 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatterns, predictions, and actions: A story about machine learning
Feb 10, 2021


This graduate textbook on machine learning tells a story of how patterns in data support predictions and consequential actions. Starting with the foundations of decision making, we cover representation, optimization, and generalization as the constituents of supervised learning. A chapter on datasets as benchmarks examines their histories and scientific bases. Self-contained introductions to causality, the practice of causal inference, sequential decision making, and reinforcement learning equip the reader with concepts and tools to reason about actions and their consequences. Throughout, the text discusses historical context and societal impact. We invite readers from all backgrounds; some experience with probability, calculus, and linear algebra suffices.
Revisiting Design Choices in Proximal Policy Optimization
Sep 23, 2020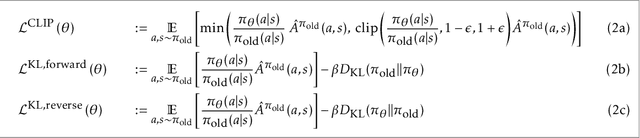

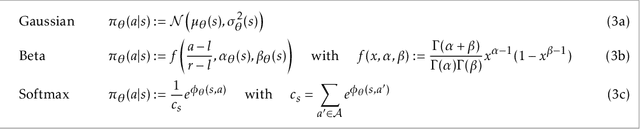
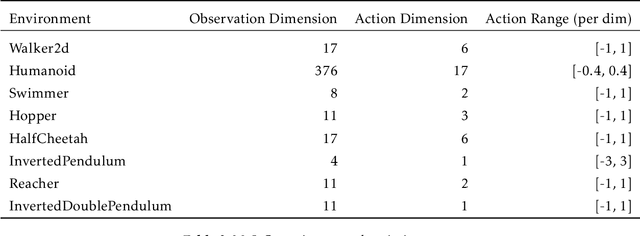
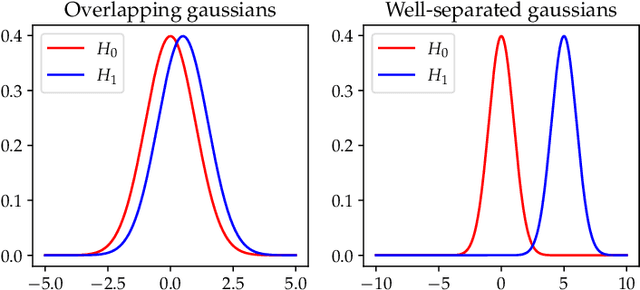
Proximal Policy Optimization (PPO) is a popular deep policy gradient algorithm. In standard implementations, PPO regularizes policy updates with clipped probability ratios, and parameterizes policies with either continuous Gaussian distributions or discrete Softmax distributions. These design choices are widely accepted, and motivated by empirical performance comparisons on MuJoCo and Atari benchmarks. We revisit these practices outside the regime of current benchmarks, and expose three failure modes of standard PPO. We explain why standard design choices are problematic in these cases, and show that alternative choices of surrogate objectives and policy parameterizations can prevent the failure modes. We hope that our work serves as a reminder that many algorithmic design choices in reinforcement learning are tied to specific simulation environments. We should not implicitly accept these choices as a standard part of a more general algorithm.
From Optimizing Engagement to Measuring Value
Aug 21, 2020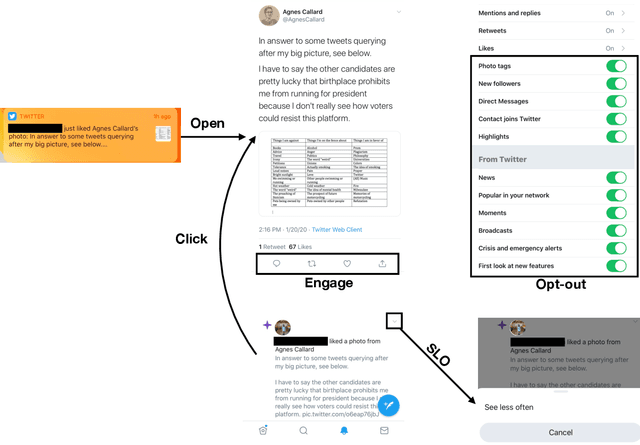
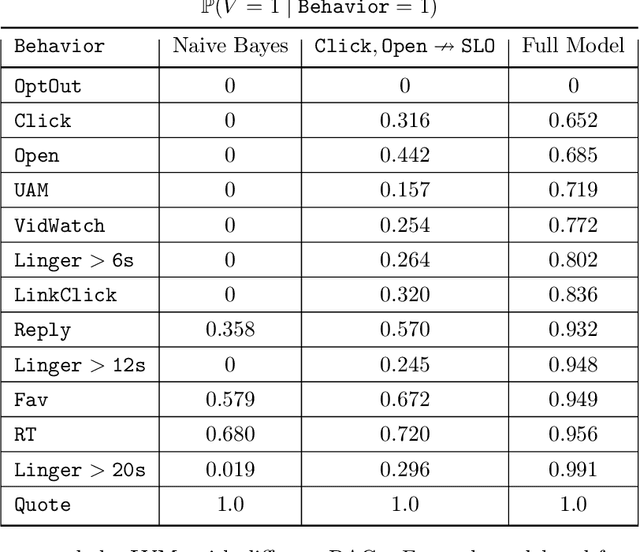
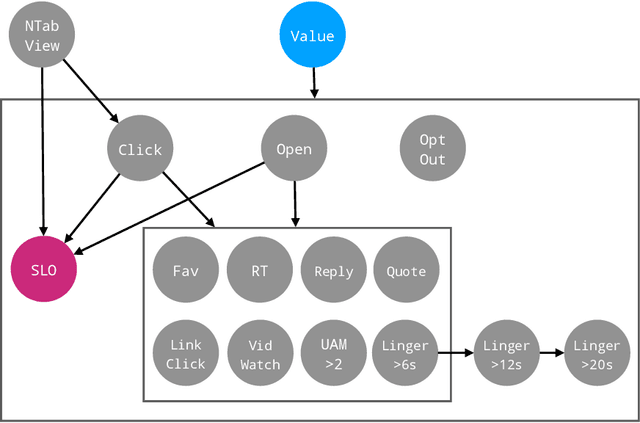
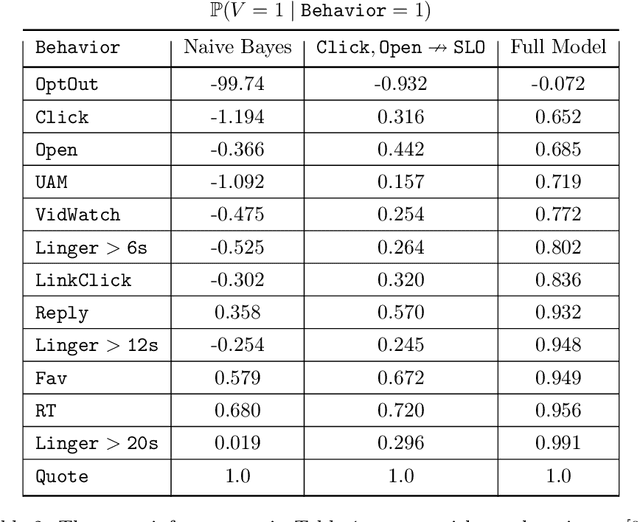
Most recommendation engines today are based on predicting user engagement, e.g. predicting whether a user will click on an item or not. However, there is potentially a large gap between engagement signals and a desired notion of "value" that is worth optimizing for. We use the framework of measurement theory to (a) confront the designer with a normative question about what the designer values, (b) provide a general latent variable model approach that can be used to operationalize the target construct and directly optimize for it, and (c) guide the designer in evaluating and revising their operationalization. We implement our approach on the Twitter platform on millions of users. In line with established approaches to assessing the validity of measurements, we perform a qualitative evaluation of how well our model captures a desired notion of "value".
Stochastic Optimization for Performative Prediction
Jun 16, 2020
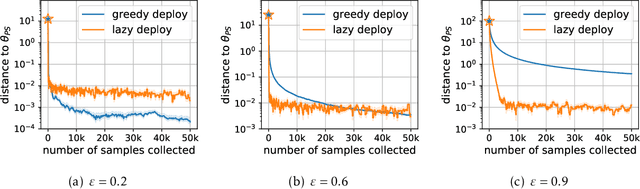
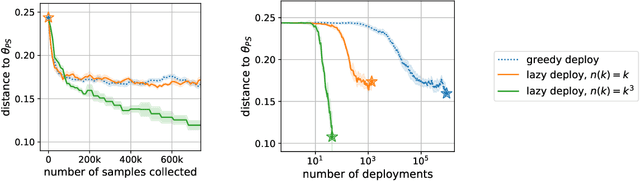
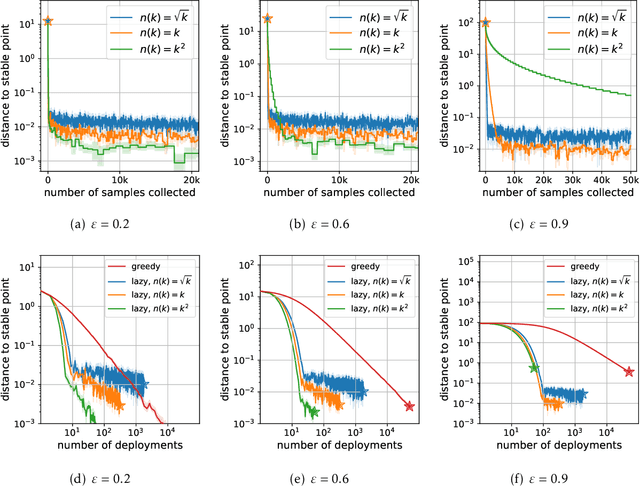
In performative prediction, the choice of a model influences the distribution of future data, typically through actions taken based on the model's predictions. We initiate the study of stochastic optimization for performative prediction. What sets this setting apart from traditional stochastic optimization is the difference between merely updating model parameters and deploying the new model. The latter triggers a shift in the distribution that affects future data, while the former keeps the distribution as is. Assuming smoothness and strong convexity, we prove non-asymptotic rates of convergence for both greedily deploying models after each stochastic update (greedy deploy) as well as for taking several updates before redeploying (lazy deploy). In both cases, our bounds smoothly recover the optimal $O(1/k)$ rate as the strength of performativity decreases. Furthermore, they illustrate how depending on the strength of performative effects, there exists a regime where either approach outperforms the other. We experimentally explore this trade-off on both synthetic data and a strategic classification simulator.
Balancing Competing Objectives with Noisy Data: Score-Based Classifiers for Welfare-Aware Machine Learning
Mar 15, 2020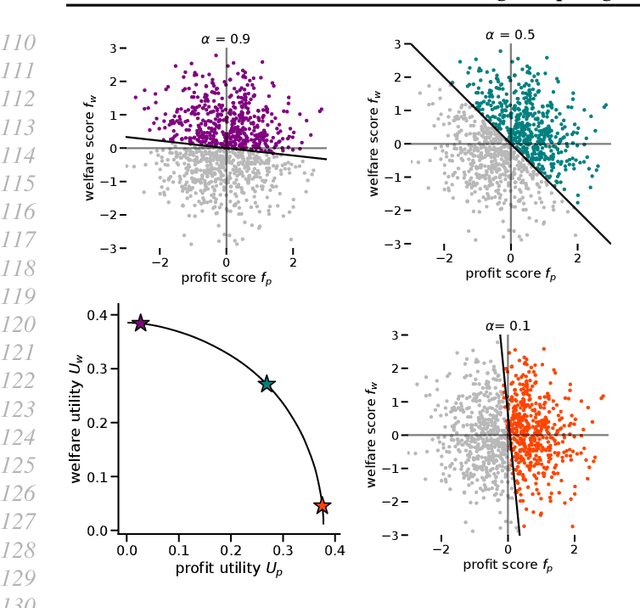
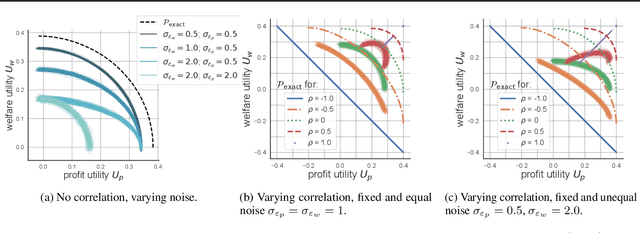
While real-world decisions involve many competing objectives, algorithmic decisions are often evaluated with a single objective function. In this paper, we study algorithmic policies which explicitly trade off between a private objective (such as profit) and a public objective (such as social welfare). We analyze a natural class of policies which trace an empirical Pareto frontier based on learned scores, and focus on how such decisions can be made in noisy or data-limited regimes. Our theoretical results characterize the optimal strategies in this class, bound the Pareto errors due to inaccuracies in the scores, and show an equivalence between optimal strategies and a rich class of fairness-constrained profit-maximizing policies. We then present empirical results in two different contexts --- online content recommendation and sustainable abalone fisheries --- to underscore the applicability of our approach to a wide range of practical decisions. Taken together, these results shed light on inherent trade-offs in using machine learning for decisions that impact social welfare.
Performative Prediction
Feb 16, 2020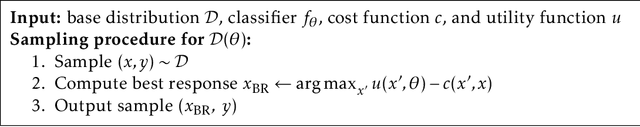
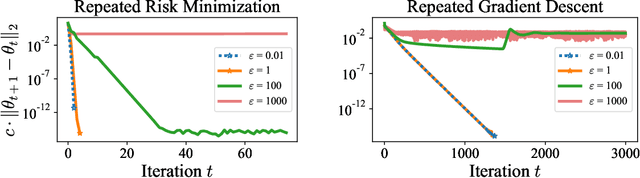
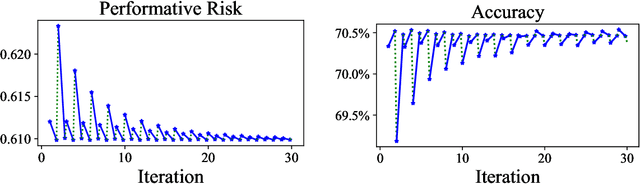
When predictions support decisions they may influence the outcome they aim to predict. We call such predictions performative; the prediction influences the target. Performativity is a well-studied phenomenon in policy-making that has so far been neglected in supervised learning. When ignored, performativity surfaces as undesirable distribution shift, routinely addressed with retraining. We develop a risk minimization framework for performative prediction bringing together concepts from statistics, game theory, and causality. A conceptual novelty is an equilibrium notion we call performative stability. Performative stability implies that the predictions are calibrated not against past outcomes, but against the future outcomes that manifest from acting on the prediction. Our main results are necessary and sufficient conditions for the convergence of retraining to a performatively stable point of nearly minimal loss. In full generality, performative prediction strictly subsumes the setting known as strategic classification. We thus also give the first sufficient conditions for retraining to overcome strategic feedback effects.
Strategic Adaptation to Classifiers: A Causal Perspective
Nov 01, 2019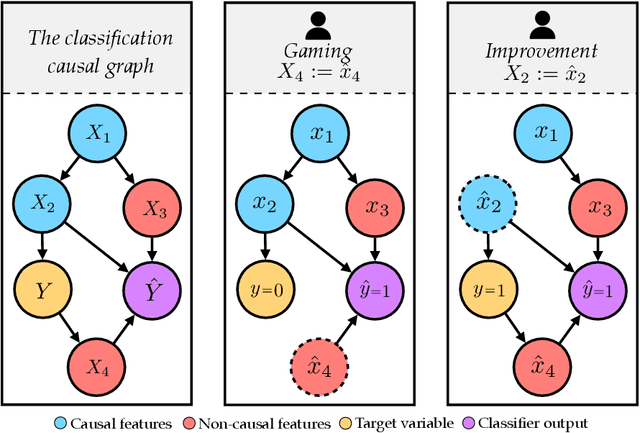
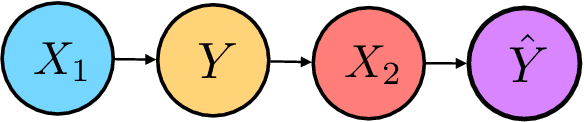
Consequential decision-making incentivizes individuals to adapt their behavior to the specifics of the decision rule. A long line of work has therefore sought to understand and anticipate adaptation, both to prevent strategic individuals from "gaming" the decision rule and to explicitly motivate individuals to improve. In this work, we frame the problem of adaptation as performing interventions in a causal graph. With this causal perspective, we make several contributions. First, we articulate a formal distinction between gaming and improvement. Second, we formalize strategic classification in a new way that recognizes that the individual may improve, rather than only game. In this setting, we show that it is beneficial for the decision-maker to incentivize improvement. Third, we give a reduction from causal inference to designing incentivizes for improvement. This shows that designing good incentives, while desirable, is at least as hard as causal inference.
Test-Time Training for Out-of-Distribution Generalization
Oct 25, 2019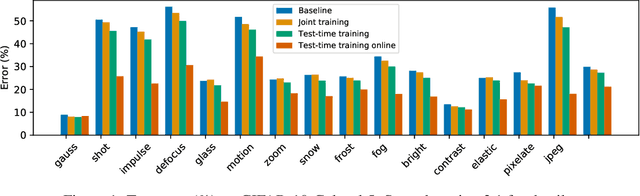
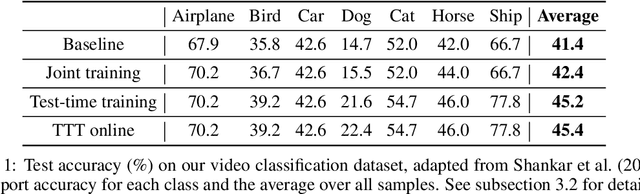
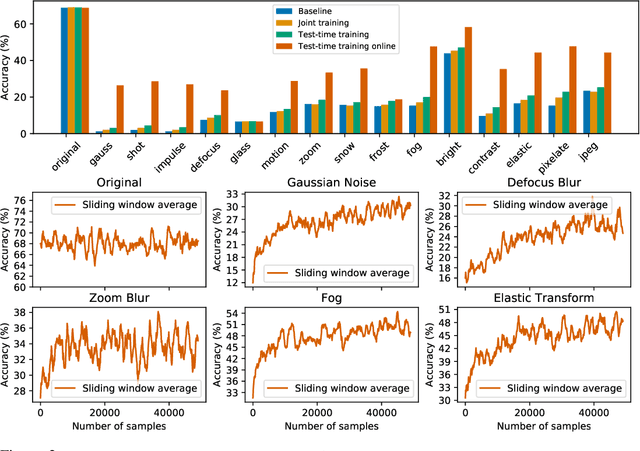
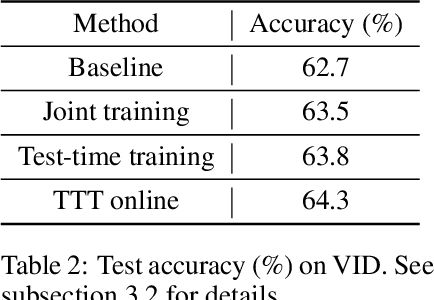
We introduce a general approach, called test-time training, for improving the performance of predictive models when test and training data come from different distributions. Test-time training turns a single unlabeled test instance into a self-supervised learning problem, on which we update the model parameters before making a prediction on this instance. We show that this simple idea leads to surprising improvements on diverse image classification benchmarks aimed at evaluating robustness to distribution shifts. Theoretical investigations on a convex model reveal helpful intuitions for when we can expect our approach to help.
Linear Dynamics: Clustering without identification
Sep 02, 2019
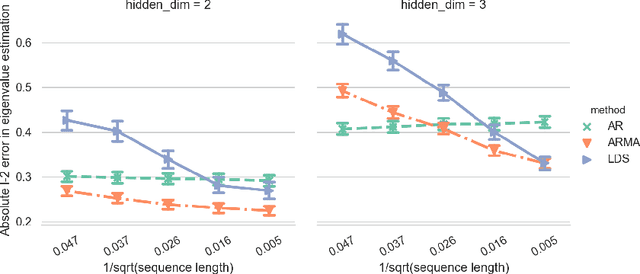
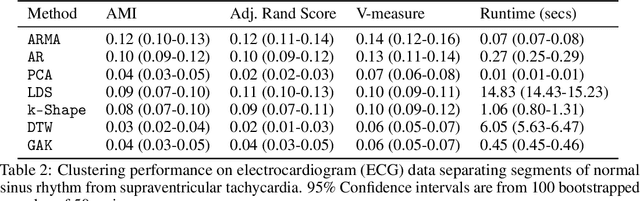
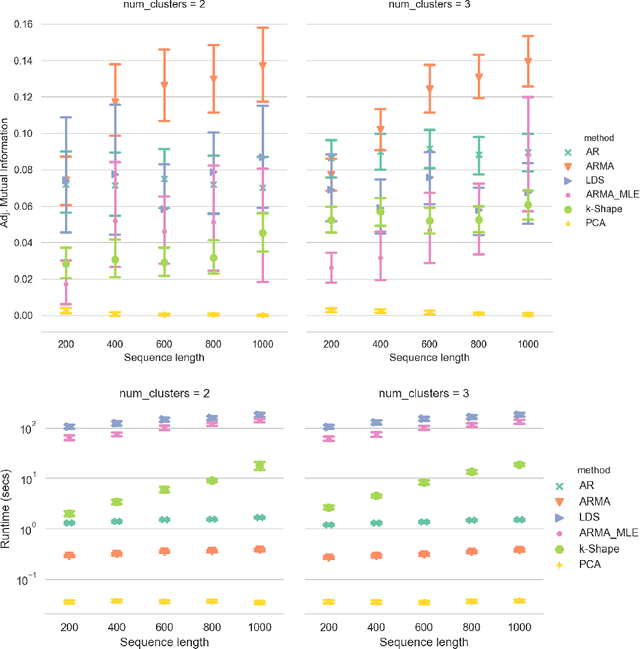
Clustering time series is a delicate task; varying lengths and temporal offsets obscure direct comparisons. A natural strategy is to learn a parametric model foreach time series and to cluster the model parameters rather than the sequences themselves. Linear dynamical systems are a fundamental and powerful parametric model class. However, identifying the parameters of a linear dynamical systems is a venerable task, permitting provably efficient solutions only in special cases. In this work, we show that clustering the parameters of unknown linear dynamical systems is, in fact, easier than identifying them. We analyze a computationally efficient clustering algorithm that enjoys provable convergence guarantees under a natural separation assumption. Although easy to implement, our algorithm is general, handling multi-dimensional data with time offsets and partial sequences. Evaluating our algorithm on both synthetic data and real electrocardiogram (ECG) signals, we see significant improvements in clustering quality over existing baselines.
Explaining an increase in predicted risk for clinical alerts
Jul 10, 2019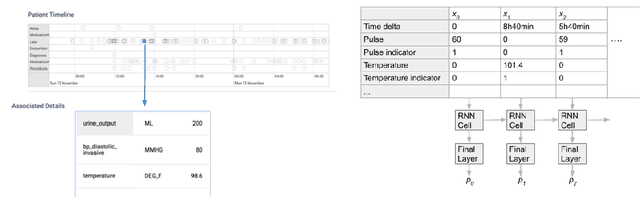
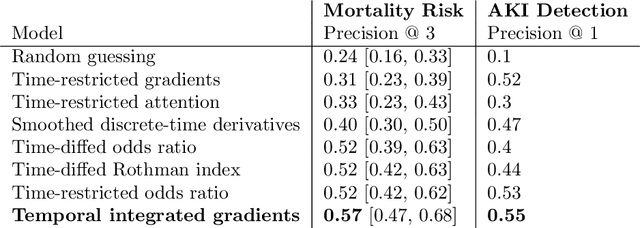

Much work aims to explain a model's prediction on a static input. We consider explanations in a temporal setting where a stateful dynamical model produces a sequence of risk estimates given an input at each time step. When the estimated risk increases, the goal of the explanation is to attribute the increase to a few relevant inputs from the past. While our formal setup and techniques are general, we carry out an in-depth case study in a clinical setting. The goal here is to alert a clinician when a patient's risk of deterioration rises. The clinician then has to decide whether to intervene and adjust the treatment. Given a potentially long sequence of new events since she last saw the patient, a concise explanation helps her to quickly triage the alert. We develop methods to lift static attribution techniques to the dynamical setting, where we identify and address challenges specific to dynamics. We then experimentally assess the utility of different explanations of clinical alerts through expert evaluation.