 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottleneck Conditional Density Estimation
Jun 30, 2017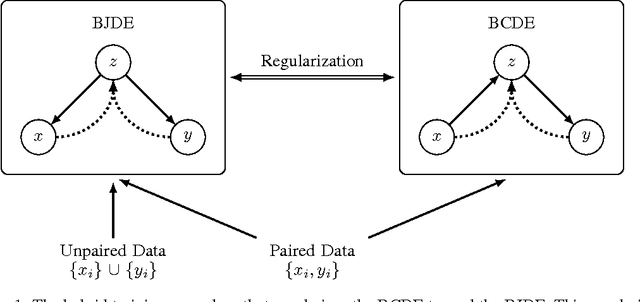
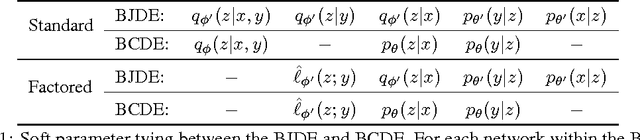
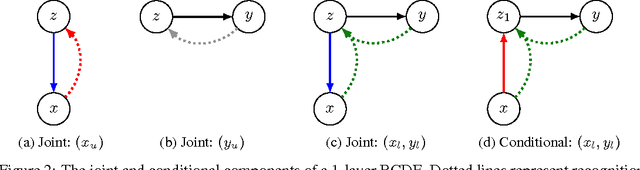
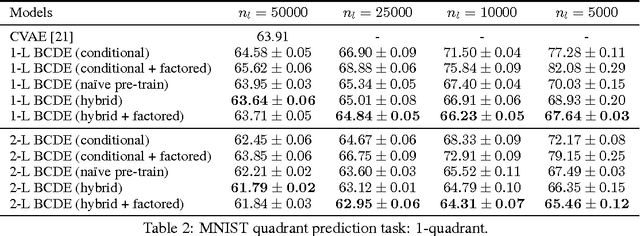
We introduce a new framework for training deep generative models for high-dimensional conditional density estimation. The Bottleneck Conditional Density Estimator (BCDE) is a variant of the conditional variational autoencoder (CVAE) that employs layer(s) of stochastic variables as the bottleneck between the input $x$ and target $y$, where both are high-dimensional. Crucially, we propose a new hybrid training method that blends the conditional generative model with a joint generative model. Hybrid blending is the key to effective training of the BCDE, which avoids overfitting and provides a novel mechanism for leveraging unlabeled data. We show that our hybrid training procedure enables models to achieve competitive results in the MNIST quadrant prediction task in the fully-supervised setting, and sets new benchmarks in the semi-supervised regime for MNIST, SVHN, and CelebA.
Online Learning to Rank in Stochastic Click Models
Jun 20, 2017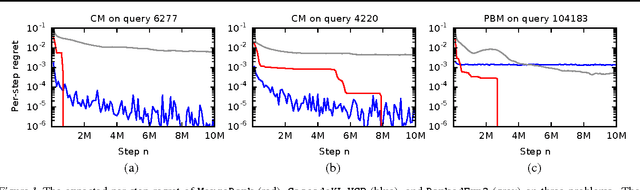
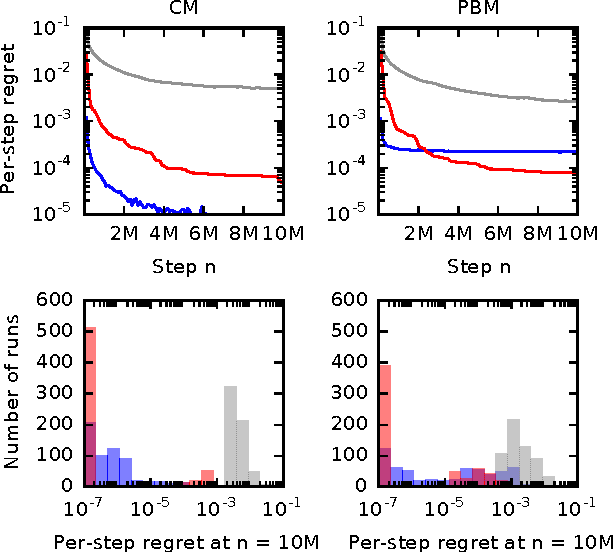
Online learning to rank is a core problem in information retrieval and machine learning. Many provably efficient algorithms have been recently proposed for this problem in specific click models. The click model is a model of how the user interacts with a list of documents. Though these results are significant, their impact on practice is limited, because all proposed algorithms are designed for specific click models and lack convergence guarantees in other models. In this work, we propose BatchRank, the first online learning to rank algorithm for a broad class of click models. The class encompasses two most fundamental click models, the cascade and position-based models. We derive a gap-dependent upper bound on the $T$-step regret of BatchRank and evaluate it on a range of web search queries. We observe that BatchRank outperforms ranked bandits and is more robust than CascadeKL-UCB, an existing algorithm for the cascade model.
Risk-Constrained Reinforcement Learning with Percentile Risk Criteria
Apr 06, 2017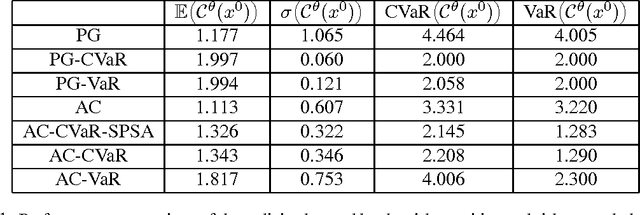
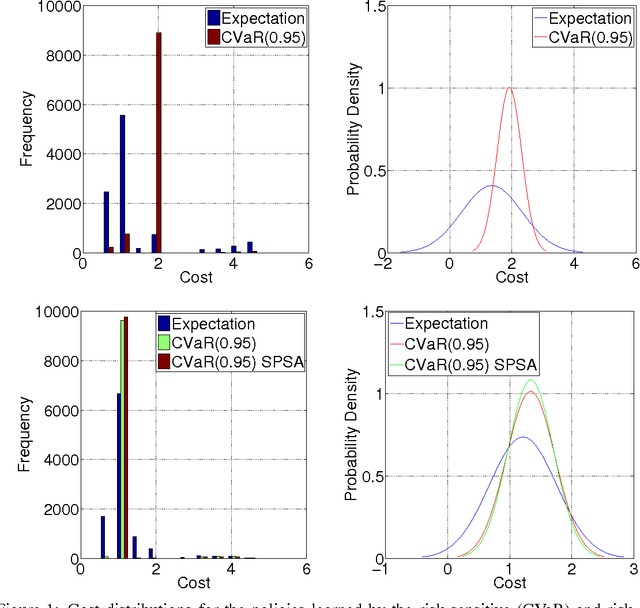
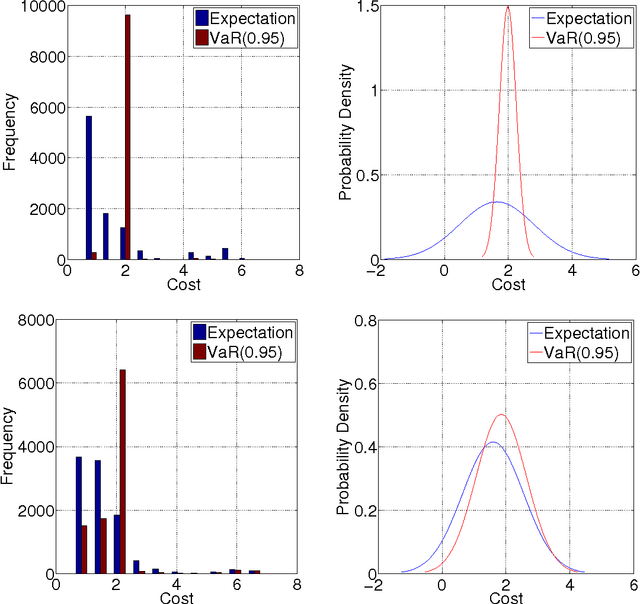
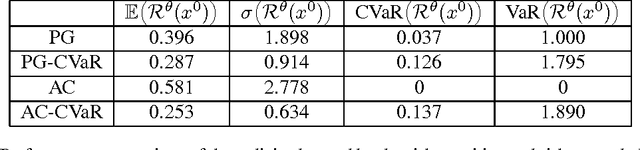
In many sequential decision-making problems one is interested in minimizing an expected cumulative cost while taking into account \emph{risk}, i.e., increased awareness of events of small probability and high consequences. Accordingly, the objective of this paper is to present efficient reinforcement learning algorithms for risk-constrained Markov decision processes (MDPs), where risk is represented via a chance constraint or a constraint on the conditional value-at-risk (CVaR) of the cumulative cost. We collectively refer to such problems as percentile risk-constrained MDPs. Specifically, we first derive a formula for computing the gradient of the Lagrangian function for percentile risk-constrained MDPs. Then, we devise policy gradient and actor-critic algorithms that (1) estimate such gradient, (2) update the policy in the descent direction, and (3) update the Lagrange multiplier in the ascent direction. For these algorithms we prove convergence to locally optimal policies. Finally, we demonstrate the effectiveness of our algorithms in an optimal stopping problem and an online marketing application.
Conservative Contextual Linear Bandits
Mar 04, 2017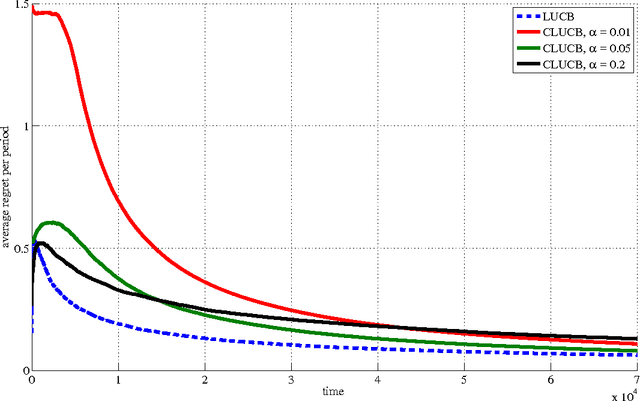
Safety is a desirable property that can immensely increase the applicability of learning algorithms in real-world decision-making problems. It is much easier for a company to deploy an algorithm that is safe, i.e., guaranteed to perform at least as well as a baseline. In this paper, we study the issue of safety in contextual linear bandits that have application in many different fields including personalized ad recommendation in online marketing. We formulate a notion of safety for this class of algorithms. We develop a safe contextual linear bandit algorithm, called conservative linear UCB (CLUCB), that simultaneously minimizes its regret and satisfies the safety constraint, i.e., maintains its performance above a fixed percentage of the performance of a baseline strategy, uniformly over time. We prove an upper-bound on the regret of CLUCB and show that it can be decomposed into two terms: 1) an upper-bound for the regret of the standard linear UCB algorithm that grows with the time horizon and 2) a constant (does not grow with the time horizon) term that accounts for the loss of being conservative in order to satisfy the safety constraint. We empirically show that our algorithm is safe and validate our theoretical analysis.
Bayesian Reinforcement Learning: A Survey
Sep 14, 2016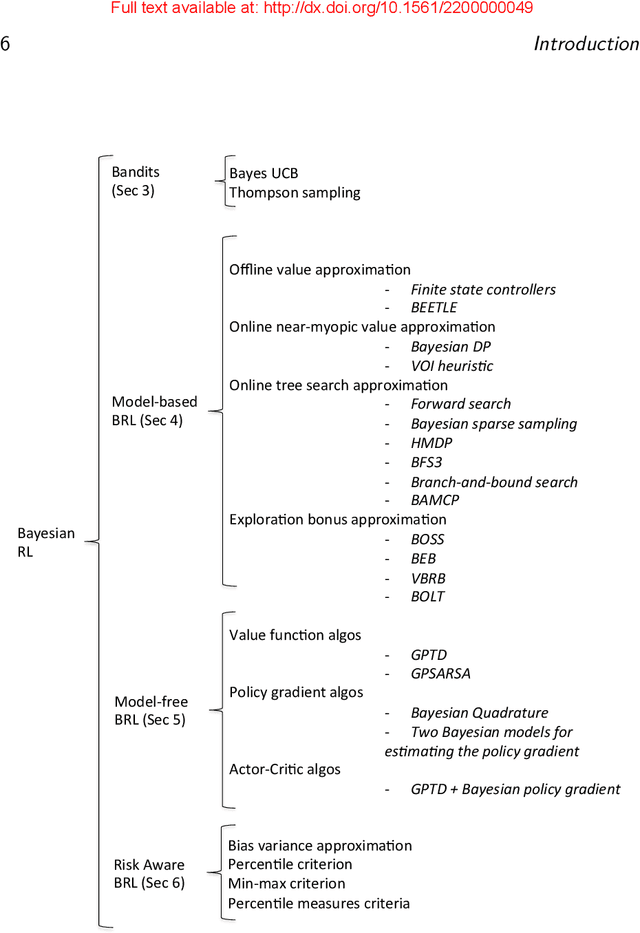
Bayesian methods for machine learning have been widely investigated, yielding principled methods for incorporating prior information into inference algorithms. In this survey, we provide an in-depth review of the role of Bayesian methods for the reinforcement learning (RL) paradigm. The major incentives for incorporating Bayesian reasoning in RL are: 1) it provides an elegant approach to action-selection (exploration/exploitation) as a function of the uncertainty in learning; and 2) it provides a machinery to incorporate prior knowledge into the algorithms. We first discuss models and methods for Bayesian inference in the simple single-step Bandit model. We then review the extensive recent literature on Bayesian methods for model-based RL, where prior information can be expressed on the parameters of the Markov model. We also present Bayesian methods for model-free RL, where priors are expressed over the value function or policy class. The objective of the paper is to provide a comprehensive survey on Bayesian RL algorithms and their theoretical and empirical properties.
Graphical Model Sketch
Jul 18, 2016
Structured high-cardinality data arises in many domains, and poses a major challenge for both modeling and inference. Graphical models are a popular approach to modeling structured data but they are unsuitable for high-cardinality variables. The count-min (CM) sketch is a popular approach to estimating probabilities in high-cardinality data but it does not scale well beyond a few variables. In this work, we bring together the ideas of graphical models and count sketches; and propose and analyze several approaches to estimating probabilities in structured high-cardinality streams of data. The key idea of our approximations is to use the structure of a graphical model and approximately estimate its factors by "sketches", which hash high-cardinality variables using random projections. Our approximations are computationally efficient and their space complexity is independent of the cardinality of variables. Our error bounds are multiplicative and significantly improve upon those of the CM sketch, a state-of-the-art approach to estimating probabilities in streams. We evaluate our approximations on synthetic and real-world problems, and report an order of magnitude improvements over the CM sketch.
Safe Policy Improvement by Minimizing Robust Baseline Regret
Jul 13, 2016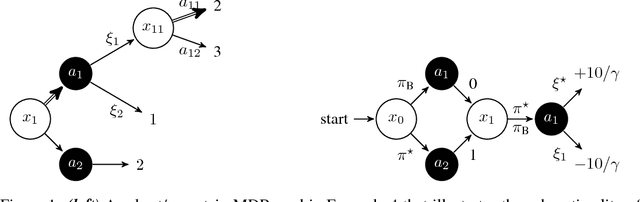
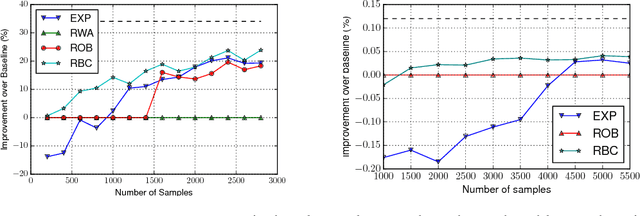
An important problem in sequential decision-making under uncertainty is to use limited data to compute a safe policy, i.e., a policy that is guaranteed to perform at least as well as a given baseline strategy. In this paper, we develop and analyze a new model-based approach to compute a safe policy when we have access to an inaccurate dynamics model of the system with known accuracy guarantees. Our proposed robust method uses this (inaccurate) model to directly minimize the (negative) regret w.r.t. the baseline policy. Contrary to the existing approaches, minimizing the regret allows one to improve the baseline policy in states with accurate dynamics and seamlessly fall back to the baseline policy, otherwise. We show that our formulation is NP-hard and propose an approximate algorithm. Our empirical results on several domains show that even this relatively simple approximate algorithm can significantly outperform standard approaches.
Personalized Advertisement Recommendation: A Ranking Approach to Address the Ubiquitous Click Sparsity Problem
Mar 06, 2016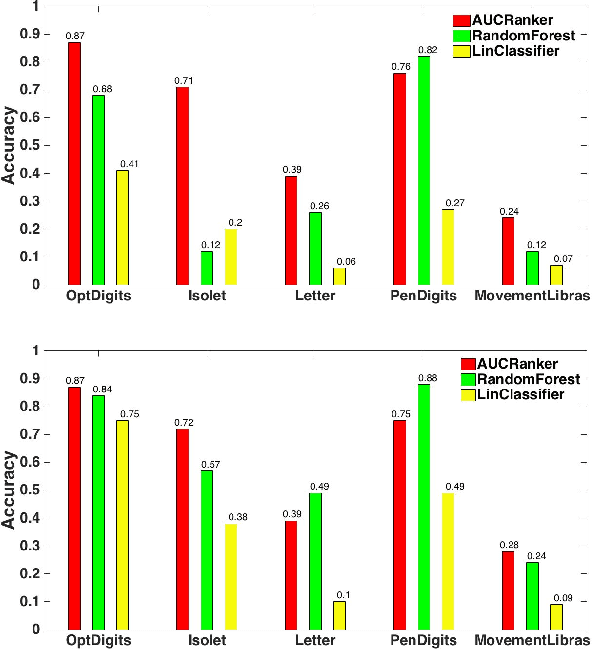

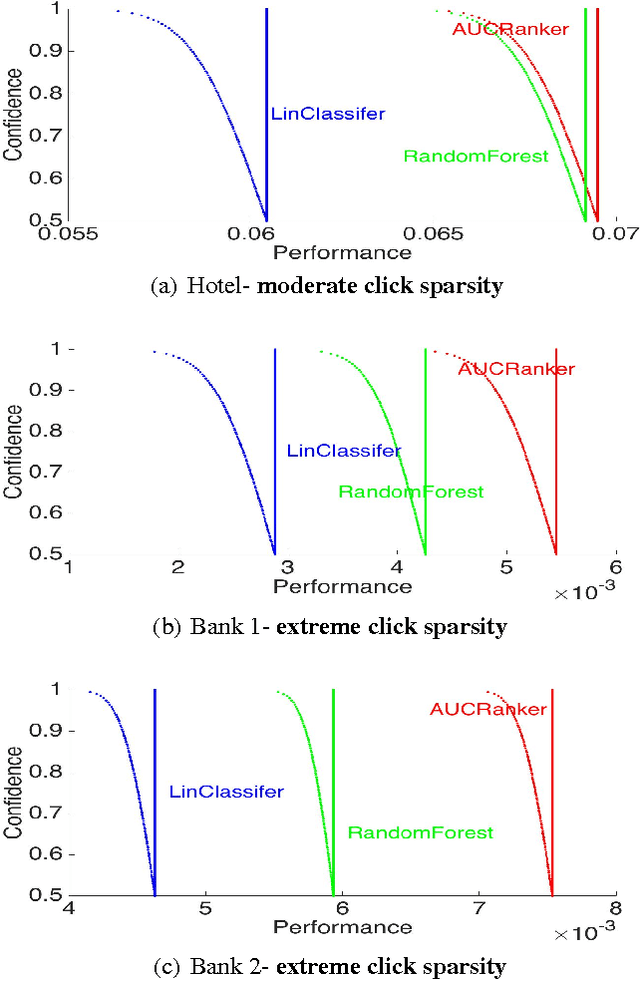
We study the problem of personalized advertisement recommendation (PAR), which consist of a user visiting a system (website) and the system displaying one of $K$ ads to the user. The system uses an internal ad recommendation policy to map the user's profile (context) to one of the ads. The user either clicks or ignores the ad and correspondingly, the system updates its recommendation policy. PAR problem is usually tackled by scalable \emph{contextual bandit} algorithms, where the policies are generally based on classifiers. A practical problem in PAR is extreme click sparsity, due to very few users actually clicking on ads. We systematically study the drawback of using contextual bandit algorithms based on classifier-based policies, in face of extreme click sparsity. We then suggest an alternate policy, based on rankers, learnt by optimizing the Area Under the Curve (AUC) ranking loss, which can significantly alleviate the problem of click sparsity. We conduct extensive experiments on public datasets, as well as three industry proprietary datasets, to illustrate the improvement in click-through-rate (CTR) obtained by using the ranker-based policy over classifier-based policies.
Upper-Confidence-Bound Algorithms for Active Learning in Multi-Armed Bandits
Jul 16, 2015
In this paper, we study the problem of estimating uniformly well the mean values of several distributions given a finite budget of samples. If the variance of the distributions were known, one could design an optimal sampling strategy by collecting a number of independent samples per distribution that is proportional to their variance. However, in the more realistic case where the distributions are not known in advance, one needs to design adaptive sampling strategies in order to select which distribution to sample from according to the previously observed samples. We describe two strategies based on pulling the distributions a number of times that is proportional to a high-probability upper-confidence-bound on their variance (built from previous observed samples) and report a finite-sample performance analysis on the excess estimation error compared to the optimal allocation. We show that the performance of these allocation strategies depends not only on the variances but also on the full shape of the distributions.
A Generalized Kernel Approach to Structured Output Learning
Jul 15, 2015


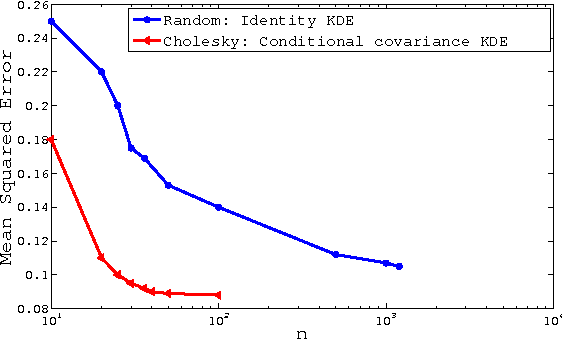
We study the problem of structured output learning from a regression perspective. We first provide a general formulation of the kernel dependency estimation (KDE) problem using operator-valued kernels. We show that some of the existing formulations of this problem are special cases of our framework. We then propose a covariance-based operator-valued kernel that allows us to take into account the structure of the kernel feature space. This kernel operates on the output space and encodes the interactions between the outputs without any reference to the input space. To address this issue, we introduce a variant of our KDE method based on the conditional covariance operator that in addition to the correlation between the outputs takes into account the effects of the input variables. Finally, we evaluate the performance of our KDE approach using both covariance and conditional covariance kernels on two structured output problems, and compare it to the state-of-the-art kernel-based structured output regression methods.