 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025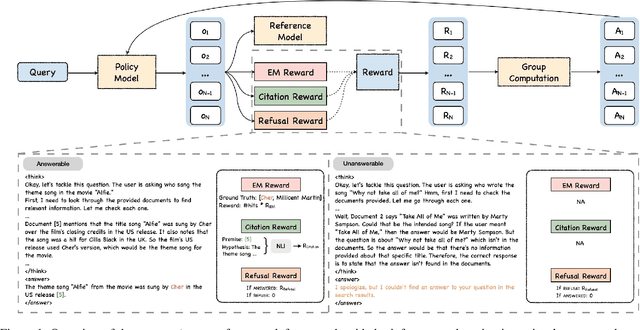
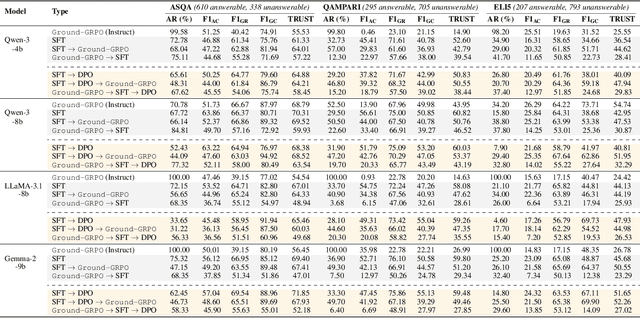
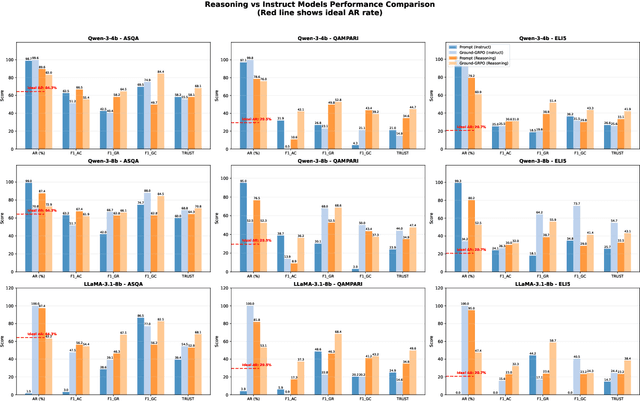
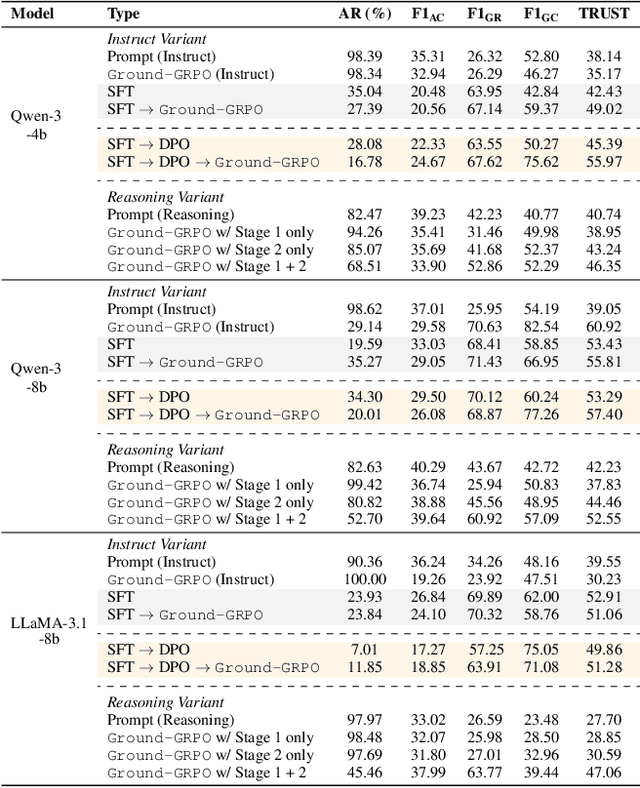
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
Evaluating the Generation of Spatial Relations in Text and Image Generative Models
Nov 12, 2024



Understanding spatial relations is a crucial cognitive ability for both humans and AI. While current research has predominantly focused on the benchmarking of text-to-image (T2I) models, we propose a more comprehensive evaluation that includes \textit{both} T2I and Large Language Models (LLMs). As spatial relations are naturally understood in a visuo-spatial manner, we develop an approach to convert LLM outputs into an image, thereby allowing us to evaluate both T2I models and LLMs \textit{visually}. We examined the spatial relation understanding of 8 prominent generative models (3 T2I models and 5 LLMs) on a set of 10 common prepositions, as well as assess the feasibility of automatic evaluation methods. Surprisingly, we found that T2I models only achieve subpar performance despite their impressive general image-generation abilities. Even more surprisingly, our results show that LLMs are significantly more accurate than T2I models in generating spatial relations, despite being primarily trained on textual data. We examined reasons for model failures and highlight gaps that can be filled to enable more spatially faithful generations.
Measuring and Enhancing Trustworthiness of LLMs in RAG through Grounded Attributions and Learning to Refuse
Sep 17, 2024



LLMs are an integral part of retrieval-augmented generation (RAG) systems. While many studies focus on evaluating the quality of end-to-end RAG systems, there is a lack of research on understanding the appropriateness of an LLM for the RAG task. Thus, we introduce a new metric, Trust-Score, that provides a holistic evaluation of the trustworthiness of LLMs in an RAG framework. We show that various prompting methods, such as in-context learning, fail to adapt LLMs effectively to the RAG task. Thus, we propose Trust-Align, a framework to align LLMs for higher Trust-Score. LLaMA-3-8b, aligned with our method, significantly outperforms open-source LLMs of comparable sizes on ASQA (up 10.7), QAMPARI (up 29.2) and ELI5 (up 14.9). We release our code at: https://github.com/declare-lab/trust-align.