 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIL: Gradient-Reweighted Advantages for Reinforcement Learning with Verifiable Rewards
Jun 03, 2026Reinforcement learning with verifiable rewards (e.g. GRPO) is now a common way to improve mathematical reasoning in Large Language Models (LLMs). However, current methods usually broadcast one sequence-level advantage to all tokens, or use costly process reward models (PRMs) for step-level supervision. Uniform advantage distribution assumes that all tokens contribute equally to the final reward. This dilutes the gradient signal, since flawed reasoning steps and filler words are updated as strongly as valid logical inferences. To address this, we introduce Gradient-Reweighted Advantage (GRAIL), an intrinsic token-wise advantage reweighting method. GRAIL uses gradient-activation saliency to place more weight on tokens that are more locally sensitive to the final answer. Evaluations across five models from the Qwen3, R1-distilled and OctoThinker families show that GRAIL consistently outperforms GRPO. GRAIL achieved an average improvement of 3.60% in accuracy and 3.05% in Pass@3, demonstrating that fine-grained reasoning alignment can be achieved without process-level supervision.
Lessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025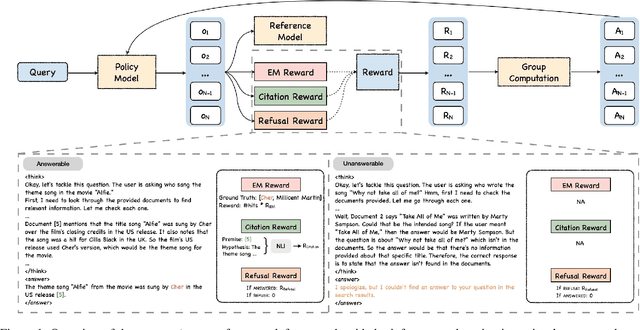
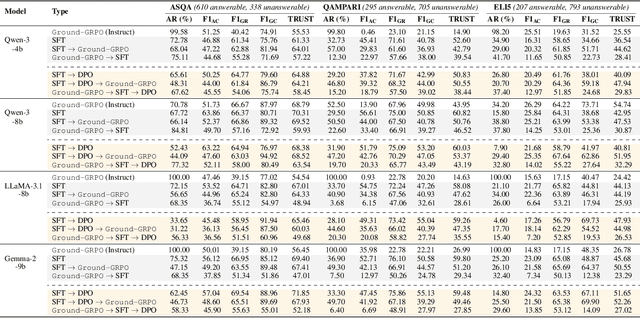
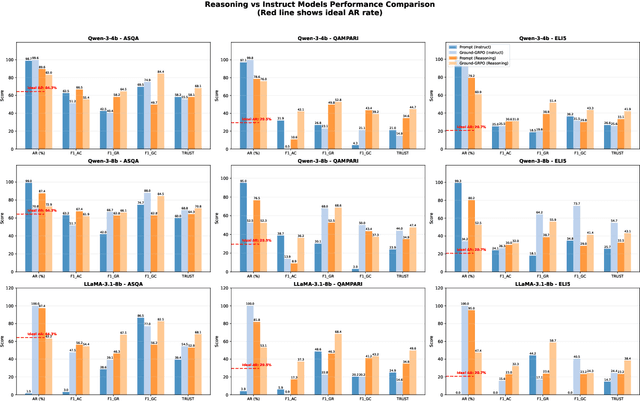
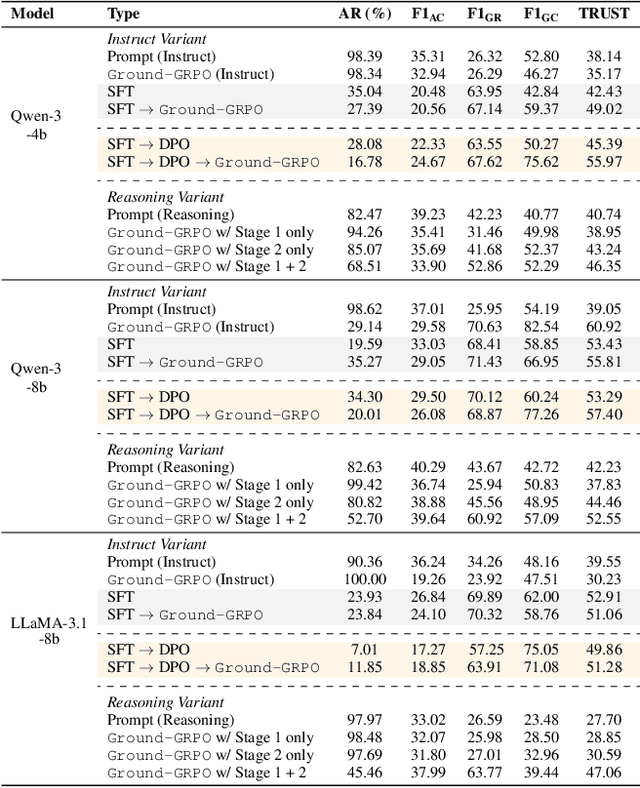
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
Emma-X: An Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning
Dec 17, 2024Traditional reinforcement learning-based robotic control methods are often task-specific and fail to generalize across diverse environments or unseen objects and instructions. Visual Language Models (VLMs) demonstrate strong scene understanding and planning capabilities but lack the ability to generate actionable policies tailored to specific robotic embodiments. To address this, Visual-Language-Action (VLA) models have emerged, yet they face challenges in long-horizon spatial reasoning and grounded task planning. In this work, we propose the Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning, Emma-X. Emma-X leverages our constructed hierarchical embodiment dataset based on BridgeV2, containing 60,000 robot manipulation trajectories auto-annotated with grounded task reasoning and spatial guidance. Additionally, we introduce a trajectory segmentation strategy based on gripper states and motion trajectories, which can help mitigate hallucination in grounding subtask reasoning generation. Experimental results demonstrate that Emma-X achieves superior performance over competitive baselines, particularly in real-world robotic tasks requiring spatial reasoning.
VerityMath: Advancing Mathematical Reasoning by Self-Verification Through Unit Consistency
Nov 13, 2023



Large Language Models (LLMs) combined with program-based solving techniques are increasingly demonstrating proficiency in mathematical reasoning. However, such progress is mostly demonstrated in closed-source models such as OpenAI-GPT4 and Claude. In this paper, we seek to study the performance of strong open-source LLMs. Specifically, we analyze the outputs of Code Llama (7B) when applied to math word problems. We identify a category of problems that pose a challenge for the model, particularly those involving quantities that span multiple types or units. To address this issue, we propose a systematic approach by defining units for each quantity and ensuring the consistency of these units during mathematical operations. We developed Unit Consistency Programs (UCPs), an annotated dataset of math word problems, each paired with programs that contain unit specifications and unit verification routines. Finally, we finetune the Code Llama (7B) model with UCPs to produce VerityMath and present our preliminary findings.