 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Method for Face Anti-Spoofing with Semi-Supervised Learning
Jun 13, 2022
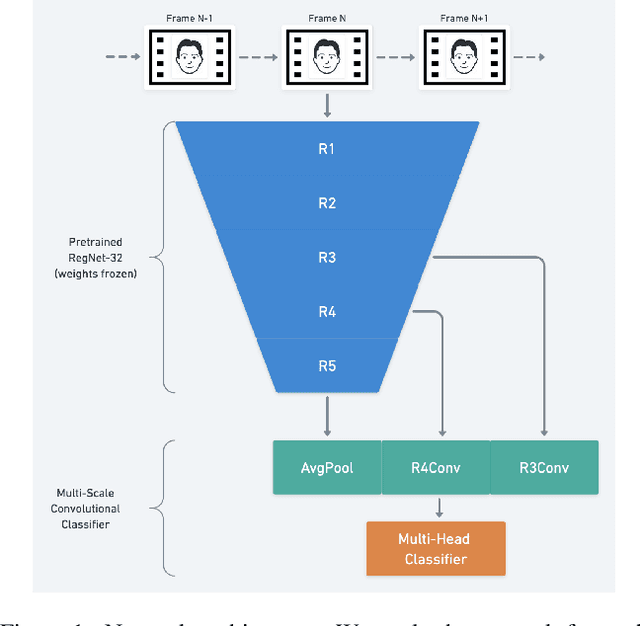


Face anti-spoofing has drawn a lot of attention due to the high security requirements in biometric authentication systems. Bringing face biometric to commercial hardware became mostly dependent on developing reliable methods for detecting fake login sessions without specialized sensors. Current CNN-based method perform well on the domains they were trained for, but often show poor generalization on previously unseen datasets. In this paper we describe a method for utilizing unsupervised pretraining for improving performance across multiple datasets without any adaptation, introduce the Entry Antispoofing Dataset for supervised fine-tuning, and propose a multi-class auxiliary classification layer for augmenting the binary classification task of detecting spoofing attempts with explicit interpretable signals. We demonstrate the efficiency of our model by achieving state-of-the-art results on cross-dataset testing on MSU-MFSD, Replay-Attack, and OULU-NPU datasets.
Reduced Focal Loss: 1st Place Solution to xView object detection in Satellite Imagery
Mar 04, 2019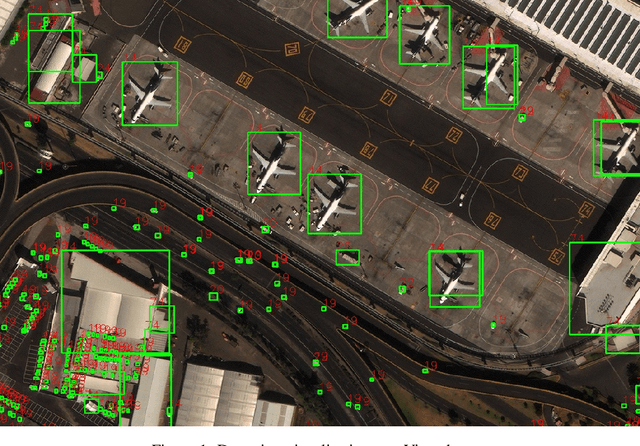
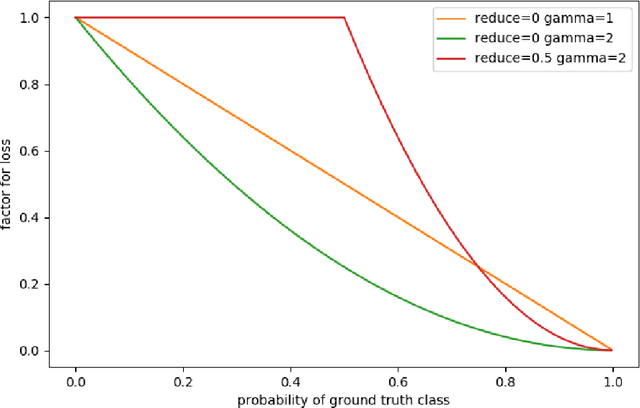
This paper describes our approach to the DIUx xView 2018 Detection Challenge [1]. This challenge focuses on a new satellite imagery dataset. The dataset contains 60 object classes that are highly imbalanced. Due to the imbalanced nature of the dataset, the training process becomes significantly more challenging. To address this problem, we introduce a novel Reduced Focal Loss function, which brought us 1st place in the DIUx xView 2018 Detection Challenge.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019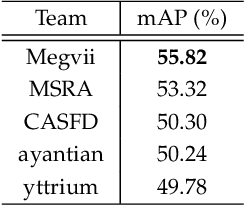

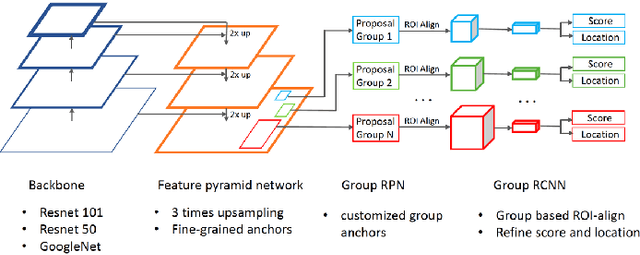
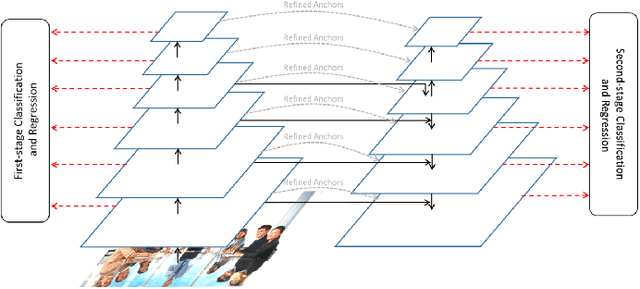
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
Systematic evaluation of CNN advances on the ImageNet
Jun 13, 2016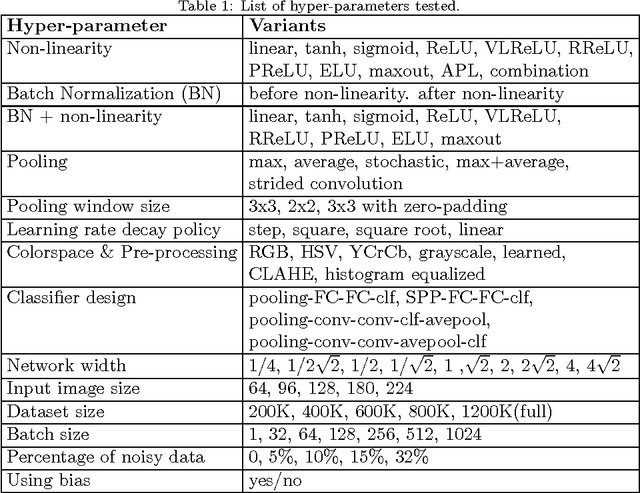
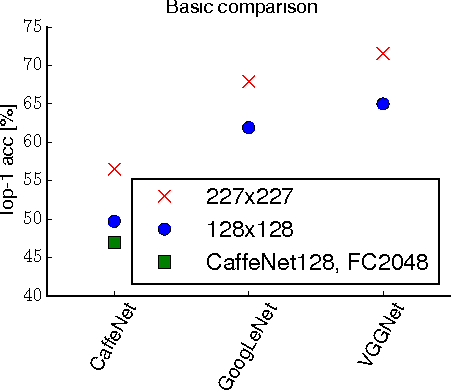
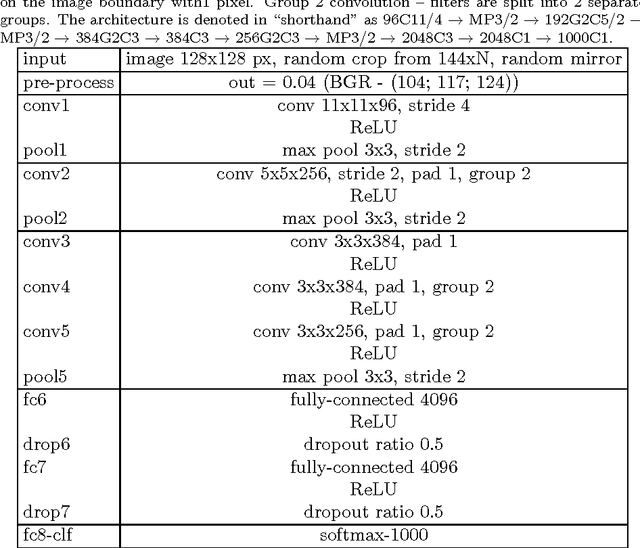
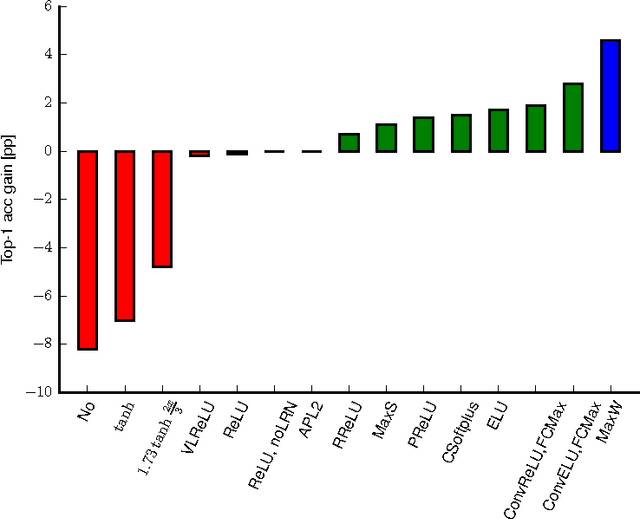
The paper systematically studies the impact of a range of recent advances in CNN architectures and learning methods on the object categorization (ILSVRC) problem. The evalution tests the influence of the following choices of the architecture: non-linearity (ReLU, ELU, maxout, compatibility with batch normalization), pooling variants (stochastic, max, average, mixed), network width, classifier design (convolutional, fully-connected, SPP), image pre-processing, and of learning parameters: learning rate, batch size, cleanliness of the data, etc. The performance gains of the proposed modifications are first tested individually and then in combination. The sum of individual gains is bigger than the observed improvement when all modifications are introduced, but the "deficit" is small suggesting independence of their benefits. We show that the use of 128x128 pixel images is sufficient to make qualitative conclusions about optimal network structure that hold for the full size Caffe and VGG nets. The results are obtained an order of magnitude faster than with the standard 224 pixel images.