 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ-Forcing: Training Stochastic Recurrent Networks
Nov 16, 2017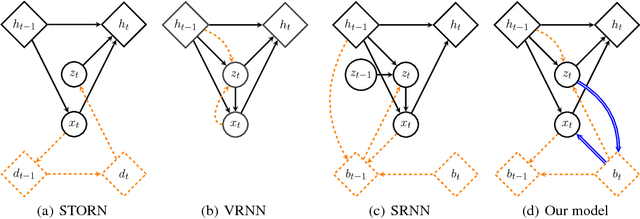
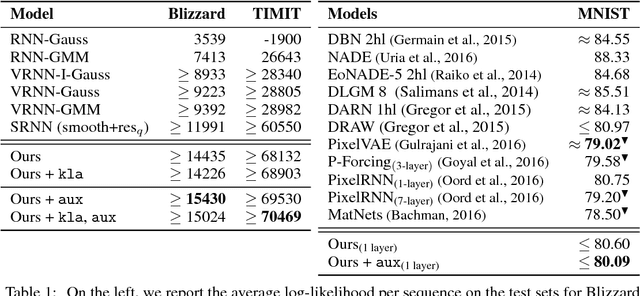

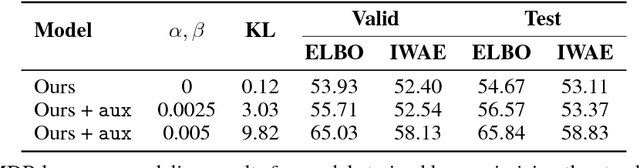
Many efforts have been devoted to training generative latent variable models with autoregressive decoders, such as recurrent neural networks (RNN). Stochastic recurrent models have been successful in capturing the variability observed in natural sequential data such as speech. We unify successful ideas from recently proposed architectures into a stochastic recurrent model: each step in the sequence is associated with a latent variable that is used to condition the recurrent dynamics for future steps. Training is performed with amortized variational inference where the approximate posterior is augmented with a RNN that runs backward through the sequence. In addition to maximizing the variational lower bound, we ease training of the latent variables by adding an auxiliary cost which forces them to reconstruct the state of the backward recurrent network. This provides the latent variables with a task-independent objective that enhances the performance of the overall model. We found this strategy to perform better than alternative approaches such as KL annealing. Although being conceptually simple, our model achieves state-of-the-art results on standard speech benchmarks such as TIMIT and Blizzard and competitive performance on sequential MNIST. Finally, we apply our model to language modeling on the IMDB dataset where the auxiliary cost helps in learning interpretable latent variables. Source Code: \url{https://github.com/anirudh9119/zforcing_nips17}
ACtuAL: Actor-Critic Under Adversarial Learning
Nov 13, 2017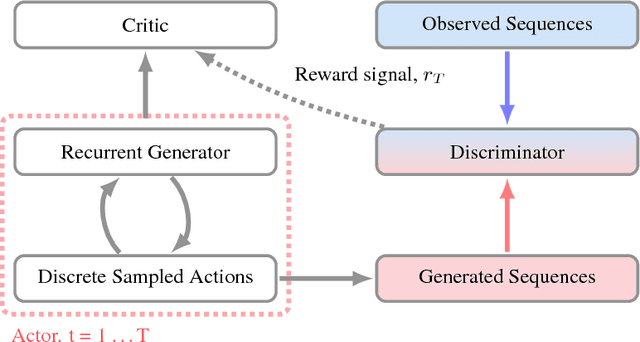
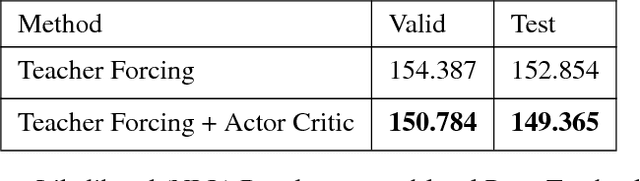
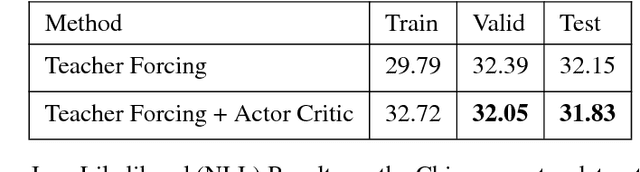

Generative Adversarial Networks (GANs) are a powerful framework for deep generative modeling. Posed as a two-player minimax problem, GANs are typically trained end-to-end on real-valued data and can be used to train a generator of high-dimensional and realistic images. However, a major limitation of GANs is that training relies on passing gradients from the discriminator through the generator via back-propagation. This makes it fundamentally difficult to train GANs with discrete data, as generation in this case typically involves a non-differentiable function. These difficulties extend to the reinforcement learning setting when the action space is composed of discrete decisions. We address these issues by reframing the GAN framework so that the generator is no longer trained using gradients through the discriminator, but is instead trained using a learned critic in the actor-critic framework with a Temporal Difference (TD) objective. This is a natural fit for sequence modeling and we use it to achieve improvements on language modeling tasks over the standard Teacher-Forcing methods.
Sparse Attentive Backtracking: Long-Range Credit Assignment in Recurrent Networks
Nov 07, 2017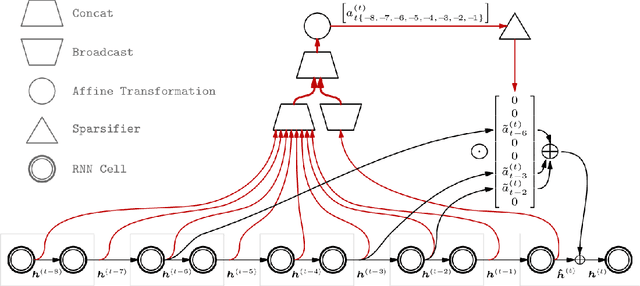
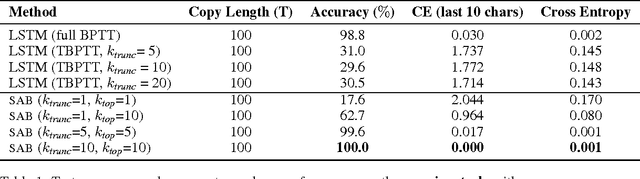
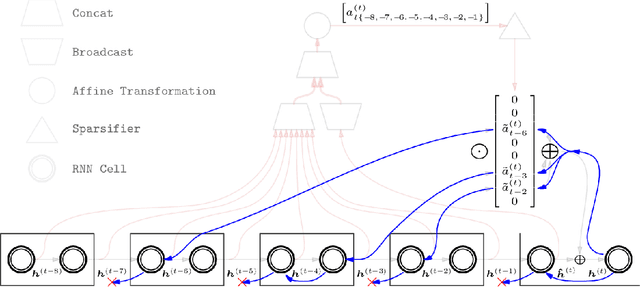
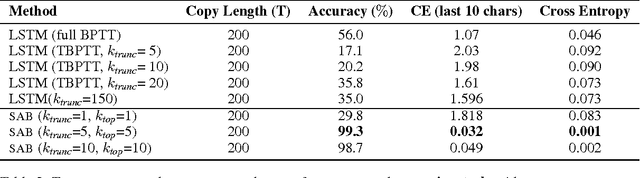
A major drawback of backpropagation through time (BPTT) is the difficulty of learning long-term dependencies, coming from having to propagate credit information backwards through every single step of the forward computation. This makes BPTT both computationally impractical and biologically implausible. For this reason, full backpropagation through time is rarely used on long sequences, and truncated backpropagation through time is used as a heuristic. However, this usually leads to biased estimates of the gradient in which longer term dependencies are ignored. Addressing this issue, we propose an alternative algorithm, Sparse Attentive Backtracking, which might also be related to principles used by brains to learn long-term dependencies. Sparse Attentive Backtracking learns an attention mechanism over the hidden states of the past and selectively backpropagates through paths with high attention weights. This allows the model to learn long term dependencies while only backtracking for a small number of time steps, not just from the recent past but also from attended relevant past states.
Variational Walkback: Learning a Transition Operator as a Stochastic Recurrent Net
Nov 07, 2017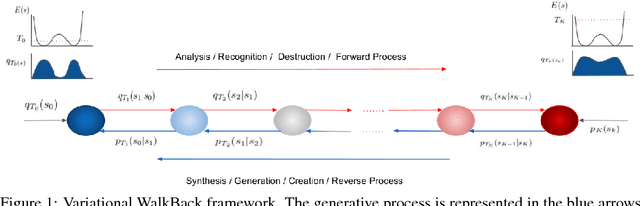

We propose a novel method to directly learn a stochastic transition operator whose repeated application provides generated samples. Traditional undirected graphical models approach this problem indirectly by learning a Markov chain model whose stationary distribution obeys detailed balance with respect to a parameterized energy function. The energy function is then modified so the model and data distributions match, with no guarantee on the number of steps required for the Markov chain to converge. Moreover, the detailed balance condition is highly restrictive: energy based models corresponding to neural networks must have symmetric weights, unlike biological neural circuits. In contrast, we develop a method for directly learning arbitrarily parameterized transition operators capable of expressing non-equilibrium stationary distributions that violate detailed balance, thereby enabling us to learn more biologically plausible asymmetric neural networks and more general non-energy based dynamical systems. The proposed training objective, which we derive via principled variational methods, encourages the transition operator to "walk back" in multi-step trajectories that start at data-points, as quickly as possible back to the original data points. We present a series of experimental results illustrating the soundness of the proposed approach, Variational Walkback (VW), on the MNIST, CIFAR-10, SVHN and CelebA datasets, demonstrating superior samples compared to earlier attempts to learn a transition operator. We also show that although each rapid training trajectory is limited to a finite but variable number of steps, our transition operator continues to generate good samples well past the length of such trajectories, thereby demonstrating the match of its non-equilibrium stationary distribution to the data distribution. Source Code: http://github.com/anirudh9119/walkback_nips17
A Deep Reinforcement Learning Chatbot
Nov 05, 2017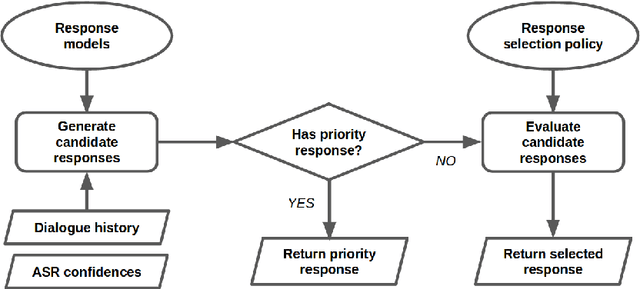
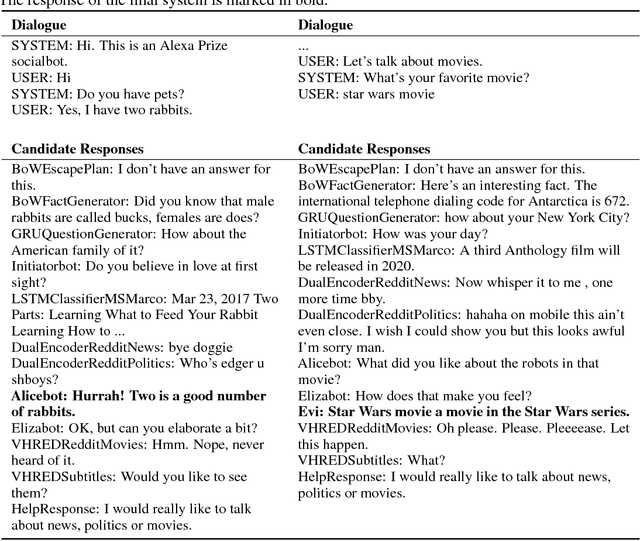
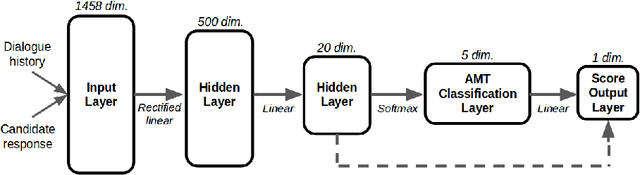

We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including template-based models, bag-of-words models, sequence-to-sequence neural network and latent variable neural network models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than many competing systems. Due to its machine learning architecture, the system is likely to improve with additional data.
Zoneout: Regularizing RNNs by Randomly Preserving Hidden Activations
Sep 22, 2017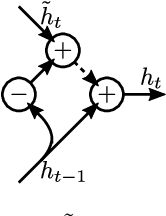
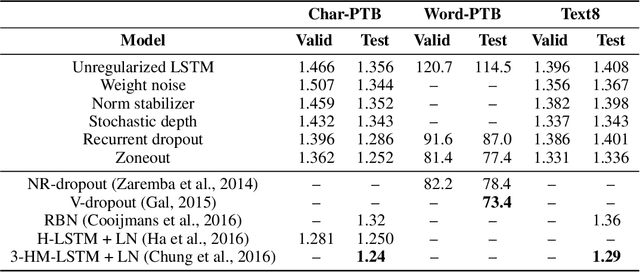
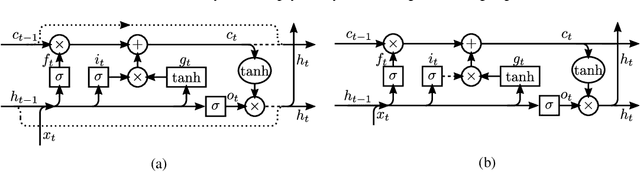

We propose zoneout, a novel method for regularizing RNNs. At each timestep, zoneout stochastically forces some hidden units to maintain their previous values. Like dropout, zoneout uses random noise to train a pseudo-ensemble, improving generalization. But by preserving instead of dropping hidden units, gradient information and state information are more readily propagated through time, as in feedforward stochastic depth networks. We perform an empirical investigation of various RNN regularizers, and find that zoneout gives significant performance improvements across tasks. We achieve competitive results with relatively simple models in character- and word-level language modelling on the Penn Treebank and Text8 datasets, and combining with recurrent batch normalization yields state-of-the-art results on permuted sequential MNIST.
Cascading Bandits for Large-Scale Recommendation Problems
Jun 30, 2016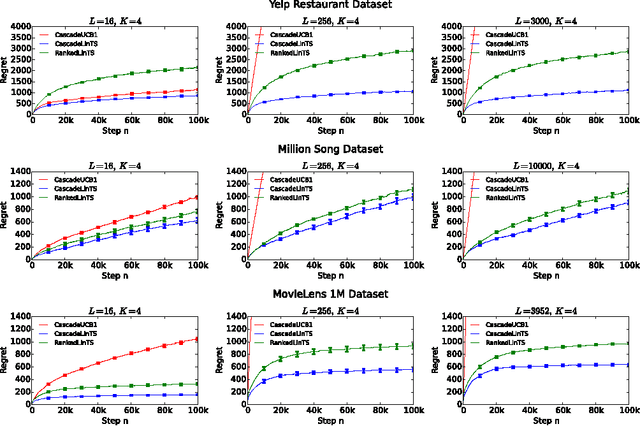
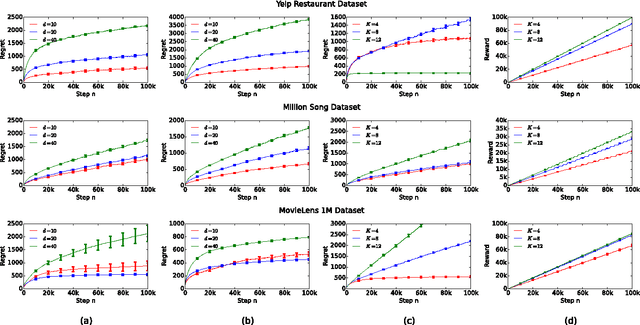
Most recommender systems recommend a list of items. The user examines the list, from the first item to the last, and often chooses the first attractive item and does not examine the rest. This type of user behavior can be modeled by the cascade model. In this work, we study cascading bandits, an online learning variant of the cascade model where the goal is to recommend $K$ most attractive items from a large set of $L$ candidate items. We propose two algorithms for solving this problem, which are based on the idea of linear generalization. The key idea in our solutions is that we learn a predictor of the attraction probabilities of items from their features, as opposing to learning the attraction probability of each item independently as in the existing work. This results in practical learning algorithms whose regret does not depend on the number of items $L$. We bound the regret of one algorithm and comprehensively evaluate the other on a range of recommendation problems. The algorithm performs well and outperforms all baselines.
Task Loss Estimation for Sequence Prediction
Jan 19, 2016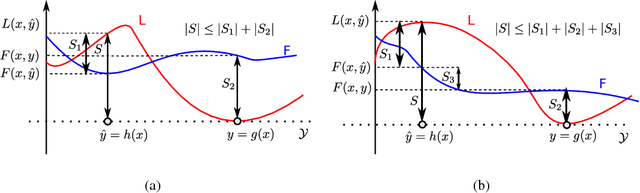
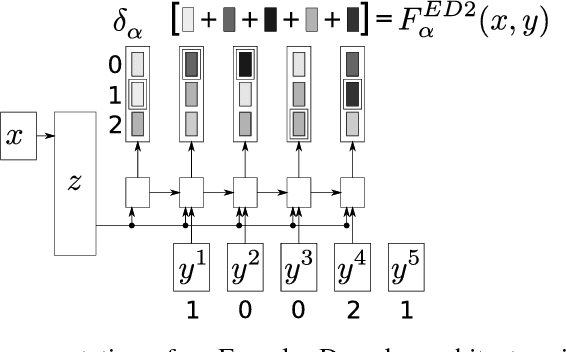
Often, the performance on a supervised machine learning task is evaluated with a emph{task loss} function that cannot be optimized directly. Examples of such loss functions include the classification error, the edit distance and the BLEU score. A common workaround for this problem is to instead optimize a emph{surrogate loss} function, such as for instance cross-entropy or hinge loss. In order for this remedy to be effective, it is important to ensure that minimization of the surrogate loss results in minimization of the task loss, a condition that we call emph{consistency with the task loss}. In this work, we propose another method for deriving differentiable surrogate losses that provably meet this requirement. We focus on the broad class of models that define a score for every input-output pair. Our idea is that this score can be interpreted as an estimate of the task loss, and that the estimation error may be used as a consistent surrogate loss. A distinct feature of such an approach is that it defines the desirable value of the score for every input-output pair. We use this property to design specialized surrogate losses for Encoder-Decoder models often used for sequence prediction tasks. In our experiment, we benchmark on the task of speech recognition. Using a new surrogate loss instead of cross-entropy to train an Encoder-Decoder speech recognizer brings a significant ~13% relative improvement in terms of Character Error Rate (CER) in the case when no extra corpora are used for language modeling.
Transferring Knowledge from a RNN to a DNN
Apr 07, 2015
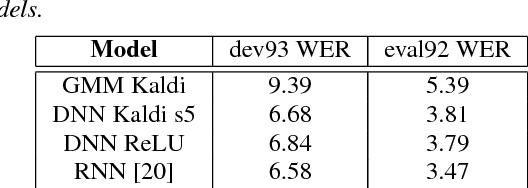
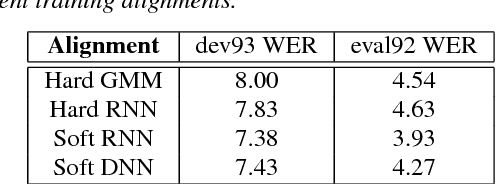
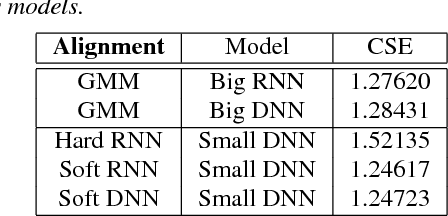
Deep Neural Network (DNN) acoustic models have yielded many state-of-the-art results in Automatic Speech Recognition (ASR) tasks. More recently, Recurrent Neural Network (RNN) models have been shown to outperform DNNs counterparts. However, state-of-the-art DNN and RNN models tend to be impractical to deploy on embedded systems with limited computational capacity. Traditionally, the approach for embedded platforms is to either train a small DNN directly, or to train a small DNN that learns the output distribution of a large DNN. In this paper, we utilize a state-of-the-art RNN to transfer knowledge to small DNN. We use the RNN model to generate soft alignments and minimize the Kullback-Leibler divergence against the small DNN. The small DNN trained on the soft RNN alignments achieved a 3.93 WER on the Wall Street Journal (WSJ) eval92 task compared to a baseline 4.54 WER or more than 13% relative improvement.