 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Contextual Perception: How to Generalize to New Backgrounds and Ambiguous Objects
Jun 09, 2023



Biological vision systems make adaptive use of context to recognize objects in new settings with novel contexts as well as occluded or blurry objects in familiar settings. In this paper, we investigate how vision models adaptively use context for out-of-distribution (OOD) generalization and leverage our analysis results to improve model OOD generalization. First, we formulate two distinct OOD settings where the contexts are either irrelevant (Background-Invariance) or beneficial (Object-Disambiguation), reflecting the diverse contextual challenges faced in biological vision. We then analyze model performance in these two different OOD settings and demonstrate that models that excel in one setting tend to struggle in the other. Notably, prior works on learning causal features improve on one setting but hurt in the other. This underscores the importance of generalizing across both OOD settings, as this ability is crucial for both human cognition and robust AI systems. Next, to better understand the model properties contributing to OOD generalization, we use representational geometry analysis and our own probing methods to examine a population of models, and we discover that those with more factorized representations and appropriate feature weighting are more successful in handling Background-Invariance and Object-Disambiguation tests. We further validate these findings through causal intervention on representation factorization and feature weighting to demonstrate their causal effect on performance. Lastly, we propose new augmentation methods to enhance model generalization. These methods outperform strong baselines, yielding improvements in both in-distribution and OOD tests. In conclusion, to replicate the generalization abilities of biological vision, computer vision models must have factorized object vs. background representations and appropriately weight both kinds of features.
VisFIS: Visual Feature Importance Supervision with Right-for-the-Right-Reason Objectives
Jun 22, 2022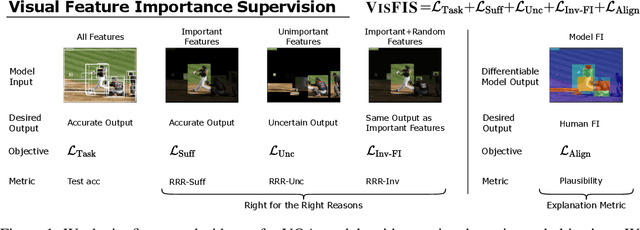
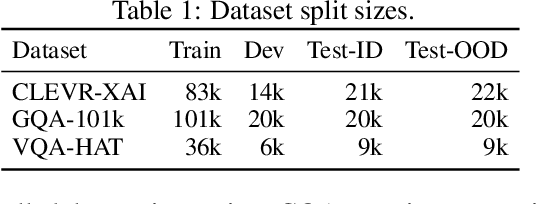
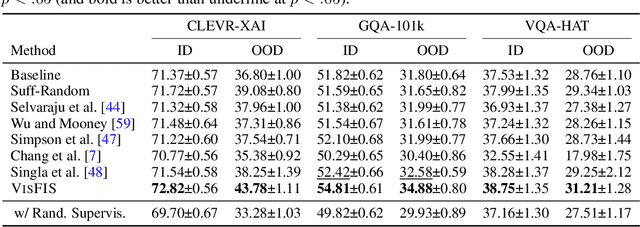
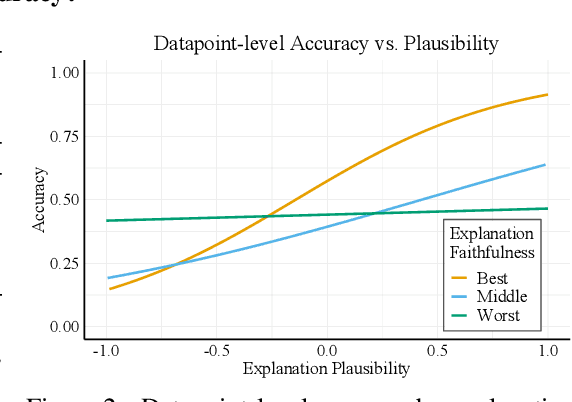
Many past works aim to improve visual reasoning in models by supervising feature importance (estimated by model explanation techniques) with human annotations such as highlights of important image regions. However, recent work has shown that performance gains from feature importance (FI) supervision for Visual Question Answering (VQA) tasks persist even with random supervision, suggesting that these methods do not meaningfully align model FI with human FI. In this paper, we show that model FI supervision can meaningfully improve VQA model accuracy as well as performance on several Right-for-the-Right-Reason (RRR) metrics by optimizing for four key model objectives: (1) accurate predictions given limited but sufficient information (Sufficiency); (2) max-entropy predictions given no important information (Uncertainty); (3) invariance of predictions to changes in unimportant features (Invariance); and (4) alignment between model FI explanations and human FI explanations (Plausibility). Our best performing method, Visual Feature Importance Supervision (VisFIS), outperforms strong baselines on benchmark VQA datasets in terms of both in-distribution and out-of-distribution accuracy. While past work suggests that the mechanism for improved accuracy is through improved explanation plausibility, we show that this relationship depends crucially on explanation faithfulness (whether explanations truly represent the model's internal reasoning). Predictions are more accurate when explanations are plausible and faithful, and not when they are plausible but not faithful. Lastly, we show that, surprisingly, RRR metrics are not predictive of out-of-distribution model accuracy when controlling for a model's in-distribution accuracy, which calls into question the value of these metrics for evaluating model reasoning. All supporting code is available at https://github.com/zfying/visfis
Can Deep Learning Recognize Subtle Human Activities?
Mar 30, 2020
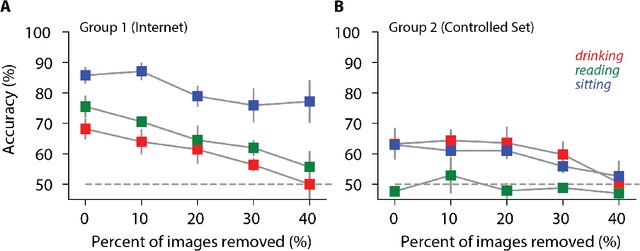
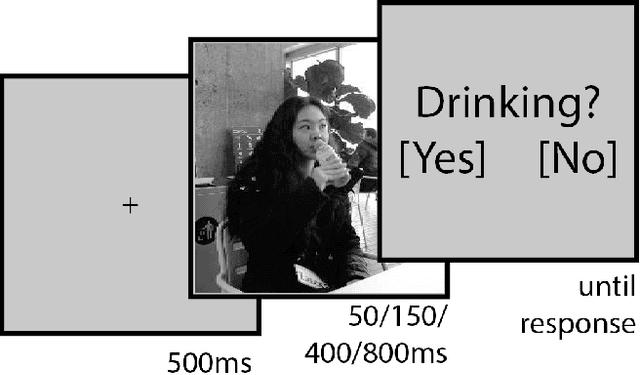
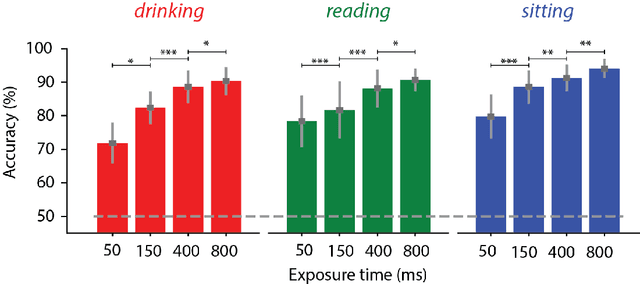
Deep Learning has driven recent and exciting progress in computer vision, instilling the belief that these algorithms could solve any visual task. Yet, datasets commonly used to train and test computer vision algorithms have pervasive confounding factors. Such biases make it difficult to truly estimate the performance of those algorithms and how well computer vision models can extrapolate outside the distribution in which they were trained. In this work, we propose a new action classification challenge that is performed well by humans, but poorly by state-of-the-art Deep Learning models. As a proof-of-principle, we consider three exemplary tasks: drinking, reading, and sitting. The best accuracies reached using state-of-the-art computer vision models were 61.7%, 62.8%, and 76.8%, respectively, while human participants scored above 90% accuracy on the three tasks. We propose a rigorous method to reduce confounds when creating datasets, and when comparing human versus computer vision performance. Source code and datasets are publicly available.