 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Distribution Modelling for Few-Shot Image Synthesis with Diffusion Models
Apr 29, 2024Few-shot image synthesis entails generating diverse and realistic images of novel categories using only a few example images. While multiple recent efforts in this direction have achieved impressive results, the existing approaches are dependent only upon the few novel samples available at test time in order to generate new images, which restricts the diversity of the generated images. To overcome this limitation, we propose Conditional Distribution Modelling (CDM) -- a framework which effectively utilizes Diffusion models for few-shot image generation. By modelling the distribution of the latent space used to condition a Diffusion process, CDM leverages the learnt statistics of the training data to get a better approximation of the unseen class distribution, thereby removing the bias arising due to limited number of few shot samples. Simultaneously, we devise a novel inversion based optimization strategy that further improves the approximated unseen class distribution, and ensures the fidelity of the generated samples to the unseen class. The experimental results on four benchmark datasets demonstrate the effectiveness of our proposed CDM for few-shot generation.
OCAI: Improving Optical Flow Estimation by Occlusion and Consistency Aware Interpolation
Mar 26, 2024



The scarcity of ground-truth labels poses one major challenge in developing optical flow estimation models that are both generalizable and robust. While current methods rely on data augmentation, they have yet to fully exploit the rich information available in labeled video sequences. We propose OCAI, a method that supports robust frame interpolation by generating intermediate video frames alongside optical flows in between. Utilizing a forward warping approach, OCAI employs occlusion awareness to resolve ambiguities in pixel values and fills in missing values by leveraging the forward-backward consistency of optical flows. Additionally, we introduce a teacher-student style semi-supervised learning method on top of the interpolated frames. Using a pair of unlabeled frames and the teacher model's predicted optical flow, we generate interpolated frames and flows to train a student model. The teacher's weights are maintained using Exponential Moving Averaging of the student. Our evaluations demonstrate perceptually superior interpolation quality and enhanced optical flow accuracy on established benchmarks such as Sintel and KITTI.
PosSAM: Panoptic Open-vocabulary Segment Anything
Mar 14, 2024



In this paper, we introduce an open-vocabulary panoptic segmentation model that effectively unifies the strengths of the Segment Anything Model (SAM) with the vision-language CLIP model in an end-to-end framework. While SAM excels in generating spatially-aware masks, it's decoder falls short in recognizing object class information and tends to oversegment without additional guidance. Existing approaches address this limitation by using multi-stage techniques and employing separate models to generate class-aware prompts, such as bounding boxes or segmentation masks. Our proposed method, PosSAM is an end-to-end model which leverages SAM's spatially rich features to produce instance-aware masks and harnesses CLIP's semantically discriminative features for effective instance classification. Specifically, we address the limitations of SAM and propose a novel Local Discriminative Pooling (LDP) module leveraging class-agnostic SAM and class-aware CLIP features for unbiased open-vocabulary classification. Furthermore, we introduce a Mask-Aware Selective Ensembling (MASE) algorithm that adaptively enhances the quality of generated masks and boosts the performance of open-vocabulary classification during inference for each image. We conducted extensive experiments to demonstrate our methods strong generalization properties across multiple datasets, achieving state-of-the-art performance with substantial improvements over SOTA open-vocabulary panoptic segmentation methods. In both COCO to ADE20K and ADE20K to COCO settings, PosSAM outperforms the previous state-of-the-art methods by a large margin, 2.4 PQ and 4.6 PQ, respectively. Project Website: https://vibashan.github.io/possam-web/.
EraseDiff: Erasing Data Influence in Diffusion Models
Jan 11, 2024In response to data protection regulations and the ``right to be forgotten'', in this work, we introduce an unlearning algorithm for diffusion models. Our algorithm equips a diffusion model with a mechanism to mitigate the concerns related to data memorization. To achieve this, we formulate the unlearning problem as a bi-level optimization problem, wherein the outer objective is to preserve the utility of the diffusion model on the remaining data. The inner objective aims to scrub the information associated with forgetting data by deviating the learnable generative process from the ground-truth denoising procedure. To solve the resulting bi-level problem, we adopt a first-order method, having superior practical performance while being vigilant about the diffusion process and solving a bi-level problem therein. Empirically, we demonstrate that our algorithm can preserve the model utility, effectiveness, and efficiency while removing across two widely-used diffusion models and in both conditional and unconditional image generation scenarios. In our experiments, we demonstrate the unlearning of classes, attributes, and even a race from face and object datasets such as UTKFace, CelebA, CelebA-HQ, and CIFAR10.
DiffAugment: Diffusion based Long-Tailed Visual Relationship Recognition
Jan 01, 2024The task of Visual Relationship Recognition (VRR) aims to identify relationships between two interacting objects in an image and is particularly challenging due to the widely-spread and highly imbalanced distribution of <subject, relation, object> triplets. To overcome the resultant performance bias in existing VRR approaches, we introduce DiffAugment -- a method which first augments the tail classes in the linguistic space by making use of WordNet and then utilizes the generative prowess of Diffusion Models to expand the visual space for minority classes. We propose a novel hardness-aware component in diffusion which is based upon the hardness of each <S,R,O> triplet and demonstrate the effectiveness of hardness-aware diffusion in generating visual embeddings for the tail classes. We also propose a novel subject and object based seeding strategy for diffusion sampling which improves the discriminative capability of the generated visual embeddings. Extensive experimentation on the GQA-LT dataset shows favorable gains in the subject/object and relation average per-class accuracy using Diffusion augmented samples.
AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset
Nov 26, 2023



The detection and localization of highly realistic deepfake audio-visual content are challenging even for the most advanced state-of-the-art methods. While most of the research efforts in this domain are focused on detecting high-quality deepfake images and videos, only a few works address the problem of the localization of small segments of audio-visual manipulations embedded in real videos. In this research, we emulate the process of such content generation and propose the AV-Deepfake1M dataset. The dataset contains content-driven (i) video manipulations, (ii) audio manipulations, and (iii) audio-visual manipulations for more than 2K subjects resulting in a total of more than 1M videos. The paper provides a thorough description of the proposed data generation pipeline accompanied by a rigorous analysis of the quality of the generated data. The comprehensive benchmark of the proposed dataset utilizing state-of-the-art deepfake detection and localization methods indicates a significant drop in performance compared to previous datasets. The proposed dataset will play a vital role in building the next-generation deepfake localization methods. The dataset and associated code are available at https://github.com/ControlNet/AV-Deepfake1M .
Unified Open-Vocabulary Dense Visual Prediction
Jul 17, 2023



In recent years, open-vocabulary (OV) dense visual prediction (such as OV object detection, semantic, instance and panoptic segmentations) has attracted increasing research attention. However, most of existing approaches are task-specific and individually tackle each task. In this paper, we propose a Unified Open-Vocabulary Network (UOVN) to jointly address four common dense prediction tasks. Compared with separate models, a unified network is more desirable for diverse industrial applications. Moreover, OV dense prediction training data is relatively less. Separate networks can only leverage task-relevant training data, while a unified approach can integrate diverse training data to boost individual tasks. We address two major challenges in unified OV prediction. Firstly, unlike unified methods for fixed-set predictions, OV networks are usually trained with multi-modal data. Therefore, we propose a multi-modal, multi-scale and multi-task (MMM) decoding mechanism to better leverage multi-modal data. Secondly, because UOVN uses data from different tasks for training, there are significant domain and task gaps. We present a UOVN training mechanism to reduce such gaps. Experiments on four datasets demonstrate the effectiveness of our UOVN.
Open-Vocabulary Object Detection via Scene Graph Discovery
Jul 07, 2023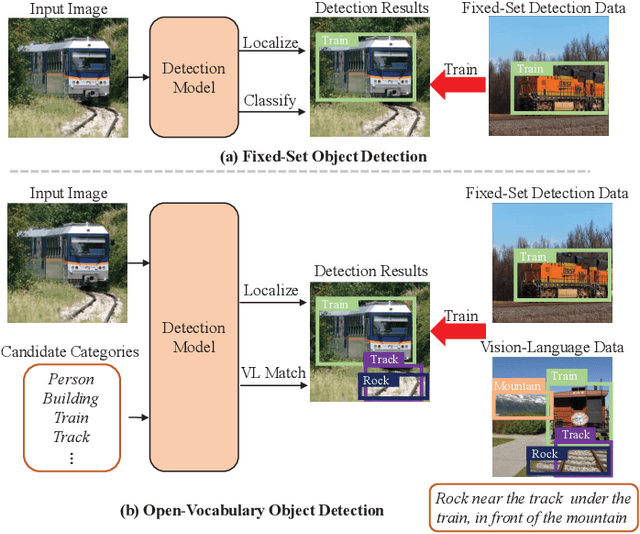
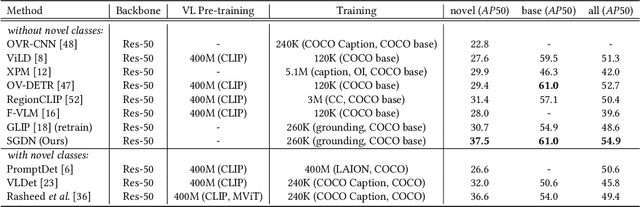
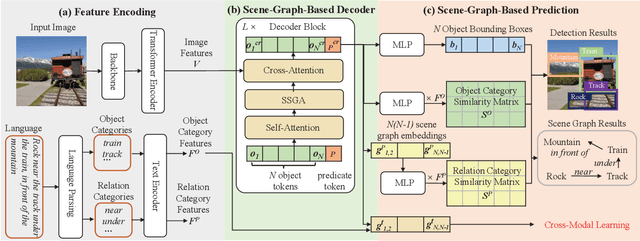
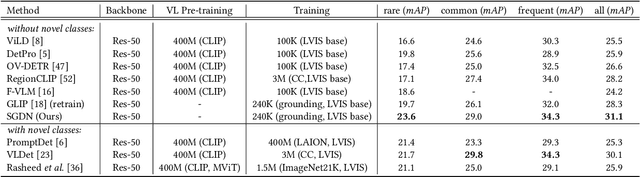
In recent years, open-vocabulary (OV) object detection has attracted increasing research attention. Unlike traditional detection, which only recognizes fixed-category objects, OV detection aims to detect objects in an open category set. Previous works often leverage vision-language (VL) training data (e.g., referring grounding data) to recognize OV objects. However, they only use pairs of nouns and individual objects in VL data, while these data usually contain much more information, such as scene graphs, which are also crucial for OV detection. In this paper, we propose a novel Scene-Graph-Based Discovery Network (SGDN) that exploits scene graph cues for OV detection. Firstly, a scene-graph-based decoder (SGDecoder) including sparse scene-graph-guided attention (SSGA) is presented. It captures scene graphs and leverages them to discover OV objects. Secondly, we propose scene-graph-based prediction (SGPred), where we build a scene-graph-based offset regression (SGOR) mechanism to enable mutual enhancement between scene graph extraction and object localization. Thirdly, we design a cross-modal learning mechanism in SGPred. It takes scene graphs as bridges to improve the consistency between cross-modal embeddings for OV object classification. Experiments on COCO and LVIS demonstrate the effectiveness of our approach. Moreover, we show the ability of our model for OV scene graph detection, while previous OV scene graph generation methods cannot tackle this task.
"Glitch in the Matrix!": A Large Scale Benchmark for Content Driven Audio-Visual Forgery Detection and Localization
May 05, 2023



Most deepfake detection methods focus on detecting spatial and/or spatio-temporal changes in facial attributes. This is because available benchmark datasets contain mostly visual-only modifications. However, a sophisticated deepfake may include small segments of audio or audio-visual manipulations that can completely change the meaning of the content. To addresses this gap, we propose and benchmark a new dataset, Localized Audio Visual DeepFake (LAV-DF), consisting of strategic content-driven audio, visual and audio-visual manipulations. The proposed baseline method, Boundary Aware Temporal Forgery Detection (BA-TFD), is a 3D Convolutional Neural Network-based architecture which efficiently captures multimodal manipulations. We further improve (i.e. BA-TFD+) the baseline method by replacing the backbone with a Multiscale Vision Transformer and guide the training process with contrastive, frame classification, boundary matching and multimodal boundary matching loss functions. The quantitative analysis demonstrates the superiority of BA- TFD+ on temporal forgery localization and deepfake detection tasks using several benchmark datasets including our newly proposed dataset. The dataset, models and code are available at https://github.com/ControlNet/LAV-DF.
Real-time Trajectory-based Social Group Detection
Apr 12, 2023



Social group detection is a crucial aspect of various robotic applications, including robot navigation and human-robot interactions. To date, a range of model-based techniques have been employed to address this challenge, such as the F-formation and trajectory similarity frameworks. However, these approaches often fail to provide reliable results in crowded and dynamic scenarios. Recent advancements in this area have mainly focused on learning-based methods, such as deep neural networks that use visual content or human pose. Although visual content-based methods have demonstrated promising performance on large-scale datasets, their computational complexity poses a significant barrier to their practical use in real-time applications. To address these issues, we propose a simple and efficient framework for social group detection. Our approach explores the impact of motion trajectory on social grouping and utilizes a novel, reliable, and fast data-driven method. We formulate the individuals in a scene as a graph, where the nodes are represented by LSTM-encoded trajectories and the edges are defined by the distances between each pair of tracks. Our framework employs a modified graph transformer module and graph clustering losses to detect social groups. Our experiments on the popular JRDBAct dataset reveal noticeable improvements in performance, with relative improvements ranging from 2% to 11%. Furthermore, our framework is significantly faster, with up to 12x faster inference times compared to state-of-the-art methods under the same computation resources. These results demonstrate that our proposed method is suitable for real-time robotic applications.