 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Model Decide its Curriculum for Multitask Learning
May 27, 2022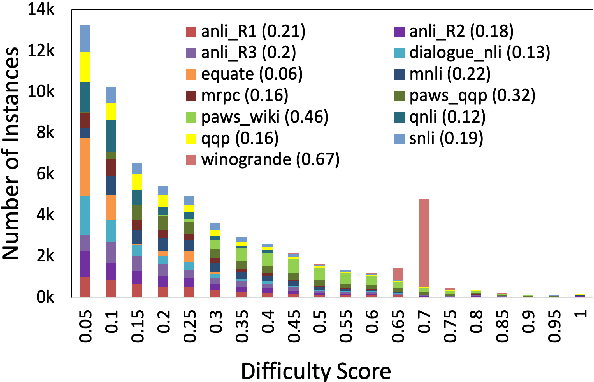
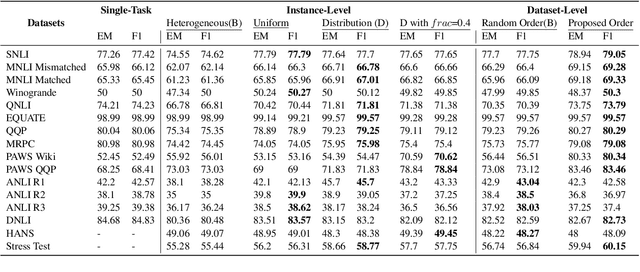
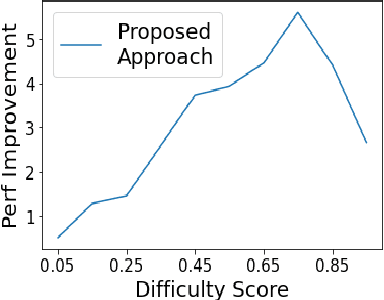
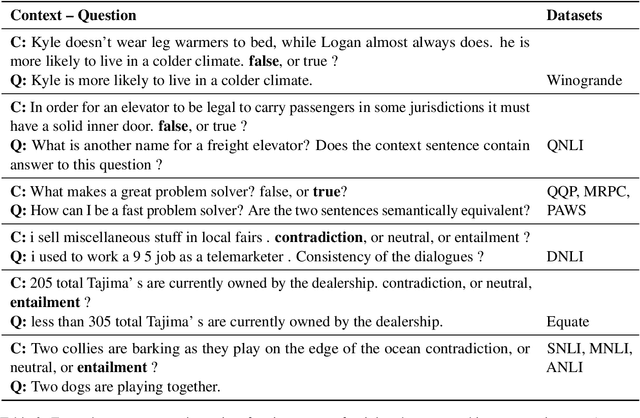
Curriculum learning strategies in prior multi-task learning approaches arrange datasets in a difficulty hierarchy either based on human perception or by exhaustively searching the optimal arrangement. However, human perception of difficulty may not always correlate well with machine interpretation leading to poor performance and exhaustive search is computationally expensive. Addressing these concerns, we propose two classes of techniques to arrange training instances into a learning curriculum based on difficulty scores computed via model-based approaches. The two classes i.e Dataset-level and Instance-level differ in granularity of arrangement. Through comprehensive experiments with 12 datasets, we show that instance-level and dataset-level techniques result in strong representations as they lead to an average performance improvement of 4.17% and 3.15% over their respective baselines. Furthermore, we find that most of this improvement comes from correctly answering the difficult instances, implying a greater efficacy of our techniques on difficult tasks.
Impact of Multiple Fully-Absorbing Receivers in Molecular Communications
May 21, 2022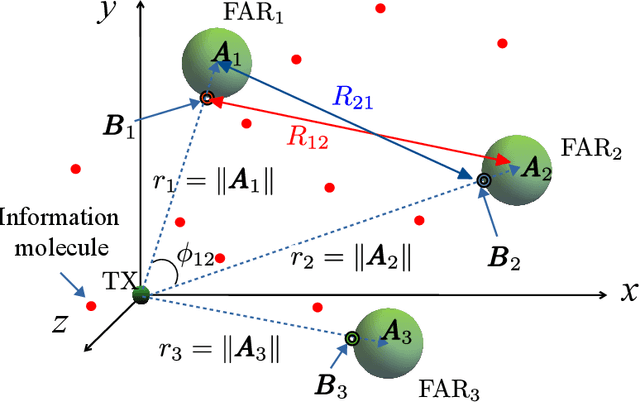
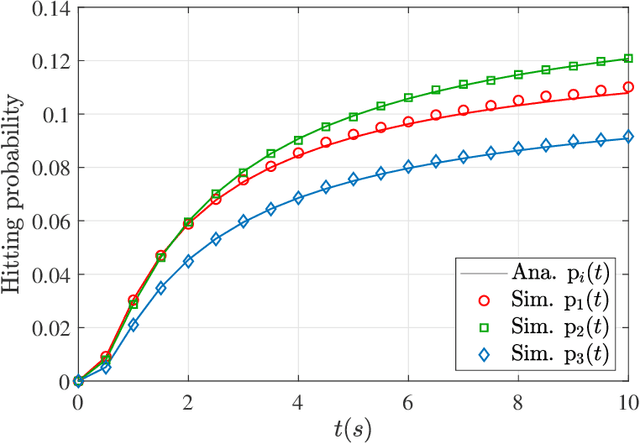
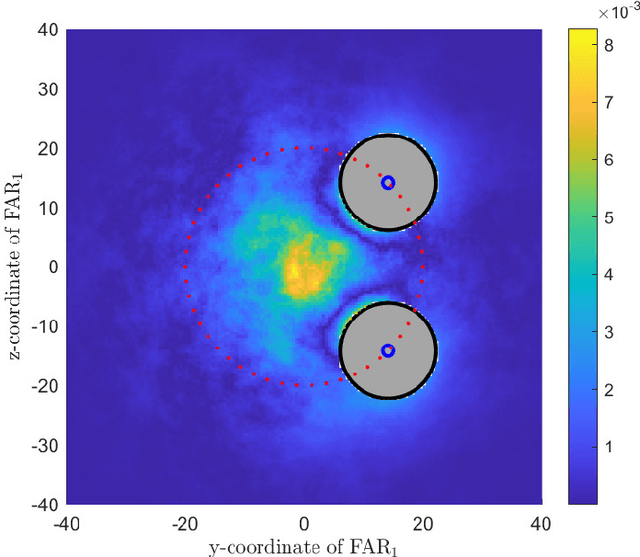
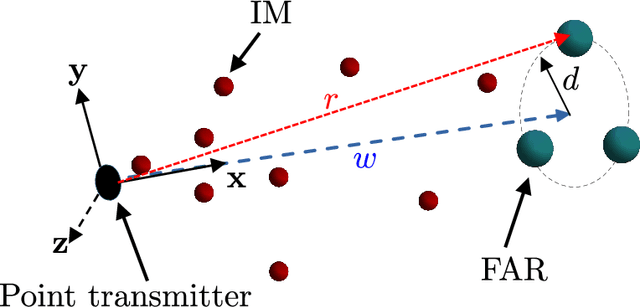
Molecular communication is a promising solution to enable intra-body communications among nanomachines. However, malicious and non-cooperative receivers can degrade the performance, compromising these systems' security. Analyzing the communication and security performance of these systems requires accurate channel models. However, such models are not present in the literature. In this work, we develop an analytical framework to derive the hitting probability of a molecule on a fully absorbing receiver (FAR) in the presence of other FARs, which can be either be cooperative or malicious. We first present an approximate hitting probability expression for the 3-FARs case. A simplified expression is obtained for the case when FARs are symmetrically positioned. Using the derived expressions, we study the impact of malicious receivers on the intended receiver and discuss how to minimize this impact to obtain a secure communication channel. We also study the gain that can be obtained by the cooperation of these FARs. We then present an approach to extend the analysis for a system with N FARs. The derived expressions can be used to analyze and design multiple input/output and secure molecular communication systems.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

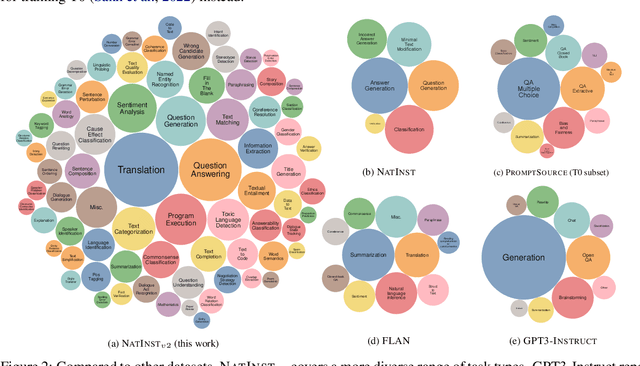
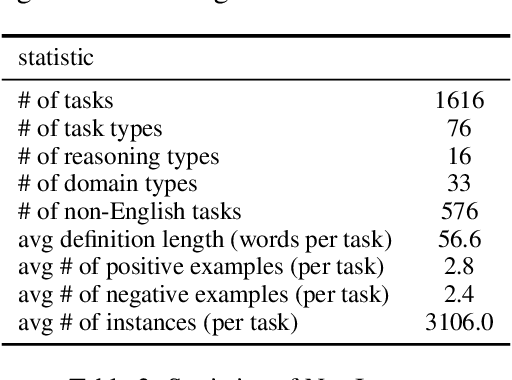
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
NumGLUE: A Suite of Fundamental yet Challenging Mathematical Reasoning Tasks
Apr 12, 2022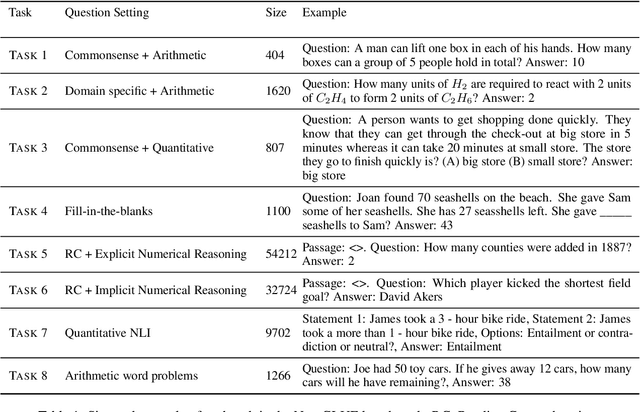
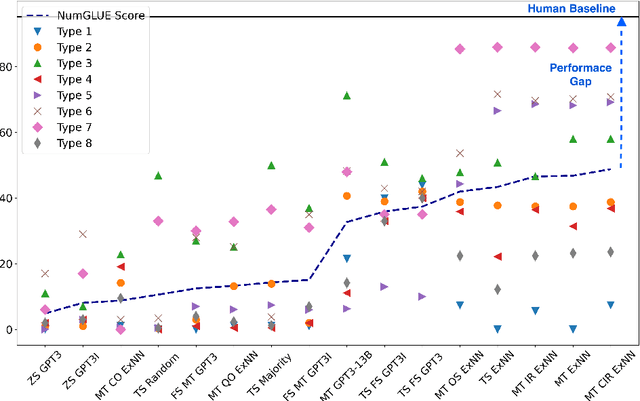
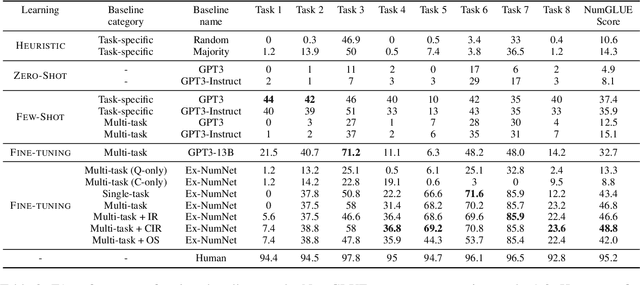

Given the ubiquitous nature of numbers in text, reasoning with numbers to perform simple calculations is an important skill of AI systems. While many datasets and models have been developed to this end, state-of-the-art AI systems are brittle; failing to perform the underlying mathematical reasoning when they appear in a slightly different scenario. Drawing inspiration from GLUE that was proposed in the context of natural language understanding, we propose NumGLUE, a multi-task benchmark that evaluates the performance of AI systems on eight different tasks, that at their core require simple arithmetic understanding. We show that this benchmark is far from being solved with neural models including state-of-the-art large-scale language models performing significantly worse than humans (lower by 46.4%). Further, NumGLUE promotes sharing knowledge across tasks, especially those with limited training data as evidenced by the superior performance (average gain of 3.4% on each task) when a model is jointly trained on all the tasks as opposed to task-specific modeling. Finally, we hope that NumGLUE will encourage systems that perform robust and general arithmetic reasoning within language, a first step towards being able to perform more complex mathematical reasoning.
ILDAE: Instance-Level Difficulty Analysis of Evaluation Data
Mar 09, 2022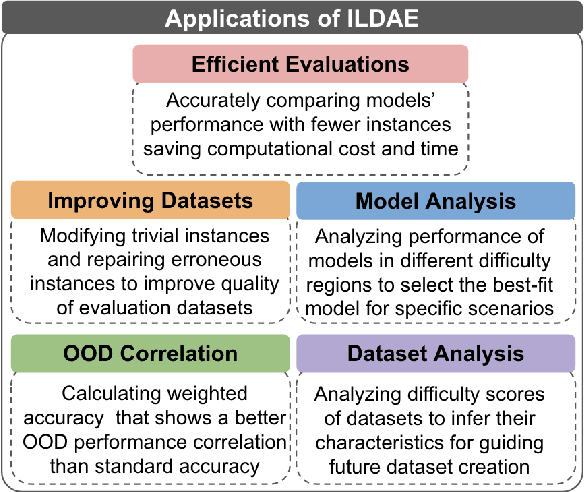
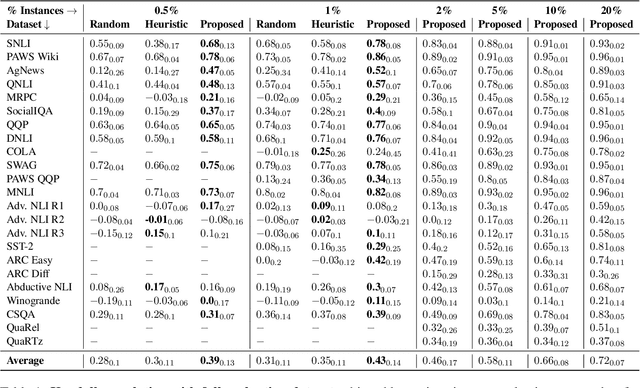
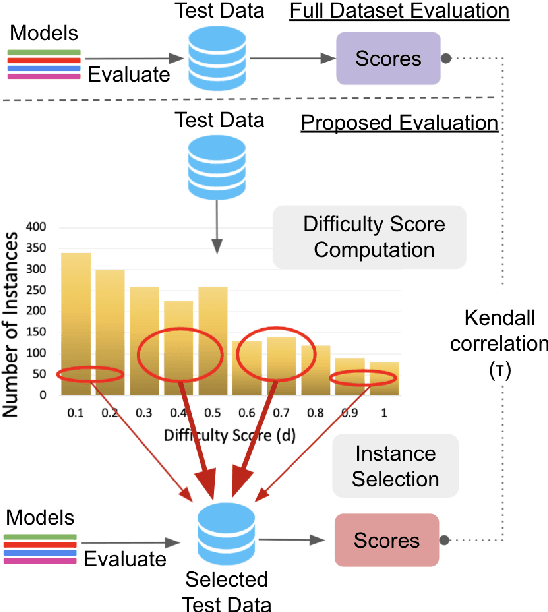

Knowledge of questions' difficulty level helps a teacher in several ways, such as estimating students' potential quickly by asking carefully selected questions and improving quality of examination by modifying trivial and hard questions. Can we extract such benefits of instance difficulty in NLP? To this end, we conduct Instance-Level Difficulty Analysis of Evaluation data (ILDAE) in a large-scale setup of 23 datasets and demonstrate its five novel applications: 1) conducting efficient-yet-accurate evaluations with fewer instances saving computational cost and time, 2) improving quality of existing evaluation datasets by repairing erroneous and trivial instances, 3) selecting the best model based on application requirements, 4) analyzing dataset characteristics for guiding future data creation, 5) estimating Out-of-Domain performance reliably. Comprehensive experiments for these applications result in several interesting findings, such as evaluation using just 5% instances (selected via ILDAE) achieves as high as 0.93 Kendall correlation with evaluation using complete dataset and computing weighted accuracy using difficulty scores leads to 5.2% higher correlation with Out-of-Domain performance. We release the difficulty scores and hope our analyses and findings will bring more attention to this important yet understudied field of leveraging instance difficulty in evaluations.
Investigating Selective Prediction Approaches Across Several Tasks in IID, OOD, and Adversarial Settings
Mar 01, 2022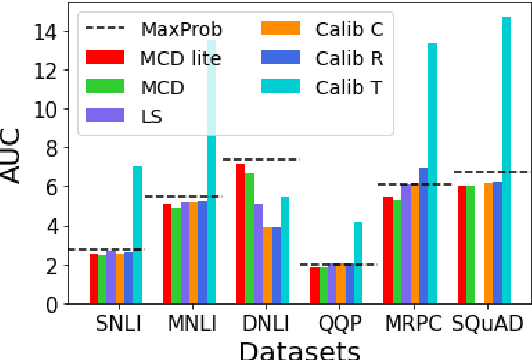
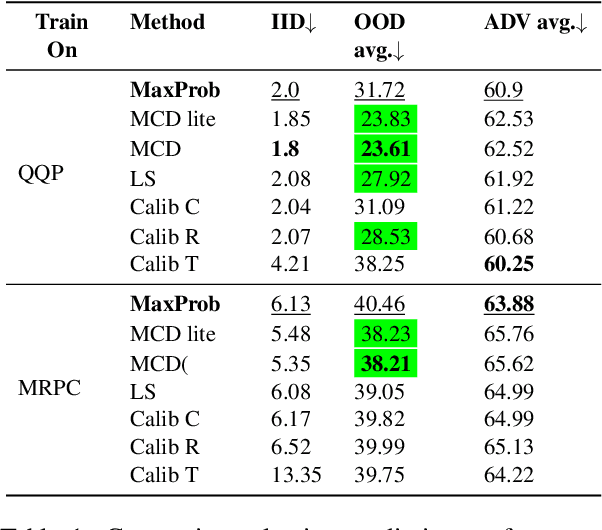
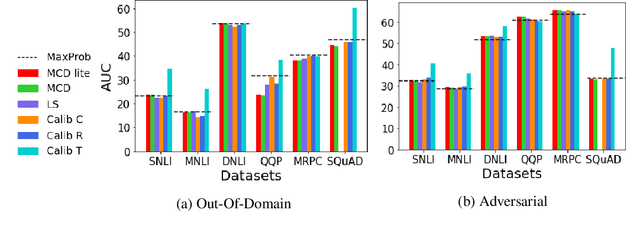
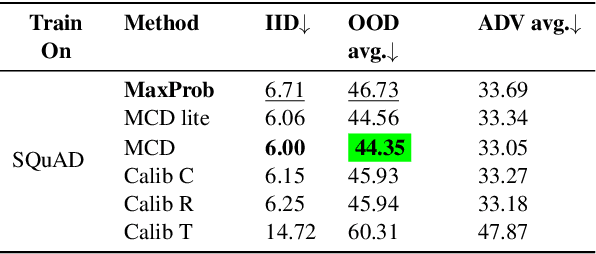
In order to equip NLP systems with selective prediction capability, several task-specific approaches have been proposed. However, which approaches work best across tasks or even if they consistently outperform the simplest baseline 'MaxProb' remains to be explored. To this end, we systematically study 'selective prediction' in a large-scale setup of 17 datasets across several NLP tasks. Through comprehensive experiments under in-domain (IID), out-of-domain (OOD), and adversarial (ADV) settings, we show that despite leveraging additional resources (held-out data/computation), none of the existing approaches consistently and considerably outperforms MaxProb in all three settings. Furthermore, their performance does not translate well across tasks. For instance, Monte-Carlo Dropout outperforms all other approaches on Duplicate Detection datasets but does not fare well on NLI datasets, especially in the OOD setting. Thus, we recommend that future selective prediction approaches should be evaluated across tasks and settings for reliable estimation of their capabilities.
Unsupervised Natural Language Inference Using PHL Triplet Generation
Oct 16, 2021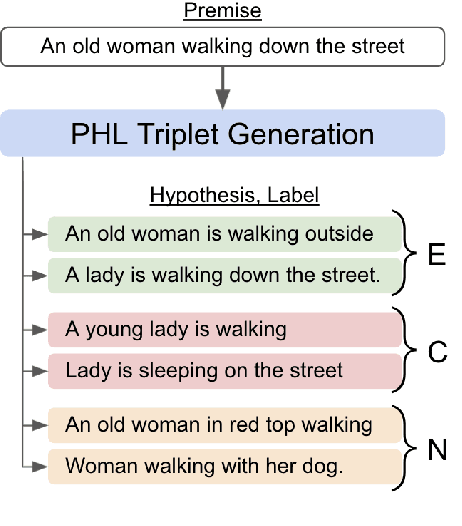

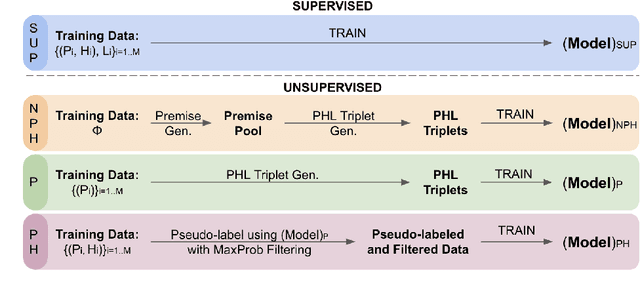
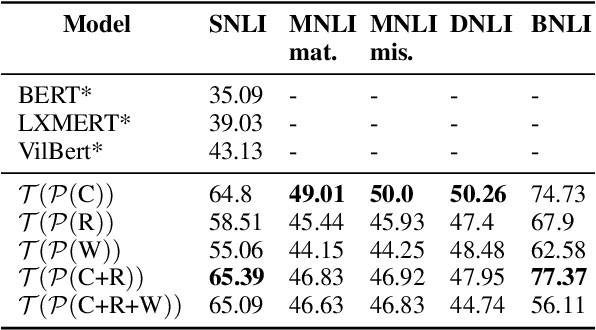
Transformer-based models have achieved impressive performance on various Natural Language Inference (NLI) benchmarks, when trained on respective training datasets. However, in certain cases, training samples may not be available or collecting them could be time-consuming and resource-intensive. In this work, we address this challenge and present an explorative study on unsupervised NLI, a paradigm in which no human-annotated training samples are available. We investigate NLI under three challenging settings: PH, P, and NPH that differ in the extent of unlabeled data available for learning. As a solution, we propose a procedural data generation approach that leverages a set of sentence transformations to collect PHL (Premise, Hypothesis, Label) triplets for training NLI models, bypassing the need for human-annotated training datasets. Comprehensive experiments show that this approach results in accuracies of 66.75%, 65.9%, 65.39% in PH, P, NPH settings respectively, outperforming all existing baselines. Furthermore, fine-tuning our models with as little as ~0.1% of the training dataset (500 samples) leads to 12.2% higher accuracy than the model trained from scratch on the same 500 instances.
Hybrid Transceiver Design for Tera-Hertz MIMO Systems Relying on Bayesian Learning Aided Sparse Channel Estimation
Sep 20, 2021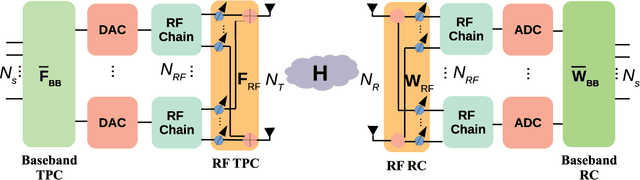
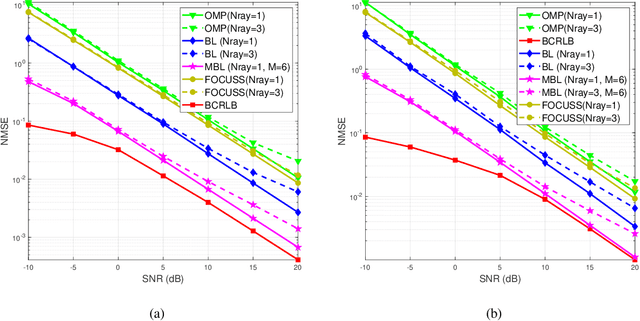
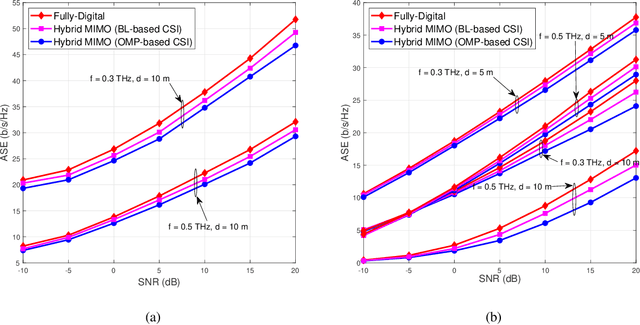
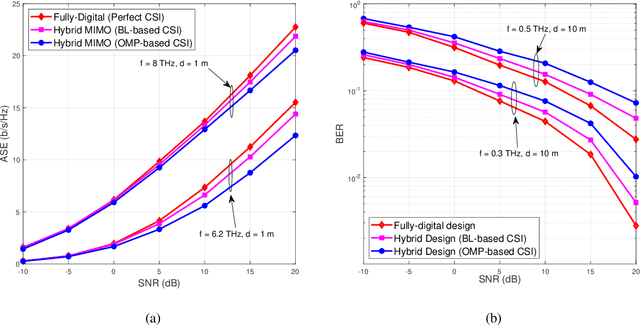
Hybrid transceiver design in multiple-input multiple-output (MIMO) Tera-Hertz (THz) systems relying on sparse channel state information (CSI) estimation techniques is conceived. To begin with, a practical MIMO channel model is developed for the THz band that incorporates its molecular absorption and reflection losses, as well as its non-line-of-sight (NLoS) rays associated with its diffused components. Subsequently, a novel CSI estimation model is derived by exploiting the angular-sparsity of the THz MIMO channel. Then an orthogonal matching pursuit (OMP)-based framework is conceived, followed by designing a sophisticated Bayesian learning (BL)-based approach for efficient estimation of the sparse THz MIMO channel. The Bayesian Cramer-Rao Lower Bound (BCRLB) is also determined for benchmarking the performance of the CSI estimation techniques developed. Finally, an optimal hybrid transmit precoder and receiver combiner pair is designed, which directly relies on the beamspace domain CSI estimates and only requires limited feedback. Finally, simulation results are provided for quantifying the improved mean square error (MSE), spectral-efficiency (SE) and bit-error rate (BER) performance for transmission on practical THz MIMO channel obtained from the HIgh resolution TRANsmission (HITRAN)-database.
Interviewer-Candidate Role Play: Towards Developing Real-World NLP Systems
Jul 01, 2021

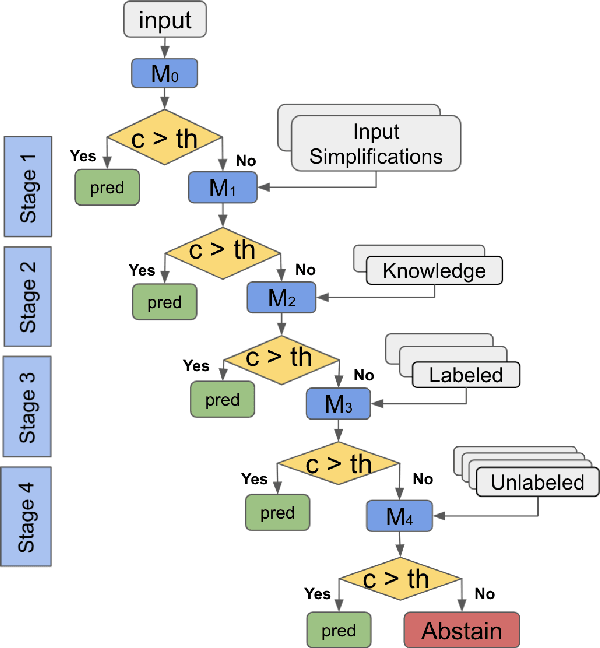

Standard NLP tasks do not incorporate several common real-world scenarios such as seeking clarifications about the question, taking advantage of clues, abstaining in order to avoid incorrect answers, etc. This difference in task formulation hinders the adoption of NLP systems in real-world settings. In this work, we take a step towards bridging this gap and present a multi-stage task that simulates a typical human-human questioner-responder interaction such as an interview. Specifically, the system is provided with question simplifications, knowledge statements, examples, etc. at various stages to improve its prediction when it is not sufficiently confident. We instantiate the proposed task in Natural Language Inference setting where a system is evaluated on both in-domain and out-of-domain (OOD) inputs. We conduct comprehensive experiments and find that the multi-stage formulation of our task leads to OOD generalization performance improvement up to 2.29% in Stage 1, 1.91% in Stage 2, 54.88% in Stage 3, and 72.02% in Stage 4 over the standard unguided prediction. However, our task leaves a significant challenge for NLP researchers to further improve OOD performance at each stage.
Can Transformers Reason About Effects of Actions?
Dec 17, 2020
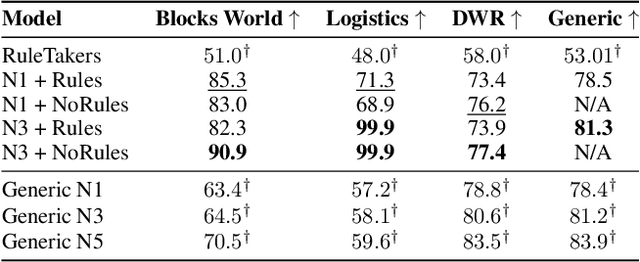
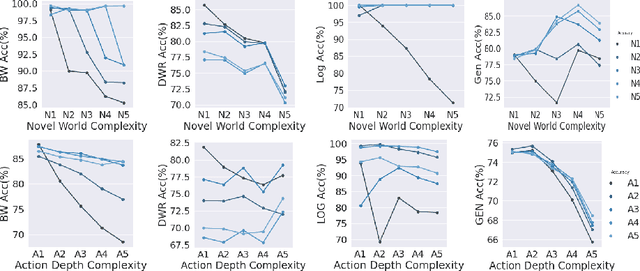
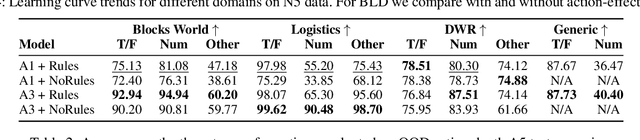
A recent work has shown that transformers are able to "reason" with facts and rules in a limited setting where the rules are natural language expressions of conjunctions of conditions implying a conclusion. Since this suggests that transformers may be used for reasoning with knowledge given in natural language, we do a rigorous evaluation of this with respect to a common form of knowledge and its corresponding reasoning -- the reasoning about effects of actions. Reasoning about action and change has been a top focus in the knowledge representation subfield of AI from the early days of AI and more recently it has been a highlight aspect in common sense question answering. We consider four action domains (Blocks World, Logistics, Dock-Worker-Robots and a Generic Domain) in natural language and create QA datasets that involve reasoning about the effects of actions in these domains. We investigate the ability of transformers to (a) learn to reason in these domains and (b) transfer that learning from the generic domains to the other domains.