 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
Riemannian Batch Normalization: A Gyro Approach
Sep 08, 2025Normalization layers are crucial for deep learning, but their Euclidean formulations are inadequate for data on manifolds. On the other hand, many Riemannian manifolds in machine learning admit gyro-structures, enabling principled extensions of Euclidean neural networks to non-Euclidean domains. Inspired by this, we introduce GyroBN, a principled Riemannian batch normalization framework for gyrogroups. We establish two necessary conditions, namely \emph{pseudo-reduction} and \emph{gyroisometric gyrations}, that guarantee GyroBN with theoretical control over sample statistics, and show that these conditions hold for all known gyrogroups in machine learning. Our framework also incorporates several existing Riemannian normalization methods as special cases. We further instantiate GyroBN on seven representative geometries, including the Grassmannian, five constant curvature spaces, and the correlation manifold, and derive novel gyro and Riemannian structures to enable these instantiations. Experiments across these geometries demonstrate the effectiveness of GyroBN. The code is available at https://github.com/GitZH-Chen/GyroBN.git.
H$_{2}$OT: Hierarchical Hourglass Tokenizer for Efficient Video Pose Transformers
Sep 08, 2025



Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a hierarchical plug-and-play pruning-and-recovering framework, called Hierarchical Hourglass Tokenizer (H$_{2}$OT), for efficient transformer-based 3D human pose estimation from videos. H$_{2}$OT begins with progressively pruning pose tokens of redundant frames and ends with recovering full-length sequences, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. It works with two key modules, namely, a Token Pruning Module (TPM) and a Token Recovering Module (TRM). TPM dynamically selects a few representative tokens to eliminate the redundancy of video frames, while TRM restores the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Our method is general-purpose: it can be easily incorporated into common VPT models on both seq2seq and seq2frame pipelines while effectively accommodating different token pruning and recovery strategies. In addition, our H$_{2}$OT reveals that maintaining the full pose sequence is unnecessary, and a few pose tokens of representative frames can achieve both high efficiency and estimation accuracy. Extensive experiments on multiple benchmark datasets demonstrate both the effectiveness and efficiency of the proposed method. Code and models are available at https://github.com/NationalGAILab/HoT.
Organ-Agents: Virtual Human Physiology Simulator via LLMs
Aug 20, 2025Recent advances in large language models (LLMs) have enabled new possibilities in simulating complex physiological systems. We introduce Organ-Agents, a multi-agent framework that simulates human physiology via LLM-driven agents. Each Simulator models a specific system (e.g., cardiovascular, renal, immune). Training consists of supervised fine-tuning on system-specific time-series data, followed by reinforcement-guided coordination using dynamic reference selection and error correction. We curated data from 7,134 sepsis patients and 7,895 controls, generating high-resolution trajectories across 9 systems and 125 variables. Organ-Agents achieved high simulation accuracy on 4,509 held-out patients, with per-system MSEs <0.16 and robustness across SOFA-based severity strata. External validation on 22,689 ICU patients from two hospitals showed moderate degradation under distribution shifts with stable simulation. Organ-Agents faithfully reproduces critical multi-system events (e.g., hypotension, hyperlactatemia, hypoxemia) with coherent timing and phase progression. Evaluation by 15 critical care physicians confirmed realism and physiological plausibility (mean Likert ratings 3.9 and 3.7). Organ-Agents also enables counterfactual simulations under alternative sepsis treatment strategies, generating trajectories and APACHE II scores aligned with matched real-world patients. In downstream early warning tasks, classifiers trained on synthetic data showed minimal AUROC drops (<0.04), indicating preserved decision-relevant patterns. These results position Organ-Agents as a credible, interpretable, and generalizable digital twin for precision diagnosis, treatment simulation, and hypothesis testing in critical care.
Hierarchical Visual Prompt Learning for Continual Video Instance Segmentation
Aug 12, 2025
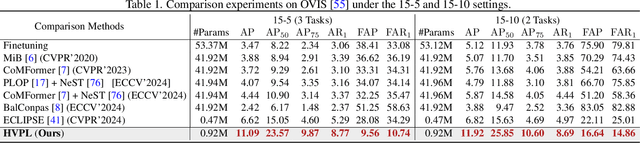


Video instance segmentation (VIS) has gained significant attention for its capability in tracking and segmenting object instances across video frames. However, most of the existing VIS approaches unrealistically assume that the categories of object instances remain fixed over time. Moreover, they experience catastrophic forgetting of old classes when required to continuously learn object instances belonging to new categories. To resolve these challenges, we develop a novel Hierarchical Visual Prompt Learning (HVPL) model that overcomes catastrophic forgetting of previous categories from both frame-level and video-level perspectives. Specifically, to mitigate forgetting at the frame level, we devise a task-specific frame prompt and an orthogonal gradient correction (OGC) module. The OGC module helps the frame prompt encode task-specific global instance information for new classes in each individual frame by projecting its gradients onto the orthogonal feature space of old classes. Furthermore, to address forgetting at the video level, we design a task-specific video prompt and a video context decoder. This decoder first embeds structural inter-class relationships across frames into the frame prompt features, and then propagates task-specific global video contexts from the frame prompt features to the video prompt. Through rigorous comparisons, our HVPL model proves to be more effective than baseline approaches. The code is available at https://github.com/JiahuaDong/HVPL.
Masked Clustering Prediction for Unsupervised Point Cloud Pre-training
Aug 12, 2025



Vision transformers (ViTs) have recently been widely applied to 3D point cloud understanding, with masked autoencoding as the predominant pre-training paradigm. However, the challenge of learning dense and informative semantic features from point clouds via standard ViTs remains underexplored. We propose MaskClu, a novel unsupervised pre-training method for ViTs on 3D point clouds that integrates masked point modeling with clustering-based learning. MaskClu is designed to reconstruct both cluster assignments and cluster centers from masked point clouds, thus encouraging the model to capture dense semantic information. Additionally, we introduce a global contrastive learning mechanism that enhances instance-level feature learning by contrasting different masked views of the same point cloud. By jointly optimizing these complementary objectives, i.e., dense semantic reconstruction, and instance-level contrastive learning. MaskClu enables ViTs to learn richer and more semantically meaningful representations from 3D point clouds. We validate the effectiveness of our method via multiple 3D tasks, including part segmentation, semantic segmentation, object detection, and classification, where MaskClu sets new competitive results. The code and models will be released at:https://github.com/Amazingren/maskclu.
Spatial-Temporal Graph Mamba for Music-Guided Dance Video Synthesis
Jul 09, 2025



We propose a novel spatial-temporal graph Mamba (STG-Mamba) for the music-guided dance video synthesis task, i.e., to translate the input music to a dance video. STG-Mamba consists of two translation mappings: music-to-skeleton translation and skeleton-to-video translation. In the music-to-skeleton translation, we introduce a novel spatial-temporal graph Mamba (STGM) block to effectively construct skeleton sequences from the input music, capturing dependencies between joints in both the spatial and temporal dimensions. For the skeleton-to-video translation, we propose a novel self-supervised regularization network to translate the generated skeletons, along with a conditional image, into a dance video. Lastly, we collect a new skeleton-to-video translation dataset from the Internet, containing 54,944 video clips. Extensive experiments demonstrate that STG-Mamba achieves significantly better results than existing methods.
Orthogonal Projection Subspace to Aggregate Online Prior-knowledge for Continual Test-time Adaptation
Jun 23, 2025


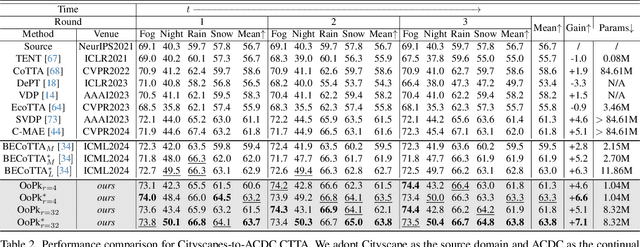
Continual Test Time Adaptation (CTTA) is a task that requires a source pre-trained model to continually adapt to new scenarios with changing target distributions. Existing CTTA methods primarily focus on mitigating the challenges of catastrophic forgetting and error accumulation. Though there have been emerging methods based on forgetting adaptation with parameter-efficient fine-tuning, they still struggle to balance competitive performance and efficient model adaptation, particularly in complex tasks like semantic segmentation. In this paper, to tackle the above issues, we propose a novel pipeline, Orthogonal Projection Subspace to aggregate online Prior-knowledge, dubbed OoPk. Specifically, we first project a tuning subspace orthogonally which allows the model to adapt to new domains while preserving the knowledge integrity of the pre-trained source model to alleviate catastrophic forgetting. Then, we elaborate an online prior-knowledge aggregation strategy that employs an aggressive yet efficient image masking strategy to mimic potential target dynamism, enhancing the student model's domain adaptability. This further gradually ameliorates the teacher model's knowledge, ensuring high-quality pseudo labels and reducing error accumulation. We demonstrate our method with extensive experiments that surpass previous CTTA methods and achieve competitive performances across various continual TTA benchmarks in semantic segmentation tasks.
SceneSplat++: A Large Dataset and Comprehensive Benchmark for Language Gaussian Splatting
Jun 10, 20253D Gaussian Splatting (3DGS) serves as a highly performant and efficient encoding of scene geometry, appearance, and semantics. Moreover, grounding language in 3D scenes has proven to be an effective strategy for 3D scene understanding. Current Language Gaussian Splatting line of work fall into three main groups: (i) per-scene optimization-based, (ii) per-scene optimization-free, and (iii) generalizable approach. However, most of them are evaluated only on rendered 2D views of a handful of scenes and viewpoints close to the training views, limiting ability and insight into holistic 3D understanding. To address this gap, we propose the first large-scale benchmark that systematically assesses these three groups of methods directly in 3D space, evaluating on 1060 scenes across three indoor datasets and one outdoor dataset. Benchmark results demonstrate a clear advantage of the generalizable paradigm, particularly in relaxing the scene-specific limitation, enabling fast feed-forward inference on novel scenes, and achieving superior segmentation performance. We further introduce GaussianWorld-49K a carefully curated 3DGS dataset comprising around 49K diverse indoor and outdoor scenes obtained from multiple sources, with which we demonstrate the generalizable approach could harness strong data priors. Our codes, benchmark, and datasets will be made public to accelerate research in generalizable 3DGS scene understanding.
When Semantics Mislead Vision: Mitigating Large Multimodal Models Hallucinations in Scene Text Spotting and Understanding
Jun 05, 2025



Large Multimodal Models (LMMs) have achieved impressive progress in visual perception and reasoning. However, when confronted with visually ambiguous or non-semantic scene text, they often struggle to accurately spot and understand the content, frequently generating semantically plausible yet visually incorrect answers, which we refer to as semantic hallucination. In this work, we investigate the underlying causes of semantic hallucination and identify a key finding: Transformer layers in LLM with stronger attention focus on scene text regions are less prone to producing semantic hallucinations. Thus, we propose a training-free semantic hallucination mitigation framework comprising two key components: (1) ZoomText, a coarse-to-fine strategy that identifies potential text regions without external detectors; and (2) Grounded Layer Correction, which adaptively leverages the internal representations from layers less prone to hallucination to guide decoding, correcting hallucinated outputs for non-semantic samples while preserving the semantics of meaningful ones. To enable rigorous evaluation, we introduce TextHalu-Bench, a benchmark of over 1,730 samples spanning both semantic and non-semantic cases, with manually curated question-answer pairs designed to probe model hallucinations. Extensive experiments demonstrate that our method not only effectively mitigates semantic hallucination but also achieves strong performance on public benchmarks for scene text spotting and understanding.