 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoxingGym: Benchmarking Progress in Automated Experimental Design and Model Discovery
Jan 02, 2025



Understanding the world and explaining it with scientific theories is a central aspiration of artificial intelligence research. Proposing theories, designing experiments to test them, and then revising them based on data are fundamental to scientific discovery. Despite the significant promise of LLM-based scientific agents, no benchmarks systematically test LLM's ability to propose scientific models, collect experimental data, and revise them in light of new data. We introduce BoxingGym, a benchmark with 10 environments for systematically evaluating both experimental design (e.g. collecting data to test a scientific theory) and model discovery (e.g. proposing and revising scientific theories). To enable tractable and quantitative evaluation, we implement each environment as a generative probabilistic model with which a scientific agent can run interactive experiments. These probabilistic models are drawn from various real-world scientific domains ranging from psychology to ecology. To quantitatively evaluate a scientific agent's ability to collect informative experimental data, we compute the expected information gain (EIG), an information-theoretic quantity which measures how much an experiment reduces uncertainty about the parameters of a generative model. A good scientific theory is a concise and predictive explanation. Therefore, to quantitatively evaluate model discovery, we ask a scientific agent to explain their model and then assess whether this explanation enables another scientific agent to make reliable predictions about this environment. In addition to this explanation-based evaluation, we compute standard model evaluation metrics such as prediction errors. We find that current LLMs, such as GPT-4o, struggle with both experimental design and model discovery. We find that augmenting the LLM-based agent with an explicit statistical model does not reliably improve these results.
CriticAL: Critic Automation with Language Models
Nov 10, 2024Understanding the world through models is a fundamental goal of scientific research. While large language model (LLM) based approaches show promise in automating scientific discovery, they often overlook the importance of criticizing scientific models. Criticizing models deepens scientific understanding and drives the development of more accurate models. Automating model criticism is difficult because it traditionally requires a human expert to define how to compare a model with data and evaluate if the discrepancies are significant--both rely heavily on understanding the modeling assumptions and domain. Although LLM-based critic approaches are appealing, they introduce new challenges: LLMs might hallucinate the critiques themselves. Motivated by this, we introduce CriticAL (Critic Automation with Language Models). CriticAL uses LLMs to generate summary statistics that capture discrepancies between model predictions and data, and applies hypothesis tests to evaluate their significance. We can view CriticAL as a verifier that validates models and their critiques by embedding them in a hypothesis testing framework. In experiments, we evaluate CriticAL across key quantitative and qualitative dimensions. In settings where we synthesize discrepancies between models and datasets, CriticAL reliably generates correct critiques without hallucinating incorrect ones. We show that both human and LLM judges consistently prefer CriticAL's critiques over alternative approaches in terms of transparency and actionability. Finally, we show that CriticAL's critiques enable an LLM scientist to improve upon human-designed models on real-world datasets.
What Should Embeddings Embed? Autoregressive Models Represent Latent Generating Distributions
Jun 06, 2024



Autoregressive language models have demonstrated a remarkable ability to extract latent structure from text. The embeddings from large language models have been shown to capture aspects of the syntax and semantics of language. But what {\em should} embeddings represent? We connect the autoregressive prediction objective to the idea of constructing predictive sufficient statistics to summarize the information contained in a sequence of observations, and use this connection to identify three settings where the optimal content of embeddings can be identified: independent identically distributed data, where the embedding should capture the sufficient statistics of the data; latent state models, where the embedding should encode the posterior distribution over states given the data; and discrete hypothesis spaces, where the embedding should reflect the posterior distribution over hypotheses given the data. We then conduct empirical probing studies to show that transformers encode these three kinds of latent generating distributions, and that they perform well in out-of-distribution cases and without token memorization in these settings.
Automated Statistical Model Discovery with Language Models
Feb 27, 2024



Statistical model discovery involves a challenging search over a vast space of models subject to domain-specific modeling constraints. Efficiently searching over this space requires human expertise in modeling and the problem domain. Motivated by the domain knowledge and programming capabilities of large language models (LMs), we introduce a method for language model driven automated statistical model discovery. We cast our automated procedure within the framework of Box's Loop: the LM iterates between proposing statistical models represented as probabilistic programs, acting as a modeler, and critiquing those models, acting as a domain expert. By leveraging LMs, we do not have to define a domain-specific language of models or design a handcrafted search procedure, key restrictions of previous systems. We evaluate our method in three common settings in probabilistic modeling: searching within a restricted space of models, searching over an open-ended space, and improving classic models under natural language constraints (e.g., this model should be interpretable to an ecologist). Our method matches the performance of previous systems, identifies models on par with human expert designed models, and extends classic models in interpretable ways. Our results highlight the promise of LM driven model discovery.
Gaussian process surrogate models for neural networks
Aug 11, 2022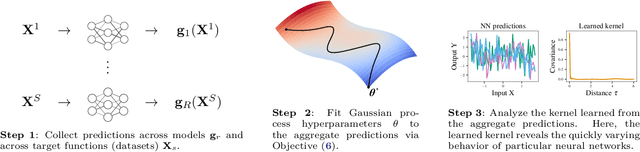
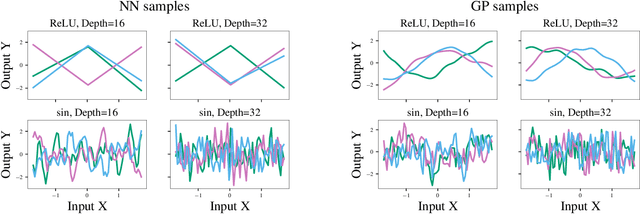
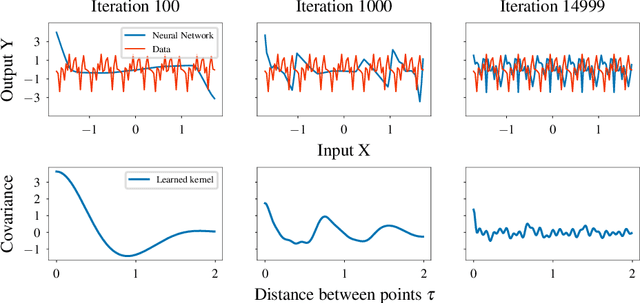
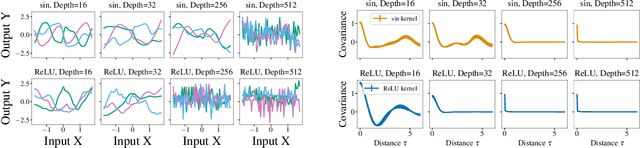
The lack of insight into deep learning systems hinders their systematic design. In science and engineering, modeling is a methodology used to understand complex systems whose internal processes are opaque. Modeling replaces a complex system with a simpler surrogate that is more amenable to interpretation. Drawing inspiration from this, we construct a class of surrogate models for neural networks using Gaussian processes. Rather than deriving the kernels for certain limiting cases of neural networks, we learn the kernels of the Gaussian process empirically from the naturalistic behavior of neural networks. We first evaluate our approach with two case studies inspired by previous theoretical studies of neural network behavior in which we capture neural network preferences for learning low frequencies and identify pathological behavior in deep neural networks. In two further practical case studies, we use the learned kernel to predict the generalization properties of neural networks.