 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
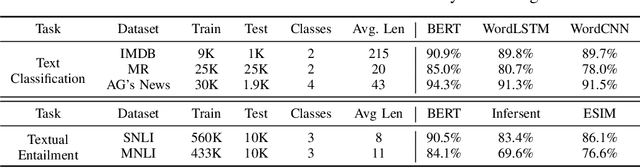
Add to EdgeOn-Demand Resource Management for 6G Wireless Networks Using Knowledge-Assisted Dynamic Neural Networks
Aug 02, 2022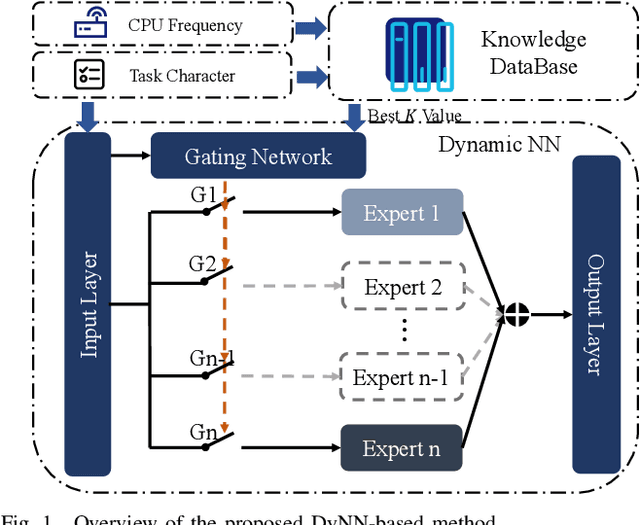
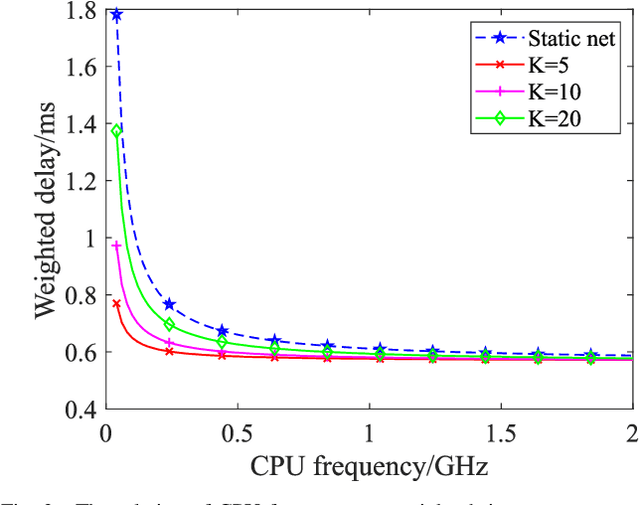
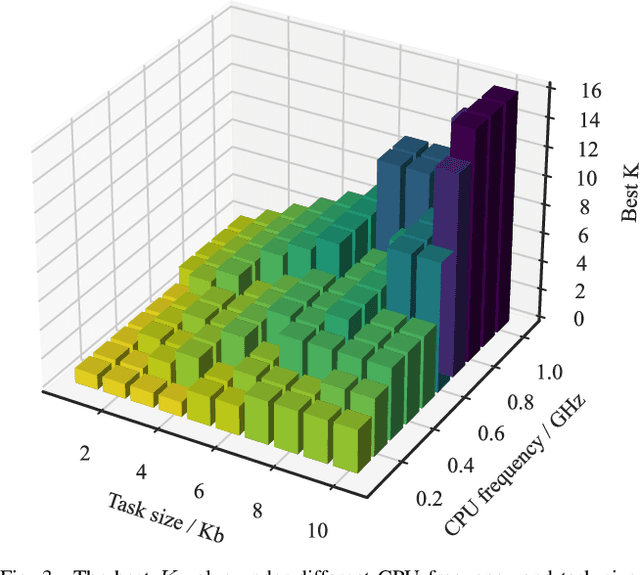
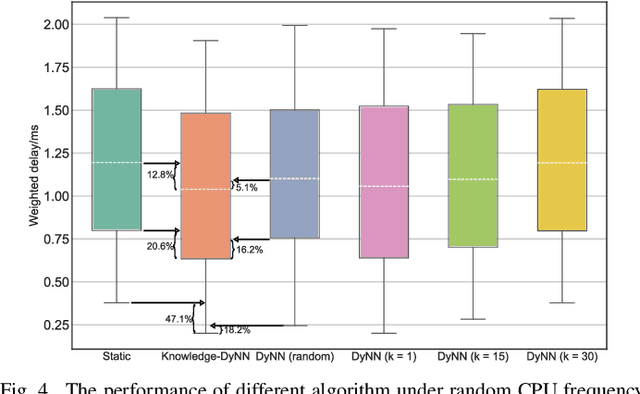
On-demand service provisioning is a critical yet challenging issue in 6G wireless communication networks, since emerging services have significantly diverse requirements and the network resources become increasingly heterogeneous and dynamic. In this paper, we study the on-demand wireless resource orchestration problem with the focus on the computing delay in orchestration decision-making process. Specifically, we take the decision-making delay into the optimization problem. Then, a dynamic neural network (DyNN)-based method is proposed, where the model complexity can be adjusted according to the service requirements. We further build a knowledge base representing the relationship among the service requirements, available computing resources, and the resource allocation performance. By exploiting the knowledge, the width of DyNN can be selected in a timely manner, further improving the performance of orchestration. Simulation results show that the proposed scheme significantly outperforms the traditional static neural network, and also shows sufficient flexibility in on-demand service provisioning.
A Novel Data Segmentation Method for Data-driven Phase Identification
Nov 20, 2021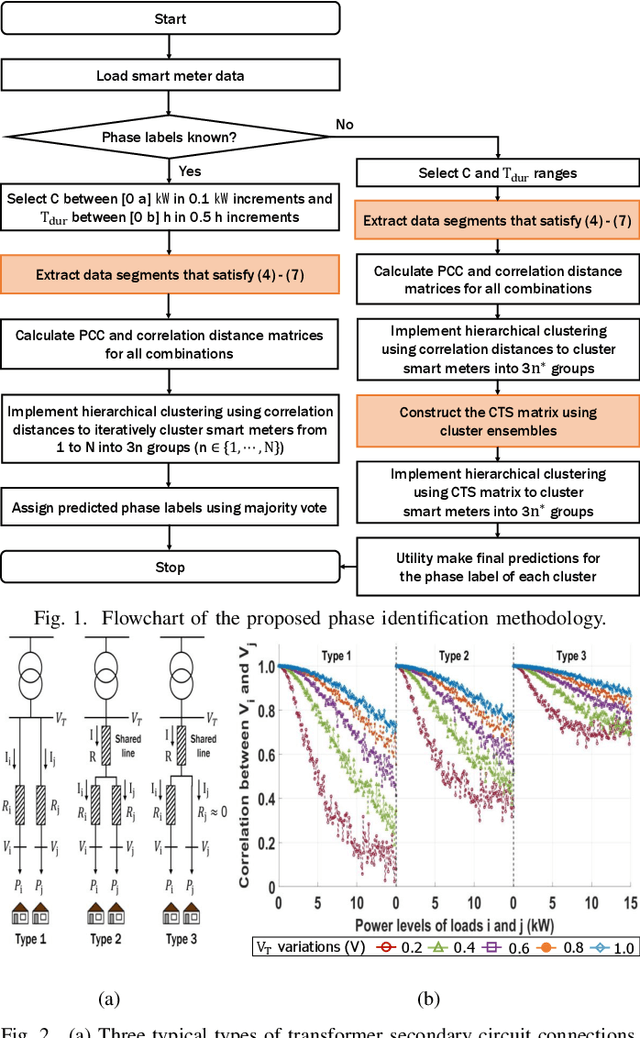
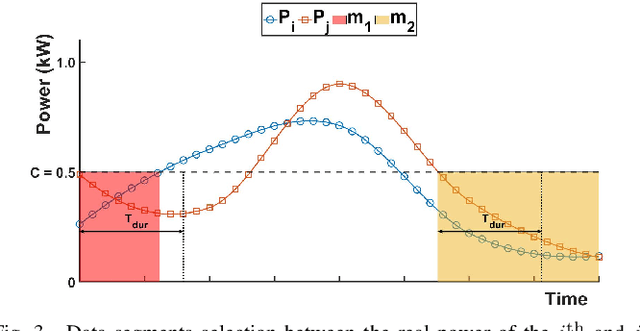
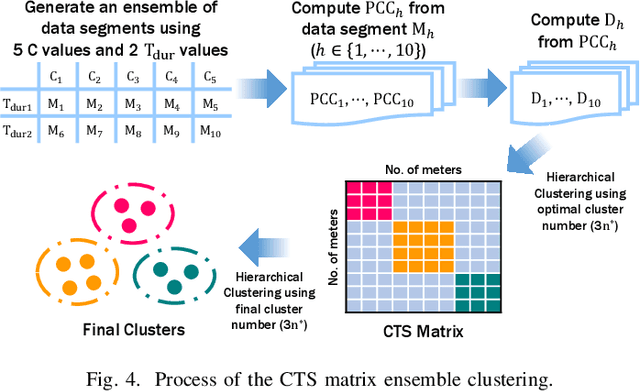
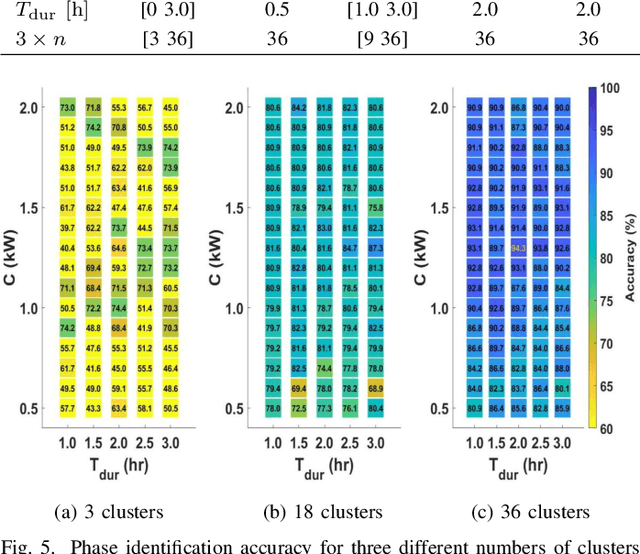
This paper presents a smart meter phase identification algorithm for two cases: meter-phase-label-known and meter-phase-label-unknown. To improve the identification accuracy, a data segmentation method is proposed to exclude data segments that are collected when the voltage correlation between smart meters on the same phase are weakened. Then, using the selected data segments, a hierarchical clustering method is used to calculate the correlation distances and cluster the smart meters. If the phase labels are unknown, a Connected-Triple-based Similarity (CTS) method is adapted to further improve the phase identification accuracy of the ensemble clustering method. The methods are developed and tested on both synthetic and real feeder data sets. Simulation results show that the proposed phase identification algorithm outperforms the state-of-the-art methods in both accuracy and robustness.
A TCN-based Spatial-Temporal PV Forecasting Framework with Automated Detector Network Selection
Nov 16, 2021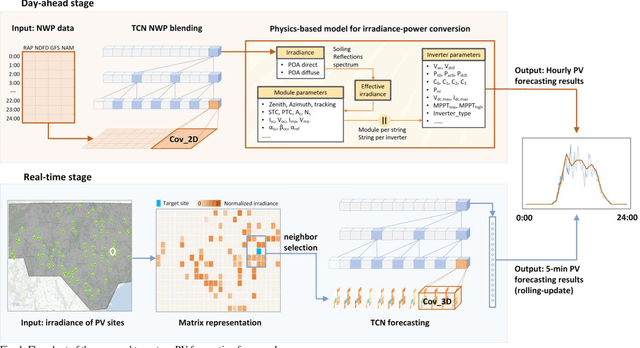
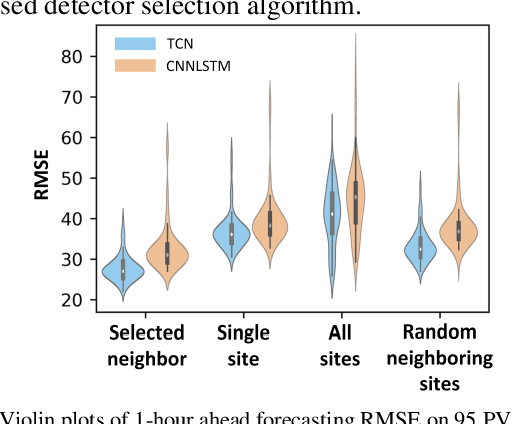
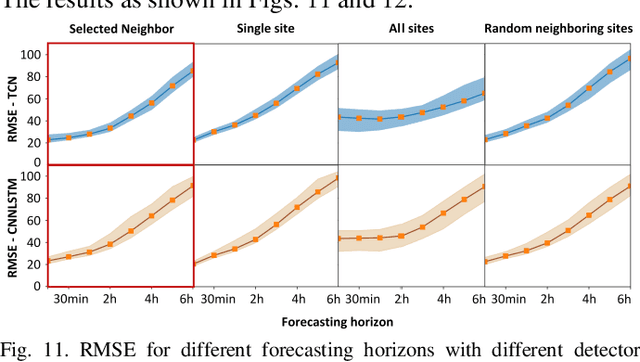
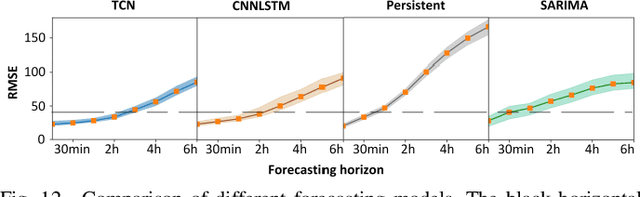
This paper proposes a two-stage PV forecasting framework for MW-level PV farms based on Temporal Convolutional Network (TCN). In the day-ahead stage, inverter-level physics-based model is built to convert Numerical Weather Prediction (NWP) to hourly power forecasts. TCN works as the NWP blender to merge different NWP sources to improve the forecasting accuracy. In the real-time stage, TCN can leverage the spatial-temporal correlations between the target site and its neighbors to achieve intra-hour power forecasts. A scenario-based correlation analysis method is proposed to automatically identify the most contributive neighbors. Simulation results based on 95 PV farms in North Carolina demonstrate the accuracy and efficiency of the proposed method.
HydraText: Multi-objective Optimization for Adversarial Textual Attack
Nov 02, 2021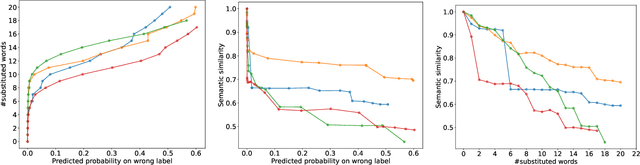
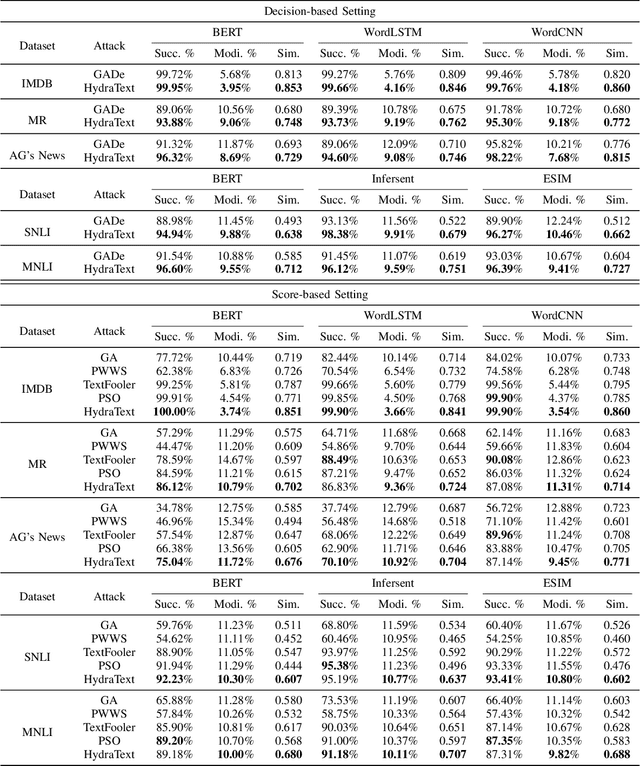

The field of adversarial textual attack has significantly grown over the last years, where the commonly considered objective is to craft adversarial examples that can successfully fool the target models. However, the imperceptibility of attacks, which is also an essential objective, is often left out by previous studies. In this work, we advocate considering both objectives at the same time, and propose a novel multi-optimization approach (dubbed HydraText) with provable performance guarantee to achieve successful attacks with high imperceptibility. We demonstrate the efficacy of HydraText through extensive experiments under both score-based and decision-based settings, involving five modern NLP models across five benchmark datasets. In comparison to existing state-of-the-art attacks, HydraText consistently achieves simultaneously higher success rates, lower modification rates, and higher semantic similarity to the original texts. A human evaluation study shows that the adversarial examples crafted by HydraText maintain validity and naturality well. Finally, these examples also exhibit good transferability and can bring notable robustness improvement to the target models by adversarial training.
Efficient Combinatorial Optimization for Word-level Adversarial Textual Attack
Sep 06, 2021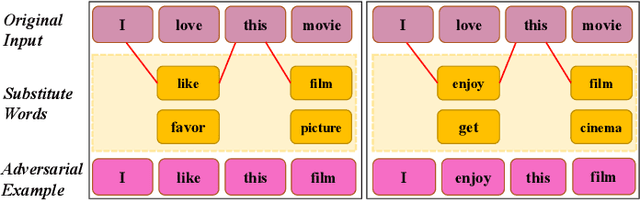
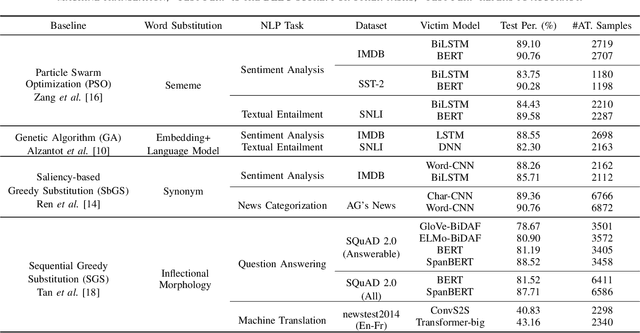

Over the past few years, various word-level textual attack approaches have been proposed to reveal the vulnerability of deep neural networks used in natural language processing. Typically, these approaches involve an important optimization step to determine which substitute to be used for each word in the original input. However, current research on this step is still rather limited, from the perspectives of both problem-understanding and problem-solving. In this paper, we address these issues by uncovering the theoretical properties of the problem and proposing an efficient local search algorithm (LS) to solve it. We establish the first provable approximation guarantee on solving the problem in general cases. Notably, for adversarial textual attack, it is even better than the previous bound which only holds in special case. Extensive experiments involving five NLP tasks, six datasets and eleven NLP models show that LS can largely reduce the number of queries usually by an order of magnitude to achieve high attack success rates. Further experiments show that the adversarial examples crafted by LS usually have higher quality, exhibit better transferability, and can bring more robustness improvement to victim models by adversarial training.
ProfileSR-GAN: A GAN based Super-Resolution Method for Generating High-Resolution Load Profiles
Jul 18, 2021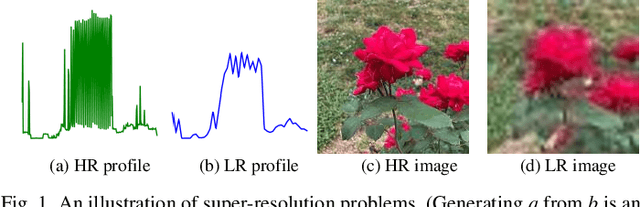
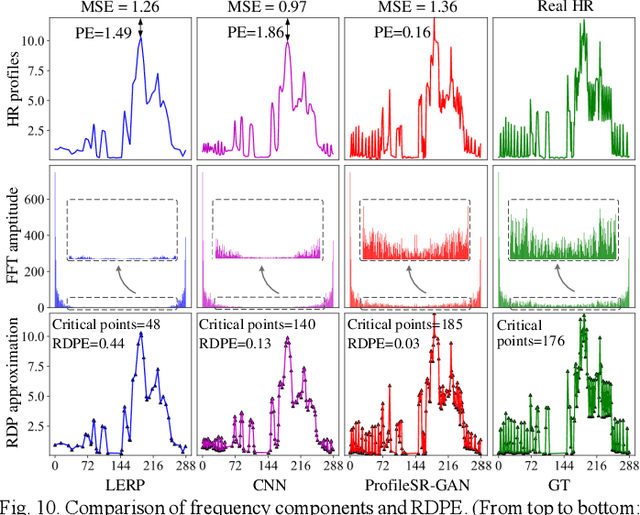
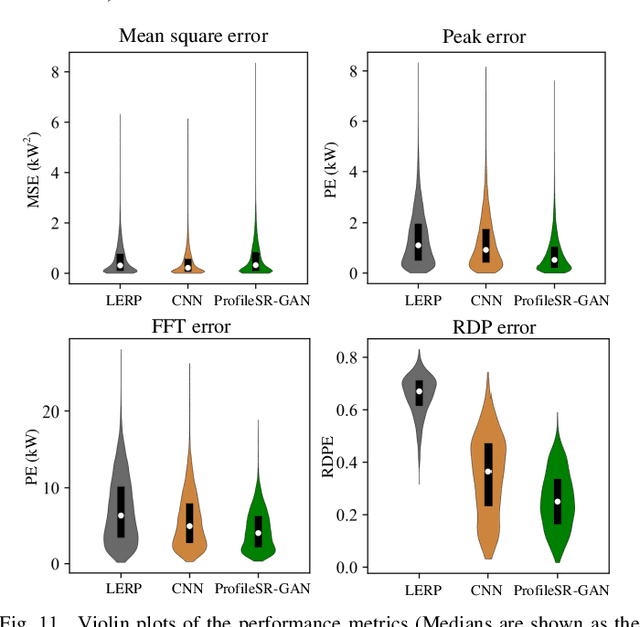
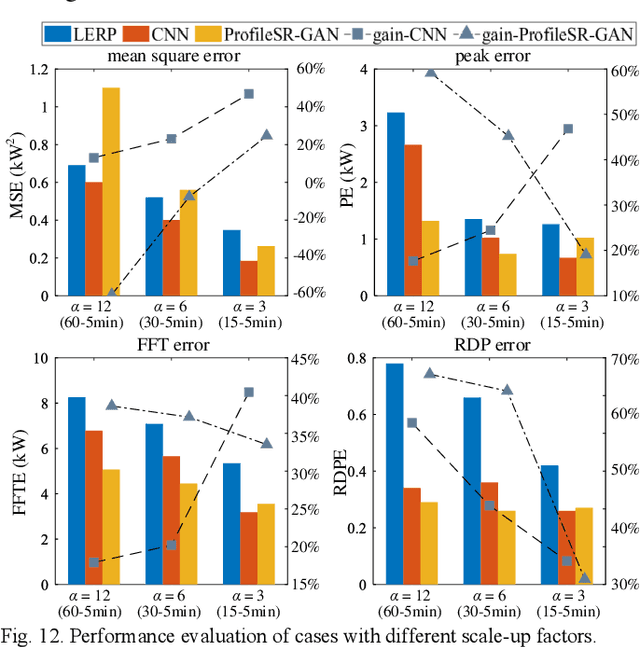
It is a common practice for utilities to down-sample smart meter measurements from high resolution (e.g. 1-min or 1-sec) to low resolution (e.g. 15-, 30- or 60-min) to lower the data transmission and storage cost. However, down-sampling can remove high-frequency components from time-series load profiles, making them unsuitable for in-depth studies such as quasi-static power flow analysis or non-intrusive load monitoring (NILM). Thus, in this paper, we propose ProfileSR-GAN: a Generative Adversarial Network (GAN) based load profile super-resolution (LPSR) framework for restoring high-frequency components lost through the smoothing effect of the down-sampling process. The LPSR problem is formulated as a Maximum-a-Prior problem. When training the ProfileSR-GAN generator network, to make the generated profiles more realistic, we introduce two new shape-related losses in addition to conventionally used content loss: adversarial loss and feature-matching loss. Moreover, a new set of shape-based evaluation metrics are proposed to evaluate the realisticness of the generated profiles. Simulation results show that ProfileSR-GAN outperforms Mean-Square Loss based methods in all shape-based metrics. The successful application in NILM further demonstrates that ProfileSR-GAN is effective in recovering high-resolution realistic waveforms.
ACDER: Augmented Curiosity-Driven Experience Replay
Nov 16, 2020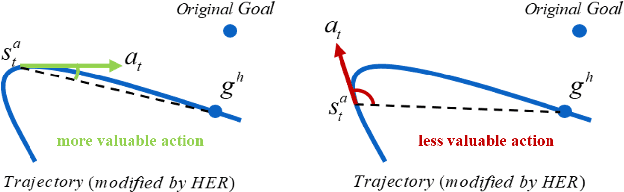
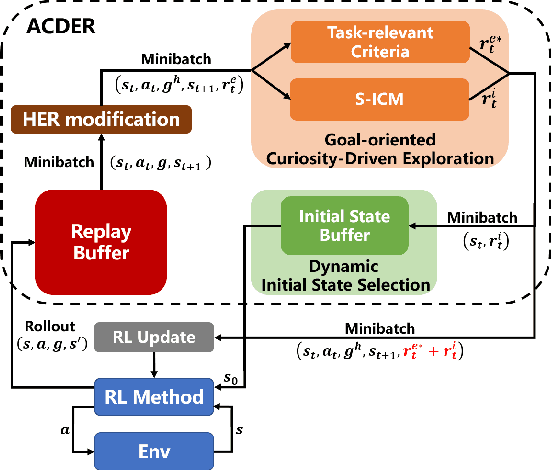


Exploration in environments with sparse feedback remains a challenging research problem in reinforcement learning (RL). When the RL agent explores the environment randomly, it results in low exploration efficiency, especially in robotic manipulation tasks with high dimensional continuous state and action space. In this paper, we propose a novel method, called Augmented Curiosity-Driven Experience Replay (ACDER), which leverages (i) a new goal-oriented curiosity-driven exploration to encourage the agent to pursue novel and task-relevant states more purposefully and (ii) the dynamic initial states selection as an automatic exploratory curriculum to further improve the sample-efficiency. Our approach complements Hindsight Experience Replay (HER) by introducing a new way to pursue valuable states. Experiments conducted on four challenging robotic manipulation tasks with binary rewards, including Reach, Push, Pick&Place and Multi-step Push. The empirical results show that our proposed method significantly outperforms existing methods in the first three basic tasks and also achieves satisfactory performance in multi-step robotic task learning.
A Meta-learning based Distribution System Load Forecasting Model Selection Framework
Sep 25, 2020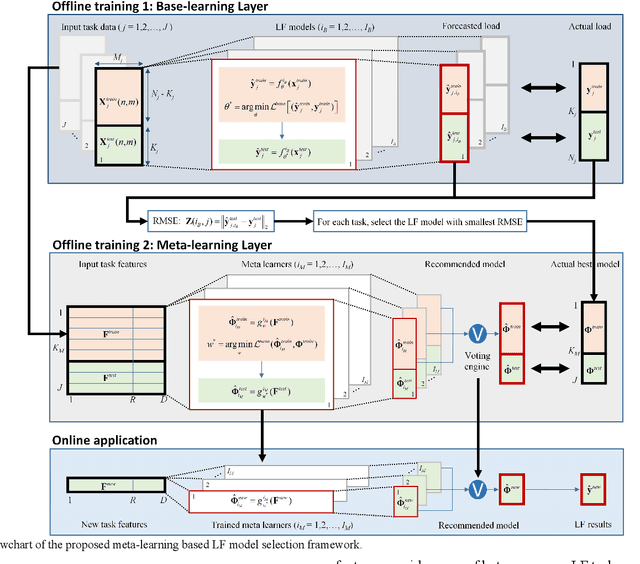
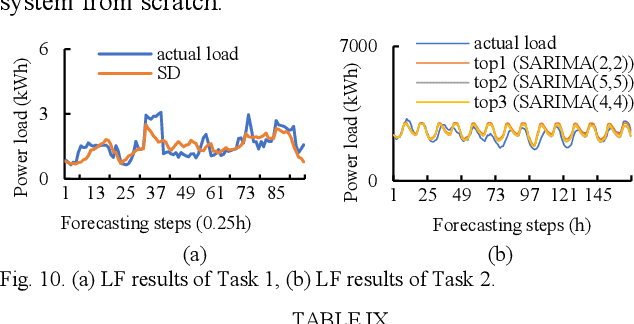
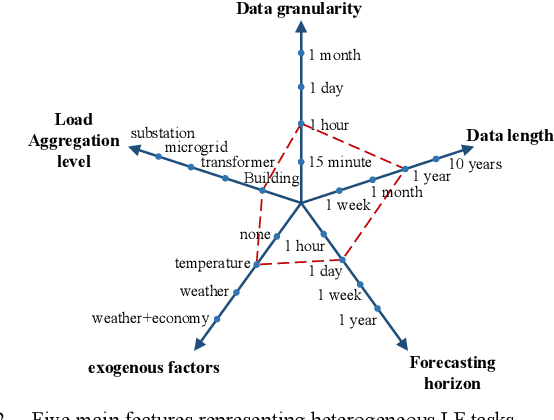
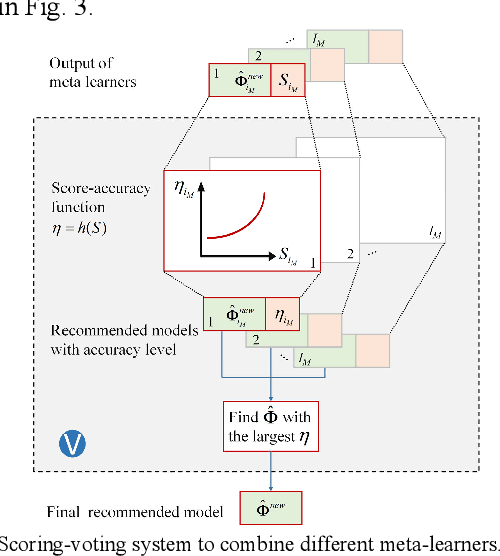
This paper presents a meta-learning based, automatic distribution system load forecasting model selection framework. The framework includes the following processes: feature extraction, candidate model labeling, offline training, and online model recommendation. Using user load forecasting needs as input features, multiple meta-learners are used to rank the available load forecast models based on their forecasting accuracy. Then, a scoring-voting mechanism weights recommendations from each meta-leaner to make the final recommendations. Heterogeneous load forecasting tasks with different temporal and technical requirements at different load aggregation levels are set up to train, validate, and test the performance of the proposed framework. Simulation results demonstrate that the performance of the meta-learning based approach is satisfactory in both seen and unseen forecasting tasks.
Synthetic-to-Real Unsupervised Domain Adaptation for Scene Text Detection in the Wild
Sep 03, 2020
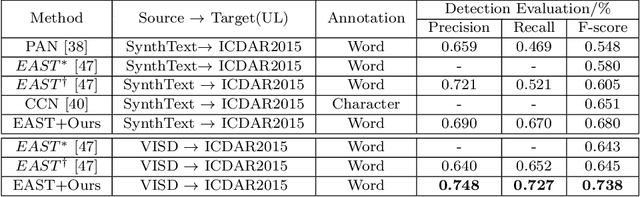
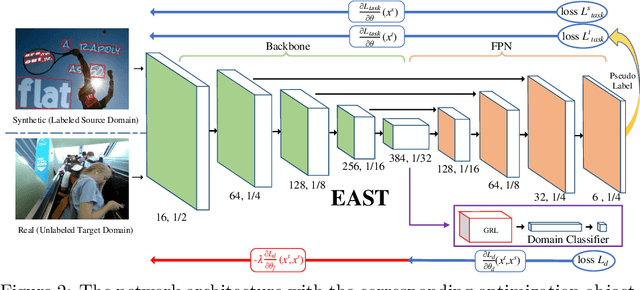
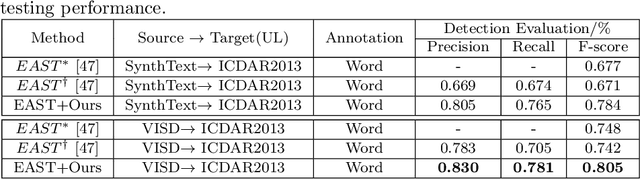
Deep learning-based scene text detection can achieve preferable performance, powered with sufficient labeled training data. However, manual labeling is time consuming and laborious. At the extreme, the corresponding annotated data are unavailable. Exploiting synthetic data is a very promising solution except for domain distribution mismatches between synthetic datasets and real datasets. To address the severe domain distribution mismatch, we propose a synthetic-to-real domain adaptation method for scene text detection, which transfers knowledge from synthetic data (source domain) to real data (target domain). In this paper, a text self-training (TST) method and adversarial text instance alignment (ATA) for domain adaptive scene text detection are introduced. ATA helps the network learn domain-invariant features by training a domain classifier in an adversarial manner. TST diminishes the adverse effects of false positives~(FPs) and false negatives~(FNs) from inaccurate pseudo-labels. Two components have positive effects on improving the performance of scene text detectors when adapting from synthetic-to-real scenes. We evaluate the proposed method by transferring from SynthText, VISD to ICDAR2015, ICDAR2013. The results demonstrate the effectiveness of the proposed method with up to 10% improvement, which has important exploration significance for domain adaptive scene text detection. Code is available at https://github.com/weijiawu/SyntoReal_STD
PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks
Apr 16, 2020
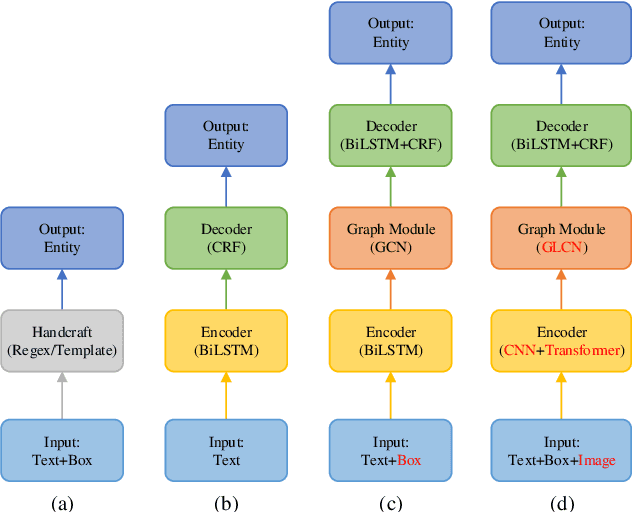
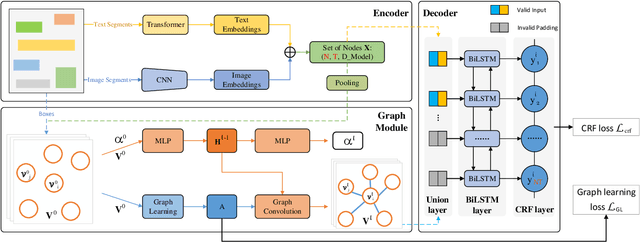
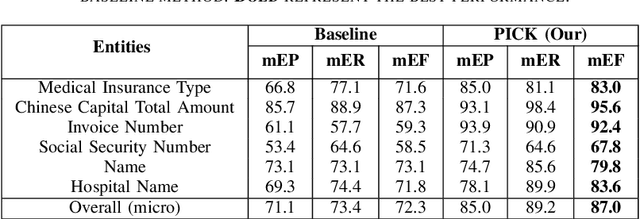
Computer vision with state-of-the-art deep learning models has achieved huge success in the field of Optical Character Recognition (OCR) including text detection and recognition tasks recently. However, Key Information Extraction (KIE) from documents as the downstream task of OCR, having a large number of use scenarios in real-world, remains a challenge because documents not only have textual features extracting from OCR systems but also have semantic visual features that are not fully exploited and play a critical role in KIE. Too little work has been devoted to efficiently make full use of both textual and visual features of the documents. In this paper, we introduce PICK, a framework that is effective and robust in handling complex documents layout for KIE by combining graph learning with graph convolution operation, yielding a richer semantic representation containing the textual and visual features and global layout without ambiguity. Extensive experiments on real-world datasets have been conducted to show that our method outperforms baselines methods by significant margins.