 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt or Forget: Provable Tradeoffs Between Adam and SGD in Nonstationary Optimization
May 05, 2026We provide a theoretical analysis of Adam under non-stationary stochastic objectives, separating two regimes: Euclidean tracking under adaptive strong monotonicity of the Adam-preconditioned mean-gradient operator, and high-probability projected stationarity guarantees under general $L$-smooth objectives. In the tracking regime, we derive finite-time expected and high-probability bounds that decompose sharply into four components: initialization, objective drift, a first-moment tracking error governed by $β_1$, and a preconditioner perturbation governed by $β_2$. We characterize the burn-in time to reach Adam's irreducible tracking floor under constant and step-decay schedules. We also prove a high-probability bound on the average projected stationarity gap for Adam under distribution shift. Across both analyses, our bounds reveal a noise--drift tradeoff: in noise-dominated regimes, first-moment averaging and adaptive preconditioning can improve the high-probability error, whereas in drift-dominated regimes, stale first-moment information and preconditioner perturbations can compound the cost of nonstationarity, allowing vanilla SGD to achieve a smaller tracking floor. Our explicit $(β_1,β_2,ε)$-dependent bounds delineate when adaptive step-sizing is beneficial versus harmful, and provide a theoretical mechanism for Adam's empirical instability and stabilization under distribution shift.
On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization
Jan 21, 2026While momentum-based acceleration has been studied extensively in deterministic optimization problems, its behavior in nonstationary environments -- where the data distribution and optimal parameters drift over time -- remains underexplored. We analyze the tracking performance of Stochastic Gradient Descent (SGD) and its momentum variants (Polyak heavy-ball and Nesterov) under uniform strong convexity and smoothness in varying stepsize regimes. We derive finite-time bounds in expectation and with high probability for the tracking error, establishing a sharp decomposition into three components: a transient initialization term, a noise-induced variance term, and a drift-induced tracking lag. Crucially, our analysis uncovers a fundamental trade-off: while momentum can suppress gradient noise, it incurs an explicit penalty on the tracking capability. We show that momentum can substantially amplify drift-induced tracking error, with amplification that becomes unbounded as the momentum parameter approaches one, formalizing the intuition that using 'stale' gradients hinders adaptation to rapid regime shifts. Complementing these upper bounds, we establish minimax lower bounds for dynamic regret under gradient-variation constraints. These lower bounds prove that the inertia-induced penalty is not an artifact of analysis but an information-theoretic barrier: in drift-dominated regimes, momentum creates an unavoidable 'inertia window' that fundamentally degrades performance. Collectively, these results provide a definitive theoretical grounding for the empirical instability of momentum in dynamic environments and delineate the precise regime boundaries where SGD provably outperforms its accelerated counterparts.
Data-adaptive Transfer Learning for Translation: A Case Study in Haitian and Jamaican
Sep 13, 2022
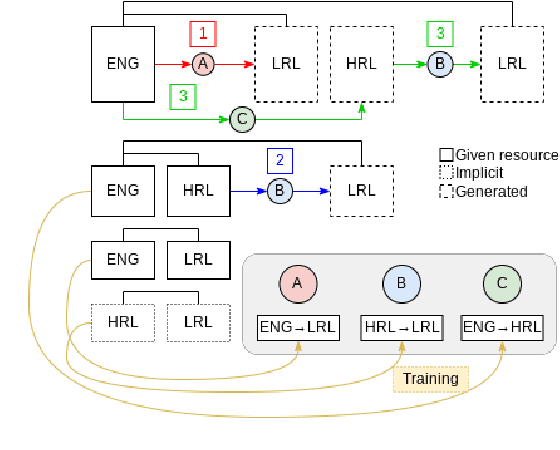
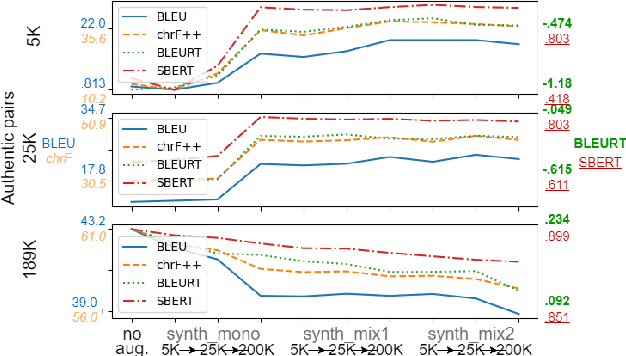
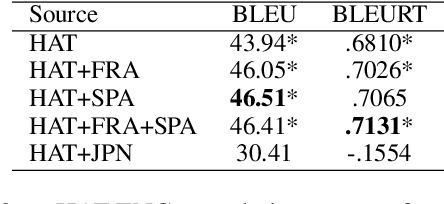
Multilingual transfer techniques often improve low-resource machine translation (MT). Many of these techniques are applied without considering data characteristics. We show in the context of Haitian-to-English translation that transfer effectiveness is correlated with amount of training data and relationships between knowledge-sharing languages. Our experiments suggest that for some languages beyond a threshold of authentic data, back-translation augmentation methods are counterproductive, while cross-lingual transfer from a sufficiently related language is preferred. We complement this finding by contributing a rule-based French-Haitian orthographic and syntactic engine and a novel method for phonological embedding. When used with multilingual techniques, orthographic transformation makes statistically significant improvements over conventional methods. And in very low-resource Jamaican MT, code-switching with a transfer language for orthographic resemblance yields a 6.63 BLEU point advantage.