 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale MLPerf-0.6 models on Google TPU-v3 Pods
Oct 02, 2019
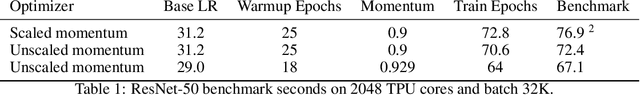

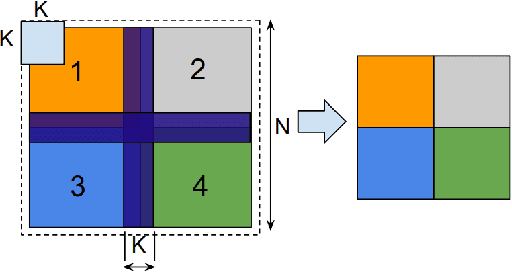
The recent submission of Google TPU-v3 Pods to the industry wide MLPerf v0.6 training benchmark demonstrates the scalability of a suite of industry relevant ML models. MLPerf defines a suite of models, datasets and rules to follow when benchmarking to ensure results are comparable across hardware, frameworks and companies. Using this suite of models, we discuss the optimizations and techniques including choice of optimizer, spatial partitioning and weight update sharding necessary to scale to 1024 TPU chips. Furthermore, we identify properties of models that make scaling them challenging, such as limited data parallelism and unscaled weights. These optimizations contribute to record performance in transformer, Resnet-50 and SSD in the Google MLPerf-0.6 submission.
Multimodal Representation Learning using Deep Multiset Canonical Correlation
Apr 03, 2019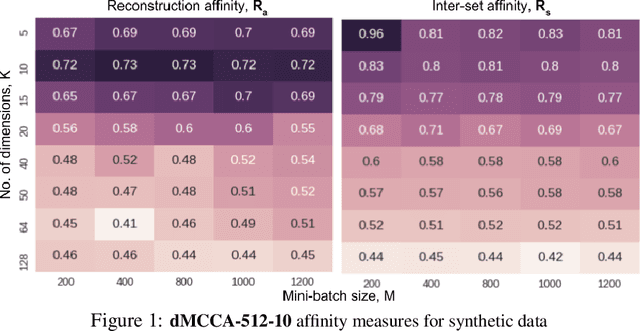
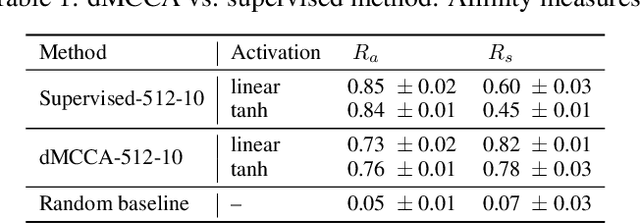
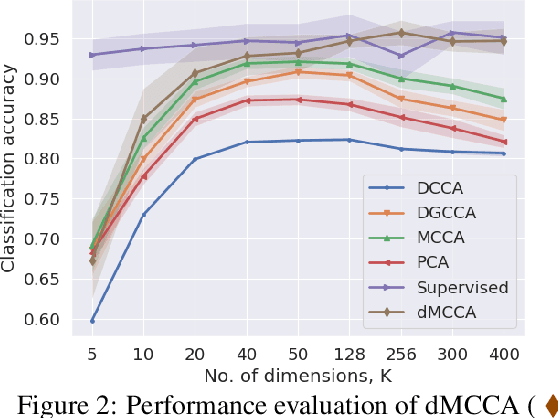
We propose Deep Multiset Canonical Correlation Analysis (dMCCA) as an extension to representation learning using CCA when the underlying signal is observed across multiple (more than two) modalities. We use deep learning framework to learn non-linear transformations from different modalities to a shared subspace such that the representations maximize the ratio of between- and within-modality covariance of the observations. Unlike linear discriminant analysis, we do not need class information to learn these representations, and we show that this model can be trained for complex data using mini-batches. Using synthetic data experiments, we show that dMCCA can effectively recover the common signal across the different modalities corrupted by multiplicative and additive noise. We also analyze the sensitivity of our model to recover the correlated components with respect to mini-batch size and dimension of the embeddings. Performance evaluation on noisy handwritten datasets shows that our model outperforms other CCA-based approaches and is comparable to deep neural network models trained end-to-end on this dataset.
Device Placement Optimization with Reinforcement Learning
Jun 25, 2017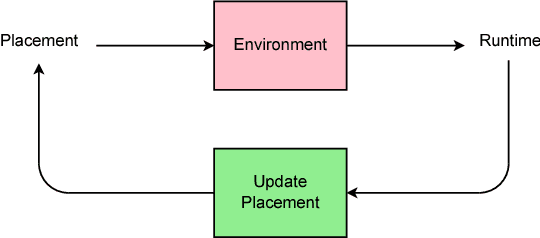
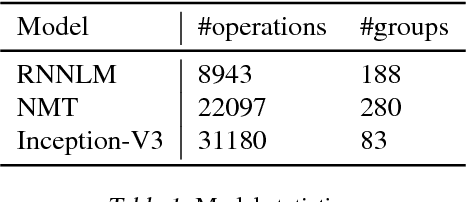
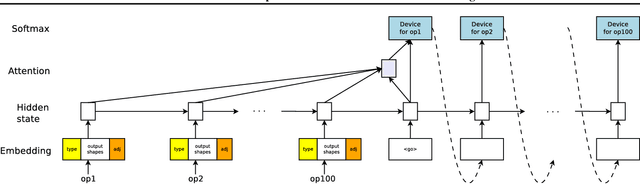
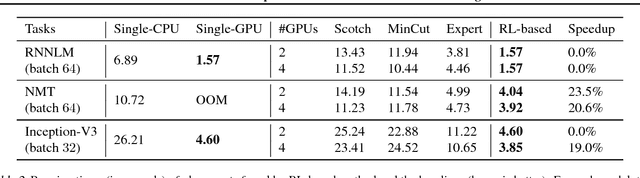
The past few years have witnessed a growth in size and computational requirements for training and inference with neural networks. Currently, a common approach to address these requirements is to use a heterogeneous distributed environment with a mixture of hardware devices such as CPUs and GPUs. Importantly, the decision of placing parts of the neural models on devices is often made by human experts based on simple heuristics and intuitions. In this paper, we propose a method which learns to optimize device placement for TensorFlow computational graphs. Key to our method is the use of a sequence-to-sequence model to predict which subsets of operations in a TensorFlow graph should run on which of the available devices. The execution time of the predicted placements is then used as the reward signal to optimize the parameters of the sequence-to-sequence model. Our main result is that on Inception-V3 for ImageNet classification, and on RNN LSTM, for language modeling and neural machine translation, our model finds non-trivial device placements that outperform hand-crafted heuristics and traditional algorithmic methods.