 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalBench: Prototyping a Collaborative Benchmark for Legal Reasoning
Sep 13, 2022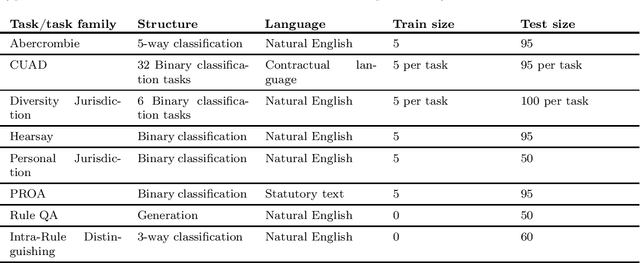
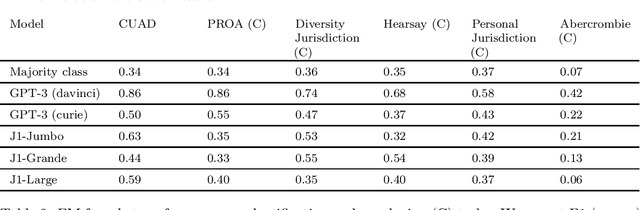

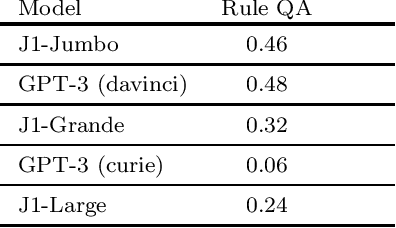
Can foundation models be guided to execute tasks involving legal reasoning? We believe that building a benchmark to answer this question will require sustained collaborative efforts between the computer science and legal communities. To that end, this short paper serves three purposes. First, we describe how IRAC-a framework legal scholars use to distinguish different types of legal reasoning-can guide the construction of a Foundation Model oriented benchmark. Second, we present a seed set of 44 tasks built according to this framework. We discuss initial findings, and highlight directions for new tasks. Finally-inspired by the Open Science movement-we make a call for the legal and computer science communities to join our efforts by contributing new tasks. This work is ongoing, and our progress can be tracked here: https://github.com/HazyResearch/legalbench.
Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset
Jul 01, 2022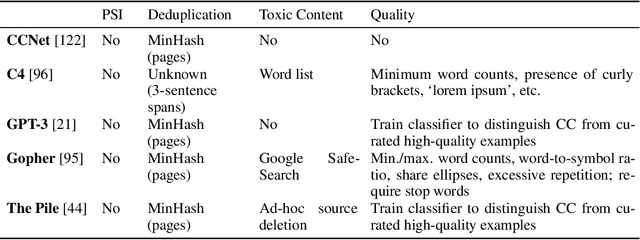
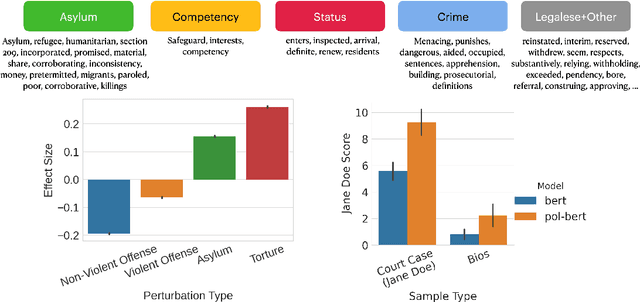
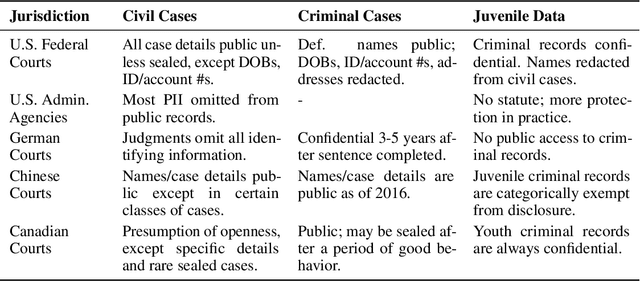
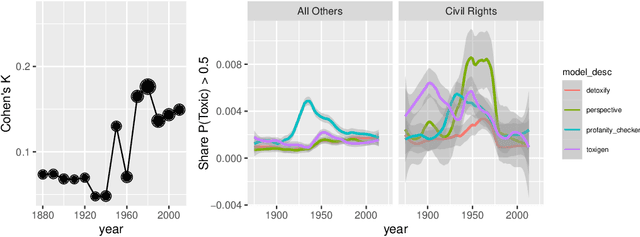
One concern with the rise of large language models lies with their potential for significant harm, particularly from pretraining on biased, obscene, copyrighted, and private information. Emerging ethical approaches have attempted to filter pretraining material, but such approaches have been ad hoc and failed to take into account context. We offer an approach to filtering grounded in law, which has directly addressed the tradeoffs in filtering material. First, we gather and make available the Pile of Law, a 256GB (and growing) dataset of open-source English-language legal and administrative data, covering court opinions, contracts, administrative rules, and legislative records. Pretraining on the Pile of Law may potentially help with legal tasks that have the promise to improve access to justice. Second, we distill the legal norms that governments have developed to constrain the inclusion of toxic or private content into actionable lessons for researchers and discuss how our dataset reflects these norms. Third, we show how the Pile of Law offers researchers the opportunity to learn such filtering rules directly from the data, providing an exciting new research direction in model-based processing.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset
May 17, 2021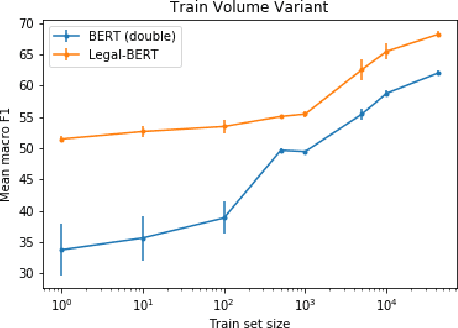
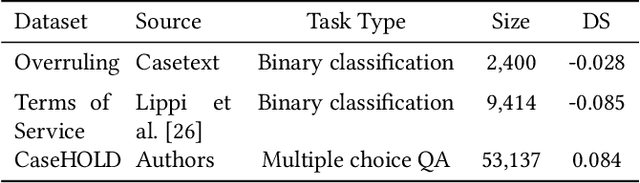
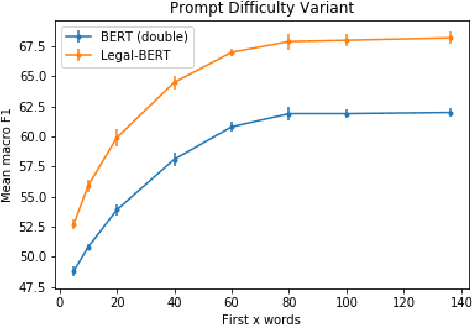

While self-supervised learning has made rapid advances in natural language processing, it remains unclear when researchers should engage in resource-intensive domain-specific pretraining (domain pretraining). The law, puzzlingly, has yielded few documented instances of substantial gains to domain pretraining in spite of the fact that legal language is widely seen to be unique. We hypothesize that these existing results stem from the fact that existing legal NLP tasks are too easy and fail to meet conditions for when domain pretraining can help. To address this, we first present CaseHOLD (Case Holdings On Legal Decisions), a new dataset comprised of over 53,000+ multiple choice questions to identify the relevant holding of a cited case. This dataset presents a fundamental task to lawyers and is both legally meaningful and difficult from an NLP perspective (F1 of 0.4 with a BiLSTM baseline). Second, we assess performance gains on CaseHOLD and existing legal NLP datasets. While a Transformer architecture (BERT) pretrained on a general corpus (Google Books and Wikipedia) improves performance, domain pretraining (using corpus of approximately 3.5M decisions across all courts in the U.S. that is larger than BERT's) with a custom legal vocabulary exhibits the most substantial performance gains with CaseHOLD (gain of 7.2% on F1, representing a 12% improvement on BERT) and consistent performance gains across two other legal tasks. Third, we show that domain pretraining may be warranted when the task exhibits sufficient similarity to the pretraining corpus: the level of performance increase in three legal tasks was directly tied to the domain specificity of the task. Our findings inform when researchers should engage resource-intensive pretraining and show that Transformer-based architectures, too, learn embeddings suggestive of distinct legal language.
Bootleg: Chasing the Tail with Self-Supervised Named Entity Disambiguation
Oct 23, 2020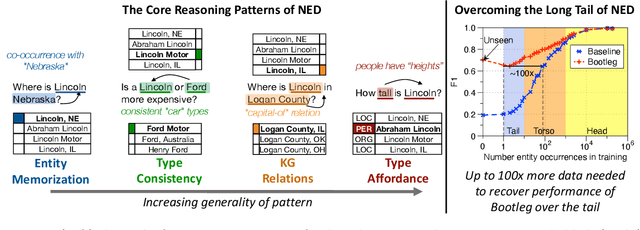
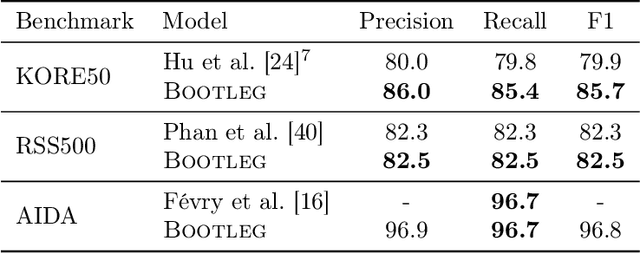
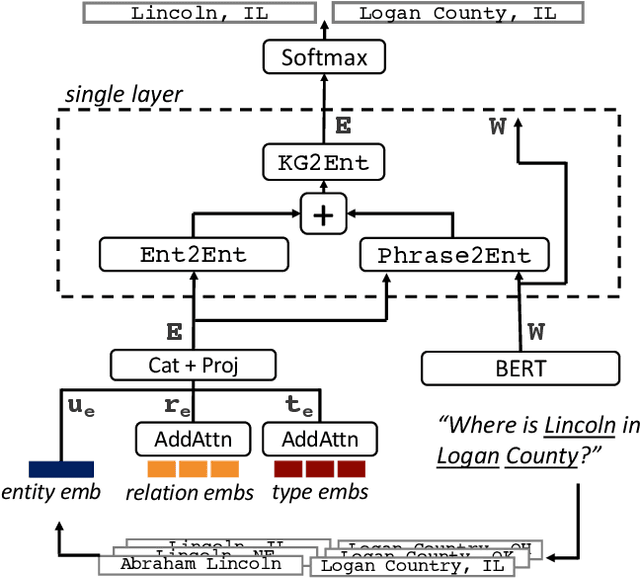
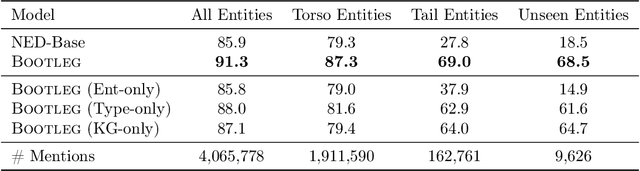
A challenge for named entity disambiguation (NED), the task of mapping textual mentions to entities in a knowledge base, is how to disambiguate entities that appear rarely in the training data, termed tail entities. Humans use subtle reasoning patterns based on knowledge of entity facts, relations, and types to disambiguate unfamiliar entities. Inspired by these patterns, we introduce Bootleg, a self-supervised NED system that is explicitly grounded in reasoning patterns for disambiguation. We define core reasoning patterns for disambiguation, create a learning procedure to encourage the self-supervised model to learn the patterns, and show how to use weak supervision to enhance the signals in the training data. Encoding the reasoning patterns in a simple Transformer architecture, Bootleg meets or exceeds state-of-the-art on three NED benchmarks. We further show that the learned representations from Bootleg successfully transfer to other non-disambiguation tasks that require entity-based knowledge: we set a new state-of-the-art in the popular TACRED relation extraction task by 1.0 F1 points and demonstrate up to 8% performance lift in highly optimized production search and assistant tasks at a major technology company
Machine Learning for AC Optimal Power Flow
Oct 19, 2019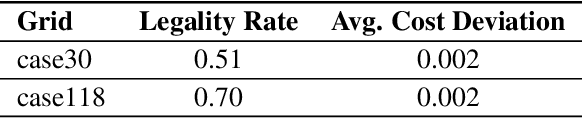

We explore machine learning methods for AC Optimal Powerflow (ACOPF) - the task of optimizing power generation in a transmission network according while respecting physical and engineering constraints. We present two formulations of ACOPF as a machine learning problem: 1) an end-to-end prediction task where we directly predict the optimal generator settings, and 2) a constraint prediction task where we predict the set of active constraints in the optimal solution. We validate these approaches on two benchmark grids.
One-Shot Federated Learning
Mar 05, 2019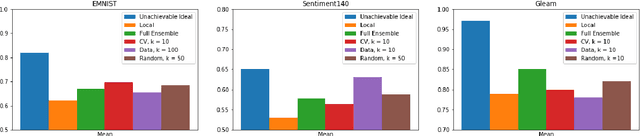

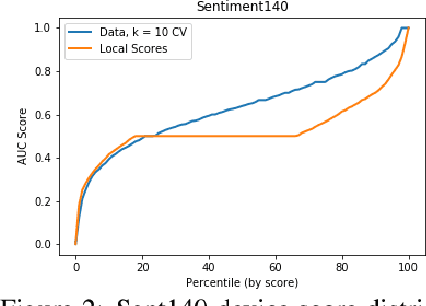
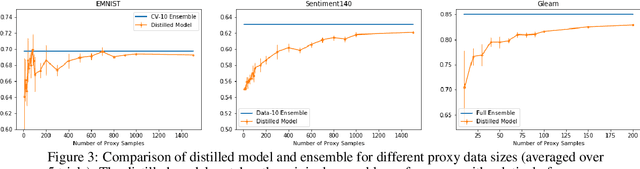
We present one-shot federated learning, where a central server learns a global model over a network of federated devices in a single round of communication. Our approach - drawing on ensemble learning and knowledge aggregation - achieves an average relative gain of 51.5% in AUC over local baselines and comes within 90.1% of the (unattainable) global ideal. We discuss these methods and identify several promising directions of future work.
Knowledge Aggregation via Good-Enough Model Spaces
Oct 03, 2018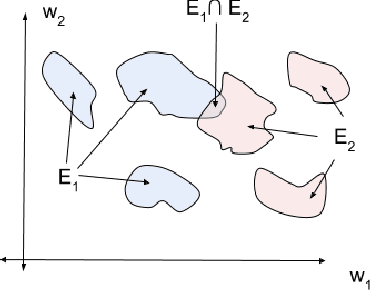
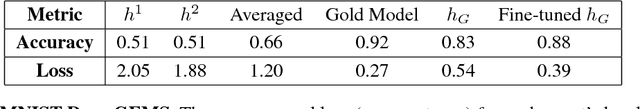

In many practical applications, the training data for a machine learning task is partitioned across multiple learners. In many such cases, aggregating all the data onto a single device for model training may not be possible for privacy and communications bandwidth reasons. Existing approaches for learning global models in these settings iteratively aggregate local updates from each learner. These approaches can require many rounds of communication between learners and may produce suboptimal results when the data distribution is extremely non-i.i.d. In this work, we present Good-Enough Model Spaces (GEMS), a framework for learning a global satisficing (i.e. "good-enough") model by considering the space of local learners satisficing models. Our approach does not require sharing of data between learners, makes no assumptions on the distribution of data across learners, and requires minimal communication between learners. We present methods for learning both shallow and deep models within this framework and discuss how hold-out data can be used for post-learning fine-tuning. We find our approaches perform comparably to non-distributed models on experiments in image recognition and sentiment analysis.