 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multi-Objective Reinforcement Learning through Policy Orchestration
Sep 21, 2018
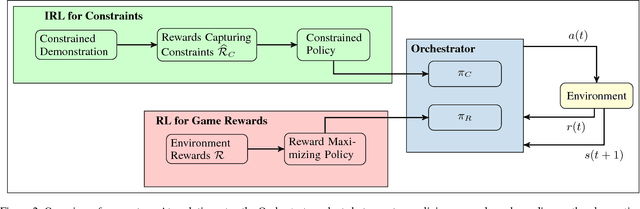
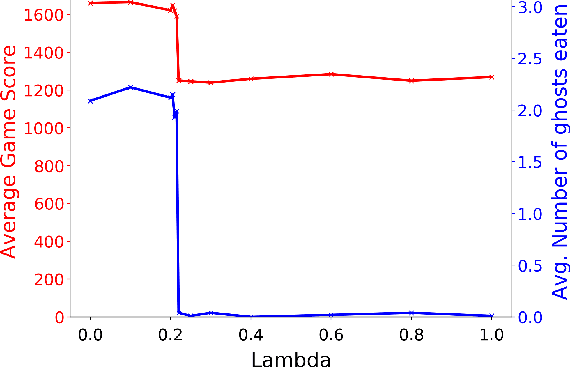
Autonomous cyber-physical agents and systems play an increasingly large role in our lives. To ensure that agents behave in ways aligned with the values of the societies in which they operate, we must develop techniques that allow these agents to not only maximize their reward in an environment, but also to learn and follow the implicit constraints of society. These constraints and norms can come from any number of sources including regulations, business process guidelines, laws, ethical principles, social norms, and moral values. We detail a novel approach that uses inverse reinforcement learning to learn a set of unspecified constraints from demonstrations of the task, and reinforcement learning to learn to maximize the environment rewards. More precisely, we assume that an agent can observe traces of behavior of members of the society but has no access to the explicit set of constraints that give rise to the observed behavior. Inverse reinforcement learning is used to learn such constraints, that are then combined with a possibly orthogonal value function through the use of a contextual bandit-based orchestrator that picks a contextually-appropriate choice between the two policies (constraint-based and environment reward-based) when taking actions. The contextual bandit orchestrator allows the agent to mix policies in novel ways, taking the best actions from either a reward maximizing or constrained policy. In addition, the orchestrator is transparent on which policy is being employed at each time step. We test our algorithms using a Pac-Man domain and show that the agent is able to learn to act optimally, act within the demonstrated constraints, and mix these two functions in complex ways.
Answering Science Exam Questions Using Query Rewriting with Background Knowledge
Sep 15, 2018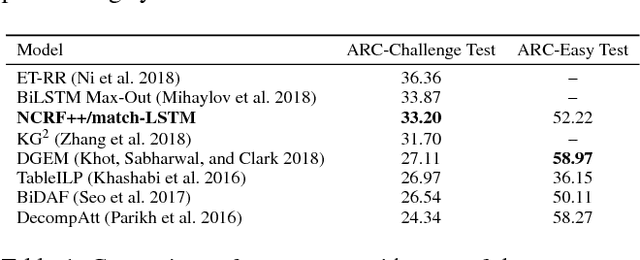
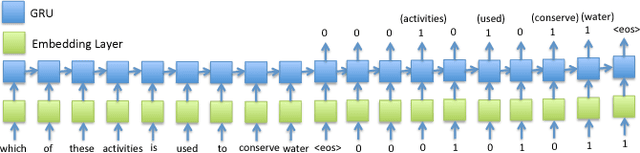
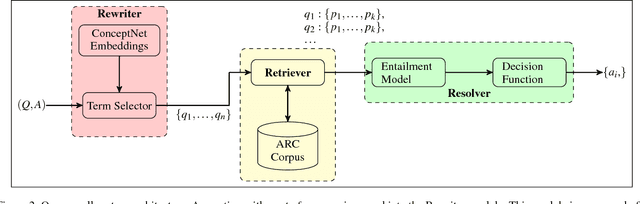
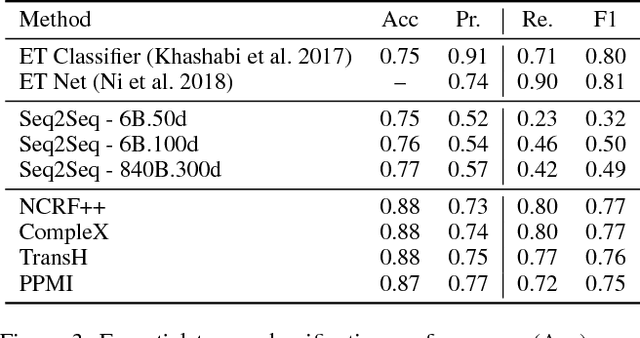
Open-domain question answering (QA) is an important problem in AI and NLP that is emerging as a bellwether for progress on the generalizability of AI methods and techniques. Much of the progress in open-domain QA systems has been realized through advances in information retrieval methods and corpus construction. In this paper, we focus on the recently introduced ARC Challenge dataset, which contains 2,590 multiple choice questions authored for grade-school science exams. These questions are selected to be the most challenging for current QA systems, and current state of the art performance is only slightly better than random chance. We present a system that rewrites a given question into queries that are used to retrieve supporting text from a large corpus of science-related text. Our rewriter is able to incorporate background knowledge from ConceptNet and -- in tandem with a generic textual entailment system trained on SciTail that identifies support in the retrieved results -- outperforms several strong baselines on the end-to-end QA task despite only being trained to identify essential terms in the original source question. We use a generalizable decision methodology over the retrieved evidence and answer candidates to select the best answer. By combining query rewriting, background knowledge, and textual entailment our system is able to outperform several strong baselines on the ARC dataset.
Improving Natural Language Inference Using External Knowledge in the Science Questions Domain
Sep 15, 2018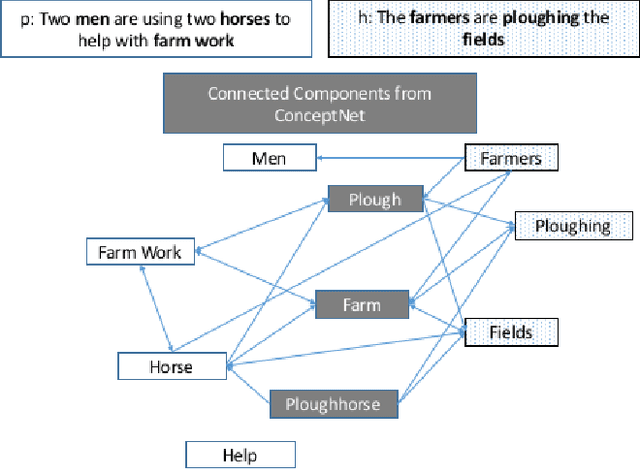
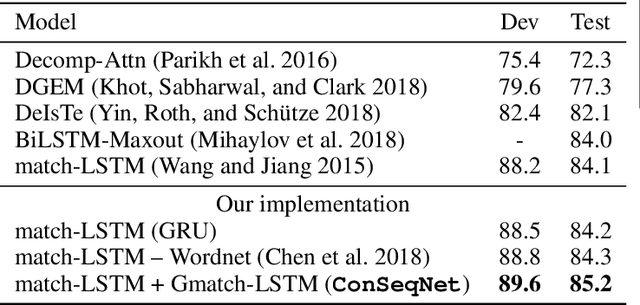
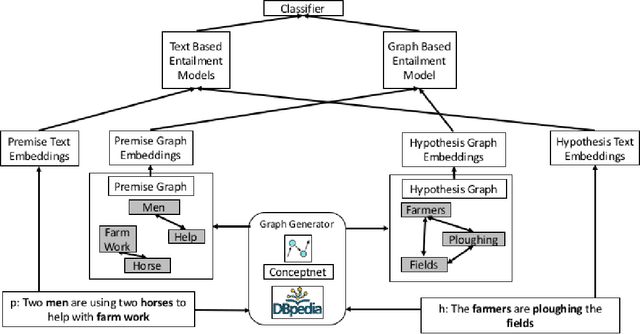
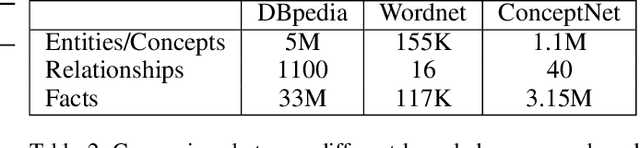
Natural Language Inference (NLI) is fundamental to many Natural Language Processing (NLP) applications including semantic search and question answering. The NLI problem has gained significant attention thanks to the release of large scale, challenging datasets. Present approaches to the problem largely focus on learning-based methods that use only textual information in order to classify whether a given premise entails, contradicts, or is neutral with respect to a given hypothesis. Surprisingly, the use of methods based on structured knowledge -- a central topic in artificial intelligence -- has not received much attention vis-a-vis the NLI problem. While there are many open knowledge bases that contain various types of reasoning information, their use for NLI has not been well explored. To address this, we present a combination of techniques that harness knowledge graphs to improve performance on the NLI problem in the science questions domain. We present the results of applying our techniques on text, graph, and text-to-graph based models, and discuss implications for the use of external knowledge in solving the NLI problem. Our model achieves the new state-of-the-art performance on the NLI problem over the SciTail science questions dataset.
Incorporating Behavioral Constraints in Online AI Systems
Sep 15, 2018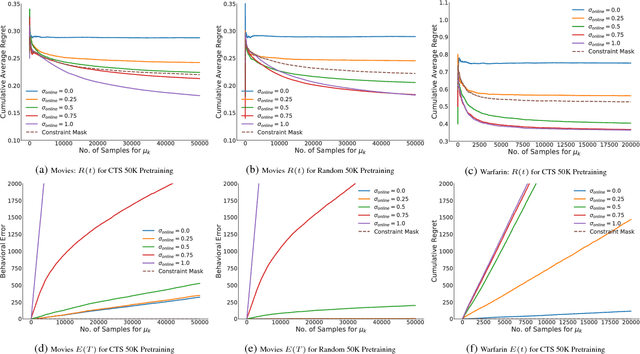
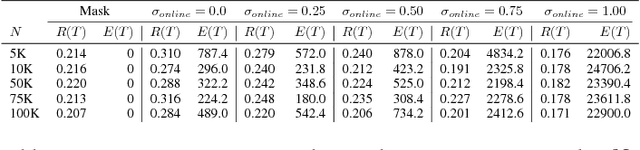
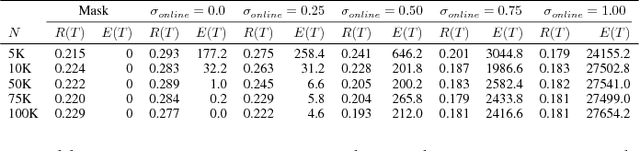
AI systems that learn through reward feedback about the actions they take are increasingly deployed in domains that have significant impact on our daily life. However, in many cases the online rewards should not be the only guiding criteria, as there are additional constraints and/or priorities imposed by regulations, values, preferences, or ethical principles. We detail a novel online agent that learns a set of behavioral constraints by observation and uses these learned constraints as a guide when making decisions in an online setting while still being reactive to reward feedback. To define this agent, we propose to adopt a novel extension to the classical contextual multi-armed bandit setting and we provide a new algorithm called Behavior Constrained Thompson Sampling (BCTS) that allows for online learning while obeying exogenous constraints. Our agent learns a constrained policy that implements the observed behavioral constraints demonstrated by a teacher agent, and then uses this constrained policy to guide the reward-based online exploration and exploitation. We characterize the upper bound on the expected regret of the contextual bandit algorithm that underlies our agent and provide a case study with real world data in two application domains. Our experiments show that the designed agent is able to act within the set of behavior constraints without significantly degrading its overall reward performance.
A Cost-Effective Framework for Preference Elicitation and Aggregation
Jul 07, 2018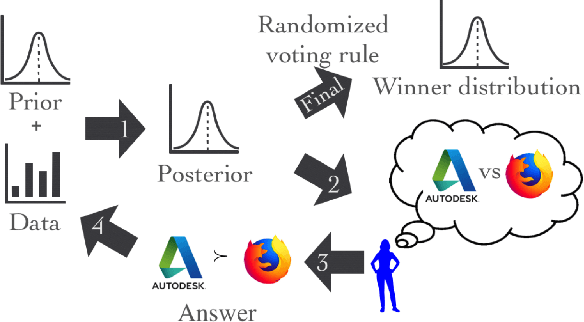
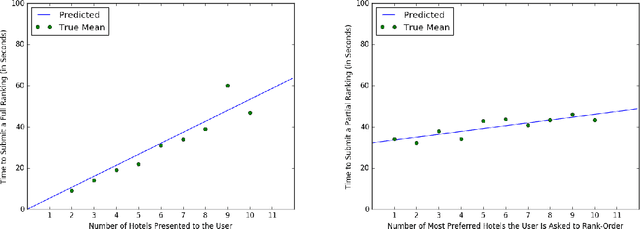
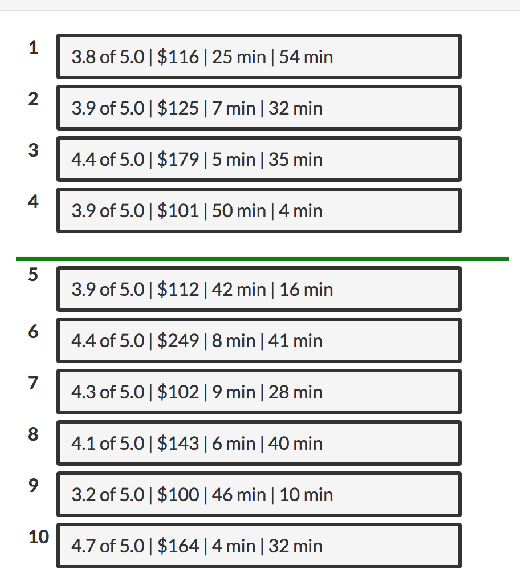
We propose a cost-effective framework for preference elicitation and aggregation under the Plackett-Luce model with features. Given a budget, our framework iteratively computes the most cost-effective elicitation questions in order to help the agents make a better group decision. We illustrate the viability of the framework with experiments on Amazon Mechanical Turk, which we use to estimate the cost of answering different types of elicitation questions. We compare the prediction accuracy of our framework when adopting various information criteria that evaluate the expected information gain from a question. Our experiments show carefully designed information criteria are much more efficient, i.e., they arrive at the correct answer using fewer queries, than randomly asking questions given the budget constraint.
A Systematic Classification of Knowledge, Reasoning, and Context within the ARC Dataset
Jun 01, 2018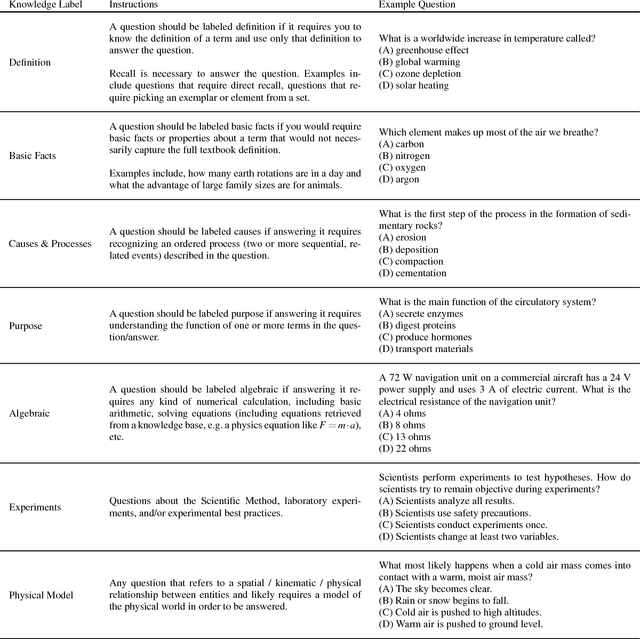
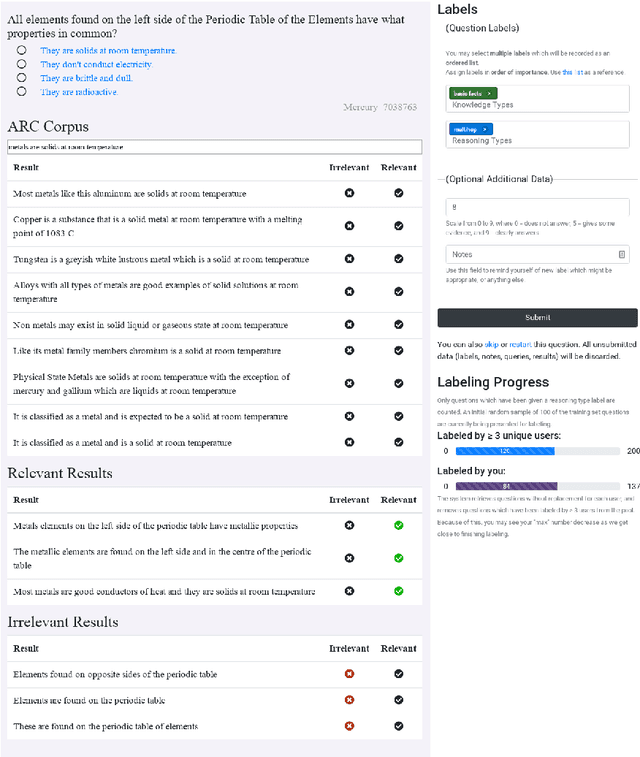
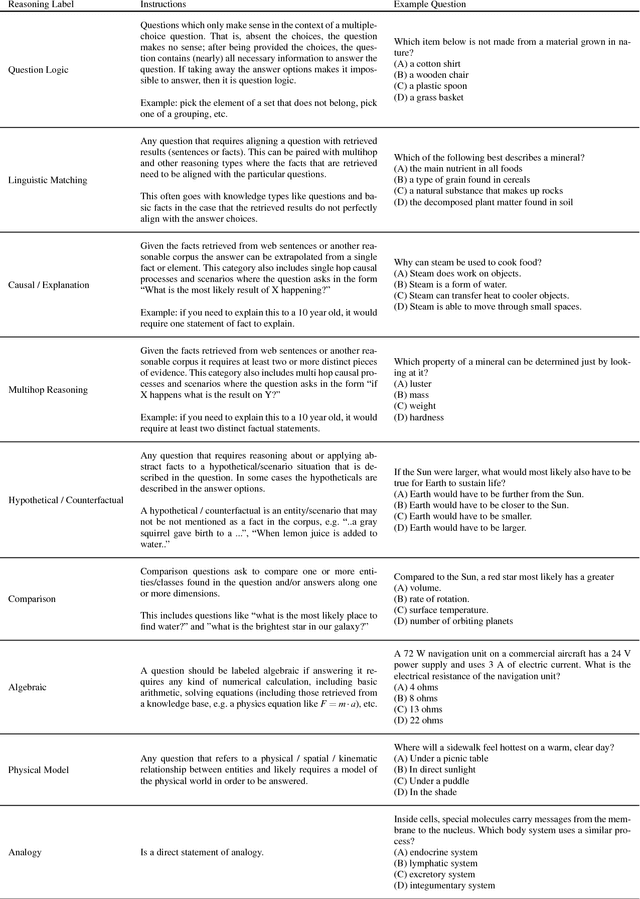
The recent work of Clark et al. introduces the AI2 Reasoning Challenge (ARC) and the associated ARC dataset that partitions open domain, complex science questions into an Easy Set and a Challenge Set. That paper includes an analysis of 100 questions with respect to the types of knowledge and reasoning required to answer them; however, it does not include clear definitions of these types, nor does it offer information about the quality of the labels. We propose a comprehensive set of definitions of knowledge and reasoning types necessary for answering the questions in the ARC dataset. Using ten annotators and a sophisticated annotation interface, we analyze the distribution of labels across the Challenge Set and statistics related to them. Additionally, we demonstrate that although naive information retrieval methods return sentences that are irrelevant to answering the query, sufficient supporting text is often present in the (ARC) corpus. Evaluating with human-selected relevant sentences improves the performance of a neural machine comprehension model by 42 points.
Strategyproof Peer Selection using Randomization, Partitioning, and Apportionment
Sep 29, 2017
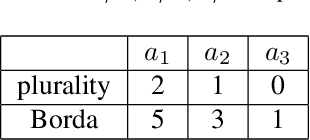
Peer review, evaluation, and selection is a fundamental aspect of modern science. Funding bodies the world over employ experts to review and select the best proposals of those submitted for funding. The problem of peer selection, however, is much more general: a professional society may want to give a subset of its members awards based on the opinions of all members; an instructor for a MOOC or online course may want to crowdsource grading; or a marketing company may select ideas from group brainstorming sessions based on peer evaluation. We make three fundamental contributions to the study of procedures or mechanisms for peer selection, a specific type of group decision-making problem, studied in computer science, economics, and political science. First, we propose a novel mechanism that is strategyproof, i.e., agents cannot benefit by reporting insincere valuations. Second, we demonstrate the effectiveness of our mechanism by a comprehensive simulation-based comparison with a suite of mechanisms found in the literature. Finally, our mechanism employs a randomized rounding technique that is of independent interest, as it solves the apportionment problem that arises in various settings where discrete resources such as parliamentary representation slots need to be divided proportionally.
The Conference Paper Assignment Problem: Using Order Weighted Averages to Assign Indivisible Goods
May 19, 2017
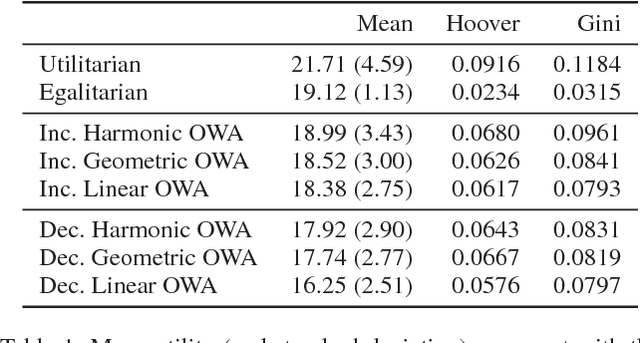
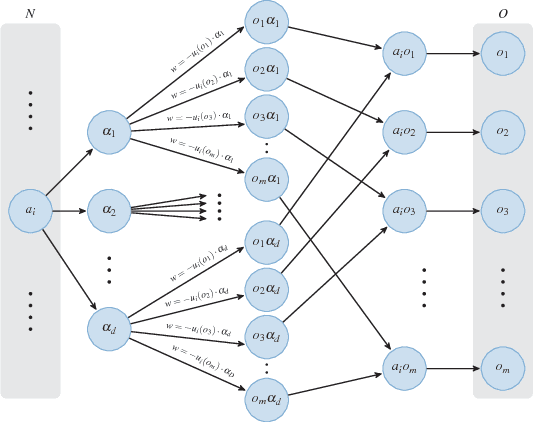
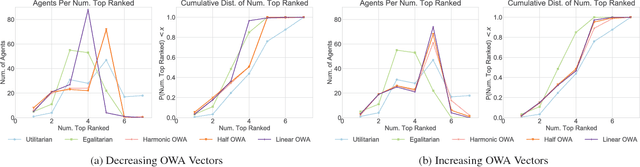
Motivated by the common academic problem of allocating papers to referees for conference reviewing we propose a novel mechanism for solving the assignment problem when we have a two sided matching problem with preferences from one side (the agents/reviewers) over the other side (the objects/papers) and both sides have capacity constraints. The assignment problem is a fundamental problem in both computer science and economics with application in many areas including task and resource allocation. We draw inspiration from multi-criteria decision making and voting and use order weighted averages (OWAs) to propose a novel and flexible class of algorithms for the assignment problem. We show an algorithm for finding a $\Sigma$-OWA assignment in polynomial time, in contrast to the NP-hardness of finding an egalitarian assignment. Inspired by this setting we observe an interesting connection between our model and the classic proportional multi-winner election problem in social choice.
Ethical Considerations in Artificial Intelligence Courses
Jan 26, 2017The recent surge in interest in ethics in artificial intelligence may leave many educators wondering how to address moral, ethical, and philosophical issues in their AI courses. As instructors we want to develop curriculum that not only prepares students to be artificial intelligence practitioners, but also to understand the moral, ethical, and philosophical impacts that artificial intelligence will have on society. In this article we provide practical case studies and links to resources for use by AI educators. We also provide concrete suggestions on how to integrate AI ethics into a general artificial intelligence course and how to teach a stand-alone artificial intelligence ethics course.
Empirical Evaluation of Real World Tournaments
Aug 03, 2016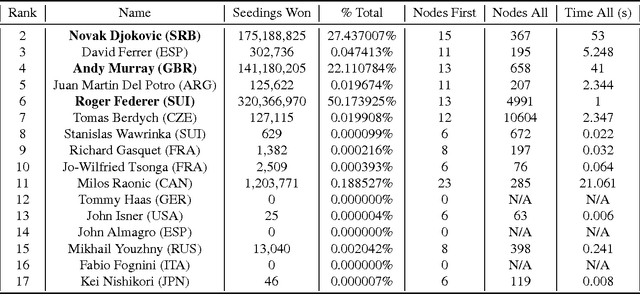
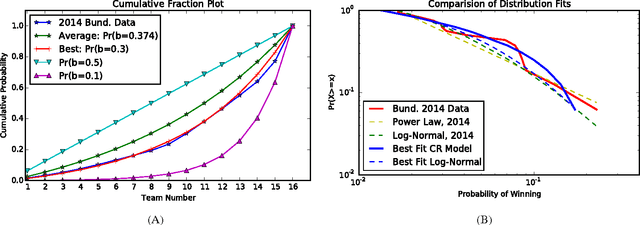
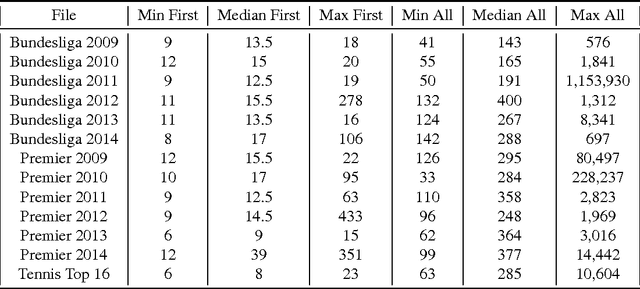
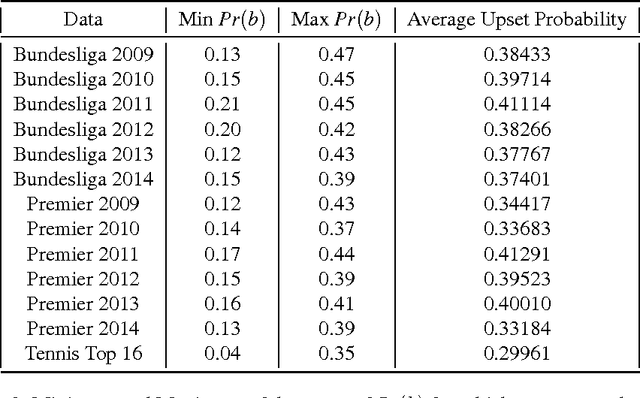
Computational Social Choice (ComSoc) is a rapidly developing field at the intersection of computer science, economics, social choice, and political science. The study of tournaments is fundamental to ComSoc and many results have been published about tournament solution sets and reasoning in tournaments. Theoretical results in ComSoc tend to be worst case and tell us little about performance in practice. To this end we detail some experiments on tournaments using real wold data from soccer and tennis. We make three main contributions to the understanding of tournaments using real world data from English Premier League, the German Bundesliga, and the ATP World Tour: (1) we find that the NP-hard question of finding a seeding for which a given team can win a tournament is easily solvable in real world instances, (2) using detailed and principled methodology from statistical physics we show that our real world data obeys a log-normal distribution; and (3) leveraging our log-normal distribution result and using robust statistical methods, we show that the popular Condorcet Random (CR) tournament model does not generate realistic tournament data.