 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Aware Learning for Camouflaged Object Detection
Jun 22, 2021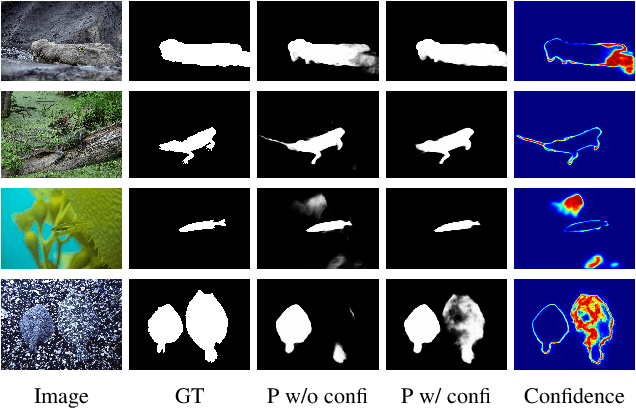
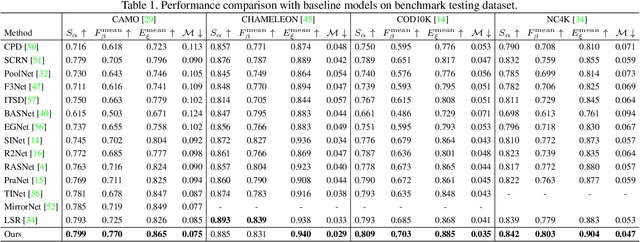
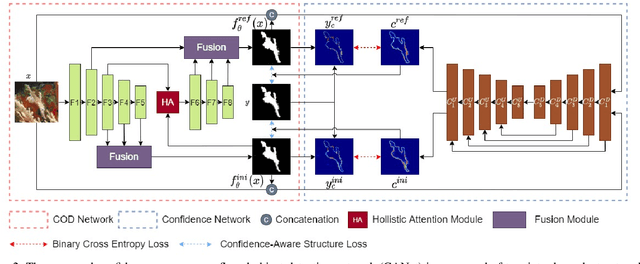
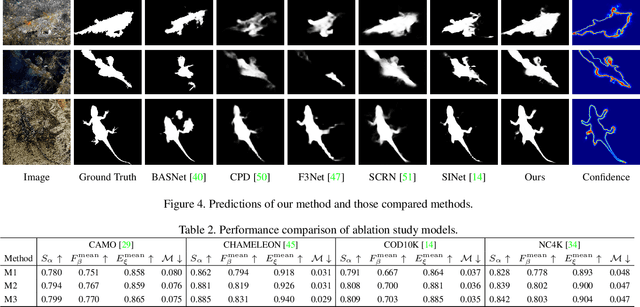
Confidence-aware learning is proven as an effective solution to prevent networks becoming overconfident. We present a confidence-aware camouflaged object detection framework using dynamic supervision to produce both accurate camouflage map and meaningful "confidence" representing model awareness about the current prediction. A camouflaged object detection network is designed to produce our camouflage prediction. Then, we concatenate it with the input image and feed it to the confidence estimation network to produce an one channel confidence map.We generate dynamic supervision for the confidence estimation network, representing the agreement of camouflage prediction with the ground truth camouflage map. With the produced confidence map, we introduce confidence-aware learning with the confidence map as guidance to pay more attention to the hard/low-confidence pixels in the loss function. We claim that, once trained, our confidence estimation network can evaluate pixel-wise accuracy of the prediction without relying on the ground truth camouflage map. Extensive results on four camouflaged object detection testing datasets illustrate the superior performance of the proposed model in explaining the camouflage prediction.
Transformer Transforms Salient Object Detection and Camouflaged Object Detection
Apr 20, 2021
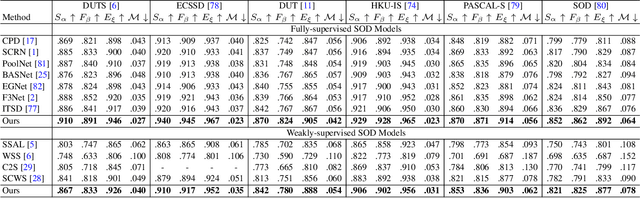
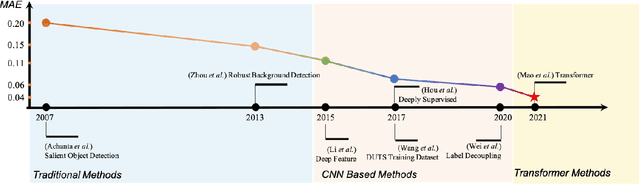
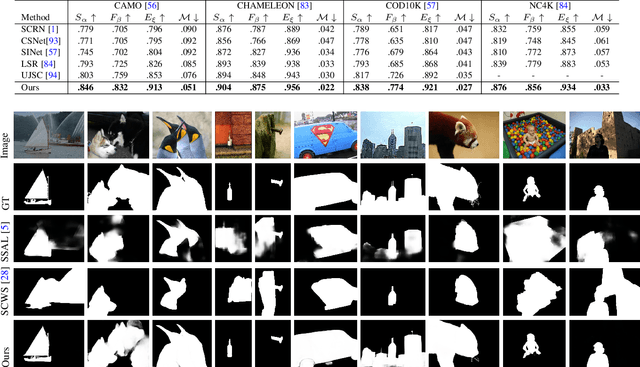
The transformer networks, which originate from machine translation, are particularly good at modeling long-range dependencies within a long sequence. Currently, the transformer networks are making revolutionary progress in various vision tasks ranging from high-level classification tasks to low-level dense prediction tasks. In this paper, we conduct research on applying the transformer networks for salient object detection (SOD). Specifically, we adopt the dense transformer backbone for fully supervised RGB image based SOD, RGB-D image pair based SOD, and weakly supervised SOD via scribble supervision. As an extension, we also apply our fully supervised model to the task of camouflaged object detection (COD) for camouflaged object segmentation. For the fully supervised models, we define the dense transformer backbone as feature encoder, and design a very simple decoder to produce a one channel saliency map (or camouflage map for the COD task). For the weakly supervised model, as there exists no structure information in the scribble annotation, we first adopt the recent proposed Gated-CRF loss to effectively model the pair-wise relationships for accurate model prediction. Then, we introduce self-supervised learning strategy to push the model to produce scale-invariant predictions, which is proven effective for weakly supervised models and models trained on small training datasets. Extensive experimental results on various SOD and COD tasks (fully supervised RGB image based SOD, fully supervised RGB-D image pair based SOD, weakly supervised SOD via scribble supervision, and fully supervised RGB image based COD) illustrate that transformer networks can transform salient object detection and camouflaged object detection, leading to new benchmarks for each related task.
Learning structure-aware semantic segmentation with image-level supervision
Apr 15, 2021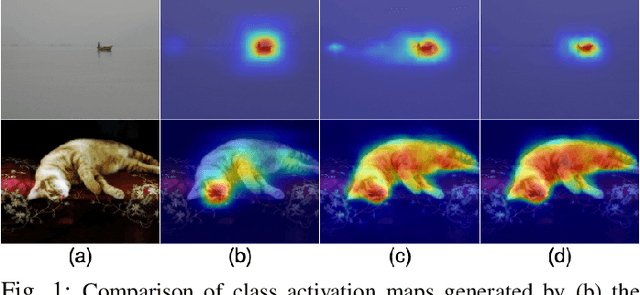
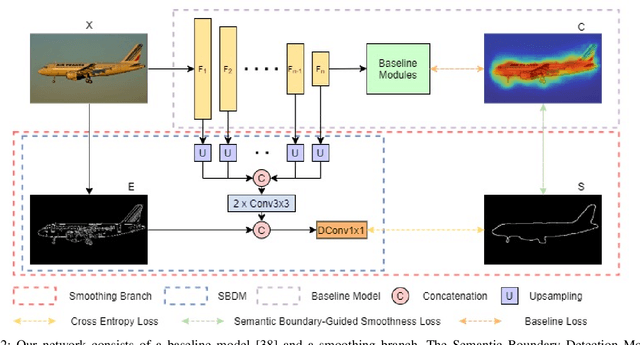


Compared with expensive pixel-wise annotations, image-level labels make it possible to learn semantic segmentation in a weakly-supervised manner. Within this pipeline, the class activation map (CAM) is obtained and further processed to serve as a pseudo label to train the semantic segmentation model in a fully-supervised manner. In this paper, we argue that the lost structure information in CAM limits its application in downstream semantic segmentation, leading to deteriorated predictions. Furthermore, the inconsistent class activation scores inside the same object contradicts the common sense that each region of the same object should belong to the same semantic category. To produce sharp prediction with structure information, we introduce an auxiliary semantic boundary detection module, which penalizes the deteriorated predictions. Furthermore, we adopt smoothness loss to encourage prediction inside the object to be consistent. Experimental results on the PASCAL-VOC dataset illustrate the effectiveness of the proposed solution.
Weakly Supervised Video Salient Object Detection
Apr 06, 2021
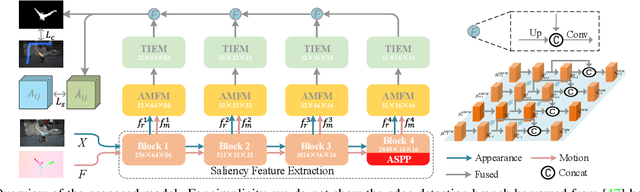
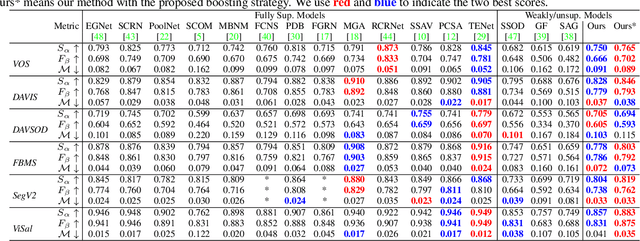
Significant performance improvement has been achieved for fully-supervised video salient object detection with the pixel-wise labeled training datasets, which are time-consuming and expensive to obtain. To relieve the burden of data annotation, we present the first weakly supervised video salient object detection model based on relabeled "fixation guided scribble annotations". Specifically, an "Appearance-motion fusion module" and bidirectional ConvLSTM based framework are proposed to achieve effective multi-modal learning and long-term temporal context modeling based on our new weak annotations. Further, we design a novel foreground-background similarity loss to further explore the labeling similarity across frames. A weak annotation boosting strategy is also introduced to boost our model performance with a new pseudo-label generation technique. Extensive experimental results on six benchmark video saliency detection datasets illustrate the effectiveness of our solution.
Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion
Mar 12, 2021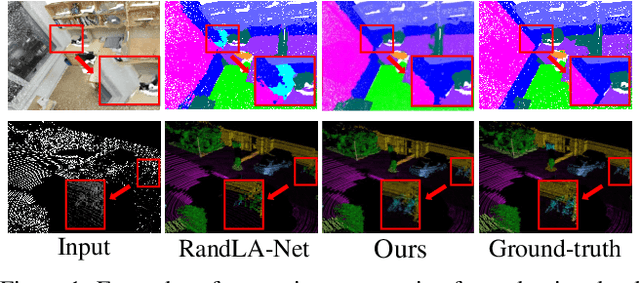
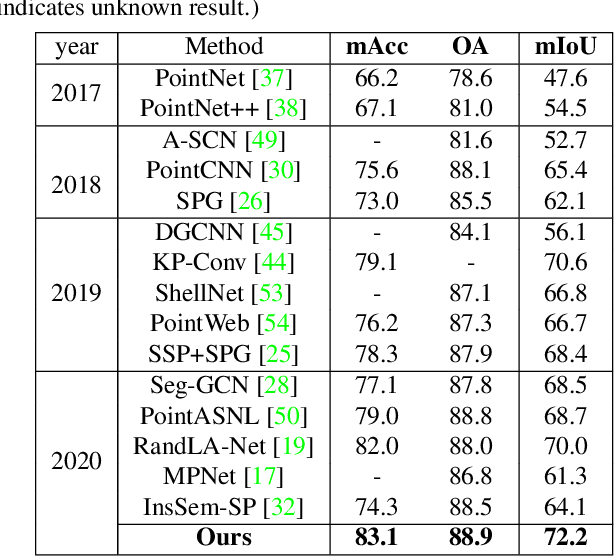
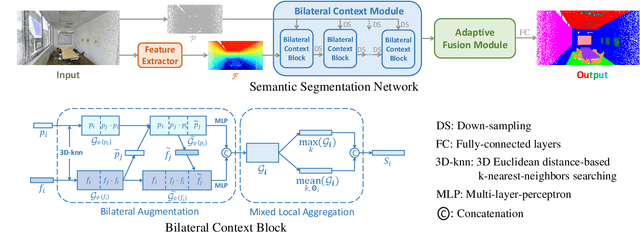
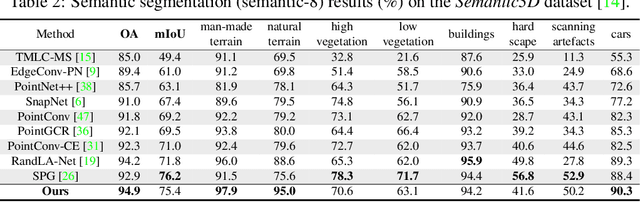
Given the prominence of current 3D sensors, a fine-grained analysis on the basic point cloud data is worthy of further investigation. Particularly, real point cloud scenes can intuitively capture complex surroundings in the real world, but due to 3D data's raw nature, it is very challenging for machine perception. In this work, we concentrate on the essential visual task, semantic segmentation, for large-scale point cloud data collected in reality. On the one hand, to reduce the ambiguity in nearby points, we augment their local context by fully utilizing both geometric and semantic features in a bilateral structure. On the other hand, we comprehensively interpret the distinctness of the points from multiple resolutions and represent the feature map following an adaptive fusion method at point-level for accurate semantic segmentation. Further, we provide specific ablation studies and intuitive visualizations to validate our key modules. By comparing with state-of-the-art networks on three different benchmarks, we demonstrate the effectiveness of our network.
Simultaneously Localize, Segment and Rank the Camouflaged Objects
Mar 06, 2021
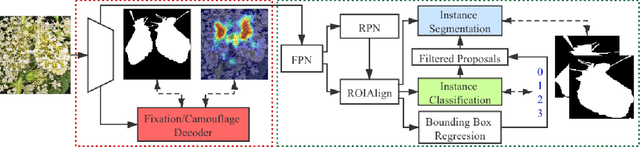
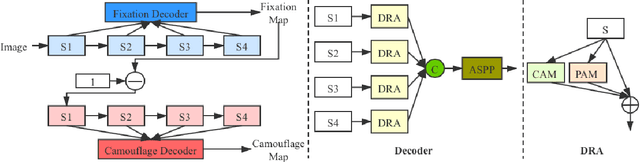
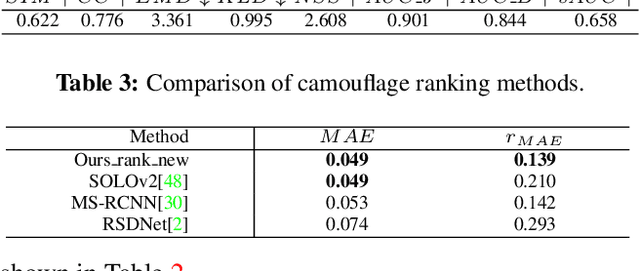
Camouflage is a key defence mechanism across species that is critical to survival. Common strategies for camouflage include background matching, imitating the color and pattern of the environment, and disruptive coloration, disguising body outlines [35]. Camouflaged object detection (COD) aims to segment camouflaged objects hiding in their surroundings. Existing COD models are built upon binary ground truth to segment the camouflaged objects without illustrating the level of camouflage. In this paper, we revisit this task and argue that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage and evolution of animals, but also provide guidance to design more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of the camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first ranking based COD network (Rank-Net) to simultaneously localize, segment and rank camouflaged objects. The localization model is proposed to find the discriminative regions that make the camouflaged object obvious. The segmentation model segments the full scope of the camouflaged objects. And, the ranking model infers the detectability of different camouflaged objects. Moreover, we contribute a large COD testing set to evaluate the generalization ability of COD models. Experimental results show that our model achieves new state-of-the-art, leading to a more interpretable COD network.
Recursive Training for Zero-Shot Semantic Segmentation
Feb 26, 2021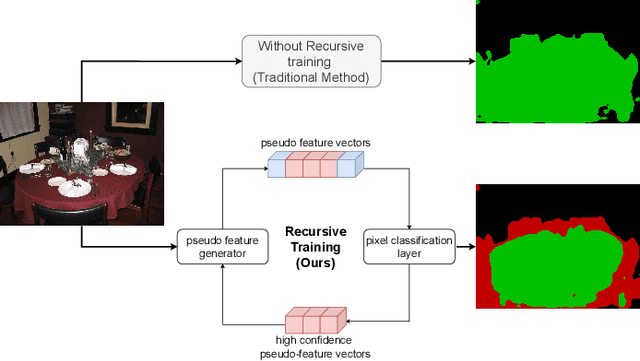
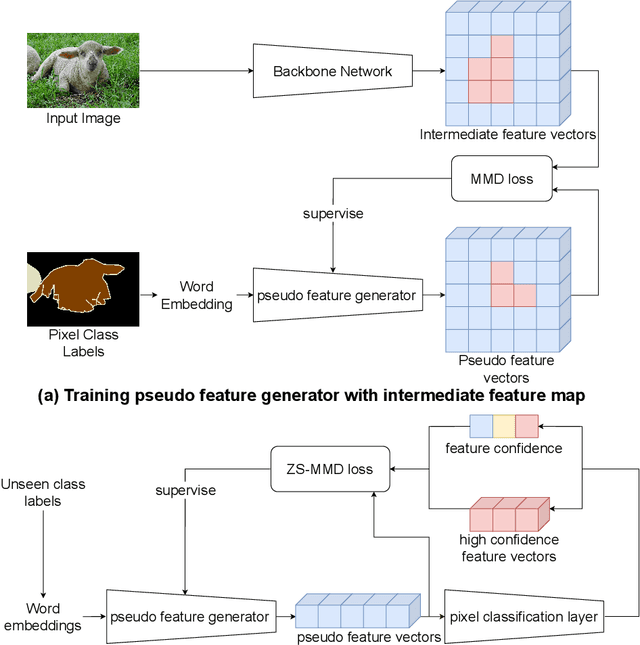

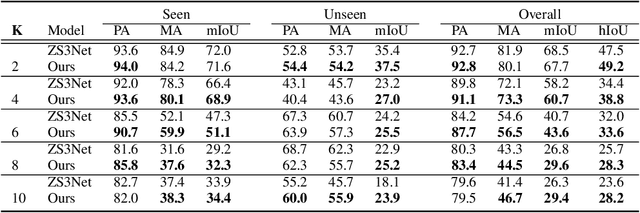
General purpose semantic segmentation relies on a backbone CNN network to extract discriminative features that help classify each image pixel into a 'seen' object class (ie., the object classes available during training) or a background class. Zero-shot semantic segmentation is a challenging task that requires a computer vision model to identify image pixels belonging to an object class which it has never seen before. Equipping a general purpose semantic segmentation model to separate image pixels of 'unseen' classes from the background remains an open challenge. Some recent models have approached this problem by fine-tuning the final pixel classification layer of a semantic segmentation model for a Zero-Shot setting, but struggle to learn discriminative features due to the lack of supervision. We propose a recursive training scheme to supervise the retraining of a semantic segmentation model for a zero-shot setting using a pseudo-feature representation. To this end, we propose a Zero-Shot Maximum Mean Discrepancy (ZS-MMD) loss that weighs high confidence outputs of the pixel classification layer as a pseudo-feature representation, and feeds it back to the generator. By closing-the-loop on the generator end, we provide supervision during retraining that in turn helps the model learn a more discriminative feature representation for 'unseen' classes. We show that using our recursive training and ZS-MMD loss, our proposed model achieves state-of-the-art performance on the Pascal-VOC 2012 dataset and Pascal-Context dataset.
Robust normalizing flows using Bernstein-type polynomials
Feb 06, 2021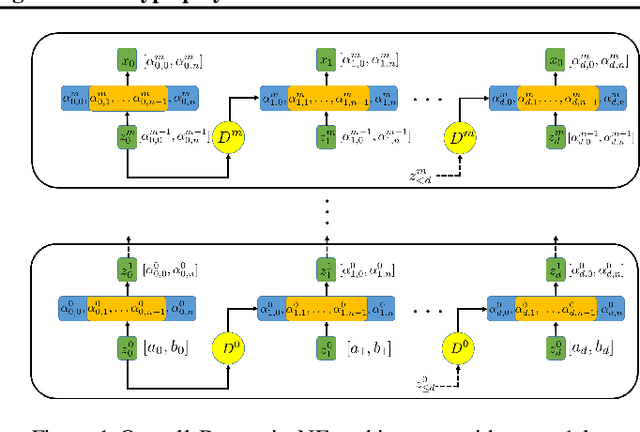
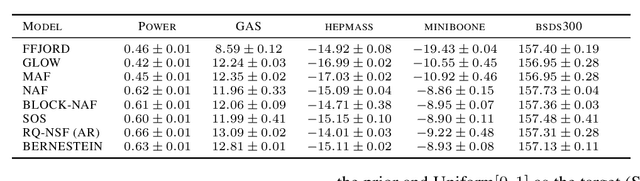
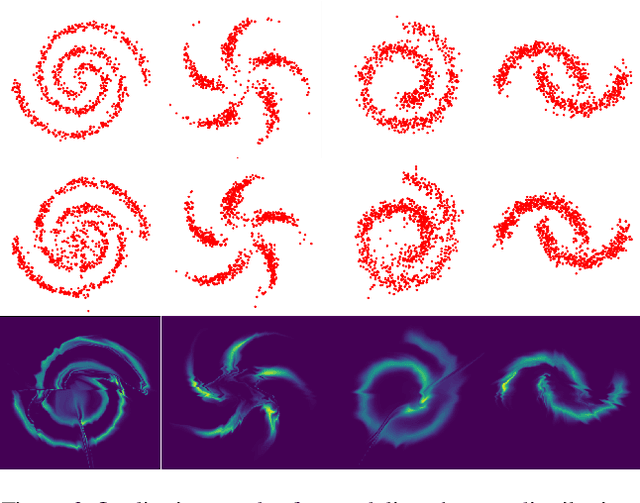
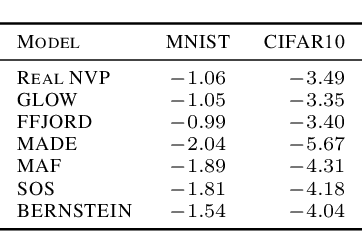
Normalizing flows (NFs) are a class of generative models that allows exact density evaluation and sampling. We propose a framework to construct NFs based on increasing triangular maps and Bernstein-type polynomials. Compared to the existing (universal) NF frameworks, our method provides compelling advantages like theoretical upper bounds for the approximation error, robustness, higher interpretability, suitability for compactly supported densities, and the ability to employ higher degree polynomials without training instability. Moreover, we provide a constructive universality proof, which gives analytic expressions of the approximations for known transformations. We conduct a thorough theoretical analysis and empirically demonstrate the efficacy of the proposed technique using experiments on both real-world and synthetic datasets.
Uncertainty-Aware Deep Calibrated Salient Object Detection
Dec 10, 2020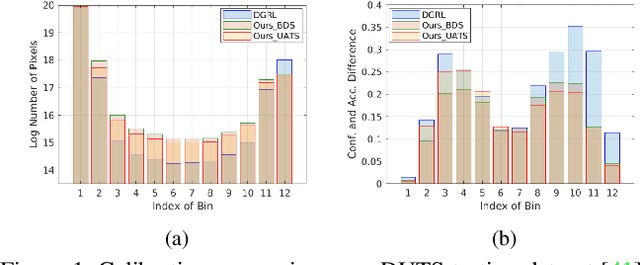
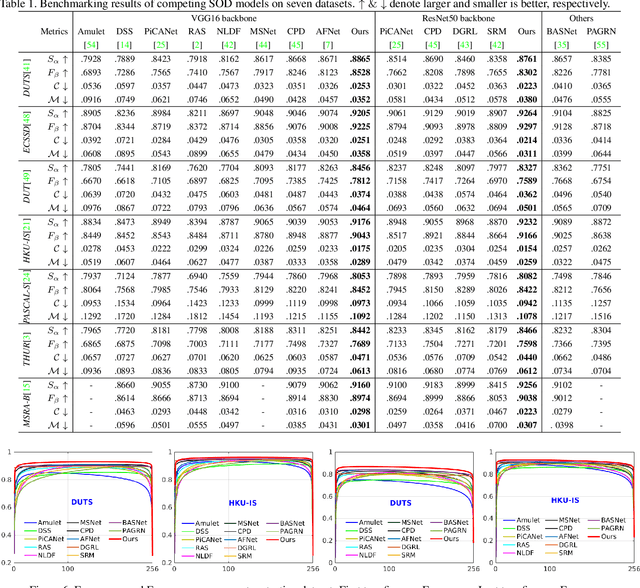

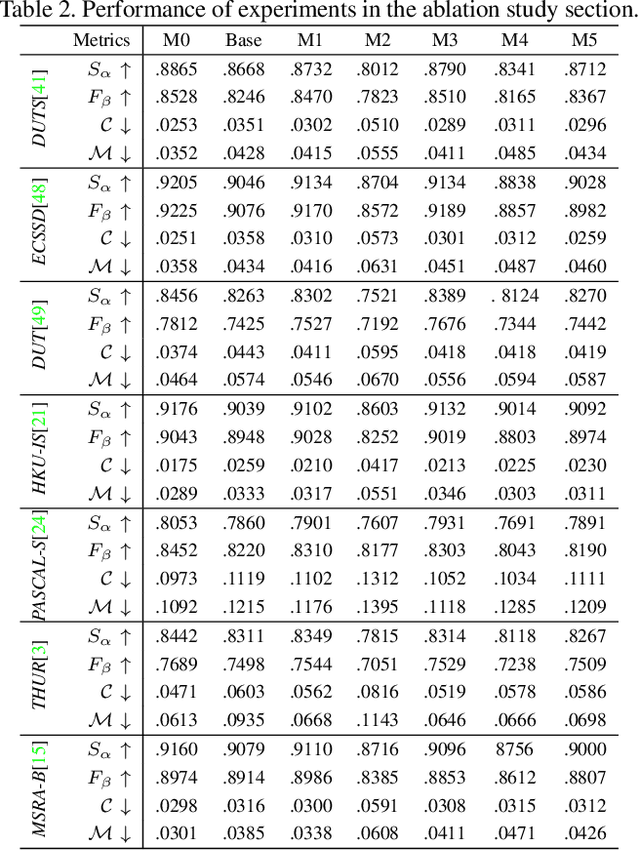
Existing deep neural network based salient object detection (SOD) methods mainly focus on pursuing high network accuracy. However, those methods overlook the gap between network accuracy and prediction confidence, known as the confidence uncalibration problem. Thus, state-of-the-art SOD networks are prone to be overconfident. In other words, the predicted confidence of the networks does not reflect the real probability of correctness of salient object detection, which significantly hinder their real-world applicability. In this paper, we introduce an uncertaintyaware deep SOD network, and propose two strategies from different perspectives to prevent deep SOD networks from being overconfident. The first strategy, namely Boundary Distribution Smoothing (BDS), generates continuous labels by smoothing the original binary ground-truth with respect to pixel-wise uncertainty. The second strategy, namely Uncertainty-Aware Temperature Scaling (UATS), exploits a relaxed Sigmoid function during both training and testing with spatially-variant temperature scaling to produce softened output. Both strategies can be incorporated into existing deep SOD networks with minimal efforts. Moreover, we propose a new saliency evaluation metric, namely dense calibration measure C, to measure how the model is calibrated on a given dataset. Extensive experimental results on seven benchmark datasets demonstrate that our solutions can not only better calibrate SOD models, but also improve the network accuracy.
3D Guided Weakly Supervised Semantic Segmentation
Dec 01, 2020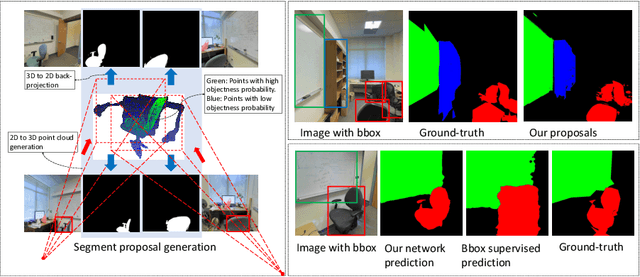
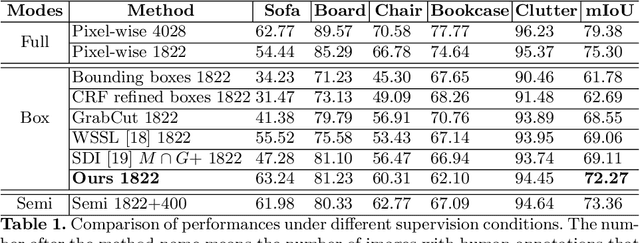
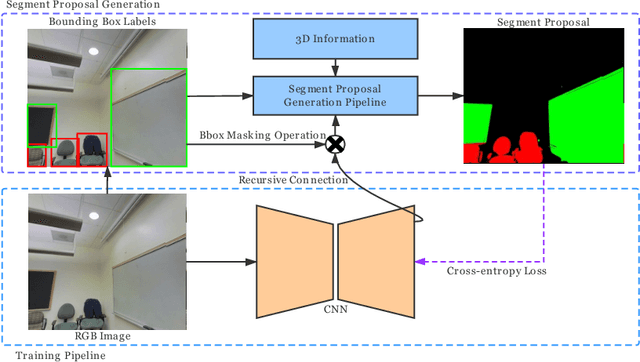
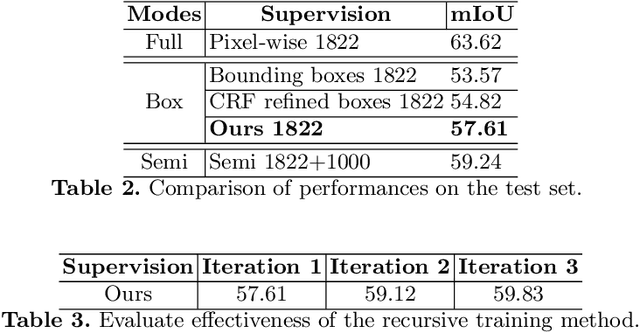
Pixel-wise clean annotation is necessary for fully-supervised semantic segmentation, which is laborious and expensive to obtain. In this paper, we propose a weakly supervised 2D semantic segmentation model by incorporating sparse bounding box labels with available 3D information, which is much easier to obtain with advanced sensors. We manually labeled a subset of the 2D-3D Semantics(2D-3D-S) dataset with bounding boxes, and introduce our 2D-3D inference module to generate accurate pixel-wise segment proposal masks. Guided by 3D information, we first generate a point cloud of objects and calculate objectness probability score for each point. Then we project the point cloud with objectness probabilities back to 2D images followed by a refinement step to obtain segment proposals, which are treated as pseudo labels to train a semantic segmentation network. Our method works in a recursive manner to gradually refine the above-mentioned segment proposals. Extensive experimental results on the 2D-3D-S dataset show that the proposed method can generate accurate segment proposals when bounding box labels are available on only a small subset of training images. Performance comparison with recent state-of-the-art methods further illustrates the effectiveness of our method.