 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Contextual Perception: How to Generalize to New Backgrounds and Ambiguous Objects
Jun 09, 2023



Biological vision systems make adaptive use of context to recognize objects in new settings with novel contexts as well as occluded or blurry objects in familiar settings. In this paper, we investigate how vision models adaptively use context for out-of-distribution (OOD) generalization and leverage our analysis results to improve model OOD generalization. First, we formulate two distinct OOD settings where the contexts are either irrelevant (Background-Invariance) or beneficial (Object-Disambiguation), reflecting the diverse contextual challenges faced in biological vision. We then analyze model performance in these two different OOD settings and demonstrate that models that excel in one setting tend to struggle in the other. Notably, prior works on learning causal features improve on one setting but hurt in the other. This underscores the importance of generalizing across both OOD settings, as this ability is crucial for both human cognition and robust AI systems. Next, to better understand the model properties contributing to OOD generalization, we use representational geometry analysis and our own probing methods to examine a population of models, and we discover that those with more factorized representations and appropriate feature weighting are more successful in handling Background-Invariance and Object-Disambiguation tests. We further validate these findings through causal intervention on representation factorization and feature weighting to demonstrate their causal effect on performance. Lastly, we propose new augmentation methods to enhance model generalization. These methods outperform strong baselines, yielding improvements in both in-distribution and OOD tests. In conclusion, to replicate the generalization abilities of biological vision, computer vision models must have factorized object vs. background representations and appropriately weight both kinds of features.
Resolving Interference When Merging Models
Jun 02, 2023



Transfer learning - i.e., further fine-tuning a pre-trained model on a downstream task - can confer significant advantages, including improved downstream performance, faster convergence, and better sample efficiency. These advantages have led to a proliferation of task-specific fine-tuned models, which typically can only perform a single task and do not benefit from one another. Recently, model merging techniques have emerged as a solution to combine multiple task-specific models into a single multitask model without performing additional training. However, existing merging methods often ignore the interference between parameters of different models, resulting in large performance drops when merging multiple models. In this paper, we demonstrate that prior merging techniques inadvertently lose valuable information due to two major sources of interference: (a) interference due to redundant parameter values and (b) disagreement on the sign of a given parameter's values across models. To address this, we propose our method, TrIm, Elect Sign & Merge (TIES-Merging), which introduces three novel steps when merging models: (1) resetting parameters that only changed a small amount during fine-tuning, (2) resolving sign conflicts, and (3) merging only the parameters that are in alignment with the final agreed-upon sign. We find that TIES-Merging outperforms several existing methods in diverse settings covering a range of modalities, domains, number of tasks, model sizes, architectures, and fine-tuning settings. We further analyze the impact of different types of interference on model parameters, highlight the importance of resolving sign interference. Our code is available at https://github.com/prateeky2806/ties-merging
PanoGen: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation
May 30, 2023Vision-and-Language Navigation (VLN) requires the agent to follow language instructions to navigate through 3D environments. One main challenge in VLN is the limited availability of photorealistic training environments, which makes it hard to generalize to new and unseen environments. To address this problem, we propose PanoGen, a generation method that can potentially create an infinite number of diverse panoramic environments conditioned on text. Specifically, we collect room descriptions by captioning the room images in existing Matterport3D environments, and leverage a state-of-the-art text-to-image diffusion model to generate the new panoramic environments. We use recursive outpainting over the generated images to create consistent 360-degree panorama views. Our new panoramic environments share similar semantic information with the original environments by conditioning on text descriptions, which ensures the co-occurrence of objects in the panorama follows human intuition, and creates enough diversity in room appearance and layout with image outpainting. Lastly, we explore two ways of utilizing PanoGen in VLN pre-training and fine-tuning. We generate instructions for paths in our PanoGen environments with a speaker built on a pre-trained vision-and-language model for VLN pre-training, and augment the visual observation with our panoramic environments during agents' fine-tuning to avoid overfitting to seen environments. Empirically, learning with our PanoGen environments achieves the new state-of-the-art on the Room-to-Room, Room-for-Room, and CVDN datasets. Pre-training with our PanoGen speaker data is especially effective for CVDN, which has under-specified instructions and needs commonsense knowledge. Lastly, we show that the agent can benefit from training with more generated panoramic environments, suggesting promising results for scaling up the PanoGen environments.
Non-Sequential Graph Script Induction via Multimedia Grounding
May 27, 2023Online resources such as WikiHow compile a wide range of scripts for performing everyday tasks, which can assist models in learning to reason about procedures. However, the scripts are always presented in a linear manner, which does not reflect the flexibility displayed by people executing tasks in real life. For example, in the CrossTask Dataset, 64.5% of consecutive step pairs are also observed in the reverse order, suggesting their ordering is not fixed. In addition, each step has an average of 2.56 frequent next steps, demonstrating "branching". In this paper, we propose the new challenging task of non-sequential graph script induction, aiming to capture optional and interchangeable steps in procedural planning. To automate the induction of such graph scripts for given tasks, we propose to take advantage of loosely aligned videos of people performing the tasks. In particular, we design a multimodal framework to ground procedural videos to WikiHow textual steps and thus transform each video into an observed step path on the latent ground truth graph script. This key transformation enables us to train a script knowledge model capable of both generating explicit graph scripts for learnt tasks and predicting future steps given a partial step sequence. Our best model outperforms the strongest pure text/vision baselines by 17.52% absolute gains on F1@3 for next step prediction and 13.8% absolute gains on Acc@1 for partial sequence completion. Human evaluation shows our model outperforming the WikiHow linear baseline by 48.76% absolute gains in capturing sequential and non-sequential step relationships.
Paxion: Patching Action Knowledge in Video-Language Foundation Models
May 26, 2023



Action knowledge involves the understanding of textual, visual, and temporal aspects of actions. We introduce the Action Dynamics Benchmark (ActionBench) containing two carefully designed probing tasks: Action Antonym and Video Reversal, which targets multimodal alignment capabilities and temporal understanding skills of the model, respectively. Despite recent video-language models' (VidLM) impressive performance on various benchmark tasks, our diagnostic tasks reveal their surprising deficiency (near-random performance) in action knowledge, suggesting that current models rely on object recognition abilities as a shortcut for action understanding. To remedy this, we propose a novel framework, Paxion, along with a new Discriminative Video Dynamics Modeling (DVDM) objective. The Paxion framework utilizes a Knowledge Patcher network to encode new action knowledge and a Knowledge Fuser component to integrate the Patcher into frozen VidLMs without compromising their existing capabilities. Due to limitations of the widely-used Video-Text Contrastive (VTC) loss for learning action knowledge, we introduce the DVDM objective to train the Knowledge Patcher. DVDM forces the model to encode the correlation between the action text and the correct ordering of video frames. Our extensive analyses show that Paxion and DVDM together effectively fill the gap in action knowledge understanding (~50% to 80%), while maintaining or improving performance on a wide spectrum of both object- and action-centric downstream tasks.
MixCE: Training Autoregressive Language Models by Mixing Forward and Reverse Cross-Entropies
May 26, 2023



Autoregressive language models are trained by minimizing the cross-entropy of the model distribution Q relative to the data distribution P -- that is, minimizing the forward cross-entropy, which is equivalent to maximum likelihood estimation (MLE). We have observed that models trained in this way may "over-generalize", in the sense that they produce non-human-like text. Moreover, we believe that reverse cross-entropy, i.e., the cross-entropy of P relative to Q, is a better reflection of how a human would evaluate text generated by a model. Hence, we propose learning with MixCE, an objective that mixes the forward and reverse cross-entropies. We evaluate models trained with this objective on synthetic data settings (where P is known) and real data, and show that the resulting models yield better generated text without complex decoding strategies. Our code and models are publicly available at https://github.com/bloomberg/mixce-acl2023
Visual Programming for Text-to-Image Generation and Evaluation
May 24, 2023



As large language models have demonstrated impressive performance in many domains, recent works have adopted language models (LMs) as controllers of visual modules for vision-and-language tasks. While existing work focuses on equipping LMs with visual understanding, we propose two novel interpretable/explainable visual programming frameworks for text-to-image (T2I) generation and evaluation. First, we introduce VPGen, an interpretable step-by-step T2I generation framework that decomposes T2I generation into three steps: object/count generation, layout generation, and image generation. We employ an LM to handle the first two steps (object/count generation and layout generation), by finetuning it on text-layout pairs. Our step-by-step T2I generation framework provides stronger spatial control than end-to-end models, the dominant approach for this task. Furthermore, we leverage the world knowledge of pretrained LMs, overcoming the limitation of previous layout-guided T2I works that can only handle predefined object classes. We demonstrate that our VPGen has improved control in counts/spatial relations/scales of objects than state-of-the-art T2I generation models. Second, we introduce VPEval, an interpretable and explainable evaluation framework for T2I generation based on visual programming. Unlike previous T2I evaluations with a single scoring model that is accurate in some skills but unreliable in others, VPEval produces evaluation programs that invoke a set of visual modules that are experts in different skills, and also provides visual+textual explanations of the evaluation results. Our analysis shows VPEval provides a more human-correlated evaluation for skill-specific and open-ended prompts than widely used single model-based evaluation. We hope our work encourages future progress on interpretable/explainable generation and evaluation for T2I models. Website: https://vp-t2i.github.io
Any-to-Any Generation via Composable Diffusion
May 19, 2023



We present Composable Diffusion (CoDi), a novel generative model capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities. Unlike existing generative AI systems, CoDi can generate multiple modalities in parallel and its input is not limited to a subset of modalities like text or image. Despite the absence of training datasets for many combinations of modalities, we propose to align modalities in both the input and output space. This allows CoDi to freely condition on any input combination and generate any group of modalities, even if they are not present in the training data. CoDi employs a novel composable generation strategy which involves building a shared multimodal space by bridging alignment in the diffusion process, enabling the synchronized generation of intertwined modalities, such as temporally aligned video and audio. Highly customizable and flexible, CoDi achieves strong joint-modality generation quality, and outperforms or is on par with the unimodal state-of-the-art for single-modality synthesis. The project page with demonstrations and code is at https://codi-gen.github.io
Self-Chained Image-Language Model for Video Localization and Question Answering
May 11, 2023



Recent studies have shown promising results on utilizing pre-trained image-language models for video question answering. While these image-language models can efficiently bootstrap the representation learning of video-language models, they typically concatenate uniformly sampled video frames as visual inputs without explicit language-aware, temporal modeling. When only a portion of a video input is relevant to the language query, such uniform frame sampling can often lead to missing important visual cues. Although humans often find a video moment to focus on and rewind the moment to answer questions, training a query-aware video moment localizer often requires expensive annotations and high computational costs. To address this issue, we propose Self-Chained Video Localization-Answering (SeViLA), a novel framework that leverages a single image-language model (BLIP-2) to tackle both temporal keyframe localization and QA on videos. SeViLA framework consists of two modules: Localizer and Answerer, where both are parameter-efficiently fine-tuned from BLIP-2. We chain these modules for cascaded inference and self-refinement. First, in the forward chain, the Localizer finds multiple language-aware keyframes in a video, which the Answerer uses to predict the answer. Second, in the reverse chain, the Answerer generates keyframe pseudo-labels to refine the Localizer, alleviating the need for expensive video moment localization annotations. SeViLA outperforms several strong baselines/previous works on five video QA and event prediction tasks, and achieves the state-of-the-art in both fine-tuning (NExT-QA, STAR) and zero-shot (NExT-QA, STAR, How2QA, VLEP) settings. We show a comprehensive analysis, e.g., the impact of Localizer, comparisons of Localizer with other temporal localization models, pre-training/self-refinement of Localizer, and varying the number of keyframes.
HistAlign: Improving Context Dependency in Language Generation by Aligning with History
May 08, 2023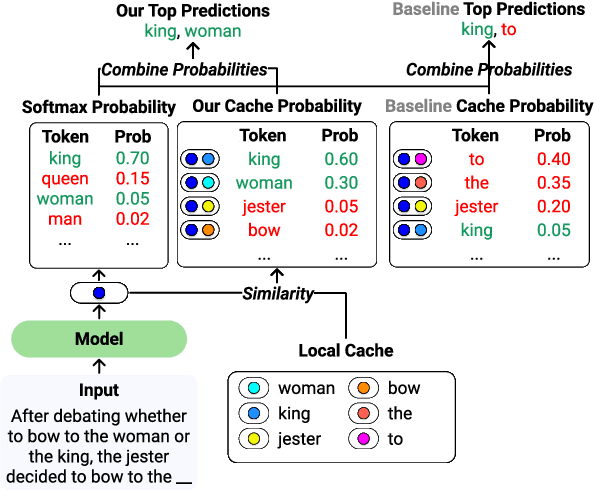
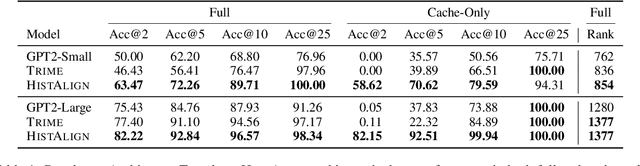
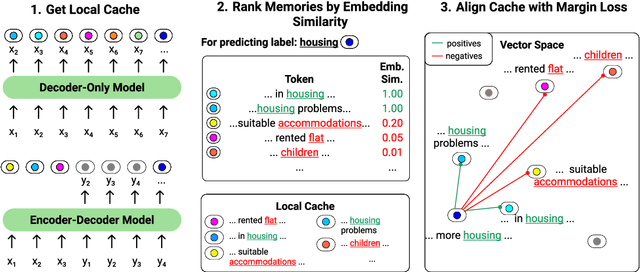

Language models (LMs) can generate hallucinations and incoherent outputs, which highlights their weak context dependency. Cache-LMs, which augment LMs with a memory of recent history, can increase context dependency and have shown remarkable performance in diverse language generation tasks. However, we find that even with training, the performance gain stemming from the cache component of current cache-LMs is suboptimal due to the misalignment between the current hidden states and those stored in the memory. In this work, we present HistAlign, a new training approach to ensure good cache alignment such that the model receives useful signals from the history. We first prove our concept on a simple and synthetic task where the memory is essential for correct predictions, and we show that the cache component of HistAlign is better aligned and improves overall performance. Next, we evaluate HistAlign on diverse downstream language generation tasks, including prompt continuation, abstractive summarization, and data-to-text. We demonstrate that HistAlign improves text coherence and faithfulness in open-ended and conditional generation settings respectively. HistAlign is also generalizable across different model families, showcasing its strength in improving context dependency of LMs in diverse scenarios. Our code is publicly available at https://github.com/meetdavidwan/histalign