 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-SysId: A Meta-Learning Approach for Simultaneous Identification and Prediction
Jun 01, 2022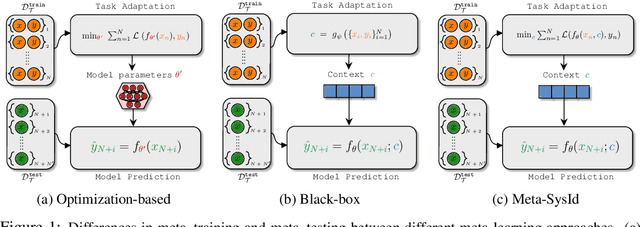
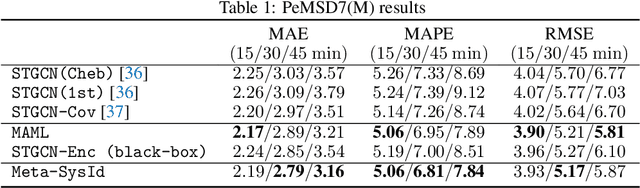
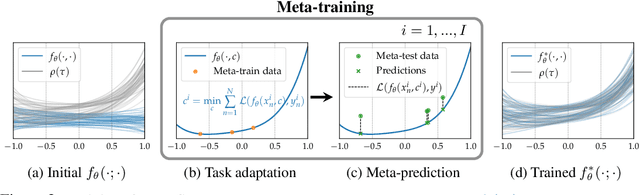
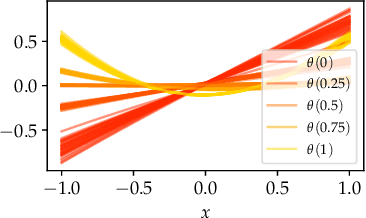
In this paper, we propose Meta-SysId, a meta-learning approach to model sets of systems that have behavior governed by common but unknown laws and that differentiate themselves by their context. Inspired by classical modeling-and-identification approaches, Meta-SysId learns to represent the common law through shared parameters and relies on online optimization to compute system-specific context. Compared to optimization-based meta-learning methods, the separation between class parameters and context variables reduces the computational burden while allowing batch computations and a simple training scheme. We test Meta-SysId on polynomial regression, time-series prediction, model-based control, and real-world traffic prediction domains, empirically finding it outperforms or is competitive with meta-learning baselines.
Risk-Driven Design of Perception Systems
May 21, 2022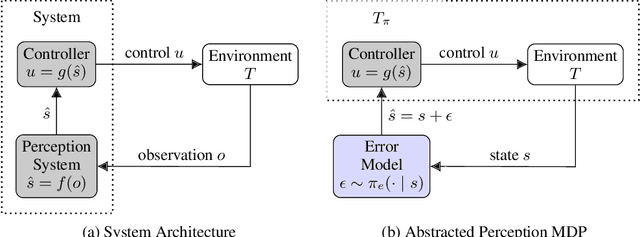

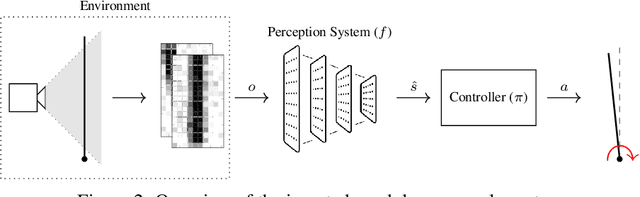

Modern autonomous systems rely on perception modules to process complex sensor measurements into state estimates. These estimates are then passed to a controller, which uses them to make safety-critical decisions. It is therefore important that we design perception systems to minimize errors that reduce the overall safety of the system. We develop a risk-driven approach to designing perception systems that accounts for the effect of perceptual errors on the performance of the fully-integrated, closed-loop system. We formulate a risk function to quantify the effect of a given perceptual error on overall safety, and show how we can use it to design safer perception systems by including a risk-dependent term in the loss function and generating training data in risk-sensitive regions. We evaluate our techniques on a realistic vision-based aircraft detect and avoid application and show that risk-driven design reduces collision risk by 37% over a baseline system.
Collision Risk and Operational Impact of Speed Change Advisories as Aircraft Collision Avoidance Maneuvers
Apr 29, 2022
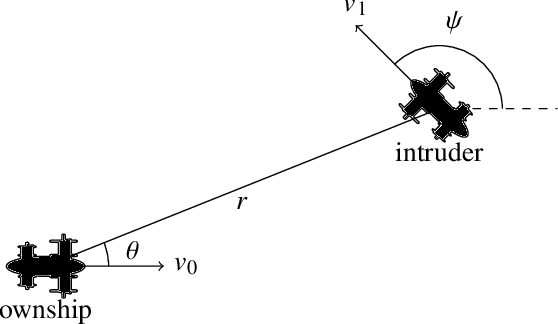

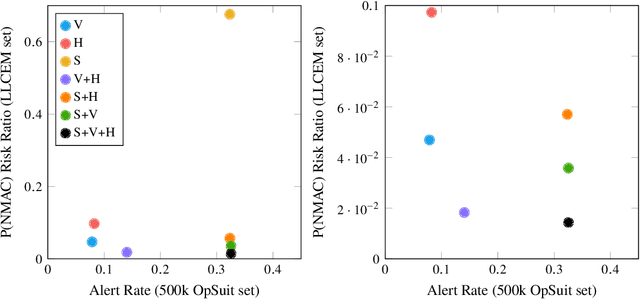
Aircraft collision avoidance systems have long been a key factor in keeping our airspace safe. Over the past decade, the FAA has supported the development of a new family of collision avoidance systems called the Airborne Collision Avoidance System X (ACAS X), which model the collision avoidance problem as a Markov decision process (MDP). Variants of ACAS X have been created for both manned (ACAS Xa) and unmanned aircraft (ACAS Xu and ACAS sXu). The variants primarily differ in the types of collision avoidance maneuvers they issue. For example, ACAS Xa issues vertical collision avoidance advisories, while ACAS Xu and ACAS sXu allow for horizontal advisories due to reduced aircraft performance capabilities. Currently, a new variant of ACAS X, called ACAS Xr, is being developed to provide collision avoidance capability to rotorcraft and Advanced Air Mobility (AAM) vehicles. Due to the desire to minimize deviation from the prescribed flight path of these aircraft, speed adjustments have been proposed as a potential collision avoidance maneuver for aircraft using ACAS Xr. In this work, we investigate the effect of speed change advisories on the safety and operational efficiency of collision avoidance systems. We develop an MDP-based collision avoidance logic that issues speed advisories and compare its performance to that of horizontal and vertical logics through Monte Carlo simulation on existing airspace encounter models. Our results show that while speed advisories are able to reduce collision risk, they are neither as safe nor as efficient as their horizontal and vertical counterparts.
SHAIL: Safety-Aware Hierarchical Adversarial Imitation Learning for Autonomous Driving in Urban Environments
Apr 05, 2022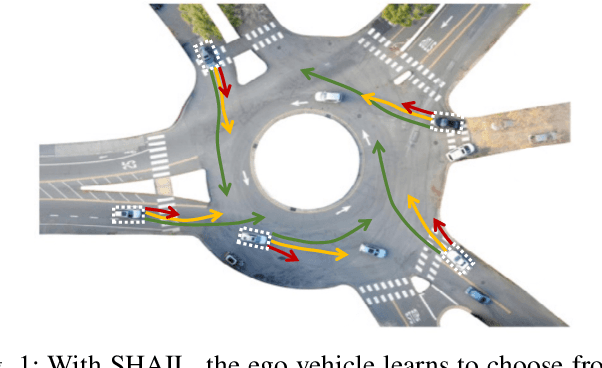
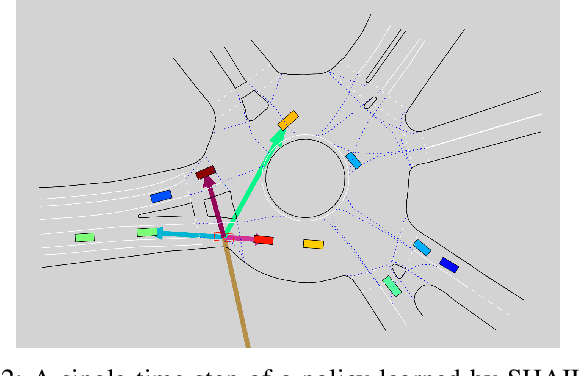
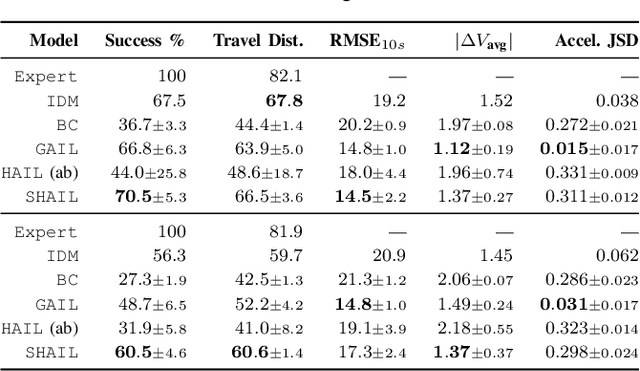
Designing a safe and human-like decision-making system for an autonomous vehicle is a challenging task. Generative imitation learning is one possible approach for automating policy-building by leveraging both real-world and simulated decisions. Previous work that applies generative imitation learning to autonomous driving policies focuses on learning a low-level controller for simple settings. However, to scale to complex settings, many autonomous driving systems combine fixed, safe, optimization-based low-level controllers with high-level decision-making logic that selects the appropriate task and associated controller. In this paper, we attempt to bridge this gap in complexity by employing Safety-Aware Hierarchical Adversarial Imitation Learning (SHAIL), a method for learning a high-level policy that selects from a set of low-level controller instances in a way that imitates low-level driving data on-policy. We introduce an urban roundabout simulator that controls non-ego vehicles using real data from the Interaction dataset. We then show empirically that our approach can produce better behavior than previous approaches in driver imitation which have difficulty scaling to complex environments. Our implementation is available at https://github.com/sisl/InteractionImitation.
Model Predictive Optimized Path Integral Strategies
Mar 30, 2022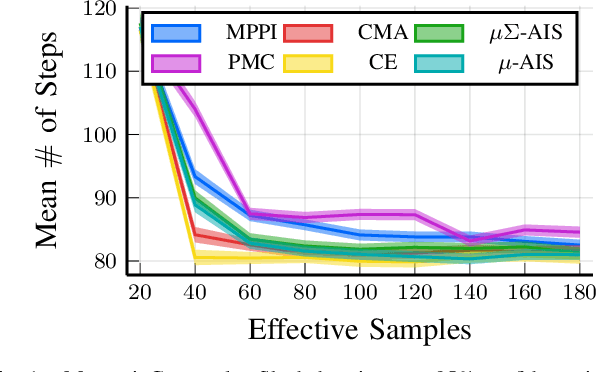
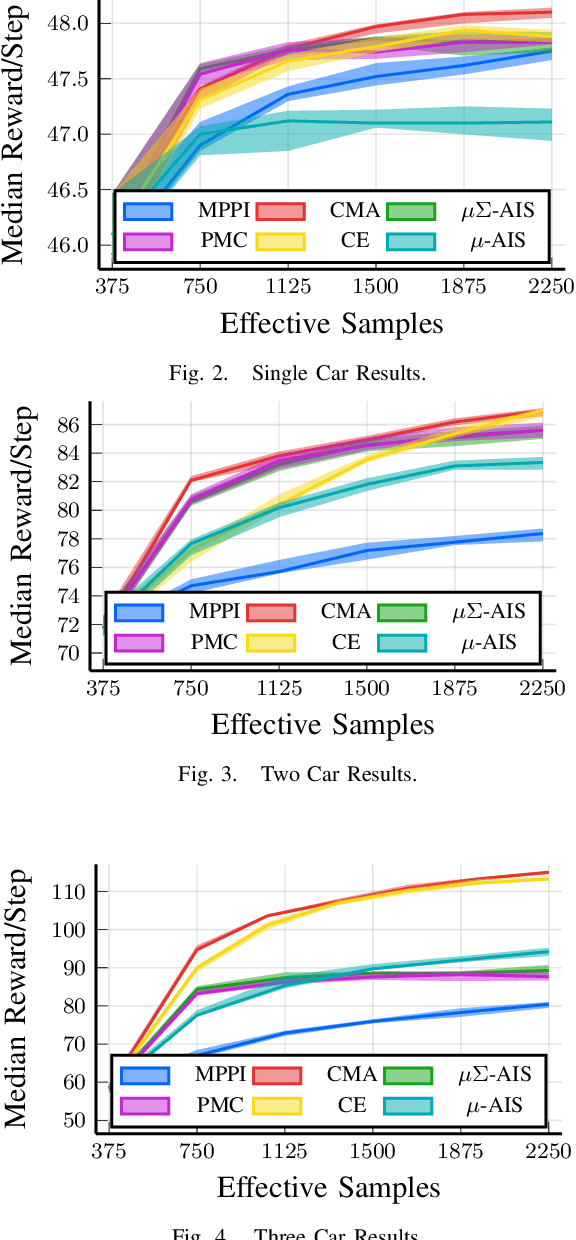
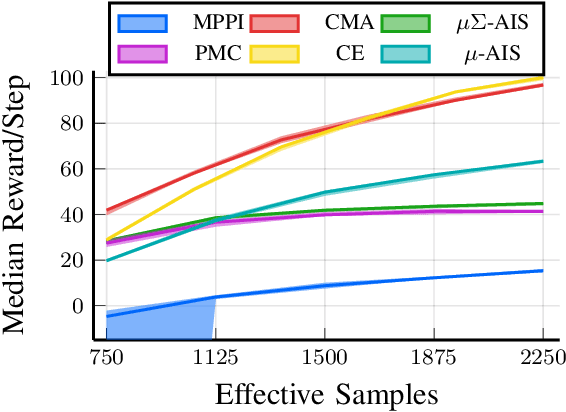
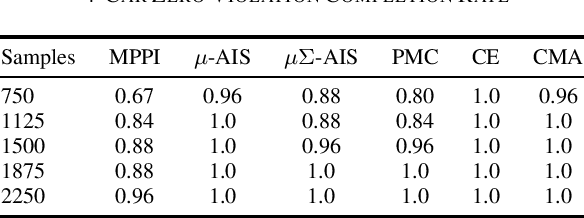
We generalize the derivation of model predictive path integral control (MPPI) to allow for a single joint distribution across controls in the control sequence. This reformation allows for the implementation of adaptive importance sampling (AIS) algorithms into the original importance sampling step while still maintaining the benefits of MPPI such as working with arbitrary system dynamics and cost functions. The benefit of optimizing the proposal distribution by integrating AIS at each control step is demonstrated in simulated environments including controlling multiple cars around a track. The new algorithm is more sample efficient than MPPI, achieving better performance with fewer samples. This performance disparity grows as the dimension of the action space increases. Results from simulations suggest the new algorithm can be used as an anytime algorithm, increasing the value of control at each iteration versus relying on a large set of samples.
How Do We Fail? Stress Testing Perception in Autonomous Vehicles
Mar 26, 2022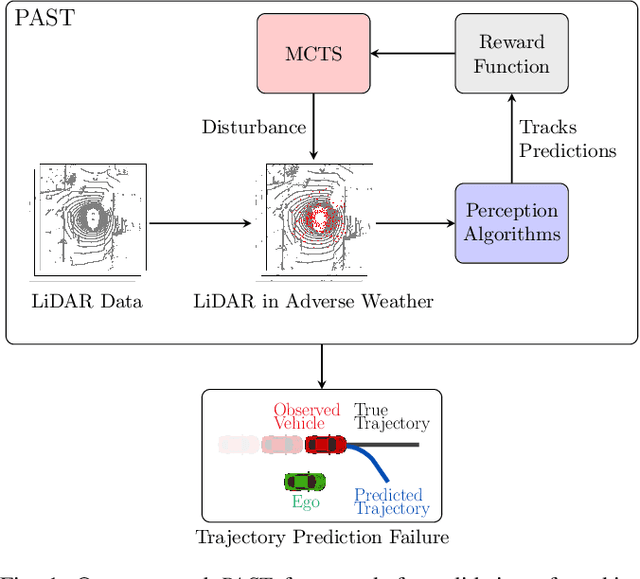
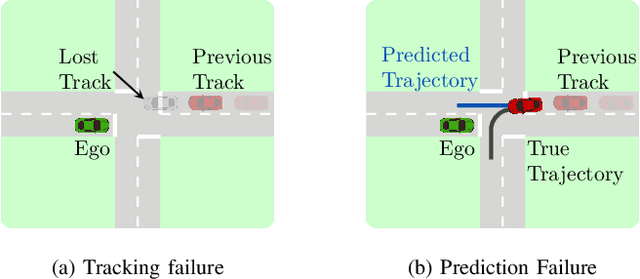
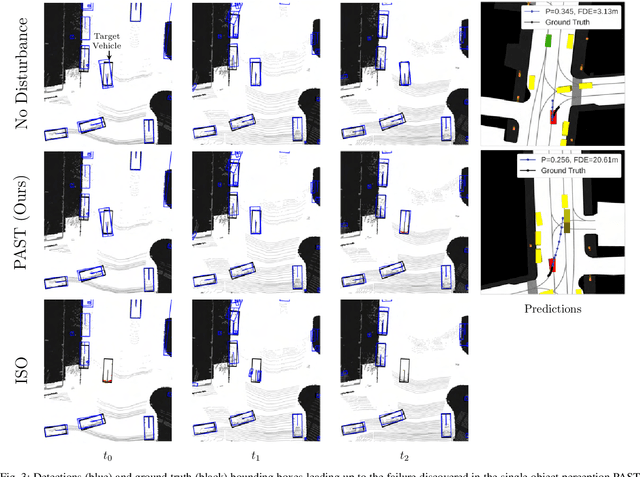
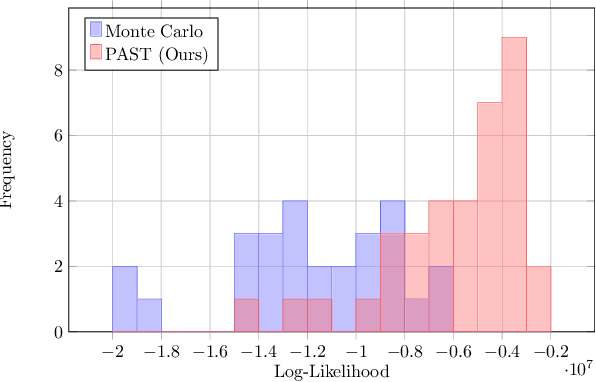
Autonomous vehicles (AVs) rely on environment perception and behavior prediction to reason about agents in their surroundings. These perception systems must be robust to adverse weather such as rain, fog, and snow. However, validation of these systems is challenging due to their complexity and dependence on observation histories. This paper presents a method for characterizing failures of LiDAR-based perception systems for AVs in adverse weather conditions. We develop a methodology based in reinforcement learning to find likely failures in object tracking and trajectory prediction due to sequences of disturbances. We apply disturbances using a physics-based data augmentation technique for simulating LiDAR point clouds in adverse weather conditions. Experiments performed across a wide range of driving scenarios from a real-world driving dataset show that our proposed approach finds high likelihood failures with smaller input disturbances compared to baselines while remaining computationally tractable. Identified failures can inform future development of robust perception systems for AVs.
Deep Binary Reinforcement Learning for Scalable Verification
Mar 11, 2022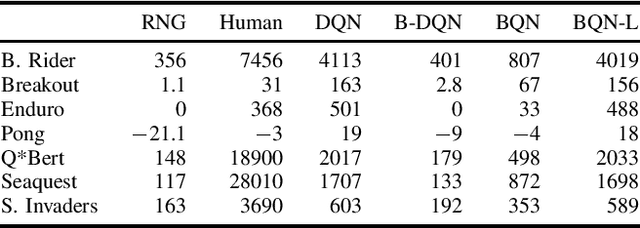
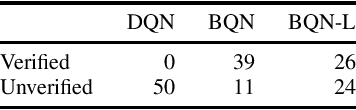
The use of neural networks as function approximators has enabled many advances in reinforcement learning (RL). The generalization power of neural networks combined with advances in RL algorithms has reignited the field of artificial intelligence. Despite their power, neural networks are considered black boxes, and their use in safety-critical settings remains a challenge. Recently, neural network verification has emerged as a way to certify safety properties of networks. Verification is a hard problem, and it is difficult to scale to large networks such as the ones used in deep reinforcement learning. We provide an approach to train RL policies that are more easily verifiable. We use binarized neural networks (BNNs), a type of network with mostly binary parameters. We present an RL algorithm tailored specifically for BNNs. After training BNNs for the Atari environments, we verify robustness properties.
A Mixed Integer Programming Approach for Verifying Properties of Binarized Neural Networks
Mar 11, 2022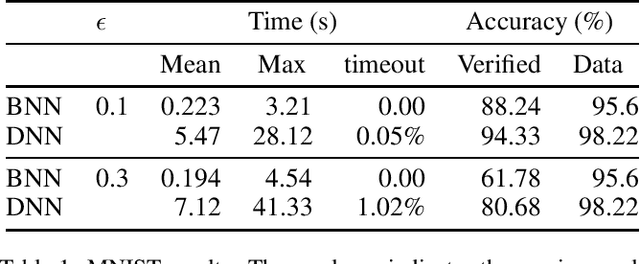
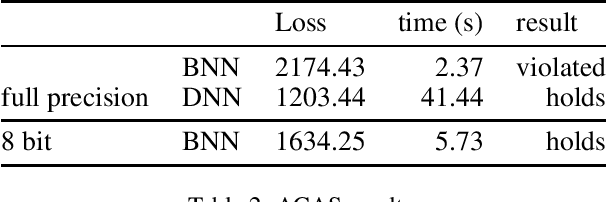
Many approaches for verifying input-output properties of neural networks have been proposed recently. However, existing algorithms do not scale well to large networks. Recent work in the field of model compression studied binarized neural networks (BNNs), whose parameters and activations are binary. BNNs tend to exhibit a slight decrease in performance compared to their full-precision counterparts, but they can be easier to verify. This paper proposes a simple mixed integer programming formulation for BNN verification that leverages network structure. We demonstrate our approach by verifying properties of BNNs trained on the MNIST dataset and an aircraft collision avoidance controller. We compare the runtime of our approach against state-of-the-art verification algorithms for full-precision neural networks. The results suggest that the difficulty of training BNNs might be worth the reduction in runtime achieved by our verification algorithm.
Recursive Reasoning Graph for Multi-Agent Reinforcement Learning
Mar 06, 2022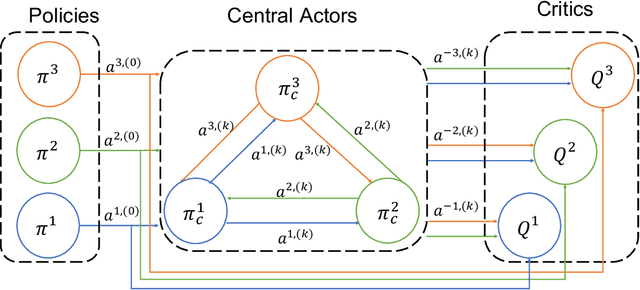
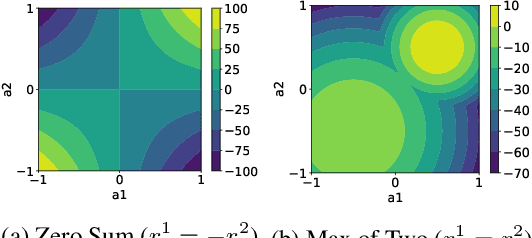
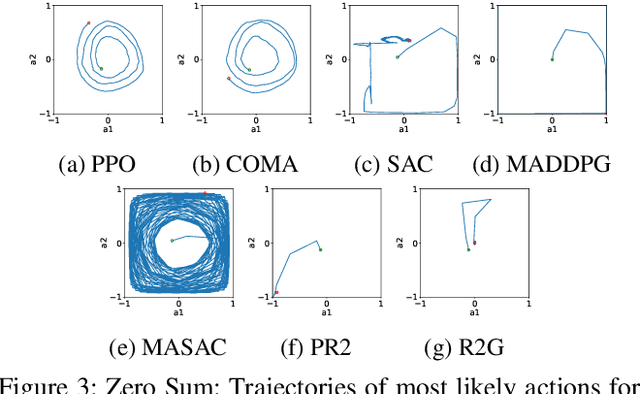
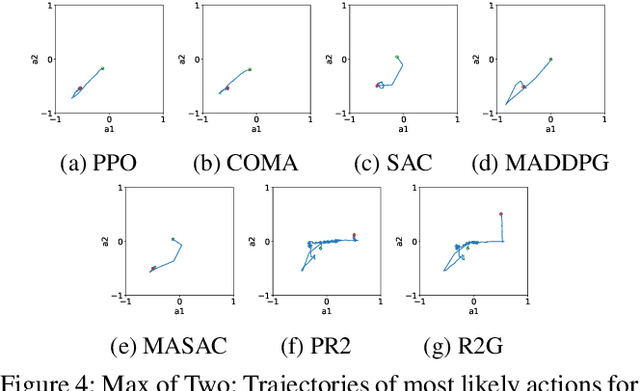
Multi-agent reinforcement learning (MARL) provides an efficient way for simultaneously learning policies for multiple agents interacting with each other. However, in scenarios requiring complex interactions, existing algorithms can suffer from an inability to accurately anticipate the influence of self-actions on other agents. Incorporating an ability to reason about other agents' potential responses can allow an agent to formulate more effective strategies. This paper adopts a recursive reasoning model in a centralized-training-decentralized-execution framework to help learning agents better cooperate with or compete against others. The proposed algorithm, referred to as the Recursive Reasoning Graph (R2G), shows state-of-the-art performance on multiple multi-agent particle and robotics games.
Verifying Inverse Model Neural Networks
Feb 04, 2022



Inverse problems exist in a wide variety of physical domains from aerospace engineering to medical imaging. The goal is to infer the underlying state from a set of observations. When the forward model that produced the observations is nonlinear and stochastic, solving the inverse problem is very challenging. Neural networks are an appealing solution for solving inverse problems as they can be trained from noisy data and once trained are computationally efficient to run. However, inverse model neural networks do not have guarantees of correctness built-in, which makes them unreliable for use in safety and accuracy-critical contexts. In this work we introduce a method for verifying the correctness of inverse model neural networks. Our approach is to overapproximate a nonlinear, stochastic forward model with piecewise linear constraints and encode both the overapproximate forward model and the neural network inverse model as a mixed-integer program. We demonstrate this verification procedure on a real-world airplane fuel gauge case study. The ability to verify and consequently trust inverse model neural networks allows their use in a wide variety of contexts, from aerospace to medicine.