 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Value Networks Learn to Evaluate and Iteratively Refine Structured Outputs
Aug 08, 2017
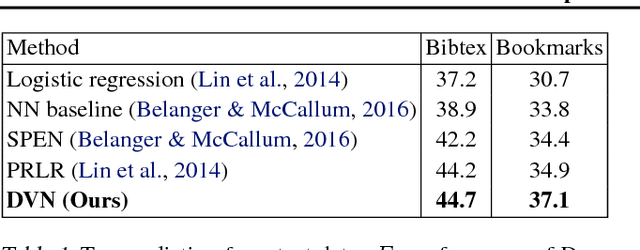
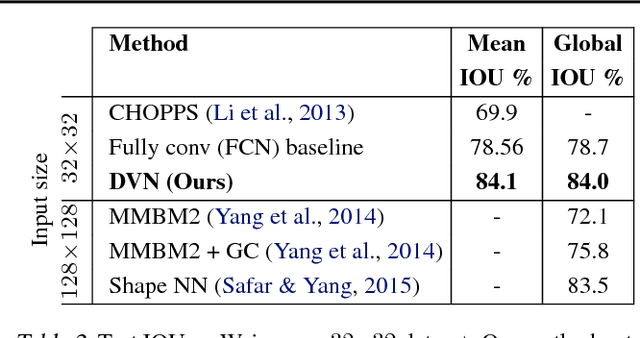
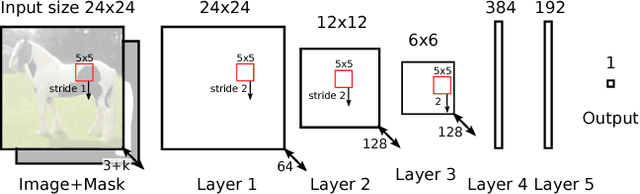
We approach structured output prediction by optimizing a deep value network (DVN) to precisely estimate the task loss on different output configurations for a given input. Once the model is trained, we perform inference by gradient descent on the continuous relaxations of the output variables to find outputs with promising scores from the value network. When applied to image segmentation, the value network takes an image and a segmentation mask as inputs and predicts a scalar estimating the intersection over union between the input and ground truth masks. For multi-label classification, the DVN's objective is to correctly predict the F1 score for any potential label configuration. The DVN framework achieves the state-of-the-art results on multi-label prediction and image segmentation benchmarks.
Device Placement Optimization with Reinforcement Learning
Jun 25, 2017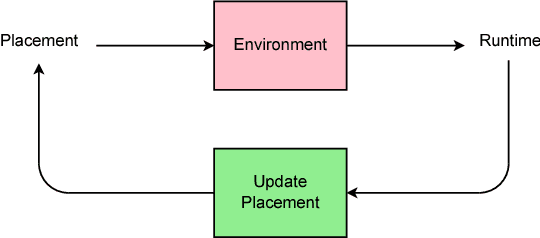
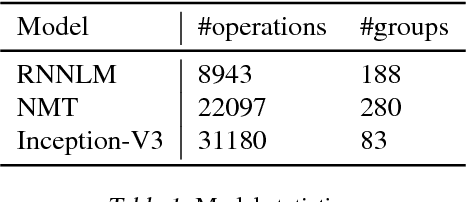
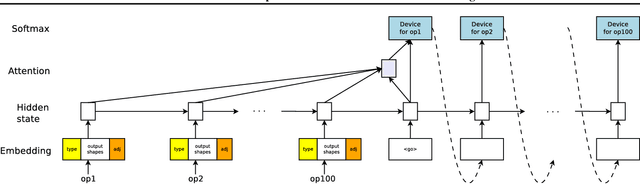
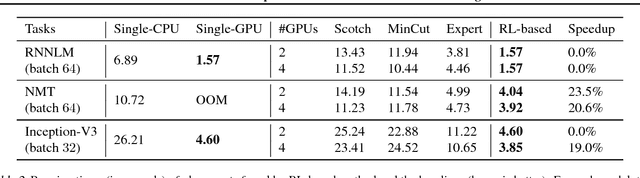
The past few years have witnessed a growth in size and computational requirements for training and inference with neural networks. Currently, a common approach to address these requirements is to use a heterogeneous distributed environment with a mixture of hardware devices such as CPUs and GPUs. Importantly, the decision of placing parts of the neural models on devices is often made by human experts based on simple heuristics and intuitions. In this paper, we propose a method which learns to optimize device placement for TensorFlow computational graphs. Key to our method is the use of a sequence-to-sequence model to predict which subsets of operations in a TensorFlow graph should run on which of the available devices. The execution time of the predicted placements is then used as the reward signal to optimize the parameters of the sequence-to-sequence model. Our main result is that on Inception-V3 for ImageNet classification, and on RNN LSTM, for language modeling and neural machine translation, our model finds non-trivial device placements that outperform hand-crafted heuristics and traditional algorithmic methods.
N-gram Language Modeling using Recurrent Neural Network Estimation
Jun 20, 2017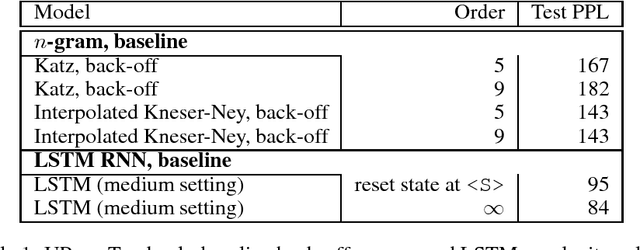
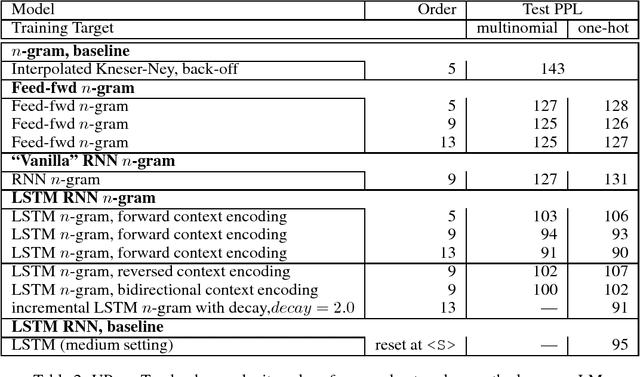


We investigate the effective memory depth of RNN models by using them for $n$-gram language model (LM) smoothing. Experiments on a small corpus (UPenn Treebank, one million words of training data and 10k vocabulary) have found the LSTM cell with dropout to be the best model for encoding the $n$-gram state when compared with feed-forward and vanilla RNN models. When preserving the sentence independence assumption the LSTM $n$-gram matches the LSTM LM performance for $n=9$ and slightly outperforms it for $n=13$. When allowing dependencies across sentence boundaries, the LSTM $13$-gram almost matches the perplexity of the unlimited history LSTM LM. LSTM $n$-gram smoothing also has the desirable property of improving with increasing $n$-gram order, unlike the Katz or Kneser-Ney back-off estimators. Using multinomial distributions as targets in training instead of the usual one-hot target is only slightly beneficial for low $n$-gram orders. Experiments on the One Billion Words benchmark show that the results hold at larger scale: while LSTM smoothing for short $n$-gram contexts does not provide significant advantages over classic N-gram models, it becomes effective with long contexts ($n > 5$); depending on the task and amount of data it can match fully recurrent LSTM models at about $n=13$. This may have implications when modeling short-format text, e.g. voice search/query LMs. Building LSTM $n$-gram LMs may be appealing for some practical situations: the state in a $n$-gram LM can be succinctly represented with $(n-1)*4$ bytes storing the identity of the words in the context and batches of $n$-gram contexts can be processed in parallel. On the downside, the $n$-gram context encoding computed by the LSTM is discarded, making the model more expensive than a regular recurrent LSTM LM.
PixColor: Pixel Recursive Colorization
Jun 05, 2017
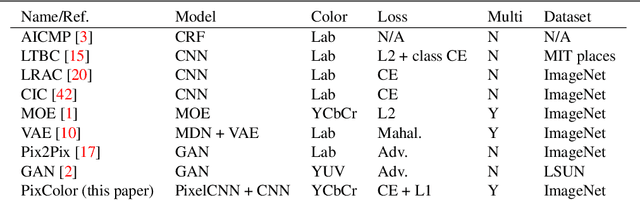


We propose a novel approach to automatically produce multiple colorized versions of a grayscale image. Our method results from the observation that the task of automated colorization is relatively easy given a low-resolution version of the color image. We first train a conditional PixelCNN to generate a low resolution color for a given grayscale image. Then, given the generated low-resolution color image and the original grayscale image as inputs, we train a second CNN to generate a high-resolution colorization of an image. We demonstrate that our approach produces more diverse and plausible colorizations than existing methods, as judged by human raters in a "Visual Turing Test".
Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders
Apr 05, 2017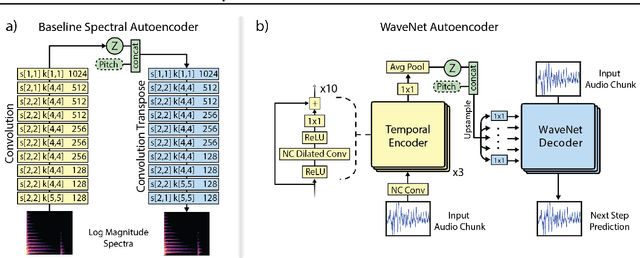
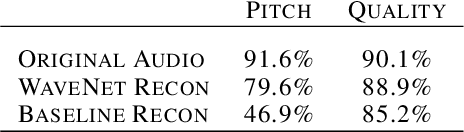

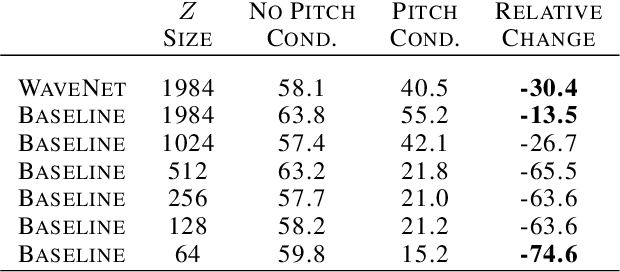
Generative models in vision have seen rapid progress due to algorithmic improvements and the availability of high-quality image datasets. In this paper, we offer contributions in both these areas to enable similar progress in audio modeling. First, we detail a powerful new WaveNet-style autoencoder model that conditions an autoregressive decoder on temporal codes learned from the raw audio waveform. Second, we introduce NSynth, a large-scale and high-quality dataset of musical notes that is an order of magnitude larger than comparable public datasets. Using NSynth, we demonstrate improved qualitative and quantitative performance of the WaveNet autoencoder over a well-tuned spectral autoencoder baseline. Finally, we show that the model learns a manifold of embeddings that allows for morphing between instruments, meaningfully interpolating in timbre to create new types of sounds that are realistic and expressive.
Pixel Recursive Super Resolution
Mar 22, 2017
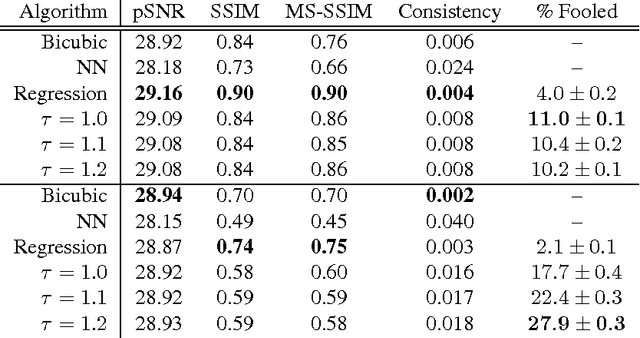
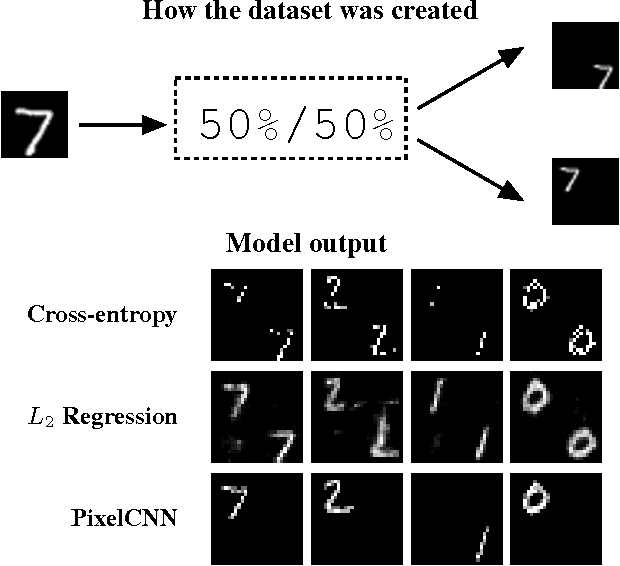
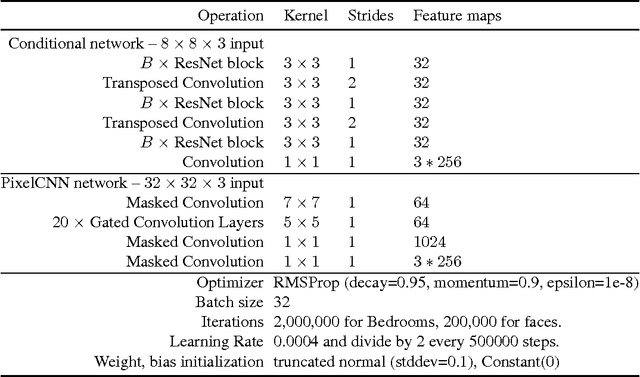
We present a pixel recursive super resolution model that synthesizes realistic details into images while enhancing their resolution. A low resolution image may correspond to multiple plausible high resolution images, thus modeling the super resolution process with a pixel independent conditional model often results in averaging different details--hence blurry edges. By contrast, our model is able to represent a multimodal conditional distribution by properly modeling the statistical dependencies among the high resolution image pixels, conditioned on a low resolution input. We employ a PixelCNN architecture to define a strong prior over natural images and jointly optimize this prior with a deep conditioning convolutional network. Human evaluations indicate that samples from our proposed model look more photo realistic than a strong L2 regression baseline.
Improving Policy Gradient by Exploring Under-appreciated Rewards
Mar 15, 2017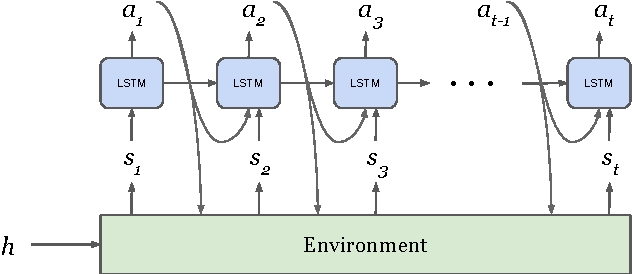
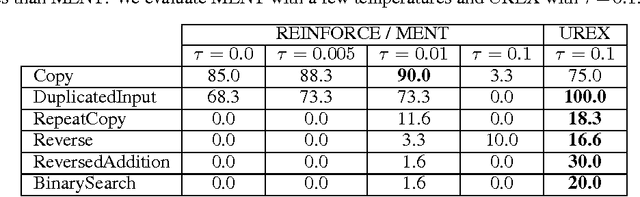
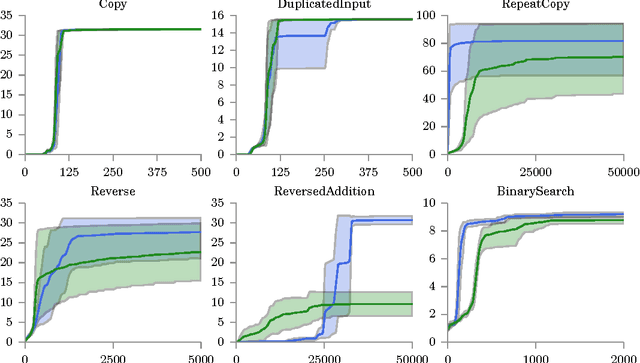
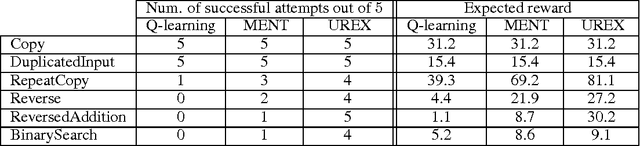
This paper presents a novel form of policy gradient for model-free reinforcement learning (RL) with improved exploration properties. Current policy-based methods use entropy regularization to encourage undirected exploration of the reward landscape, which is ineffective in high dimensional spaces with sparse rewards. We propose a more directed exploration strategy that promotes exploration of under-appreciated reward regions. An action sequence is considered under-appreciated if its log-probability under the current policy under-estimates its resulting reward. The proposed exploration strategy is easy to implement, requiring small modifications to an implementation of the REINFORCE algorithm. We evaluate the approach on a set of algorithmic tasks that have long challenged RL methods. Our approach reduces hyper-parameter sensitivity and demonstrates significant improvements over baseline methods. Our algorithm successfully solves a benchmark multi-digit addition task and generalizes to long sequences. This is, to our knowledge, the first time that a pure RL method has solved addition using only reward feedback.
Detecting Cancer Metastases on Gigapixel Pathology Images
Mar 08, 2017
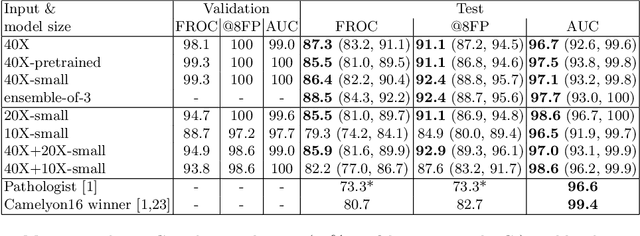
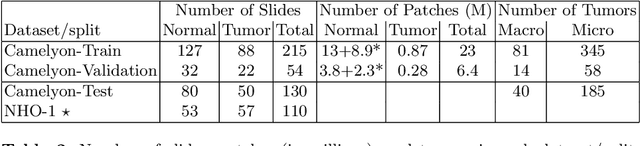
Each year, the treatment decisions for more than 230,000 breast cancer patients in the U.S. hinge on whether the cancer has metastasized away from the breast. Metastasis detection is currently performed by pathologists reviewing large expanses of biological tissues. This process is labor intensive and error-prone. We present a framework to automatically detect and localize tumors as small as 100 x 100 pixels in gigapixel microscopy images sized 100,000 x 100,000 pixels. Our method leverages a convolutional neural network (CNN) architecture and obtains state-of-the-art results on the Camelyon16 dataset in the challenging lesion-level tumor detection task. At 8 false positives per image, we detect 92.4% of the tumors, relative to 82.7% by the previous best automated approach. For comparison, a human pathologist attempting exhaustive search achieved 73.2% sensitivity. We achieve image-level AUC scores above 97% on both the Camelyon16 test set and an independent set of 110 slides. In addition, we discover that two slides in the Camelyon16 training set were erroneously labeled normal. Our approach could considerably reduce false negative rates in metastasis detection.
Neural Combinatorial Optimization with Reinforcement Learning
Jan 12, 2017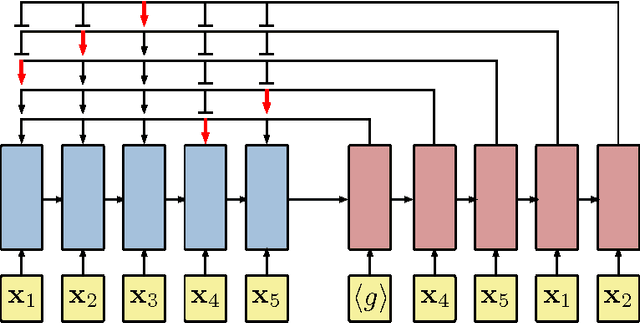
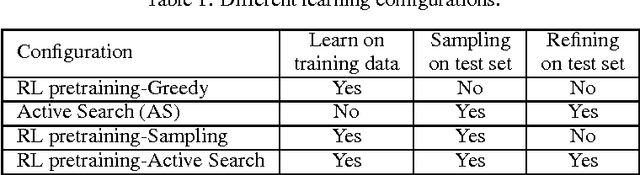


This paper presents a framework to tackle combinatorial optimization problems using neural networks and reinforcement learning. We focus on the traveling salesman problem (TSP) and train a recurrent network that, given a set of city coordinates, predicts a distribution over different city permutations. Using negative tour length as the reward signal, we optimize the parameters of the recurrent network using a policy gradient method. We compare learning the network parameters on a set of training graphs against learning them on individual test graphs. Despite the computational expense, without much engineering and heuristic designing, Neural Combinatorial Optimization achieves close to optimal results on 2D Euclidean graphs with up to 100 nodes. Applied to the KnapSack, another NP-hard problem, the same method obtains optimal solutions for instances with up to 200 items.
Reward Augmented Maximum Likelihood for Neural Structured Prediction
Jan 04, 2017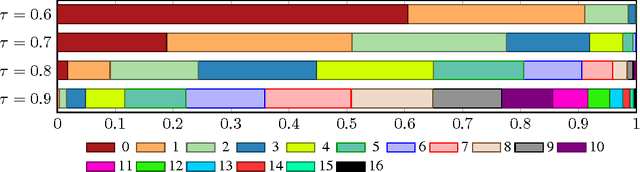
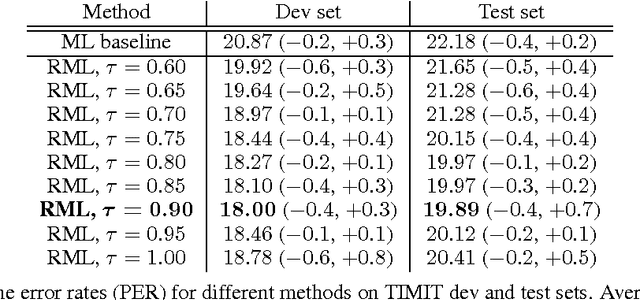
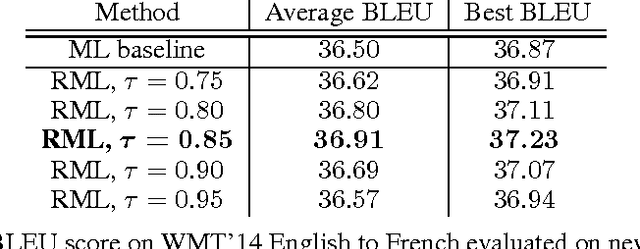
A key problem in structured output prediction is direct optimization of the task reward function that matters for test evaluation. This paper presents a simple and computationally efficient approach to incorporate task reward into a maximum likelihood framework. By establishing a link between the log-likelihood and expected reward objectives, we show that an optimal regularized expected reward is achieved when the conditional distribution of the outputs given the inputs is proportional to their exponentiated scaled rewards. Accordingly, we present a framework to smooth the predictive probability of the outputs using their corresponding rewards. We optimize the conditional log-probability of augmented outputs that are sampled proportionally to their exponentiated scaled rewards. Experiments on neural sequence to sequence models for speech recognition and machine translation show notable improvements over a maximum likelihood baseline by using reward augmented maximum likelihood (RAML), where the rewards are defined as the negative edit distance between the outputs and the ground truth labels.