 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Feature Selection with Neuron Evolution in Sparse Neural Networks
Mar 14, 2023



Feature selection that selects an informative subset of variables from data not only enhances the model interpretability and performance but also alleviates the resource demands. Recently, there has been growing attention on feature selection using neural networks. However, existing methods usually suffer from high computational costs when applied to high-dimensional datasets. In this paper, inspired by evolution processes, we propose a novel resource-efficient supervised feature selection method using sparse neural networks, named \enquote{NeuroFS}. By gradually pruning the uninformative features from the input layer of a sparse neural network trained from scratch, NeuroFS derives an informative subset of features efficiently. By performing several experiments on $11$ low and high-dimensional real-world benchmarks of different types, we demonstrate that NeuroFS achieves the highest ranking-based score among the considered state-of-the-art supervised feature selection models. The code is available on GitHub.
Automatic Noise Filtering with Dynamic Sparse Training in Deep Reinforcement Learning
Feb 13, 2023Tomorrow's robots will need to distinguish useful information from noise when performing different tasks. A household robot for instance may continuously receive a plethora of information about the home, but needs to focus on just a small subset to successfully execute its current chore. Filtering distracting inputs that contain irrelevant data has received little attention in the reinforcement learning literature. To start resolving this, we formulate a problem setting in reinforcement learning called the $\textit{extremely noisy environment}$ (ENE), where up to $99\%$ of the input features are pure noise. Agents need to detect which features provide task-relevant information about the state of the environment. Consequently, we propose a new method termed $\textit{Automatic Noise Filtering}$ (ANF), which uses the principles of dynamic sparse training in synergy with various deep reinforcement learning algorithms. The sparse input layer learns to focus its connectivity on task-relevant features, such that ANF-SAC and ANF-TD3 outperform standard SAC and TD3 by a large margin, while using up to $95\%$ fewer weights. Furthermore, we devise a transfer learning setting for ENEs, by permuting all features of the environment after 1M timesteps to simulate the fact that other information sources can become relevant as the world evolves. Again, ANF surpasses the baselines in final performance and sample complexity. Our code is available at https://github.com/bramgrooten/automatic-noise-filtering
Dynamic Sparse Network for Time Series Classification: Learning What to "see''
Dec 19, 2022



The receptive field (RF), which determines the region of time series to be ``seen'' and used, is critical to improve the performance for time series classification (TSC). However, the variation of signal scales across and within time series data, makes it challenging to decide on proper RF sizes for TSC. In this paper, we propose a dynamic sparse network (DSN) with sparse connections for TSC, which can learn to cover various RF without cumbersome hyper-parameters tuning. The kernels in each sparse layer are sparse and can be explored under the constraint regions by dynamic sparse training, which makes it possible to reduce the resource cost. The experimental results show that the proposed DSN model can achieve state-of-art performance on both univariate and multivariate TSC datasets with less than 50\% computational cost compared with recent baseline methods, opening the path towards more accurate resource-aware methods for time series analyses. Our code is publicly available at: https://github.com/QiaoXiao7282/DSN.
You Can Have Better Graph Neural Networks by Not Training Weights at All: Finding Untrained GNNs Tickets
Dec 07, 2022



Recent works have impressively demonstrated that there exists a subnetwork in randomly initialized convolutional neural networks (CNNs) that can match the performance of the fully trained dense networks at initialization, without any optimization of the weights of the network (i.e., untrained networks). However, the presence of such untrained subnetworks in graph neural networks (GNNs) still remains mysterious. In this paper we carry out the first-of-its-kind exploration of discovering matching untrained GNNs. With sparsity as the core tool, we can find \textit{untrained sparse subnetworks} at the initialization, that can match the performance of \textit{fully trained dense} GNNs. Besides this already encouraging finding of comparable performance, we show that the found untrained subnetworks can substantially mitigate the GNN over-smoothing problem, hence becoming a powerful tool to enable deeper GNNs without bells and whistles. We also observe that such sparse untrained subnetworks have appealing performance in out-of-distribution detection and robustness of input perturbations. We evaluate our method across widely-used GNN architectures on various popular datasets including the Open Graph Benchmark (OGB).
Where to Pay Attention in Sparse Training for Feature Selection?
Nov 26, 2022



A new line of research for feature selection based on neural networks has recently emerged. Despite its superiority to classical methods, it requires many training iterations to converge and detect informative features. The computational time becomes prohibitively long for datasets with a large number of samples or a very high dimensional feature space. In this paper, we present a new efficient unsupervised method for feature selection based on sparse autoencoders. In particular, we propose a new sparse training algorithm that optimizes a model's sparse topology during training to pay attention to informative features quickly. The attention-based adaptation of the sparse topology enables fast detection of informative features after a few training iterations. We performed extensive experiments on 10 datasets of different types, including image, speech, text, artificial, and biological. They cover a wide range of characteristics, such as low and high-dimensional feature spaces, and few and large training samples. Our proposed approach outperforms the state-of-the-art methods in terms of selecting informative features while reducing training iterations and computational costs substantially. Moreover, the experiments show the robustness of our method in extremely noisy environments.
FAL-CUR: Fair Active Learning using Uncertainty and Representativeness on Fair Clustering
Sep 21, 2022
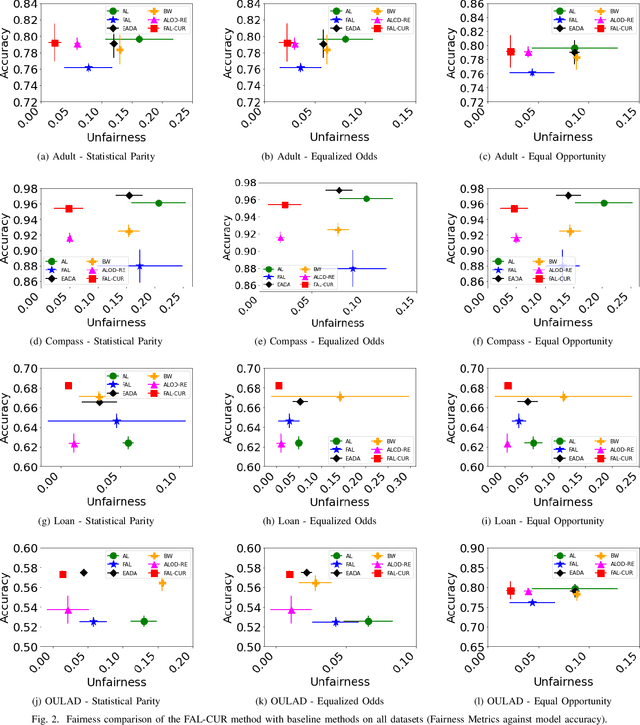
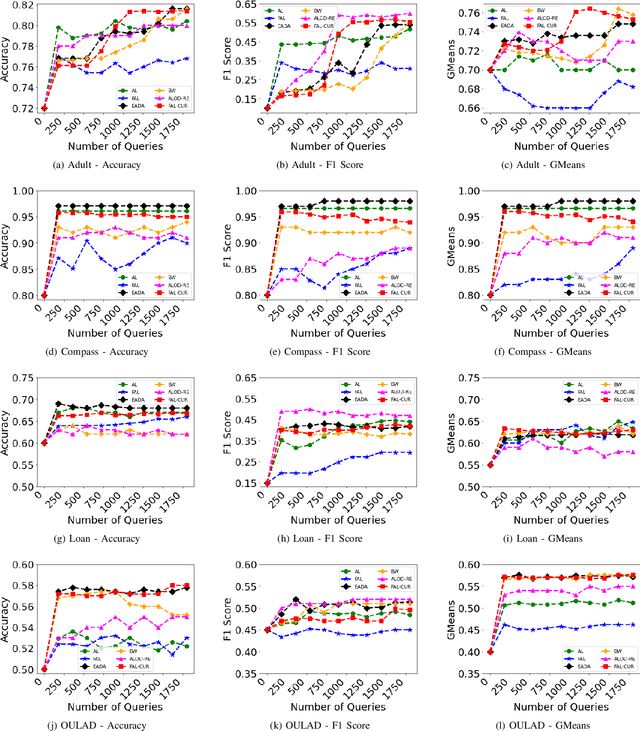
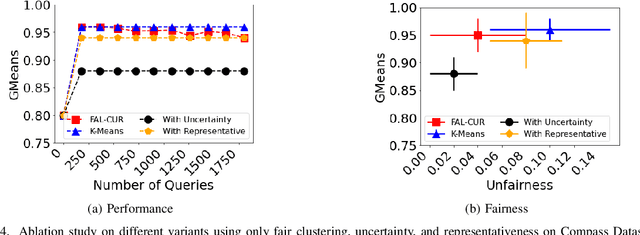
In the literature, several active learning techniques have been proposed for reducing the cost of data annotation. However, it is questionable whether the sample selection is fair with respect to sensitive attributes. Even when the active learning model considers fairness, it comes with a cost of reduced accuracy performance. Thus, it remains an open challenge to design an active learning algorithm that can maintain performance as well as fairness to underprivileged groups. This paper presents a novel active learning strategy called Fair Active Learning using fair Clustering, Uncertainty, and Representativeness (FAL-CUR) that provides a high accuracy while maintaining fairness during the sample acquisition phase. We introduce the FAL-CUR sample acquisition function that computes each sample's representative score based on the uncertainty and similarity score for sample selection. This acquisition function is added on top of the fair clustering method to add fairness constraints to the active learning method. We perform extensive experiments on four real-world datasets to compare the performance of the proposed methods. The experimental results show that the FAL-CUR algorithm maintains the performance accuracy while achieving high fairness measures and outperforms state-of-the-art methods on well-known fair active learning problems.
An Empirical Evaluation of Posterior Sampling for Constrained Reinforcement Learning
Sep 08, 2022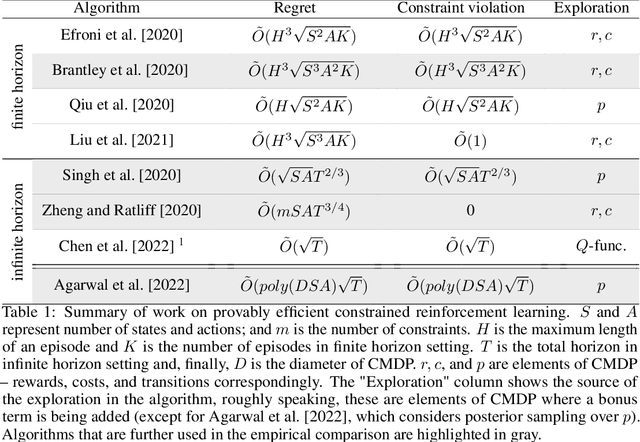
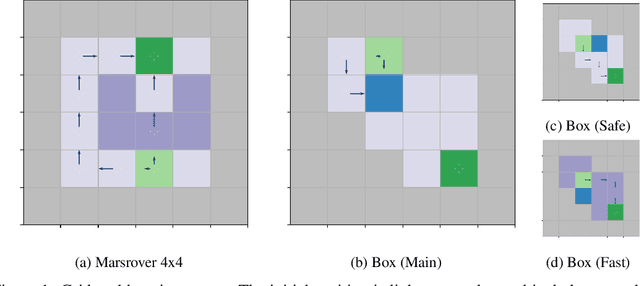
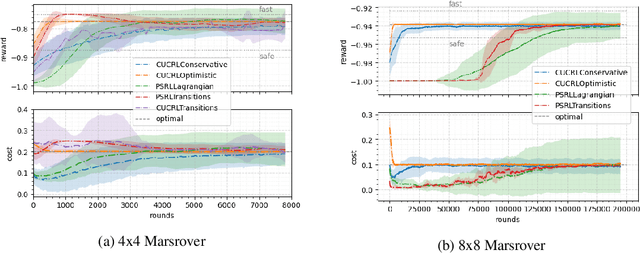
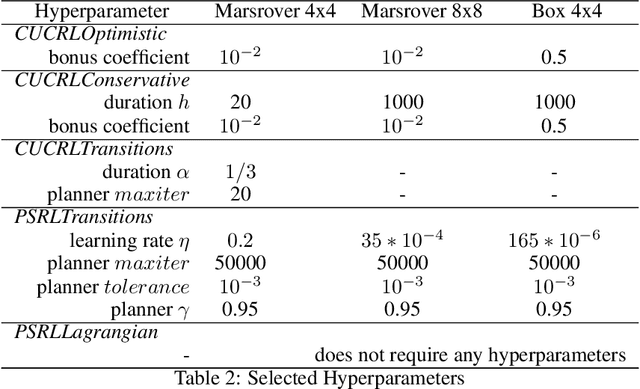
We study a posterior sampling approach to efficient exploration in constrained reinforcement learning. Alternatively to existing algorithms, we propose two simple algorithms that are more efficient statistically, simpler to implement and computationally cheaper. The first algorithm is based on a linear formulation of CMDP, and the second algorithm leverages the saddle-point formulation of CMDP. Our empirical results demonstrate that, despite its simplicity, posterior sampling achieves state-of-the-art performance and, in some cases, significantly outperforms optimistic algorithms.
Lottery Pools: Winning More by Interpolating Tickets without Increasing Training or Inference Cost
Aug 23, 2022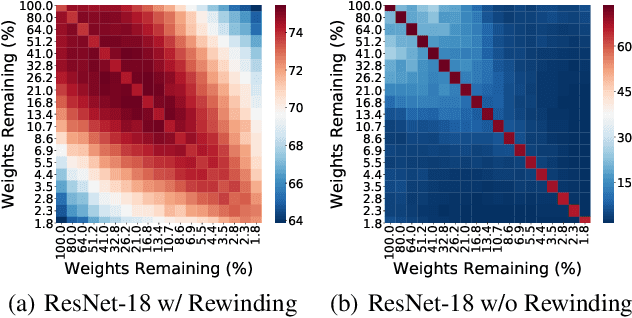
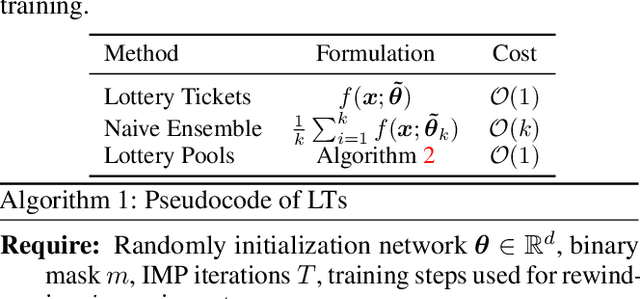
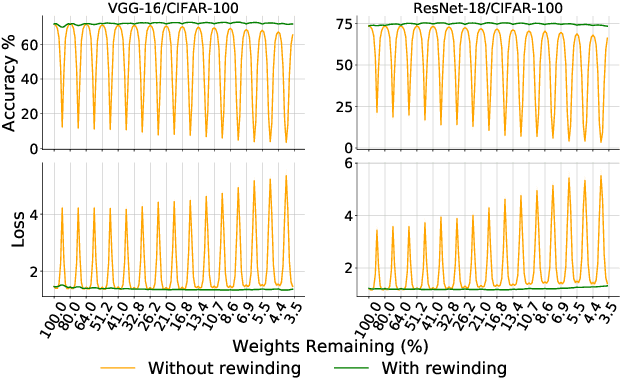

Lottery tickets (LTs) is able to discover accurate and sparse subnetworks that could be trained in isolation to match the performance of dense networks. Ensemble, in parallel, is one of the oldest time-proven tricks in machine learning to improve performance by combining the output of multiple independent models. However, the benefits of ensemble in the context of LTs will be diluted since ensemble does not directly lead to stronger sparse subnetworks, but leverages their predictions for a better decision. In this work, we first observe that directly averaging the weights of the adjacent learned subnetworks significantly boosts the performance of LTs. Encouraged by this observation, we further propose an alternative way to perform an 'ensemble' over the subnetworks identified by iterative magnitude pruning via a simple interpolating strategy. We call our method Lottery Pools. In contrast to the naive ensemble which brings no performance gains to each single subnetwork, Lottery Pools yields much stronger sparse subnetworks than the original LTs without requiring any extra training or inference cost. Across various modern architectures on CIFAR-10/100 and ImageNet, we show that our method achieves significant performance gains in both, in-distribution and out-of-distribution scenarios. Impressively, evaluated with VGG-16 and ResNet-18, the produced sparse subnetworks outperform the original LTs by up to 1.88% on CIFAR-100 and 2.36% on CIFAR-100-C; the resulting dense network surpasses the pre-trained dense-model up to 2.22% on CIFAR-100 and 2.38% on CIFAR-100-C.
Memory-free Online Change-point Detection: A Novel Neural Network Approach
Jul 08, 2022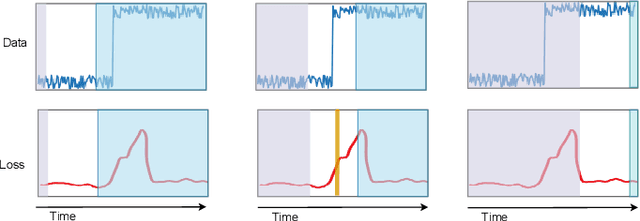
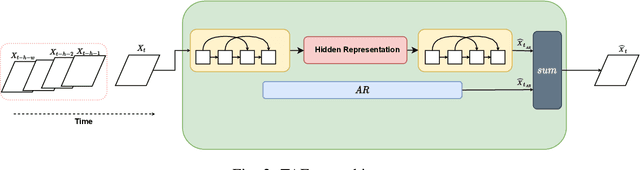
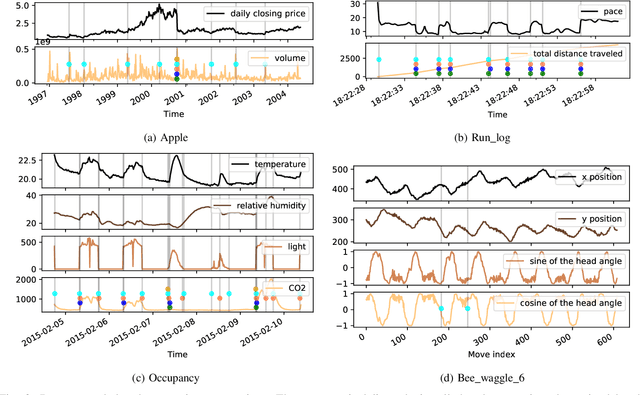
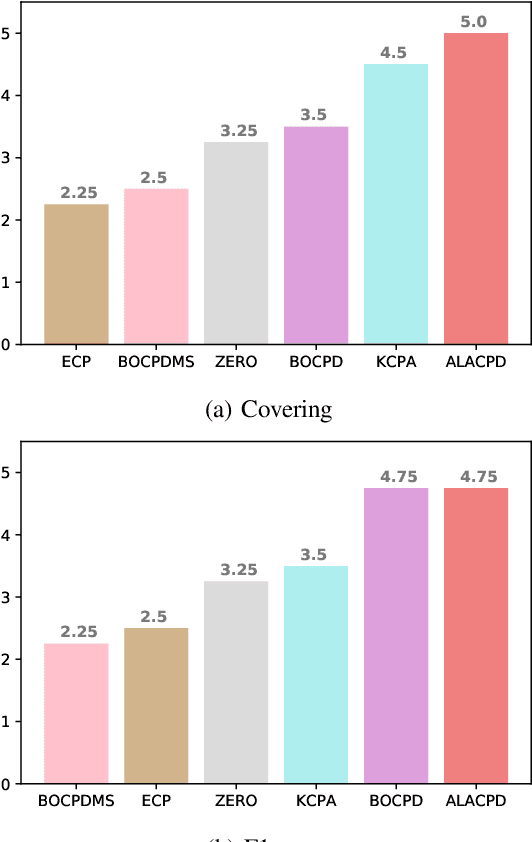
Change-point detection (CPD), which detects abrupt changes in the data distribution, is recognized as one of the most significant tasks in time series analysis. Despite the extensive literature on offline CPD, unsupervised online CPD still suffers from major challenges, including scalability, hyperparameter tuning, and learning constraints. To mitigate some of these challenges, in this paper, we propose a novel deep learning approach for unsupervised online CPD from multi-dimensional time series, named Adaptive LSTM-Autoencoder Change-Point Detection (ALACPD). ALACPD exploits an LSTM-autoencoder-based neural network to perform unsupervised online CPD. It continuously adapts to the incoming samples without keeping the previously received input, thus being memory-free. We perform an extensive evaluation on several real-world time series CPD benchmarks. We show that ALACPD, on average, ranks first among state-of-the-art CPD algorithms in terms of quality of the time series segmentation, and it is on par with the best performer in terms of the accuracy of the estimated change-points. The implementation of ALACPD is available online on Github\footnote{\url{https://github.com/zahraatashgahi/ALACPD}}.
More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 using Sparsity
Jul 07, 2022
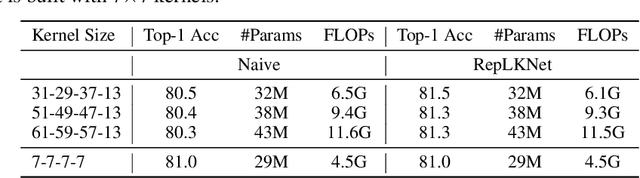
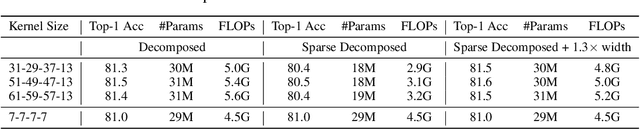
Transformers have quickly shined in the computer vision world since the emergence of Vision Transformers (ViTs). The dominant role of convolutional neural networks (CNNs) seems to be challenged by increasingly effective transformer-based models. Very recently, a couple of advanced convolutional models strike back with large kernels motivated by the local but large attention mechanism, showing appealing performance and efficiency. While one of them, i.e. RepLKNet, impressively manages to scale the kernel size to 31x31 with improved performance, the performance starts to saturate as the kernel size continues growing, compared to the scaling trend of advanced ViTs such as Swin Transformer. In this paper, we explore the possibility of training extreme convolutions larger than 31x31 and test whether the performance gap can be eliminated by strategically enlarging convolutions. This study ends up with a recipe for applying extremely large kernels from the perspective of sparsity, which can smoothly scale up kernels to 61x61 with better performance. Built on this recipe, we propose Sparse Large Kernel Network (SLaK), a pure CNN architecture equipped with 51x51 kernels that can perform on par with or better than state-of-the-art hierarchical Transformers and modern ConvNet architectures like ConvNeXt and RepLKNet, on ImageNet classification as well as typical downstream tasks. Our code is available here https://github.com/VITA-Group/SLaK.