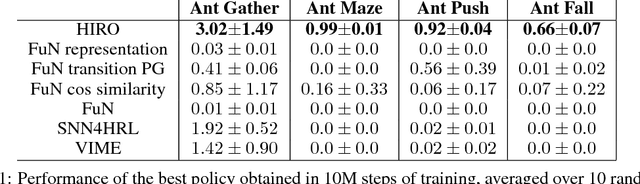
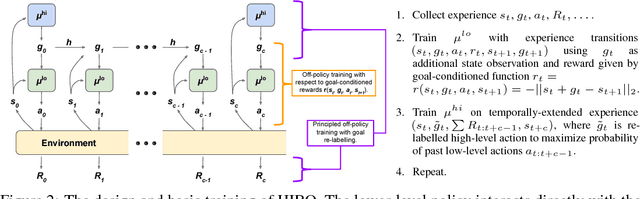
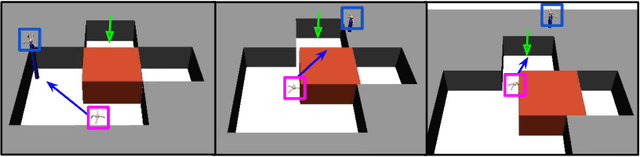
Hierarchical reinforcement learning (HRL) is a promising approach to extend traditional reinforcement learning (RL) methods to solve more complex tasks. Yet, the majority of current HRL methods require careful task-specific design and on-policy training, making them difficult to apply in real-world scenarios. In this paper, we study how we can develop HRL algorithms that are general, in that they do not make onerous additional assumptions beyond standard RL algorithms, and efficient, in the sense that they can be used with modest numbers of interaction samples, making them suitable for real-world problems such as robotic control. For generality, we develop a scheme where lower-level controllers are supervised with goals that are learned and proposed automatically by the higher-level controllers. To address efficiency, we propose to use off-policy experience for both higher and lower-level training. This poses a considerable challenge, since changes to the lower-level behaviors change the action space for the higher-level policy, and we introduce an off-policy correction to remedy this challenge. This allows us to take advantage of recent advances in off-policy model-free RL to learn both higher- and lower-level policies using substantially fewer environment interactions than on-policy algorithms. We term the resulting HRL agent HIRO and find that it is generally applicable and highly sample-efficient. Our experiments show that HIRO can be used to learn highly complex behaviors for simulated robots, such as pushing objects and utilizing them to reach target locations, learning from only a few million samples, equivalent to a few days of real-time interaction. In comparisons with a number of prior HRL methods, we find that our approach substantially outperforms previous state-of-the-art techniques.
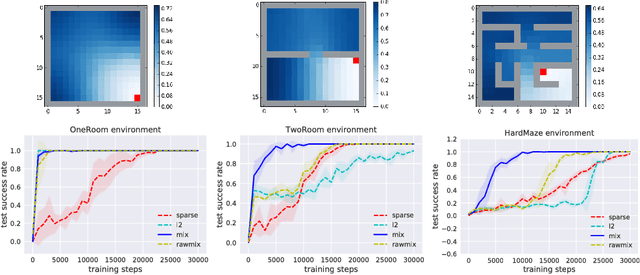
Near-Optimal Representation Learning for Hierarchical Reinforcement Learning
Oct 02, 2018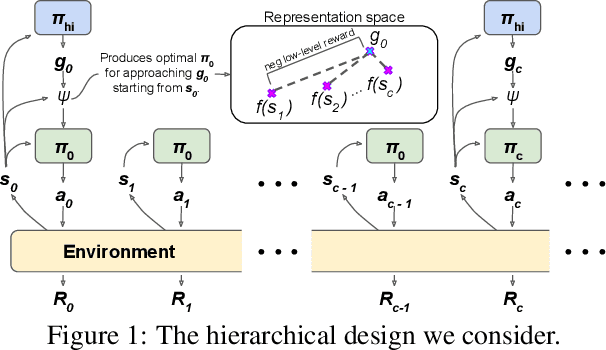
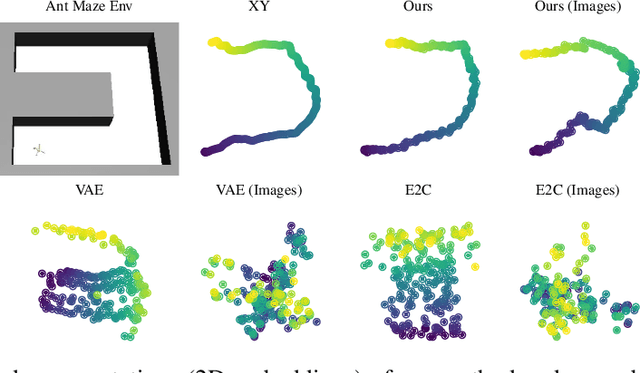
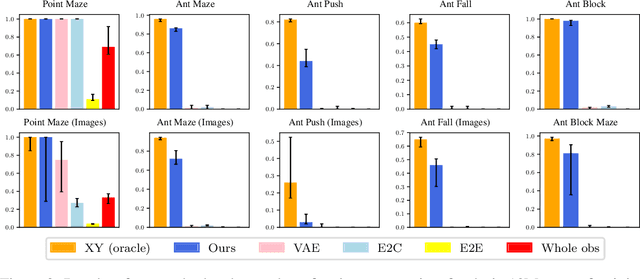
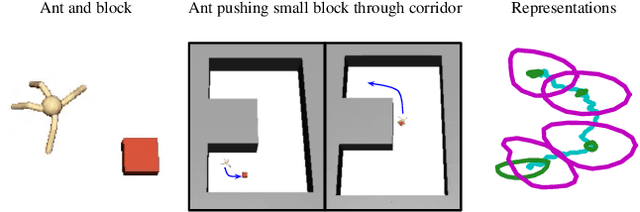
We study the problem of representation learning in goal-conditioned hierarchical reinforcement learning. In such hierarchical structures, a higher-level controller solves tasks by iteratively communicating goals which a lower-level policy is trained to reach. Accordingly, the choice of representation -- the mapping of observation space to goal space -- is crucial. To study this problem, we develop a notion of sub-optimality of a representation, defined in terms of expected reward of the optimal hierarchical policy using this representation. We derive expressions which bound the sub-optimality and show how these expressions can be translated to representation learning objectives which may be optimized in practice. Results on a number of difficult continuous-control tasks show that our approach to representation learning yields qualitatively better representations as well as quantitatively better hierarchical policies, compared to existing methods (see videos at https://sites.google.com/view/representation-hrl).
Smoothed Action Value Functions for Learning Gaussian Policies
Jul 25, 2018
State-action value functions (i.e., Q-values) are ubiquitous in reinforcement learning (RL), giving rise to popular algorithms such as SARSA and Q-learning. We propose a new notion of action value defined by a Gaussian smoothed version of the expected Q-value. We show that such smoothed Q-values still satisfy a Bellman equation, making them learnable from experience sampled from an environment. Moreover, the gradients of expected reward with respect to the mean and covariance of a parameterized Gaussian policy can be recovered from the gradient and Hessian of the smoothed Q-value function. Based on these relationships, we develop new algorithms for training a Gaussian policy directly from a learned smoothed Q-value approximator. The approach is additionally amenable to proximal optimization by augmenting the objective with a penalty on KL-divergence from a previous policy. We find that the ability to learn both a mean and covariance during training leads to significantly improved results on standard continuous control benchmarks.
A Lyapunov-based Approach to Safe Reinforcement Learning
May 20, 2018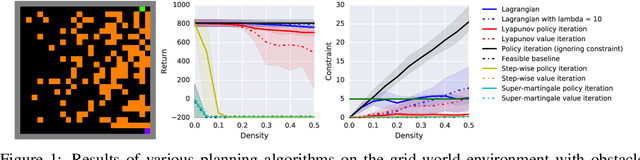
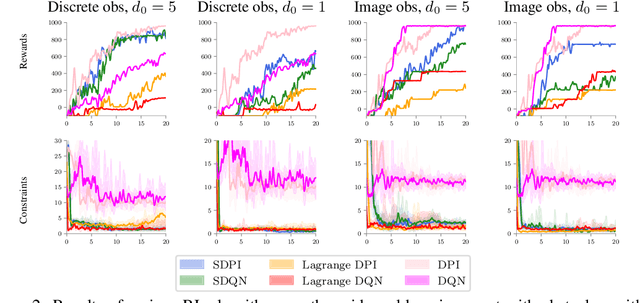
In many real-world reinforcement learning (RL) problems, besides optimizing the main objective function, an agent must concurrently avoid violating a number of constraints. In particular, besides optimizing performance it is crucial to guarantee the safety of an agent during training as well as deployment (e.g. a robot should avoid taking actions - exploratory or not - which irrevocably harm its hardware). To incorporate safety in RL, we derive algorithms under the framework of constrained Markov decision problems (CMDPs), an extension of the standard Markov decision problems (MDPs) augmented with constraints on expected cumulative costs. Our approach hinges on a novel \emph{Lyapunov} method. We define and present a method for constructing Lyapunov functions, which provide an effective way to guarantee the global safety of a behavior policy during training via a set of local, linear constraints. Leveraging these theoretical underpinnings, we show how to use the Lyapunov approach to systematically transform dynamic programming (DP) and RL algorithms into their safe counterparts. To illustrate their effectiveness, we evaluate these algorithms in several CMDP planning and decision-making tasks on a safety benchmark domain. Our results show that our proposed method significantly outperforms existing baselines in balancing constraint satisfaction and performance.