 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Parametric Scenes from Very Few Time-of-Flight Pixels
Sep 19, 2025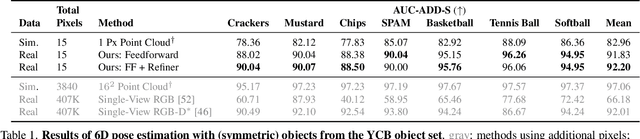
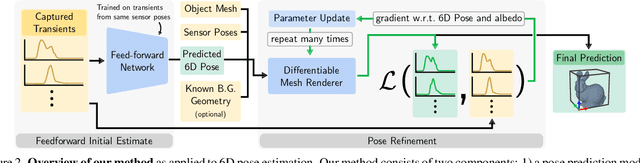
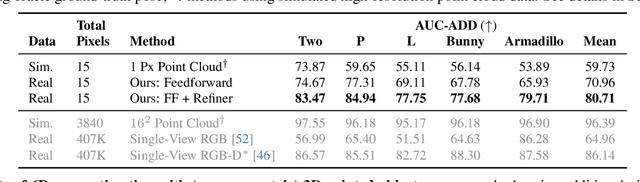
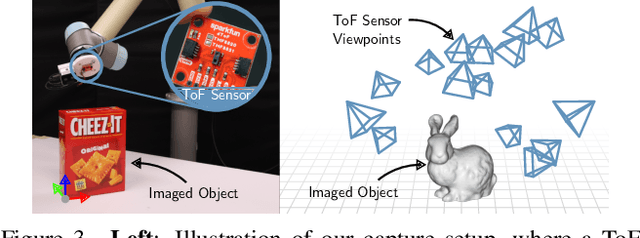
We aim to recover the geometry of 3D parametric scenes using very few depth measurements from low-cost, commercially available time-of-flight sensors. These sensors offer very low spatial resolution (i.e., a single pixel), but image a wide field-of-view per pixel and capture detailed time-of-flight data in the form of time-resolved photon counts. This time-of-flight data encodes rich scene information and thus enables recovery of simple scenes from sparse measurements. We investigate the feasibility of using a distributed set of few measurements (e.g., as few as 15 pixels) to recover the geometry of simple parametric scenes with a strong prior, such as estimating the 6D pose of a known object. To achieve this, we design a method that utilizes both feed-forward prediction to infer scene parameters, and differentiable rendering within an analysis-by-synthesis framework to refine the scene parameter estimate. We develop hardware prototypes and demonstrate that our method effectively recovers object pose given an untextured 3D model in both simulations and controlled real-world captures, and show promising initial results for other parametric scenes. We additionally conduct experiments to explore the limits and capabilities of our imaging solution.
Efficient Detection of Objects Near a Robot Manipulator via Miniature Time-of-Flight Sensors
Sep 19, 2025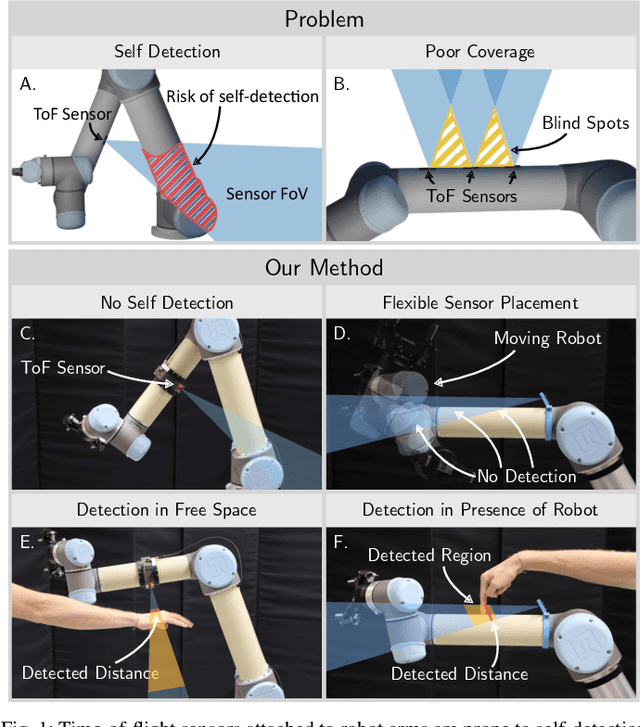
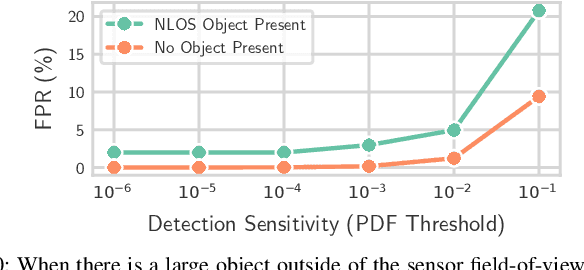
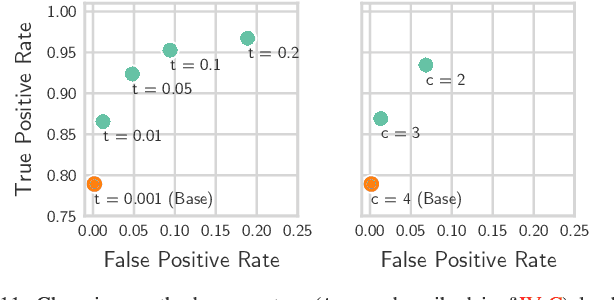
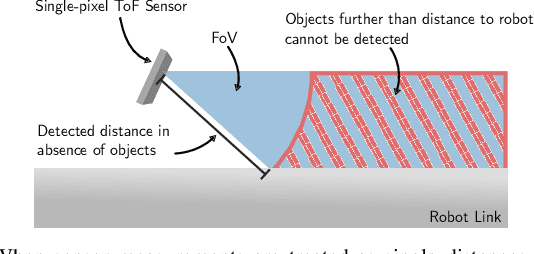
We provide a method for detecting and localizing objects near a robot arm using arm-mounted miniature time-of-flight sensors. A key challenge when using arm-mounted sensors is differentiating between the robot itself and external objects in sensor measurements. To address this challenge, we propose a computationally lightweight method which utilizes the raw time-of-flight information captured by many off-the-shelf, low-resolution time-of-flight sensor. We build an empirical model of expected sensor measurements in the presence of the robot alone, and use this model at runtime to detect objects in proximity to the robot. In addition to avoiding robot self-detections in common sensor configurations, the proposed method enables extra flexibility in sensor placement, unlocking configurations which achieve more efficient coverage of a radius around the robot arm. Our method can detect small objects near the arm and localize the position of objects along the length of a robot link to reasonable precision. We evaluate the performance of the method with respect to object type, location, and ambient light level, and identify limiting factors on performance inherent in the measurement principle. The proposed method has potential applications in collision avoidance and in facilitating safe human-robot interaction.
Agentic LLMs for Question Answering over Tabular Data
Sep 11, 2025Question Answering over Tabular Data (Table QA) presents unique challenges due to the diverse structure, size, and data types of real-world tables. The SemEval 2025 Task 8 (DataBench) introduced a benchmark composed of large-scale, domain-diverse datasets to evaluate the ability of models to accurately answer structured queries. We propose a Natural Language to SQL (NL-to-SQL) approach leveraging large language models (LLMs) such as GPT-4o, GPT-4o-mini, and DeepSeek v2:16b to generate SQL queries dynamically. Our system follows a multi-stage pipeline involving example selection, SQL query generation, answer extraction, verification, and iterative refinement. Experiments demonstrate the effectiveness of our approach, achieving 70.5\% accuracy on DataBench QA and 71.6\% on DataBench Lite QA, significantly surpassing baseline scores of 26\% and 27\% respectively. This paper details our methodology, experimental results, and alternative approaches, providing insights into the strengths and limitations of LLM-driven Table QA.
Improving Narrative Classification and Explanation via Fine Tuned Language Models
Sep 04, 2025Understanding covert narratives and implicit messaging is essential for analyzing bias and sentiment. Traditional NLP methods struggle with detecting subtle phrasing and hidden agendas. This study tackles two key challenges: (1) multi-label classification of narratives and sub-narratives in news articles, and (2) generating concise, evidence-based explanations for dominant narratives. We fine-tune a BERT model with a recall-oriented approach for comprehensive narrative detection, refining predictions using a GPT-4o pipeline for consistency. For narrative explanation, we propose a ReACT (Reasoning + Acting) framework with semantic retrieval-based few-shot prompting, ensuring grounded and relevant justifications. To enhance factual accuracy and reduce hallucinations, we incorporate a structured taxonomy table as an auxiliary knowledge base. Our results show that integrating auxiliary knowledge in prompts improves classification accuracy and justification reliability, with applications in media analysis, education, and intelligence gathering.
Robust 3D Object Detection using Probabilistic Point Clouds from Single-Photon LiDARs
Jul 31, 2025LiDAR-based 3D sensors provide point clouds, a canonical 3D representation used in various scene understanding tasks. Modern LiDARs face key challenges in several real-world scenarios, such as long-distance or low-albedo objects, producing sparse or erroneous point clouds. These errors, which are rooted in the noisy raw LiDAR measurements, get propagated to downstream perception models, resulting in potentially severe loss of accuracy. This is because conventional 3D processing pipelines do not retain any uncertainty information from the raw measurements when constructing point clouds. We propose Probabilistic Point Clouds (PPC), a novel 3D scene representation where each point is augmented with a probability attribute that encapsulates the measurement uncertainty (or confidence) in the raw data. We further introduce inference approaches that leverage PPC for robust 3D object detection; these methods are versatile and can be used as computationally lightweight drop-in modules in 3D inference pipelines. We demonstrate, via both simulations and real captures, that PPC-based 3D inference methods outperform several baselines using LiDAR as well as camera-LiDAR fusion models, across challenging indoor and outdoor scenarios involving small, distant, and low-albedo objects, as well as strong ambient light. Our project webpage is at https://bhavyagoyal.github.io/ppc .
INSPIRE-GNN: Intelligent Sensor Placement to Improve Sparse Bicycling Network Prediction via Reinforcement Learning Boosted Graph Neural Networks
Jul 31, 2025Accurate link-level bicycling volume estimation is essential for sustainable urban transportation planning. However, many cities face significant challenges of high data sparsity due to limited bicycling count sensor coverage. To address this issue, we propose INSPIRE-GNN, a novel Reinforcement Learning (RL)-boosted hybrid Graph Neural Network (GNN) framework designed to optimize sensor placement and improve link-level bicycling volume estimation in data-sparse environments. INSPIRE-GNN integrates Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT) with a Deep Q-Network (DQN)-based RL agent, enabling a data-driven strategic selection of sensor locations to maximize estimation performance. Applied to Melbourne's bicycling network, comprising 15,933 road segments with sensor coverage on only 141 road segments (99% sparsity) - INSPIRE-GNN demonstrates significant improvements in volume estimation by strategically selecting additional sensor locations in deployments of 50, 100, 200 and 500 sensors. Our framework outperforms traditional heuristic methods for sensor placement such as betweenness centrality, closeness centrality, observed bicycling activity and random placement, across key metrics such as Mean Squared Error (MSE), Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE). Furthermore, our experiments benchmark INSPIRE-GNN against standard machine learning and deep learning models in the bicycle volume estimation performance, underscoring its effectiveness. Our proposed framework provides transport planners actionable insights to effectively expand sensor networks, optimize sensor placement and maximize volume estimation accuracy and reliability of bicycling data for informed transportation planning decisions.
Med-CoDE: Medical Critique based Disagreement Evaluation Framework
Apr 21, 2025The emergence of large language models (LLMs) has significantly influenced numerous fields, including healthcare, by enhancing the capabilities of automated systems to process and generate human-like text. However, despite their advancements, the reliability and accuracy of LLMs in medical contexts remain critical concerns. Current evaluation methods often lack robustness and fail to provide a comprehensive assessment of LLM performance, leading to potential risks in clinical settings. In this work, we propose Med-CoDE, a specifically designed evaluation framework for medical LLMs to address these challenges. The framework leverages a critique-based approach to quantitatively measure the degree of disagreement between model-generated responses and established medical ground truths. This framework captures both accuracy and reliability in medical settings. The proposed evaluation framework aims to fill the existing gap in LLM assessment by offering a systematic method to evaluate the quality and trustworthiness of medical LLMs. Through extensive experiments and case studies, we illustrate the practicality of our framework in providing a comprehensive and reliable evaluation of medical LLMs.
Enhancing LLMs for Physics Problem-Solving using Reinforcement Learning with Human-AI Feedback
Dec 06, 2024



Large Language Models (LLMs) have demonstrated strong capabilities in text-based tasks but struggle with the complex reasoning required for physics problems, particularly in advanced arithmetic and conceptual understanding. While some research has explored ways to enhance LLMs in physics education using techniques such as prompt engineering and Retrieval Augmentation Generation (RAG), not enough effort has been made in addressing their limitations in physics reasoning. This paper presents a novel approach to improving LLM performance on physics questions using Reinforcement Learning with Human and Artificial Intelligence Feedback (RLHAIF). We evaluate several reinforcement learning methods, including Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO), and Remax optimization. These methods are chosen to investigate RL policy performance with different settings on the PhyQA dataset, which includes challenging physics problems from high school textbooks. Our RLHAIF model, tested on leading LLMs like LLaMA2 and Mistral, achieved superior results, notably with the MISTRAL-PPO model, demonstrating marked improvements in reasoning and accuracy. It achieved high scores, with a 58.67 METEOR score and a 0.74 Reasoning score, making it a strong example for future physics reasoning research in this area.
Evaluating the effects of Data Sparsity on the Link-level Bicycling Volume Estimation: A Graph Convolutional Neural Network Approach
Oct 11, 2024



Accurate bicycling volume estimation is crucial for making informed decisions about future investments in bicycling infrastructure. Traditional link-level volume estimation models are effective for motorised traffic but face significant challenges when applied to the bicycling context because of sparse data and the intricate nature of bicycling mobility patterns. To the best of our knowledge, we present the first study to utilize a Graph Convolutional Network (GCN) architecture to model link-level bicycling volumes. We estimate the Annual Average Daily Bicycle (AADB) counts across the City of Melbourne, Australia using Strava Metro bicycling count data. To evaluate the effectiveness of the GCN model, we benchmark it against traditional machine learning models, such as linear regression, support vector machines, and random forest. Our results show that the GCN model performs better than these traditional models in predicting AADB counts, demonstrating its ability to capture the spatial dependencies inherent in bicycle traffic data. We further investigate how varying levels of data sparsity affect performance of the GCN architecture. The GCN architecture performs well and better up to 80% sparsity level, but its limitations become apparent as the data sparsity increases further, emphasizing the need for further research on handling extreme data sparsity in bicycling volume estimation. Our findings offer valuable insights for city planners aiming to improve bicycling infrastructure and promote sustainable transportation.
Photon Inhibition for Energy-Efficient Single-Photon Imaging
Sep 26, 2024Single-photon cameras (SPCs) are emerging as sensors of choice for various challenging imaging applications. One class of SPCs based on the single-photon avalanche diode (SPAD) detects individual photons using an avalanche process; the raw photon data can then be processed to extract scene information under extremely low light, high dynamic range, and rapid motion. Yet, single-photon sensitivity in SPADs comes at a cost -- each photon detection consumes more energy than that of a CMOS camera. This avalanche power significantly limits sensor resolution and could restrict widespread adoption of SPAD-based SPCs. We propose a computational-imaging approach called \emph{photon inhibition} to address this challenge. Photon inhibition strategically allocates detections in space and time based on downstream inference task goals and resource constraints. We develop lightweight, on-sensor computational inhibition policies that use past photon data to disable SPAD pixels in real-time, to select the most informative future photons. As case studies, we design policies tailored for image reconstruction and edge detection, and demonstrate, both via simulations and real SPC captured data, considerable reduction in photon detections (over 90\% of photons) while maintaining task performance metrics. Our work raises the question of ``which photons should be detected?'', and paves the way for future energy-efficient single-photon imaging.