 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization
Aug 01, 2021

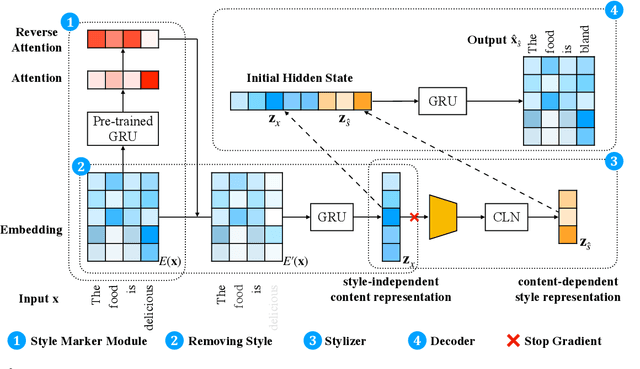
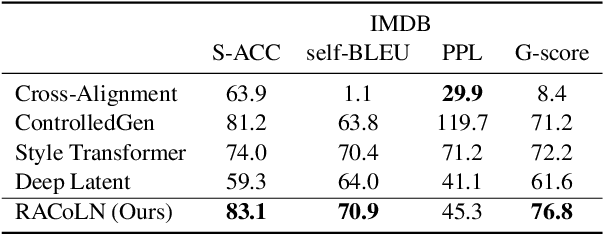
Text style transfer aims to alter the style (e.g., sentiment) of a sentence while preserving its content. A common approach is to map a given sentence to content representation that is free of style, and the content representation is fed to a decoder with a target style. Previous methods in filtering style completely remove tokens with style at the token level, which incurs the loss of content information. In this paper, we propose to enhance content preservation by implicitly removing the style information of each token with reverse attention, and thereby retain the content. Furthermore, we fuse content information when building the target style representation, making it dynamic with respect to the content. Our method creates not only style-independent content representation, but also content-dependent style representation in transferring style. Empirical results show that our method outperforms the state-of-the-art baselines by a large margin in terms of content preservation. In addition, it is also competitive in terms of style transfer accuracy and fluency.
DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling
Jul 05, 2021
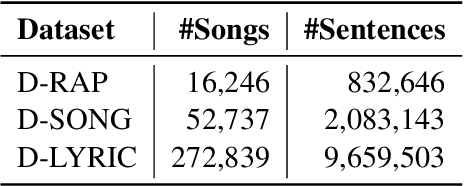
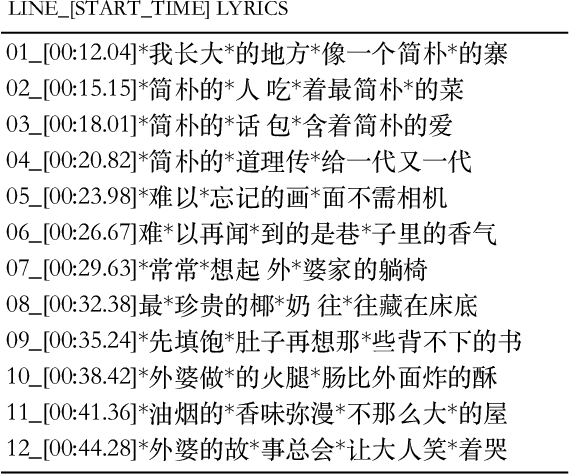

Rap generation, which aims to produce lyrics and corresponding singing beats, needs to model both rhymes and rhythms. Previous works for rap generation focused on rhyming lyrics but ignored rhythmic beats, which are important for rap performance. In this paper, we develop DeepRapper, a Transformer-based rap generation system that can model both rhymes and rhythms. Since there is no available rap dataset with rhythmic beats, we develop a data mining pipeline to collect a large-scale rap dataset, which includes a large number of rap songs with aligned lyrics and rhythmic beats. Second, we design a Transformer-based autoregressive language model which carefully models rhymes and rhythms. Specifically, we generate lyrics in the reverse order with rhyme representation and constraint for rhyme enhancement and insert a beat symbol into lyrics for rhythm/beat modeling. To our knowledge, DeepRapper is the first system to generate rap with both rhymes and rhythms. Both objective and subjective evaluations demonstrate that DeepRapper generates creative and high-quality raps with rhymes and rhythms. Code will be released on GitHub.
Learning from My Friends: Few-Shot Personalized Conversation Systems via Social Networks
May 21, 2021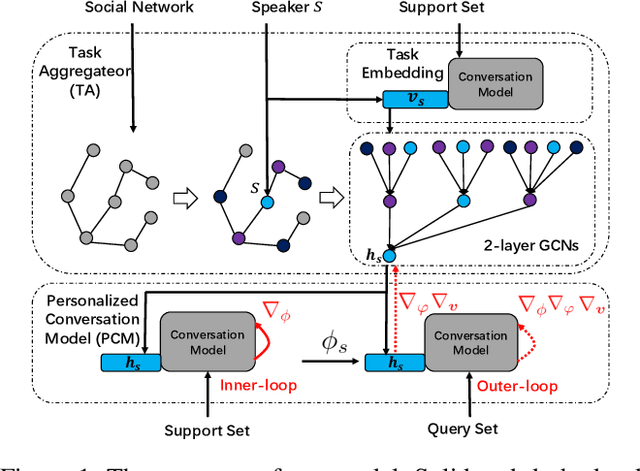
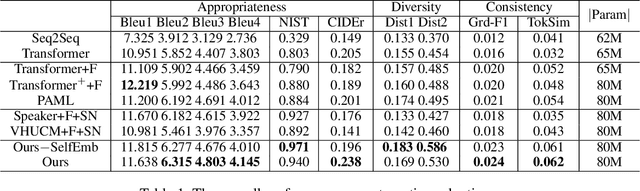


Personalized conversation models (PCMs) generate responses according to speaker preferences. Existing personalized conversation tasks typically require models to extract speaker preferences from user descriptions or their conversation histories, which are scarce for newcomers and inactive users. In this paper, we propose a few-shot personalized conversation task with an auxiliary social network. The task requires models to generate personalized responses for a speaker given a few conversations from the speaker and a social network. Existing methods are mainly designed to incorporate descriptions or conversation histories. Those methods can hardly model speakers with so few conversations or connections between speakers. To better cater for newcomers with few resources, we propose a personalized conversation model (PCM) that learns to adapt to new speakers as well as enabling new speakers to learn from resource-rich speakers. Particularly, based on a meta-learning based PCM, we propose a task aggregator (TA) to collect other speakers' information from the social network. The TA provides prior knowledge of the new speaker in its meta-learning. Experimental results show our methods outperform all baselines in appropriateness, diversity, and consistency with speakers.
Handling Collocations in Hierarchical Latent Tree Analysis for Topic Modeling
Jul 10, 2020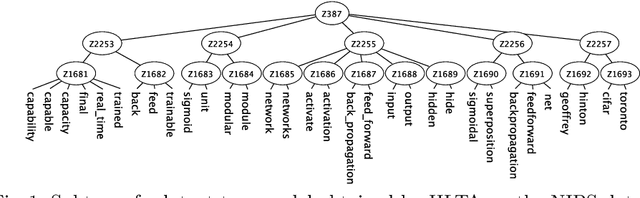

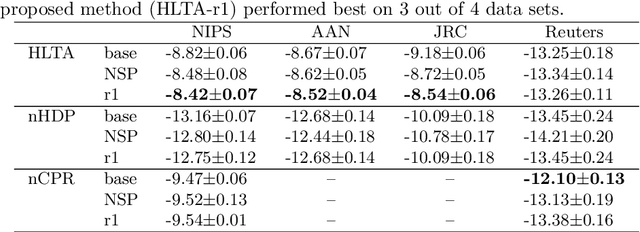
Topic modeling has been one of the most active research areas in machine learning in recent years. Hierarchical latent tree analysis (HLTA) has been recently proposed for hierarchical topic modeling and has shown superior performance over state-of-the-art methods. However, the models used in HLTA have a tree structure and cannot represent the different meanings of multiword expressions sharing the same word appropriately. Therefore, we propose a method for extracting and selecting collocations as a preprocessing step for HLTA. The selected collocations are replaced with single tokens in the bag-of-words model before running HLTA. Our empirical evaluation shows that the proposed method led to better performance of HLTA on three of the four data sets tested.
Response-Anticipated Memory for On-Demand Knowledge Integration in Response Generation
May 13, 2020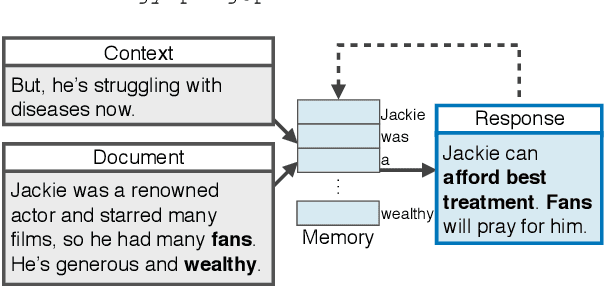
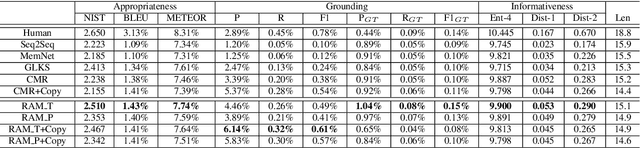
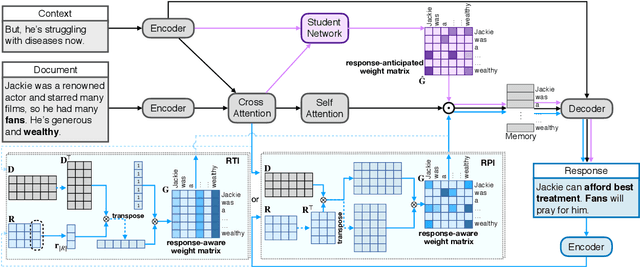

Neural conversation models are known to generate appropriate but non-informative responses in general. A scenario where informativeness can be significantly enhanced is Conversing by Reading (CbR), where conversations take place with respect to a given external document. In previous work, the external document is utilized by (1) creating a context-aware document memory that integrates information from the document and the conversational context, and then (2) generating responses referring to the memory. In this paper, we propose to create the document memory with some anticipated responses in mind. This is achieved using a teacher-student framework. The teacher is given the external document, the context, and the ground-truth response, and learns how to build a response-aware document memory from three sources of information. The student learns to construct a response-anticipated document memory from the first two sources, and the teacher's insight on memory creation. Empirical results show that our model outperforms the previous state-of-the-art for the CbR task.
Not All Attention Is Needed: Gated Attention Network for Sequence Data
Dec 01, 2019
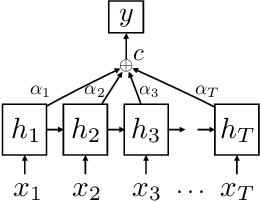
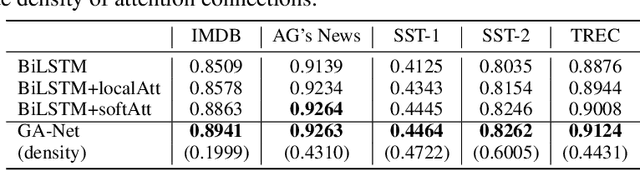
Although deep neural networks generally have fixed network structures, the concept of dynamic mechanism has drawn more and more attention in recent years. Attention mechanisms compute input-dependent dynamic attention weights for aggregating a sequence of hidden states. Dynamic network configuration in convolutional neural networks (CNNs) selectively activates only part of the network at a time for different inputs. In this paper, we combine the two dynamic mechanisms for text classification tasks. Traditional attention mechanisms attend to the whole sequence of hidden states for an input sentence, while in most cases not all attention is needed especially for long sequences. We propose a novel method called Gated Attention Network (GA-Net) to dynamically select a subset of elements to attend to using an auxiliary network, and compute attention weights to aggregate the selected elements. It avoids a significant amount of unnecessary computation on unattended elements, and allows the model to pay attention to important parts of the sequence. Experiments in various datasets show that the proposed method achieves better performance compared with all baseline models with global or local attention while requiring less computation and achieving better interpretability. It is also promising to extend the idea to more complex attention-based models, such as transformers and seq-to-seq models.
Cleaned Similarity for Better Memory-Based Recommenders
May 17, 2019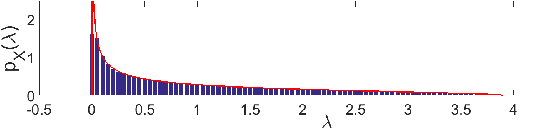
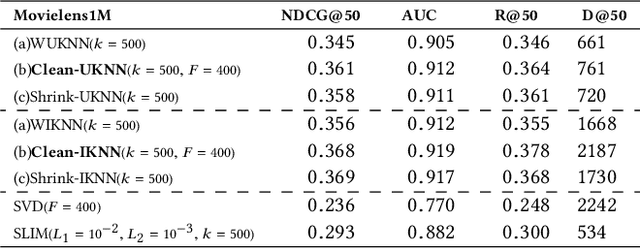
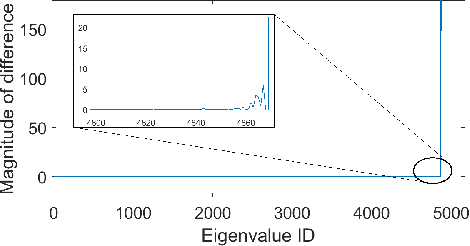
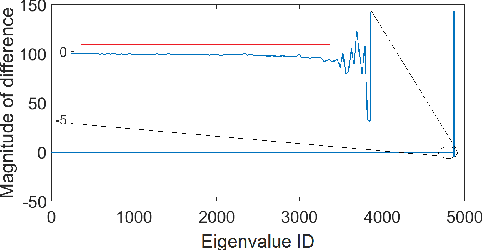
Memory-based collaborative filtering methods like user or item k-nearest neighbors (kNN) are a simple yet effective solution to the recommendation problem. The backbone of these methods is the estimation of the empirical similarity between users/items. In this paper, we analyze the spectral properties of the Pearson and the cosine similarity estimators, and we use tools from random matrix theory to argue that they suffer from noise and eigenvalues spreading. We argue that, unlike the Pearson correlation, the cosine similarity naturally possesses the desirable property of eigenvalue shrinkage for large eigenvalues. However, due to its zero-mean assumption, it overestimates the largest eigenvalues. We quantify this overestimation and present a simple re-scaling and noise cleaning scheme. This results in better performance of the memory-based methods compared to their vanilla counterparts.
Using Taste Groups for Collaborative Filtering
Aug 28, 2018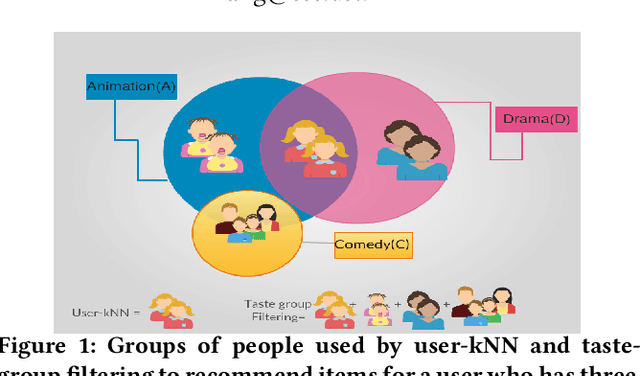
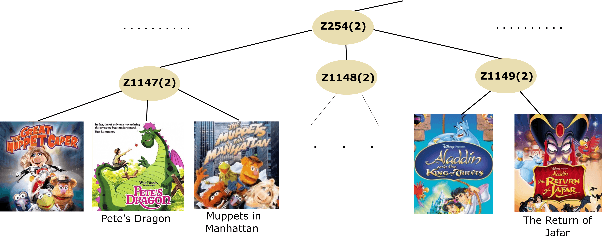
Implicit feedback is the simplest form of user feedback that can be used for item recommendation. It is easy to collect and domain independent. However, there is a lack of negative examples. Existing works circumvent this problem by making various assumptions regarding the unconsumed items, which fail to hold when the user did not consume an item because she was unaware of it. In this paper, we propose as a novel method for addressing the lack of negative examples in implicit feedback. The motivation is that if there is a large group of users who share the same taste and none of them consumed an item, then it is highly likely that the item is irrelevant to this taste. We use Hierarchical Latent Tree Analysis(HLTA) to identify taste-based user groups and make recommendations for a user based on her memberships in the groups.
Matrix Factorization Equals Efficient Co-occurrence Representation
Aug 28, 2018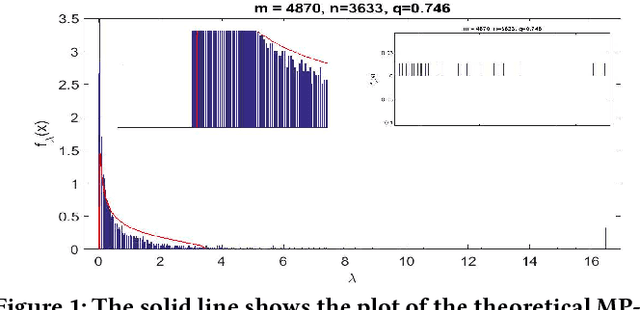
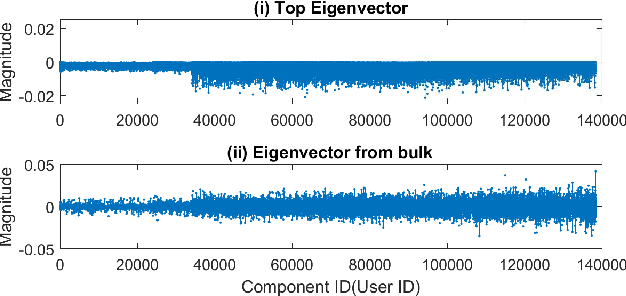
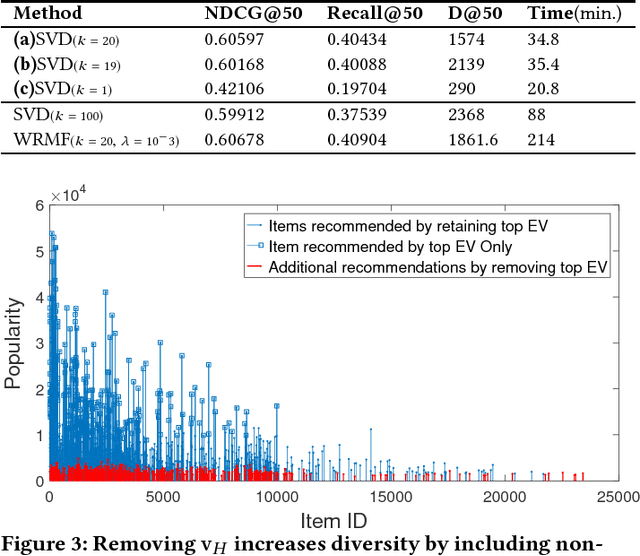
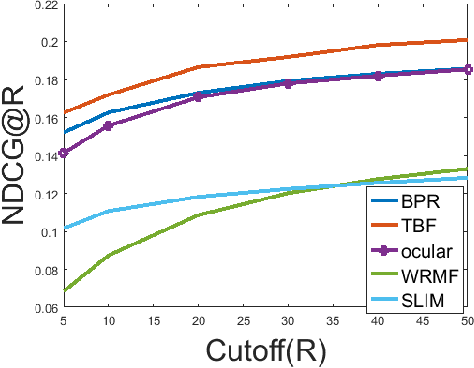
Matrix factorization is a simple and effective solution to the recommendation problem. It has been extensively employed in the industry and has attracted much attention from the academia. However, it is unclear what the low-dimensional matrices represent. We show that matrix factorization can actually be seen as simultaneously calculating the eigenvectors of the user-user and item-item sample co-occurrence matrices. We then use insights from random matrix theory (RMT) to show that picking the top eigenvectors corresponds to removing sampling noise from user/item co-occurrence matrices. Therefore, the low-dimension matrices represent a reduced noise user and item co-occurrence space. We also analyze the structure of the top eigenvector and show that it corresponds to global effects and removing it results in less popular items being recommended. This increases the diversity of the items recommended without affecting the accuracy.
Sparse Boltzmann Machines with Structure Learning as Applied to Text Analysis
Aug 05, 2018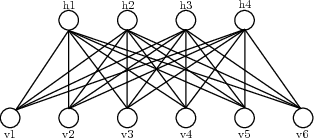
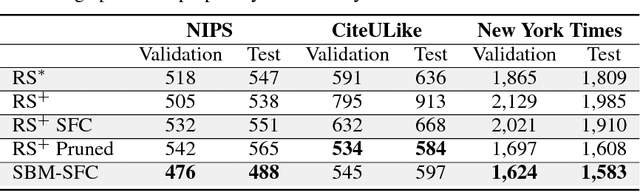
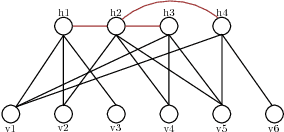
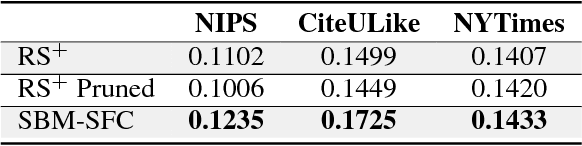
We are interested in exploring the possibility and benefits of structure learning for deep models. As the first step, this paper investigates the matter for Restricted Boltzmann Machines (RBMs). We conduct the study with Replicated Softmax, a variant of RBMs for unsupervised text analysis. We present a method for learning what we call Sparse Boltzmann Machines, where each hidden unit is connected to a subset of the visible units instead of all of them. Empirical results show that the method yields models with significantly improved model fit and interpretability as compared with RBMs where each hidden unit is connected to all visible units.