 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoFlowGAN: Co-training for Stereo and Flow with Unsupervised Domain Adaptation
Sep 04, 2023



We introduce a novel training strategy for stereo matching and optical flow estimation that utilizes image-to-image translation between synthetic and real image domains. Our approach enables the training of models that excel in real image scenarios while relying solely on ground-truth information from synthetic images. To facilitate task-agnostic domain adaptation and the training of task-specific components, we introduce a bidirectional feature warping module that handles both left-right and forward-backward directions. Experimental results show competitive performance over previous domain translation-based methods, which substantiate the efficacy of our proposed framework, effectively leveraging the benefits of unsupervised domain adaptation, stereo matching, and optical flow estimation.
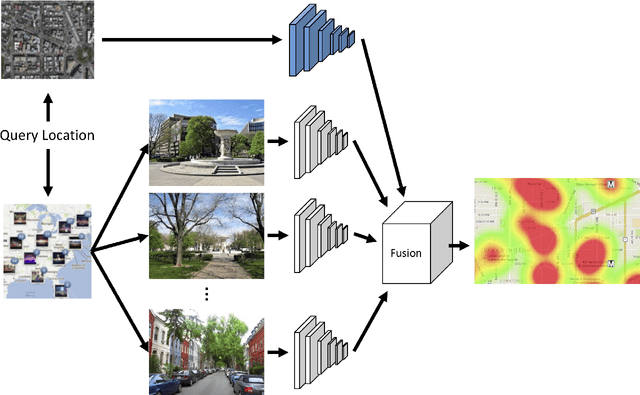
Sat2Cap: Mapping Fine-Grained Textual Descriptions from Satellite Images
Jul 29, 2023



We propose a novel weakly supervised approach for creating maps using free-form textual descriptions (or captions). We refer to this new line of work of creating textual maps as zero-shot mapping. Prior works have approached mapping tasks by developing models that predict over a fixed set of attributes using overhead imagery. However, these models are very restrictive as they can only solve highly specific tasks for which they were trained. Mapping text, on the other hand, allows us to solve a large variety of mapping problems with minimal restrictions. To achieve this, we train a contrastive learning framework called Sat2Cap on a new large-scale dataset of paired overhead and ground-level images. For a given location, our model predicts the expected CLIP embedding of the ground-level scenery. Sat2Cap is also conditioned on temporal information, enabling it to learn dynamic concepts that vary over time. Our experimental results demonstrate that our models successfully capture fine-grained concepts and effectively adapt to temporal variations. Our approach does not require any text-labeled data making the training easily scalable. The code, dataset, and models will be made publicly available.
Fine-Grained Property Value Assessment using Probabilistic Disaggregation
May 31, 2023The monetary value of a given piece of real estate, a parcel, is often readily available from a geographic information system. However, for many applications, such as insurance and urban planning, it is useful to have estimates of property value at much higher spatial resolutions. We propose a method to estimate the distribution over property value at the pixel level from remote sensing imagery. We evaluate on a real-world dataset of a major urban area. Our results show that the proposed approaches are capable of generating fine-level estimates of property values, significantly improving upon a diverse collection of baseline approaches.
A Visual Active Search Framework for Geospatial Exploration
Nov 28, 2022Many problems can be viewed as forms of geospatial search aided by aerial imagery, with examples ranging from detecting poaching activity to human trafficking. We model this class of problems in a visual active search (VAS) framework, which takes as input an image of a broad area, and aims to identify as many examples of a target object as possible. It does this through a limited sequence of queries, each of which verifies whether an example is present in a given region. We propose a reinforcement learning approach for VAS that leverages a collection of fully annotated search tasks as training data to learn a search policy, and combines features of the input image with a natural representation of active search state. Additionally, we propose domain adaptation techniques to improve the policy at decision time when training data is not fully reflective of the test-time distribution of VAS tasks. Through extensive experiments on several satellite imagery datasets, we show that the proposed approach significantly outperforms several strong baselines. Code and data will be made public.
Geo-Information Harvesting from Social Media Data
Nov 01, 2022As unconventional sources of geo-information, massive imagery and text messages from open platforms and social media form a temporally quasi-seamless, spatially multi-perspective stream, but with unknown and diverse quality. Due to its complementarity to remote sensing data, geo-information from these sources offers promising perspectives, but harvesting is not trivial due to its data characteristics. In this article, we address key aspects in the field, including data availability, analysis-ready data preparation and data management, geo-information extraction from social media text messages and images, and the fusion of social media and remote sensing data. We then showcase some exemplary geographic applications. In addition, we present the first extensive discussion of ethical considerations of social media data in the context of geo-information harvesting and geographic applications. With this effort, we wish to stimulate curiosity and lay the groundwork for researchers who intend to explore social media data for geo-applications. We encourage the community to join forces by sharing their code and data.
Causality for Inherently Explainable Transformers: CAT-XPLAIN
Jun 29, 2022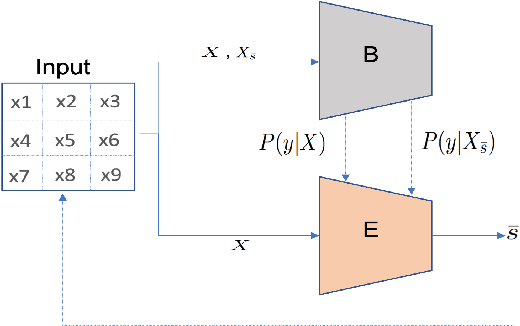
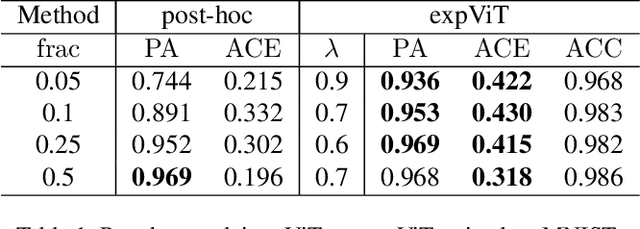
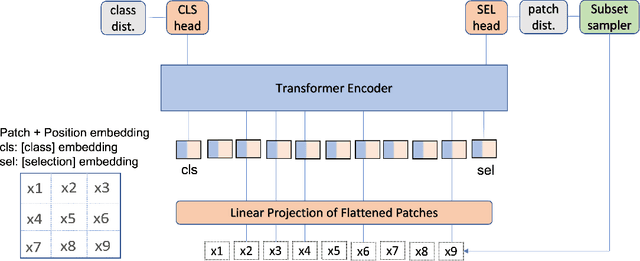
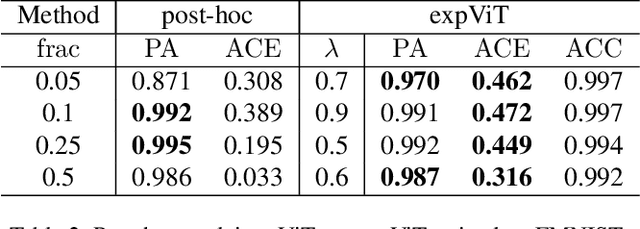
There have been several post-hoc explanation approaches developed to explain pre-trained black-box neural networks. However, there is still a gap in research efforts toward designing neural networks that are inherently explainable. In this paper, we utilize a recently proposed instance-wise post-hoc causal explanation method to make an existing transformer architecture inherently explainable. Once trained, our model provides an explanation in the form of top-$k$ regions in the input space of the given instance contributing to its decision. We evaluate our method on binary classification tasks using three image datasets: MNIST, FMNIST, and CIFAR. Our results demonstrate that compared to the causality-based post-hoc explainer model, our inherently explainable model achieves better explainability results while eliminating the need of training a separate explainer model. Our code is available at https://github.com/mvrl/CAT-XPLAIN.
Revisiting Near/Remote Sensing with Geospatial Attention
Apr 04, 2022

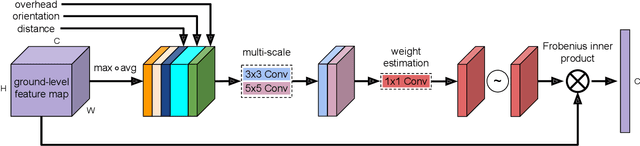
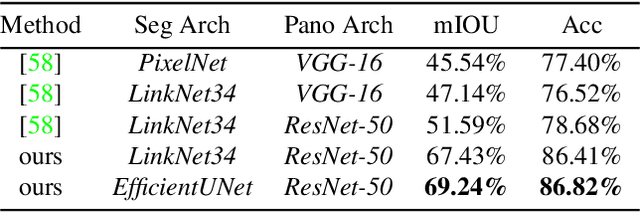
This work addresses the task of overhead image segmentation when auxiliary ground-level images are available. Recent work has shown that performing joint inference over these two modalities, often called near/remote sensing, can yield significant accuracy improvements. Extending this line of work, we introduce the concept of geospatial attention, a geometry-aware attention mechanism that explicitly considers the geospatial relationship between the pixels in a ground-level image and a geographic location. We propose an approach for computing geospatial attention that incorporates geometric features and the appearance of the overhead and ground-level imagery. We introduce a novel architecture for near/remote sensing that is based on geospatial attention and demonstrate its use for five segmentation tasks. The results demonstrate that our method significantly outperforms the previous state-of-the-art methods.
Dynamic Feature Alignment for Semi-supervised Domain Adaptation
Oct 18, 2021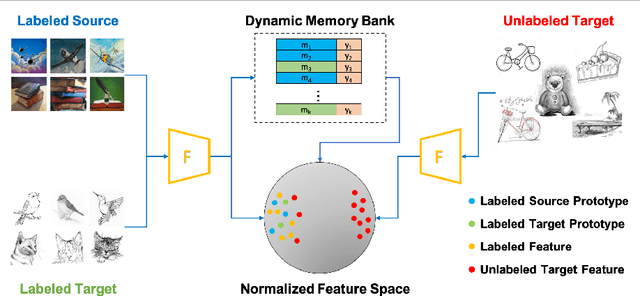
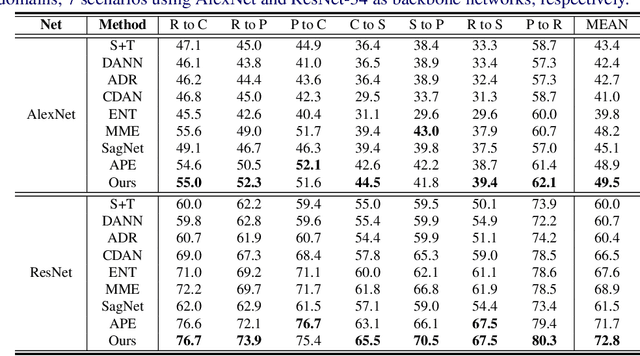
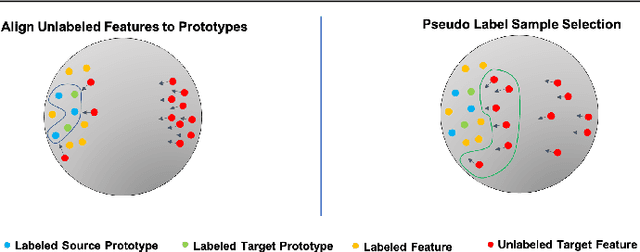
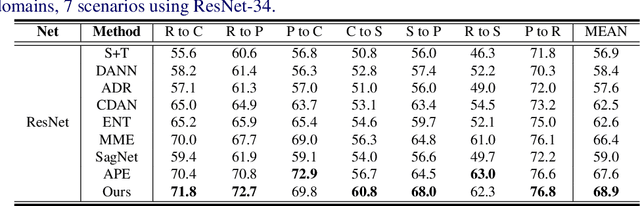
Most research on domain adaptation has focused on the purely unsupervised setting, where no labeled examples in the target domain are available. However, in many real-world scenarios, a small amount of labeled target data is available and can be used to improve adaptation. We address this semi-supervised setting and propose to use dynamic feature alignment to address both inter- and intra-domain discrepancy. Unlike previous approaches, which attempt to align source and target features within a mini-batch, we propose to align the target features to a set of dynamically updated class prototypes, which we use both for minimizing divergence and pseudo-labeling. By updating based on class prototypes, we avoid problems that arise in previous approaches due to class imbalances. Our approach, which doesn't require extensive tuning or adversarial training, significantly improves the state of the art for semi-supervised domain adaptation. We provide a quantitative evaluation on two standard datasets, DomainNet and Office-Home, and performance analysis.
Intensity Harmonization for Airborne LiDAR
May 04, 2021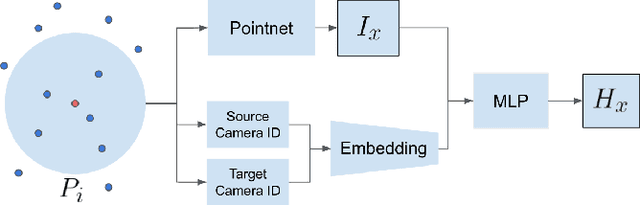
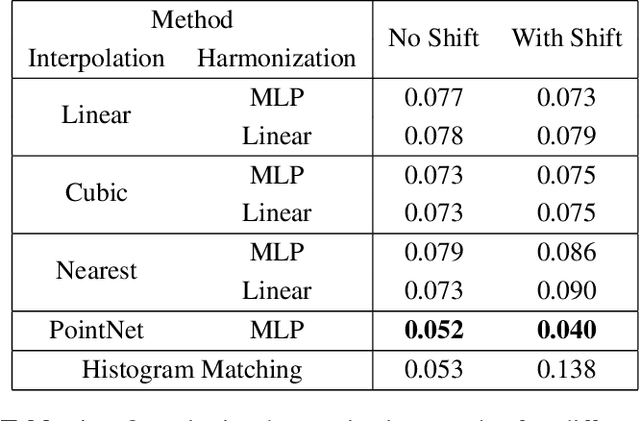

Constructing a point cloud for a large geographic region, such as a state or country, can require multiple years of effort. Often several vendors will be used to acquire LiDAR data, and a single region may be captured by multiple LiDAR scans. A key challenge is maintaining consistency between these scans, which includes point density, number of returns, and intensity. Intensity in particular can be very different between scans, even in areas that are overlapping. Harmonizing the intensity between scans to remove these discrepancies is expensive and time consuming. In this paper, we propose a novel method for point cloud harmonization based on deep neural networks. We evaluate our method quantitatively and qualitatively using a high quality real world LiDAR dataset. We compare our method to several baselines, including standard interpolation methods as well as histogram matching. We show that our method performs as well as the best baseline in areas with similar intensity distributions, and outperforms all baselines in areas with different intensity distributions. Source code is available at https://github.com/mvrl/lidar-harmonization .
Towards a Collective Agenda on AI for Earth Science Data Analysis
Apr 11, 2021
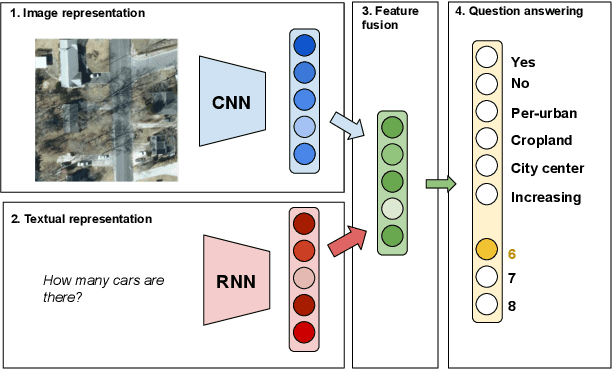

In the last years we have witnessed the fields of geosciences and remote sensing and artificial intelligence to become closer. Thanks to both the massive availability of observational data, improved simulations, and algorithmic advances, these disciplines have found common objectives and challenges to advance the modeling and understanding of the Earth system. Despite such great opportunities, we also observed a worrying tendency to remain in disciplinary comfort zones applying recent advances from artificial intelligence on well resolved remote sensing problems. Here we take a position on research directions where we think the interface between these fields will have the most impact and become potential game changers. In our declared agenda for AI on Earth sciences, we aim to inspire researchers, especially the younger generations, to tackle these challenges for a real advance of remote sensing and the geosciences.